内存是计算机⾮常关键的部件之⼀,是暂时存储程序以及数据的空间,CPU只有有限的寄存器可以⽤于存储计算数据,⽽⼤部分的数据都是存储在内存中的,程序运⾏都是在内存中进⾏的。和CPU计算能⼒⼀样, 内存也是决定计算效率的⼀个关键部分。
计算中的资源中主要包含:CPU计算能⼒,内存资源以及I/O。现代计算机为了充分利⽤资源,⽽出现了多任务操作系统,通过进程调度来共享CPU计算资源,通过虚拟存储来分享内存存储能⼒。 本章的内存管理中不会介绍操作系统级别的虚拟存储技术,⽽是关注在应⽤层⾯:如何⾼效的利⽤有限的内存资源。
⽬前除了使⽤C/C++等这类的低层编程语⾔以外,很多编程语⾔都将内存管理移到了语⾔之后, 例如Java, 各种脚本语⾔:PHP/Python/Ruby等等,程序⼿动维护内存的成本⾮常⼤, ⽽这些脚本语⾔或新型语⾔都专注于特定领域,这样能将程序员从内存管理中解放出来专注于业务的实现。 虽然程序员不需要⼿动
维护内存,⽽在程序运⾏过程中内存的使⽤还是要进⾏管理的, 内存管理的⼯作也就编程语⾔实现程序员的⼯作了。
内存管理的主要⼯作是尽可能⾼效的利⽤内存。
内存的使⽤操作包括申请内存,销毁内存,修改内存的⼤⼩等。如果申请了内存在使⽤完后没有及时释放则可能会造成内存泄露,如果这种情况出现在常驻程序中,久⽽久之,程序会把机器的内存耗光。所以对于类似于PHP这样没有低层内存管理的语⾔来说, 内存管理是其⾄关重要的⼀个模块,它在很⼤程序上决定了程序的执⾏效率。
在PHP层⾯来看,定义的变量、类、函数等等实体在运⾏过程中都会涉及到内存的申请和释放, 例如变量可能会在超出作⽤域后会进⾏销毁,在计算过程中会产⽣的临时数据等都会有内存操作, 像类对象,函数定义等数据则会在请求结束之后才会被释放。在这过程中合适申请内存合适释放内存就⽐较关键了。PHP从开始就有⼀套属于⾃⼰的内存管理机制,在5.3之前使⽤的是经典的引⽤计数技术, 但引⽤技术存在⼀定的技术缺陷,在PHP5.3之后,引⼊了新的垃圾回收机制,⾄此,PHP的内存管理机制更加完善。
本章将介绍PHP语⾔实现中的内存管理技术实现。
第⼀节 内存管理概述
从某个意义上讲,资源总是有限的,计算机资源也是如此,衡量⼀个计算机处理能⼒的指标有很多,根据不同的应⽤需要也会有不同的指标,⽐如3D游戏对显卡的性能有要求,⽽Web服务器对吞吐量及响应时间有要求, 通常CPU、内存及硬盘的读取和计算速度具有决定性的作⽤,在同⼀时刻这些资源是有限的, 正是因为有限我们才需要合理的利⽤他们。
操作系统的内存管理
当计算机的电源被打开之后,不管你使⽤的是什么操作系统,这些软件可能已经在使⽤内存了。 这是由计算机的结构决定的,操作系统也是⼀种软件,只不过它是⽐较特殊的软件, 管理计算机的所有资源,普通应⽤程序和操作系统的关系有点像⽼师和学⽣,⽼师通常管理⼀切, ⽽学⽣的⾏为会受到⽼师或学校规定的限制,例如普通应⽤程序⽆法直接访问物理内存或者其他硬件资源。
操作系统直接管理着内存,所以操作系统也需要进⾏内存管理,内存管理是如此之重要, 计算机中通常都有内存管理单元(MMU) ⽤于处理CPU对内存的访问。
应⽤层的内存管理
由于计算机的内存由操作系统进⾏管理,所以普通应⽤程序是⽆法直接对内存进⾏访问的, 应⽤程序只能向操作系统申请内存,通常的应⽤也是这么做的,在需要的时候通过类似malloc之类的库函数向操作系统申请内存,在⼀些对性能要求较⾼的应⽤场景下是需要频繁的使⽤和释放内存的, ⽐如Web服务器,
编程语⾔等,由于向操作系统申请内存空间会引发系统调⽤,系统调⽤和普通的应⽤层函数调⽤性能差别⾮常⼤,因为系统调⽤会将CPU从⽤户态切换到内核, 因为涉及到物理内存的操作,只有操作系统才能进⾏,⽽这种切换的成本是⾮常⼤的,如果频繁的在内核态和⽤户态之间切换会产⽣性能问题。
鉴于系统调⽤的开销,⼀些对性能有要求的应⽤通常会⾃⼰在⽤户态进⾏内存管理, 例如第⼀次申请稍⼤的内存留着备⽤,⽽使⽤完释放的内存并不是马上归还给操作系统, 可以将内存进⾏复⽤,这样可以避免多次的内存申请和释放所带来的性能消耗。
PHP不需要显式的对内存进⾏管理,这些⼯作都由Zend引擎进⾏管理了。PHP内部有⼀个内存管理体系, 它会⾃动将不再使⽤的内存垃圾进⾏释放,这部分的内容后⾯的⼩节会介绍到。
PHP中内存相关的功能特性
可能有很多的读者碰到过类似下⾯的错误吧:
Fatal error: Allowed memory size of X bytes exhausted (tried to allocate Y bytes)
这个错误的信息很明确,PHP已经达到了允许使⽤的最⼤内存了,通常上来说这很有可能是我们的程序编写的有些问题。 ⽐如:⼀次性读取超⼤的⽂件到内存中,或者出现超⼤的数组,或者在⼤循环中的没有及时是放掉不再使⽤的变量, 这些都有可能会造成内存占⽤过⼤⽽被终⽌。
PHP默认的最⼤内存使⽤⼤⼩是32M, 如果你真的需要使⽤超过32M的内存可以修改php.ini配置⽂件的如下配置:
memory_limit = 32M
如果你⽆法修改php配置⽂件,如果你的PHP环境没有禁⽤ini_set()函数,也可以动态的修改最⼤的内存占⽤⼤⼩:
<?php ini_set("memory_limit", "128M");
既然我们能动态的调整最⼤的内存占⽤,那我们是否有办法获取⽬前的内存占⽤情况呢?答案是肯定的。
1. memory_get_usage(),这个函数的作⽤是获取⽬前PHP脚本所⽤的内存⼤⼩。
2. memory_get_peak_usage(),这个函数的作⽤返回 当前脚本到⽬前位置所占⽤的内存峰值,这样就可能获取到⽬前的脚本的内存需求情况。
单就PHP⽤户空间提供的功能来说,我们似乎⽆法控制内存的使⽤,只能被动的获取内存的占⽤情况, 这样的话我们学习内存管理有什么⽤呢?
前⾯的章节有介绍到引⽤计数,函数表,符号表,常量表等。当我们明⽩这些信息都会占⽤内存的时候, 我们可以有意的避免不必要的浪费内存,⽐如我们在项⽬中通常会使⽤autoload来避免⼀次性把不⼀定会使⽤的类 包含进来,⽽这些信息是会占⽤内存的,如果我们及时把不再使⽤的变量unset掉之后可能会释放掉它所占⽤的空间。
前⾯之所以会说把变量unset掉时候可能会把它释放掉的原因是: 在PHP中为了避免不必要的内存复制,采⽤了引⽤计数和写时复制的技术, 所以这⾥unset只是将引⽤关系打破,如果还有其他变量指向该内存, 它所占⽤的内存还是不会被释放的。当然这还有⼀种情况:出现循环引⽤,这个就得靠gc来处理了, 内存不会当时就是放,只有在gc环节才会被释放。
后⾯的章节主要介绍PHP在运⾏时的内存使⽤和管理细节。这也能帮助我们写出更为内存友好的PHP代码。
第⼆节 PHP中的内存管理
在前⾯的⼩节中我们介绍了内存管理⼀般会包括以下内容:
1. 是否有⾜够的内存供我们的程序使⽤;
2. 如何从⾜够可⽤的内存中获取部分内存;
3. 对于使⽤后的内存,是否可以将其销毁并将其重新分配给其它程序使⽤。
与此对应,PHP的内容管理也包含这样的内容,只是这些内容在ZEND内核中是以宏的形式作为接⼝提供给外部使⽤。 后⾯两个操作分别对应emalloc宏、efree宏,⽽第⼀个操作可以根据emalloc宏返回结果检测。
PHP的内存管理可以被看作是分层(hierarchical)的。 它分为三层:存储层(storage)、堆层(heap)和接⼝层(emalloc/efree)。 存储层通过 malloc()、mmap() 等函数向系统真正的申请内存,并通过 free() 函数释放所申请的内存。 存储层通常申请的内存块都⽐较⼤,这⾥申请的内存⼤并不是指
storage层结构所需要的内存⼤, 只是堆层通过调⽤存储层的分配⽅法时,其以⼤块⼤块的⽅式申请的内存,存储层的作⽤是将内存分配的⽅式对堆层透明化。 如图6.1所⽰,PHP内存管理器。PHP在存储层共有4种内存分配⽅案: malloc,win32,mmap_anon,mmap_zero, 默认使⽤malloc分配内存,如果设置了ZEND_WIN32宏,则为windows版本,调⽤HeapAlloc分配内存, 剩下两种内存⽅案为匿名内存映射,并且PHP的内存⽅案可以通过设置环境变量来修改。
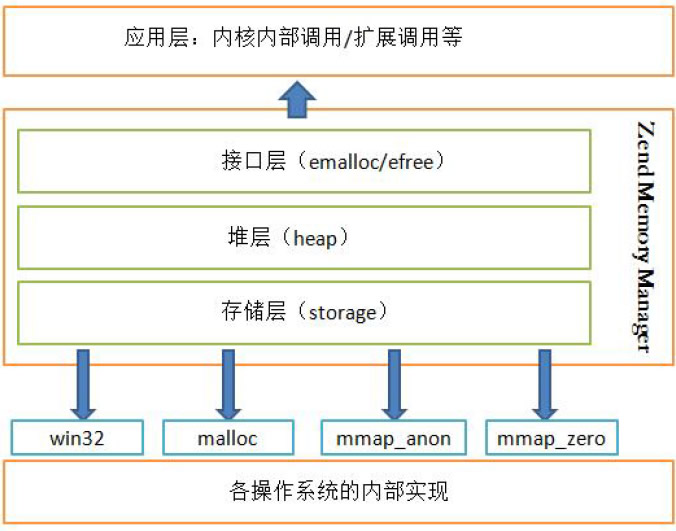
图6.1 PHP内存管理器
⾸先我们看下接⼝层的实现,接⼝层是⼀些宏定义,如下:
/* Standard wrapper macros */ #define emalloc(size) _emalloc((size) ZEND_FILE_LINE_CC,ZEND_FILE_LINE_EMPTY_CC) #define safe_emalloc(nmemb, size, offset) _safe_emalloc((nmemb), (size),(offset) ZEND_FILE_LINE_CC ZEND_FILE_LINE_EMPTY_CC) #define efree(ptr) _efree((ptr) ZEND_FILE_LINE_CC ZEND_FILE_LINE_EMPTY_CC) #define ecalloc(nmemb, size) _ecalloc((nmemb), (size) ZEND_FILE_LINE_CC ZEND_FILE_LINE_EMPTY_CC) #define erealloc(ptr, size) _erealloc((ptr), (size), 0 ZEND_FILE_LINE_CC ZEND_FILE_LINE_EMPTY_CC) #define safe_erealloc(ptr, nmemb, size, offset) _safe_erealloc((ptr), (nmemb), (size), (offset) ZEND_FILE_LINE_CC ZEND_FILE_LINE_EMPTY_CC) #define erealloc_recoverable(ptr, size) _erealloc((ptr), (size), 1 ZEND_FILE_LINE_CC ZEND_FILE_LINE_EMPTY_CC) #define estrdup(s) _estrdup((s) ZEND_FILE_LINE_CC ZEND_FILE_LINE_EMPTY_CC) #define estrndup(s, length) _estrndup((s), (length) ZEND_FILE_LINE_CC ZEND_FILE_LINE_EMPTY_CC) #define zend_mem_block_size(ptr) _zend_mem_block_size((ptr) TSRMLS_CC ZEND_FILE_LINE_CC ZEND_FILE_LINE_EMPTY_CC)
这⾥为什么没有直接调⽤函数?因为这些宏相当于⼀个接⼝层或中间层,定义了⼀个⾼层次的接⼝,使得调⽤更加容易。它隔离了外部调⽤和PHP内存管理的内部实现,实现了⼀种松耦合关系。虽然PHP不限制这些函数的使⽤, 但是官⽅⽂档还是建议使⽤这些宏。这⾥的接⼝层有点门⾯模式(facade模式)的味道。
在接⼝层下⾯是PHP内存管理的核⼼实现,我们称之为heap层。 这个层控制整个PHP内存管理的过程,⾸先我们看这个层的结构:
/* mm block type */ typedef struct _zend_mm_block_info { size_t _size; /* block的⼤⼩*/ size_t _prev; /* 计算前⼀个块有⽤到*/ } zend_mm_block_info; typedef struct _zend_mm_block { zend_mm_block_info info; } zend_mm_block; typedef struct _zend_mm_small_free_block { /* 双向链表 */ zend_mm_block_info info; struct _zend_mm_free_block *prev_free_block; /* 前⼀个块 */ struct _zend_mm_free_block *next_free_block; /* 后⼀个块 */ } zend_mm_small_free_block; /* ⼩的空闲块*/ typedef struct _zend_mm_free_block { /* 双向链表 + 树结构 */ zend_mm_block_info info; struct _zend_mm_free_block *prev_free_block; /* 前⼀个块 */ struct _zend_mm_free_block *next_free_block; /* 后⼀个块 */ struct _zend_mm_free_block **parent; /* ⽗结点 */ struct _zend_mm_free_block *child[2]; /* 两个⼦结点*/ } zend_mm_free_block;
struct _zend_mm_heap { int use_zend_alloc; /* 是否使⽤zend内存管理器 */ void *(*_malloc)(size_t); /* 内存分配函数*/ void (*_free)(void*); /* 内存释放函数*/ void *(*_realloc)(void*, size_t); size_t free_bitmap; /* ⼩块空闲内存标识 */ size_t large_free_bitmap; /* ⼤块空闲内存标识*/ size_t block_size; /* ⼀次内存分配的段⼤⼩,即ZEND_MM_SEG_SIZE指定的⼤⼩,默认为ZEND_MM_SEG_SIZE (256 * 1024)*/ size_t compact_size; /* 压缩操作边界值,为ZEND_MM_COMPACT指定⼤⼩,默认为 2 * 1024 * 1024*/ zend_mm_segment *segments_list; /* 段指针列表 */ zend_mm_storage *storage; /* 所调⽤的存储层 */ size_t real_size; /* 堆的真实⼤⼩ */ size_t real_peak; /* 堆真实⼤⼩的峰值 */ size_t limit; /* 堆的内存边界 */ size_t size; /* 堆⼤⼩ */ size_t peak; /* 堆⼤⼩的峰值*/ size_t reserve_size; /* 备⽤堆⼤⼩*/ void *reserve; /* 备⽤堆 */ int overflow; /* 内存溢出数*/ int internal; #if ZEND_MM_CACHE unsigned int cached; /* 已缓存⼤⼩ */ zend_mm_free_block *cache[ZEND_MM_NUM_BUCKETS]; /* 缓存数组/ #endif zend_mm_free_block *free_buckets[ZEND_MM_NUM_BUCKETS*2]; /* ⼩块内存数组,相当索引的⾓⾊ */ zend_mm_free_block *large_free_buckets[ZEND_MM_NUM_BUCKETS]; /* ⼤块内存数组,相当索引的⾓⾊ */ zend_mm_free_block *rest_buckets[2]; /* 剩余内存数组*/ };
当初始化内存管理时,调⽤函数是zend_mm_startup。它会初始化storage层的分配⽅案, 初始化段⼤⼩,压缩边界值,并调⽤zend_mm_startup_ex()初始化堆层。 这⾥的分配⽅案就是图6.1所⽰的四种⽅案,它对应的环境变量名为:ZEND_MM_MEM_TYPE。 这⾥的初始化的段⼤⼩可以通过
ZEND_MM_SEG_SIZE设置,如果没设置这个环境变量,程序中默认为256 * 1024。 这个值存储在_zend_mm_heap结构的block_size字段中,将来在维护的三个列表中都没有可⽤的内存中,会参考这个值的⼤⼩来申请内存的⼤⼩。
PHP中的内存管理主要⼯作就是维护三个列表:⼩块内存列表(free_buckets)、 ⼤块内存列表(large_free_buckets)和剩余内存列表(rest_buckets)。 看到bucket这个单词是不是很熟悉?在前⾯我们介绍HashTable时,这就是⼀个重要的⾓⾊,它作为HashTable中的⼀个单元⾓⾊。 在这⾥,每个bucket也对应⼀定⼤⼩的内存块列表,这样的列表都包含双向链表的实现。
我们可以把维护的前⾯两个表看作是两个HashTable,那么,每个HashTable都会有⾃⼰的hash函数。 ⾸先我们来看free_buckets列表,这个列表⽤来存储⼩块的内存分配,其hash函数为:
#define ZEND_MM_BUCKET_INDEX(true_size)
((true_size>>ZEND_MM_ALIGNMENT_LOG2)-(ZEND_MM_ALIGNED_MIN_HEADER_SIZE>>ZEND_MM_ALIGNMENT_LOG2))
假设ZEND_MM_ALIGNMENT为8(如果没有特殊说明,本章的ZEND_MM_ALIGNMENT的值都为8),则ZEND_MM_ALIGNED_MIN_HEADER_SIZE=16, 若此时true_size=256,则((256>>3)-(16>>3))= 30。 当ZEND_MM_BUCKET_INDEX宏出现时,ZEND_MM_SMALL_SIZE宏⼀般也会同时出现, ZEND_MM_SMALL_SIZE宏的作⽤是判断所申请的内存⼤⼩是否为⼩块的内存, 在上⾯的⽰例中,
⼩于272Byte的内存为⼩块内存,则index最多只能为31, 这样就保证了free_buckets不会出现数组溢出的情况。
在内存管理初始化时,PHP内核对初始化free_buckets列表。 从heap的定义我们可知free_buckets是⼀个数组指针,其存储的本质是指向zend_mm_free_block结构体的指针。 开始时这些指针都没有指向具体的元素,只是⼀个简单的指针空间。 free_buckets列表在实际使⽤过程中只存储指针,这些指针以两个为⼀对(即数组从0开始,两个为⼀对),分别存储⼀个个双向链表的头尾指针。 其结构如图6.2所⽰。
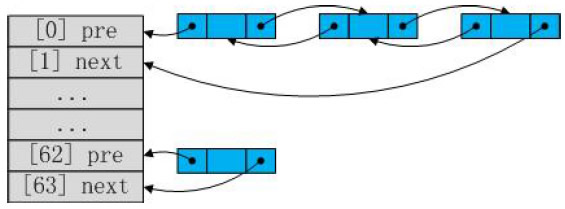
图6.2 free_buckets列表结构
对于free_buckets列表位置的获取,关键在于ZEND_MM_SMALL_FREE_BUCKET宏,宏代码如下:
#define ZEND_MM_SMALL_FREE_BUCKET(heap, index) (zend_mm_free_block*) ((char*)&heap->free_buckets[index * 2] + sizeof(zend_mm_free_block*) * 2 -sizeof(zend_mm_small_free_block))
仔细看这个宏实现,发现在它的计算过程是取free_buckets列表的偶数位的内存地址加上 两个指针的内存⼤⼩ 并减去zend_mm_small_free_block结构所占空间的⼤⼩。 ⽽zend_mm_free_block结构和zend_mm_small_free_block结构的差距在于两个指针。 据此计算过程可知,ZEND_MM_SMALL_FREE_BUCKET宏会获取free_buckets列表 index对应双向链表的第⼀个zend_mm_free_block的prev_free_block指向的位置。 free_buckets的计算仅仅与prev_free_block指针和next_free_block指针相关, 所以free_buckets列表也仅仅需要存储这两个指针。
那么,这个数组在最开始是怎样的呢? 在初始化函数zend_mm_init中free_buckets与large_free_buckts列表⼀起被初始化。 如下代码:
p = ZEND_MM_SMALL_FREE_BUCKET(heap, 0); for (i = 0; i < ZEND_MM_NUM_BUCKETS; i++) { p->next_free_block = p; p->prev_free_block = p; p = (zend_mm_free_block*)((char*)p + sizeof(zend_mm_free_block*) * 2); heap->large_free_buckets[i] = NULL; }
对于free_buckets列表来说,在循环中,偶数位的元素(索引从0开始)将其next_free_block和prev_free_block都指向⾃⼰, 以i=0为例,free_buckets的第⼀个元素(free_buckets[0])存储的是第⼆个元素(free_buckets[1])的地址, 第⼆个元素存储的是第⼀个元素的地址。 此时将可能会想⼀个问题,在整个free_buckets列表没有内容时,ZEND_MM_SMALL_FREE_BUCKET在获取第⼀个zend_mm_free_block时, 此zend_mm_free_block的next_free_block元素和prev_free_block元素却分别指向free_buckets[0]和free_buckets[1]。
在整个循环初始化过程中都没有free_buckets数组的下标操作,它的移动是通过地址操作,以加两个
sizeof(zend_mm_free_block*)实现, 这⾥的sizeof(zend_mm_free_block*)是获取指针的⼤⼩。⽐如现在
是在下标为0的元素的位置, 加上两个指针的值后,指针会指向下标为2的地址空间,从⽽实现数组元素的
向后移动, 也就是zend_mm_free_block->next_free_block和zend_mm_free_block->prev_free_block位
置的后移。 这种不存储zend_mm_free_block数组,仅存储其指针的⽅式不可不说精妙。虽然在理解上有
⼀些困难,但是节省了内存。
free_buckets列表使⽤free_bitmap标记是否该双向链表已经使⽤过时有⽤。 当有新的元素需要插⼊到列表时,需要先根据块的⼤⼩查找index, 查找到index后,在此index对应的双向链表的头部插⼊新的元素。
free_buckets列表的作⽤是存储⼩块内存,⽽与之对应的large_free_buckets列表的作⽤是存储⼤块的内存, 虽然large_free_buckets列表也类似于⼀个hash表,但是这个与前⾯的free_buckets列表⼀些区别。 它是⼀个集成了数组,树型结构和双向链表三种数据结构的混合体。 我们先看其数组结构,数组是⼀个hash映射,其hash函数为:
#define ZEND_MM_LARGE_BUCKET_INDEX(S) zend_mm_high_bit(S) static inline unsigned int zend_mm_high_bit(size_t _size) { ..//省略若⼲不同环境的实现 unsigned int n = 0; while (_size != 0) { _size = _size >> 1; n++; } return n-1; }
这个hash函数⽤来计算size中最⾼位的1的⽐特位是多少,这点从其函数名就可以看出。 假设此时size为512Byte,则这段内存会放在large_free_buckets列表, 512的⼆进制码为1000000000,则zend_mm_high_bit(512)计算的值为9,则其对应的列表index为9。 关于右移操作,这⾥有⼀点说明:
⼀般来说,右移分为逻辑右移和算术右移。逻辑位移在在左端补K个0,算术右移在左端补K个最⾼有效位的值。 C语⾔标准没有明确定义应该使⽤哪种⽅式。对于⽆符号数据,右移必须是逻辑的。对于有符号的数据,则⼆者都可以。 但是,现实中都会默认为算术右移。
以上的zend_mm_high_bit函数实现是节选的最后C语⾔部分(如果对汇编不了解的话,看这部分会⽐较容易⼀些)。 但是它却是最后⼀种选择,在其它环境中,如x86的处理中可以使⽤汇编语⾔BSR达到这段代码的⽬的,这样的速度会更快⼀些。 这个汇编语句是BSR(Bit Scan Reverse),BSR被称为逆向位
扫描指令。 它使⽤⽅法为: BSF dest,src,它的作⽤是从源操作数的的最⾼位向低位搜索,将遇到的第⼀个“1”所在的位序号存⼊⽬标寄存器。
我们通过⼀次列表的元素插⼊操作来理解列表的结果。 ⾸先确定当前需要内存所在的数组元素位置,然后查找此内存⼤⼩所在的位置。 这个查找⾏为是发⽣在树型结构中,⽽树型结构的位置与内存的⼤⼩有关。 其查找过程如下:
第⼀步 通过索引获取树型结构第⼀个结点并作为当前结点,如果第⼀个结点为空,则将内存放到第⼀个元素的结点位置,返回,否则转第⼆步
第⼆步 从当前结点出发,查找下⼀个结点,并将其作为当前结点
第三步 判断当前结点内存的⼤⼩与需要分配的内存⼤⼩是否⼀样 如果⼤⼩⼀样则以双向链表的结构将新的元素添加到结点元素的后⾯第⼀个元素的位置。否则转四步
第四步 判断当前结点是否为空,如果为空,则占据结点位置,结束查找,否则第⼆步。
从以上的过程我们可以画出large_free_buckets列表的结构如图6.3所⽰:
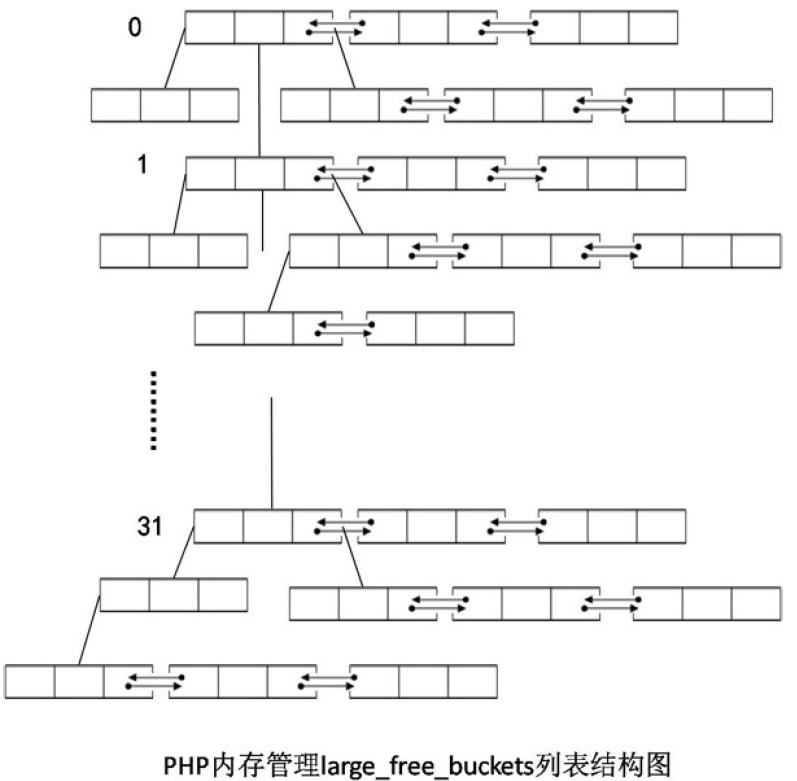
图6.3 large_free_buckets列表结构
从内存分配的过程中可以看出,内存块查找判断顺序依次是⼩块内存列表,⼤块内存列表,剩余内存列表。 在heap结构中,剩余内存列表对应rest_buckets字段,这是⼀个包含两个元素的数组, 并且也是⼀个双向链表队列,其中rest_buckets[0]为队列的头,rest_buckets[1]为队列的尾。 ⽽我们常⽤的插⼊和查找操作是针对第⼀个元素,即heap->rest_buckets[0], 当然,这是⼀个双向链表队列,队列的头和尾并没有很明显的区别。它们仅仅是作为⼀种认知上的区分。 在添加内存时,如果所需要的内存块的⼤⼩⼤于初始化时设置的ZEND_MM_SEG_SIZE的值(在heap结构中为block_size字段) 与ZEND_MM_ALIGNED_SEGMENT_SIZE(等于8)和ZEND_MM_ALIGNED_HEADER_SIZE(等于8)的和的差,则会将新⽣成的块插⼊ rest_buckts所在的双向链表中,这个操作和前⾯的双向链表操作⼀样,都是从”队列头“插⼊新的元素。 此列表的结构和free_bucket类似,只是这个列表所在的数组没有那么多元素,也没有相应的hash函数。
在heap层下⾯是存储层,存储层的作⽤是将内存分配的⽅式对堆层透明化,实现存储层和heap层的分离。 在PHP的源码中有注释显⽰相关代码为"Storage Manager"。 存储层的主要结构代码如下:
/* Heaps with user defined storage */ typedef struct _zend_mm_storage zend_mm_storage; typedef struct _zend_mm_segment { size_t size; struct _zend_mm_segment *next_segment; } zend_mm_segment; typedef struct _zend_mm_mem_handlers { const char *name;
zend_mm_storage* (*init)(void *params); // 初始化函数 void (*dtor)(zend_mm_storage *storage); // 析构函数 void (*compact)(zend_mm_storage *storage); zend_mm_segment* (*_alloc)(zend_mm_storage *storage, size_t size); //内存分配函数 zend_mm_segment* (*_realloc)(zend_mm_storage *storage, zend_mm_segment *ptr, size_t size); // 重新分配内存函数 void (*_free)(zend_mm_storage *storage, zend_mm_segment *ptr); // 释放内存函数 } zend_mm_mem_handlers; struct _zend_mm_storage { const zend_mm_mem_handlers *handlers; // 处理函数集 void *data; };
以上代码的关键在于存储层处理函数的结构体,对于不同的内存分配⽅案,所不同的就是内存分配的处理函数。 其中以name字段标识不同的分配⽅案。在图6.1中,我们可以看到PHP在存储层共有4种内存分配⽅案: malloc,win32,mmap_anon,mmap_zero默认使⽤malloc分配内存, 如果设置了
ZEND_WIN32宏,则为windows版本,调⽤HeapAlloc分配内存,剩下两种内存⽅案为匿名内存映射, 并且PHP的内存⽅案可以通过设置变量来修改。其官⽅说明如下:
The Zend MM can be tweaked using ZEND_MM_MEM_TYPE and ZEND_MM_SEG_SIZE environment variables. Default values are
“malloc” and “256K”. Dependent on target system you can also use “mmap_anon”, “mmap_zero” and “win32″ storage
managers.
在代码中,对于这4种内存分配⽅案,分别对应实现了zend_mm_mem_handlers中的各个处理函数。配合代码的简单说明如下:
/* 使⽤mmap内存映射函数分配内存 写⼊时拷贝的私有映射,并且匿名映射,映射区不与任何⽂件关 联。*/ # define ZEND_MM_MEM_MMAP_ANON_DSC {"mmap_anon", zend_mm_mem_dummy_init, zend_mm_mem_dummy_dtor, zend_mm_mem_dummy_compact, zend_mm_mem_mmap_anon_alloc, zend_mm_mem_mmap_realloc, zend_mm_mem_mmap_free} /* 使⽤mmap内存映射函数分配内存 写⼊时拷贝的私有映射,并且映射到/dev/zero。*/ # define ZEND_MM_MEM_MMAP_ZERO_DSC {"mmap_zero", zend_mm_mem_mmap_zero_init, zend_mm_mem_mmap_zero_dtor, zend_mm_mem_dummy_compact, zend_mm_mem_mmap_zero_alloc, zend_mm_mem_mmap_realloc, zend_mm_mem_mmap_free} /* 使⽤HeapAlloc分配内存 windows版本 关于这点,注释中写的是VirtualAlloc() to allocate memory,实际在程序中使⽤的是HeapAlloc*/ # define ZEND_MM_MEM_WIN32_DSC {"win32", zend_mm_mem_win32_init, zend_mm_mem_win32_dtor, zend_mm_mem_win32_compact, zend_mm_mem_win32_alloc, zend_mm_mem_win32_realloc, zend_mm_mem_win32_free} /* 使⽤malloc分配内存 默认为此种分配 如果有加ZEND_WIN32宏,则使⽤win32的分配⽅案*/ # define ZEND_MM_MEM_MALLOC_DSC {"malloc", zend_mm_mem_dummy_init, zend_mm_mem_dummy_dtor, zend_mm_mem_dummy_compact, zend_mm_mem_malloc_alloc, zend_mm_mem_malloc_realloc, zend_mm_mem_malloc_free} static const zend_mm_mem_handlers mem_handlers[] = { #ifdef HAVE_MEM_WIN32 ZEND_MM_MEM_WIN32_DSC, #endif #ifdef HAVE_MEM_MALLOC ZEND_MM_MEM_MALLOC_DSC, #endif #ifdef HAVE_MEM_MMAP_ANON ZEND_MM_MEM_MMAP_ANON_DSC, #endif #ifdef HAVE_MEM_MMAP_ZERO ZEND_MM_MEM_MMAP_ZERO_DSC, #endif {NULL, NULL, NULL, NULL, NULL, NULL} };
假设我们使⽤的是win32内存⽅案,则在PHP编译时,编译器会选择将ZEND_MM_MEM_WIN32_DSC宏所代码的所有处理函数赋值给mem_handlers。 在之后我们调⽤内存分配时,将会使⽤此数组中对应的相关函数。当然,在指定环境变量 USE_ZEND_ALLOC 时,可⽤于允许在运⾏时选择 malloc 或 emalloc 内存分配。 使⽤ malloc-type 内存分配将允许外部调试器观察内存使⽤情况,⽽ emalloc 分配将使⽤ Zend 内存管理器抽象,要求进⾏内部调试。
第三节 内存使⽤:申请和销毁
内存的申请
通过前⼀⼩节我们可以知道,PHP底层对内存的管理, 围绕着⼩块内存列表(free_buckets)、 ⼤块内存列表(large_free_buckets)和 剩余内存列表(rest_buckets)三个列表来分层进⾏的。 ZendMM向系统进⾏的内存申请,并不是有需要时向系统即时申请, ⽽是由ZendMM的最底层(heap层)先向系统申请⼀⼤块的内存,通过对上⾯三种列表的填充, 建⽴⼀个类似于内存池的管理机制。 在程序运⾏需要使⽤内存的时候,ZendMM会在内存池中分配相应的内存供使⽤。 这样做的好处是避免了PHP向系统频繁的内存申请操作,如下⾯的代码:
<?php $tipi = "o_o "; echo $tipi; ?>
这是⼀个简单的php程序,但通过对emalloc的调⽤计数,发现对内存的请求有数百次之多, 当然这⾮常容易解释,因为PHP脚本的执⾏,需要⼤量的环境变量以及内部变量的定义, 这些定义本⾝都是需要在内存中进⾏存储的。
在编写PHP的扩展时,推荐使⽤emalloc来代替malloc,其实也就是使⽤PHP的ZendMM来代替 ⼿动直接调⽤系统级的内存管理。(除⾮,你⾃⼰知道⾃已在做什么。)
那么在上⾯这个⼩程序的执⾏过程中,ZendMM是如何使⽤⾃⾝的heap层存储空间的呢? 经过对源码的追踪我们可以找到:
ZEND_ASSIGN_SPEC_CV_CONST_HANDLER (......) -> ALLOC_ZVAL(......) -> ZEND_FAST_ALLOC(......) -> emalloc (......) -> _emalloc(......) -> _zend_mm_alloc_int(.....)
void *_emalloc 实现了对内存的申请操作,在_emalloc的处理过程中, 对是否使⽤ZendMM进⾏了判断,如果heap层没有使⽤ZendMM来管理, 就直接使⽤_zend_mm_heap结构中定义的_malloc函数进⾏内存的分配; (我们通过上节可以知道,这⾥的_malloc可以是malloc,win32,mmap_anon,mmap_zero中的⼀种);
就⽬前所知,不使⽤ZendMM进⾏内存管理,唯⼀的⽤途是打开enable-debug开关后, 可以更⽅便的追踪内存的使⽤情况。所以,在这⾥我们关注ZendMM使⽤_zend_mm_alloc_int函数进⾏内存分配:
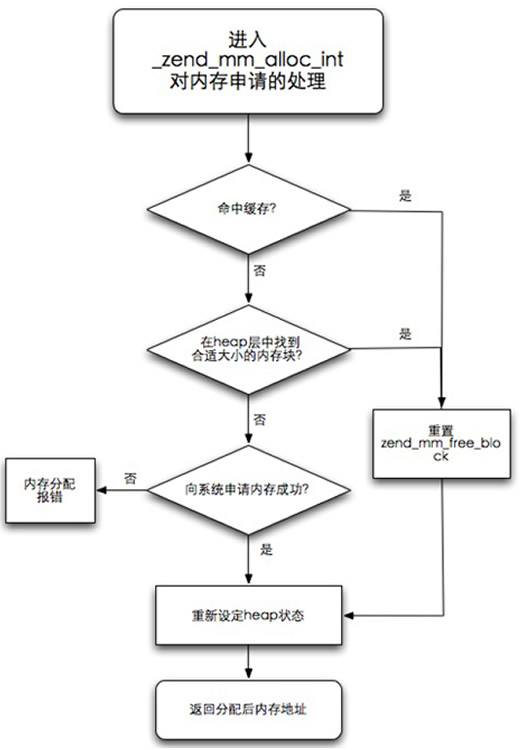
图6.1 PHP内存管理器
结合上图,再加上内存分配之前的验证,ZendMM对内存分配的处理主要有以下步骤:
1. 内存检查。 对要申请的内存⼤⼩进⾏检查,如果太⼤(超出memory_limit则报 Out of Memory);
2. 如果命中缓存,使⽤fastcache得到内存块(详见第五节),然后直接进⾏第5步;
3. 在ZendMM管理的heap层存储中搜索合适⼤⼩的内存块, 在这⼀步骤ZendMM通过与ZEND_MM_MAX_SMALL_SIZE进⾏⼤⼩⽐较, 把内存请求分为两种类型: large和small。small类型的的请求会先使⽤zend_mm_low_bit函数 在mm_heap中的free_buckets中查找,未找到则使⽤与large类型相同的⽅式: 使⽤zend_mm_search_large_block函数在“⼤块”内存(_zend_mm_heap->large_free_buckets)中进⾏查找。 如果还没有可以满⾜⼤⼩需求的内存,最后在rest_buckets中进⾏查找。 也就是说,内存的分配是在三种列表中⼩到⼤进⾏的。 找到可以使⽤的block后,进⾏第5步;
4. 如果经过第3步的查找还没有找到可以使⽤的资源(请求的内存过⼤),需要使⽤ZEND_MM_STORAGE_ALLOC函数向系统再申请⼀块内存(⼤⼩⾄少为
ZEND_MM_SEG_SIZE),然后直接将对齐后的地址分配给本次请求。跳到第6步;
5. 使⽤zend_mm_remove_from_free_list函数将已经使⽤block节点在zend_mm_free_block中移除;
6. 内存分配完毕,对zend_mm_heap结构中的各种标识型变量进⾏维护,包括large_free_buckets,peak,size等;
7. 返回分配的内存地址;
从上⾯的分配可以看出,PHP对内存的分配,是结合PHP的⽤途来设计的,PHP⼀般⽤于web应⽤程序的数据⽀持, 单个脚本的运⾏周期⼀般⽐较短(最多达到秒级),内存⼤块整块的申请,⾃主进⾏⼩块的分配, 没有进⾏⽐较复杂的不相临地址的空闲内存合并,⽽是集中再次向系统请求。 这样做的好处就是运⾏速度会更快,缺点是随着程序的运⾏时间的变长, 内存的使⽤情况会“越来越多”(PHP5.2及更早版本)。 所以PHP5.3之前的版本并不适合做为守护进程长期运⾏。 (当然,可以有其他⽅法解决,⽽且在PHP5.3中引⼊了新的GC机制,详见下⼀⼩节)
内存的销毁
ZendMM在内存销毁的处理上采⽤与内存申请相同的策略,当程序unset⼀个变量或者是其他的释放⾏为时, ZendMM并不会直接⽴刻将内存交回给系统,⽽是只在⾃⾝维护的内存池中将其重新标识为可⽤,按照内存的⼤⼩整理到上⾯所说的三种列表(small,large,free)之中,以备下次内存申请时使⽤。
关于变量销毁的处理,还涉及较多的其他操作,请参看变量的创建和销毁.
内存销毁的最终实现函数是_efree。在_efree中,内存的销毁⾸先要进⾏是否放回cache的判断。 如果内存的⼤⼩满⾜ZEND_MM_SMALL_SIZE并且cache还没有超过系统设置的ZEND_MM_CACHE_SIZE, 那么,当前内存块zend_mm_block就会被放回mm_heap->cache中。 如果内存块没有被放回cache,则使⽤下⾯的代码进⾏处理:
zend_mm_block *mm_block; //要销毁的内存块 zend_mm_block *next_block; ... next_block = ZEND_MM_BLOCK_AT(mm_block, size); if (ZEND_MM_IS_FREE_BLOCK(next_block)) { zend_mm_remove_from_free_list(heap, (zend_mm_free_block *) next_block); size += ZEND_MM_FREE_BLOCK_SIZE(next_block); } if (ZEND_MM_PREV_BLOCK_IS_FREE(mm_block)) { mm_block = ZEND_MM_PREV_BLOCK(mm_block); zend_mm_remove_from_free_list(heap, (zend_mm_free_block *) mm_block); size += ZEND_MM_FREE_BLOCK_SIZE(mm_block); } if (ZEND_MM_IS_FIRST_BLOCK(mm_block) && ZEND_MM_IS_GUARD_BLOCK(ZEND_MM_BLOCK_AT(mm_block, size))) { zend_mm_del_segment(heap, (zend_mm_segment *) ((char *)mm_block - ZEND_MM_ALIGNED_SEGMENT_SIZE)); } else { ZEND_MM_BLOCK(mm_block, ZEND_MM_FREE_BLOCK, size); zend_mm_add_to_free_list(heap, (zend_mm_free_block *) mm_block); }
这段代码逻辑⽐较清晰,主要是根据当前要销毁的内存块mm_block在zend_mm_heap 双向链表中所处的位置进⾏不同的操作。如果下⼀个节点还是free的内存,则将下⼀个节点合并; 如果上⼀相邻节点内存块为free,则合并到上⼀个节点; 如果只是普通节点,刚使⽤ zend_mm_add_to_free_list或者zend_mm_del_segment 进⾏回收。
就这样,ZendMM将内存块以整理收回到zend_mm_heap的⽅式,回收到内存池中。 程序使⽤的所有内存,将在进程结束时统⼀交还给系统。
在内存的销毁过程中,还涉及到引⽤计数和垃圾回收(GC),将在下⼀⼩节进⾏讨论。
第四节 垃圾回收
垃圾回收机制是⼀种动态存储分配⽅案。它会⾃动释放程序不再需要的已分配的内存块。 ⾃动回收内存的过程叫垃圾收集。垃圾回收机制可以让程序员不必过分关⼼程序内存分配,从⽽将更多的精⼒投⼊到业务逻辑。 在现在的流⾏各种语⾔当中,垃圾回收机制是新⼀代语⾔所共有的特征,如Python、PHP、Eiffel、C#、Ruby等都使⽤了垃圾回收机制。 虽然垃圾回收是现在⽐较流⾏的做法,但是它的年纪已经不⼩了。早在20世纪60年代MIT开发的Lisp系统中就已经有了它的⾝影, 但是由于当时技术条件不成熟,从⽽使得垃圾回收机制成了⼀个看起来很美的技术,直到20世纪90年代Java的出现,垃圾回收机制才被⼴泛应⽤。
PHP也在语⾔层实现了内存的动态管理,这在前⾯的章节中已经有了详细的说明, 内存的动态管理将开发⼈员从繁琐的内存管理中解救出来。与此配套,PHP也提供了语⾔层的垃圾回收机制, 让程序员不必过分关⼼程序内存分配。
在PHP5.3版本之前,PHP只有简单的基于引⽤计数的垃圾回收,当⼀个变量的引⽤计数变为0时,PHP将在内存中销毁这个变量,只是这⾥的垃圾并不能称之为垃圾。 并且PHP在⼀个⽣命周期结束后就会释放此进程/线程所点的内容,这种⽅式决定了PHP在前期不需要过多考虑内存的泄露问题。 但是随着PHP
的发展,PHP开发者的增加以及其所承载的业务范围的扩⼤,在PHP5.3中引⼊了更加完善的垃圾回收机制。 新的垃圾回收机制解决了⽆法处理循环的引⽤内存泄漏问题。PHP5.3中的垃圾回收机制使⽤了⽂章引⽤计数系统中的同步周期回收(Concurrent Cycle Collection in Reference Counted Systems) 中的同步算法。关于这个算法的介绍我们就不再赘述,在PHP的官⽅⽂档有图⽂并茂的介绍:回收周期(CollectingCycles)。
在本⼩节,我们从PHP的垃圾回收机制的结构出发,结合其算法介绍PHP5.3垃圾回收机制的实现。
新的垃圾回收
如前⾯所说,在PHP中,主要的内存管理⼿段是引⽤计数,引⼊垃圾收集机制的⽬的是为了打破引⽤计数中的循环引⽤,从⽽防⽌因为这个⽽产⽣的内存泄露。 垃圾收集机制基于PHP的动态内存管理⽽存在。PHP5.3为引⼊垃圾收集机制,在变量存储的基本结构上有⼀些变动,如下所⽰:
struct _zval_struct { /* Variable information */ zvalue_value value; /* value */ zend_uint refcount__gc; zend_uchar type; /* active type */ zend_uchar is_ref__gc; };
与PHP5.3之前的版本相⽐,引⽤计数字段refcount和是否引⽤字段is_ref都在其后⾯添加了__gc以⽤于新的的垃圾回收机制。 在PHP的源码风格中,⼤量的宏是⼀个⾮常鲜明的特点。这些宏相当于⼀个接⼝层,它屏蔽了接⼝层以下的⼀些底层实现,如, ALLOC_ZVAL宏,这个宏在PHP5.3之前是直接调⽤PHP
的内存管理分配函数emalloc分配内存,所分配的内存⼤⼩由变量的类型等⼤⼩决定。 在引⼊垃圾回收机制后,ALLOC_ZVAL宏直接采⽤新的垃圾回收单元结构,所分配的⼤⼩都是⼀样的,全部是zval_gc_info结构体所占内存⼤⼩, 并且在分配内存后,初始化这个结构体的垃圾回收机制。如下代码:
/* The following macroses override macroses from zend_alloc.h */ #undef ALLOC_ZVAL #define ALLOC_ZVAL(z) do { (z) = (zval*)emalloc(sizeof(zval_gc_info)); GC_ZVAL_INIT(z); } while
zend_gc.h⽂件在zend.h的749⾏被引⽤:#include “zend_gc.h” 从⽽替换覆盖了在237⾏引⽤的zend_alloc.h⽂件中的ALLOC_ZVAL等宏 在新的的宏中,关键性的改变是对所分配内存⼤⼩和分配内容的改变,在以前纯粹的内存分配中添加了垃圾收集机制的内容, 所有的内容都包括在zval_gc_info结构体中:
typedef struct _zval_gc_info { zval z; union { gc_root_buffer *buffered; struct _zval_gc_info *next; } u; } zval_gc_info;
对于任何⼀个ZVAL容器存储的变量,分配了⼀个zval结构,这个结构确保其和以zval变量分配的内存的开始对齐, 从⽽在zval_gc_info类型指针的强制转换时,其可以作为zval使⽤。在zval字段后⾯有⼀个联合体:u。 u包括gc_root_buffer结构的buffered字段和zval_gc_info结构的next字段。 这两个字段⼀个是表⽰垃圾收集机制缓存的根结点,⼀个是zval_gc_info列表的下⼀个结点, 垃圾收集机制缓存的结点⽆论是作为根结点,还是列表结点,都可以在这⾥体现。 ALLOC_ZVAL在分配了内存后会调⽤GC_ZVAL_INIT⽤来初始化替代了zval的zval_gc_info, 它会把zval_gc_info中的成员u的buffered字段设置成NULL,此字段仅在将其放⼊垃圾回收缓冲区时才会有值,否则会⼀直是NULL。 由于PHP中所有的变量都是以zval变量的形式存在,这⾥以zval_gc_info替换zval,从⽽成功实现垃圾收集机制在原有系统中的集成。
PHP的垃圾回收机制在PHP5.3中默认为开启,但是我们可以通过配置⽂件直接设置为禁⽤,其对应的配置字段为:zend.enable_gc。 在php.ini⽂件中默认是没有这个字段的,如果我们需要禁⽤此功能,则在php.ini中添加zend.enable_gc=0或zend.enable_gc=off。 除了修改php.ini配置zend.enable_gc,也可以通过调⽤gc_enable()/gc_disable()函数来打开/关闭垃圾回收机制。 这些函数的调⽤效果与修改配置项来打开或关闭垃圾回收机制的效果是⼀样的。 除了这两个函数PHP提供了gc_collect_cycles()函数可以在根缓冲区还没满时强制执⾏周期回收。 与垃圾回收机制是否开启在PHP源码中有⼀些相关的操作和字段。在zend.c⽂件中有如下代码:
static ZEND_INI_MH(OnUpdateGCEnabled) /* {{{ */ { OnUpdateBool(entry, new_value, new_value_length, mh_arg1, mh_arg2, mh_arg3,stage TSRMLS_CC); if (GC_G(gc_enabled)) { gc_init(TSRMLS_C); } return SUCCESS; } /* }}} */ ZEND_INI_BEGIN() ZEND_INI_ENTRY("error_reporting", NULL, ZEND_INI_ALL,OnUpdateErrorReporting) STD_ZEND_INI_BOOLEAN("zend.enable_gc", "1", ZEND_INI_ALL,OnUpdateGCEnabled, gc_enabled, zend_gc_globals, gc_globals) #ifdef ZEND_MULTIBYTE STD_ZEND_INI_BOOLEAN("detect_unicode", "1", ZEND_INI_ALL, OnUpdateBool,detect_unicode, zend_compiler_globals,
compiler_globals) #endif ZEND_INI_END()
zend.enable_gc对应的操作函数为ZEND_INI_MH(OnUpdateGCEnabled),如果开启了垃圾回收机制, 即GC_G(gc_enabled)为真,则会调⽤gc_init函数执⾏垃圾回收机制的初始化操作。 gc_init函数在zend/zend_gc.c 121⾏,此函数会判断是否开启垃圾回收机制, 如果开启,则初始化整个机制,即直接调⽤malloc给整个缓存列表分配10000个gc_root_buffer内存空间。 这⾥的10000是硬编码在代码中的,以宏GC_ROOT_BUFFER_MAX_ENTRIES存在,如果需要修改这个值,则需要修改源码,重新编译PHP。
gc_init函数在预分配内存后调⽤gc_reset函数重置整个机制⽤到的⼀些全局变量,如设置gc运⾏的次数统计(gc_runs)和gc中垃圾的个数(collected)为0, 设置双向链表头结点的上⼀个结点和下⼀个结点指向⾃⼰等。除了这种提的⼀些⽤于垃圾回收机制的全局变量,还有其它⼀些使⽤较多的变量,部分说明如下:
typedef struct _zend_gc_globals { zend_bool gc_enabled; /* 是否开启垃圾收集机制 */ zend_bool gc_active; /* 是否正在进⾏ */ gc_root_buffer *buf; /* 预分配的缓冲区数组,默认为10000(preallocated arrays of buffers) */ gc_root_buffer roots; /* 列表的根结点(list of possible roots of cycles) */ gc_root_buffer *unused; /* 没有使⽤过的缓冲区列表(list of unused buffers) */ gc_root_buffer *first_unused; /* 指向第⼀个没有使⽤过的缓冲区结点(pointer to first unused buffer) */ gc_root_buffer *last_unused; /* 指向最后⼀个没有使⽤过的缓冲区结点,此处为标记结束⽤(pointer to last unused buffer) */ zval_gc_info *zval_to_free; /* 将要释放的zval变量的临时列表(temporaryt list of zvals to free) */ zval_gc_info *free_list; /* 临时变量,需要释放的列表开头 */ zval_gc_info *next_to_free; /* 临时变量,下⼀个将要释放的变量位置*/ zend_uint gc_runs; /* gc运⾏的次数统计 */ zend_uint collected; /* gc中垃圾的个数 */ // 省略... }
当我们使⽤⼀个unset操作想清除这个变量所占的内存时(可能只是引⽤计数减⼀),会从当前符号的哈希表中删除变量名对应的项, 在所有的操作执⾏完后,并对从符号表中删除的项调⽤⼀个析构函数,临时变量会调⽤zval_dtor,⼀般的变量会调⽤zval_ptr_dtor。
当然我们⽆法在PHP的函数集中找到unset函数,因为它是⼀种语⾔结构。 其对应的中间代码为ZEND_UNSET,在Zend/zend_vm_execute.h⽂件中你可以找到与它相关的实现。
zval_ptr_dtor并不是⼀个函数,只是⼀个长得有点像函数的宏。 在Zend/zend_variables.h⽂件中,这个宏指向函数_zval_ptr_dtor。 在Zend/zend_execute_API.c 424⾏,函数相关代码如下:
ZEND_API void _zval_ptr_dtor(zval **zval_ptr ZEND_FILE_LINE_DC) /* {{{ */ {
#if DEBUG_ZEND>=2 printf("Reducing refcount for %x (%x): %d->%d ", *zval_ptr, zval_ptr,Z_REFCOUNT_PP(zval_ptr), Z_REFCOUNT_PP(zval_ptr) - 1); #endif Z_DELREF_PP(zval_ptr); if (Z_REFCOUNT_PP(zval_ptr) == 0) { TSRMLS_FETCH(); if (*zval_ptr != &EG(uninitialized_zval)) { GC_REMOVE_ZVAL_FROM_BUFFER(*zval_ptr); zval_dtor(*zval_ptr); efree_rel(*zval_ptr); } } else { TSRMLS_FETCH(); if (Z_REFCOUNT_PP(zval_ptr) == 1) { Z_UNSET_ISREF_PP(zval_ptr);
} GC_ZVAL_CHECK_POSSIBLE_ROOT(*zval_ptr); } } /* }}} */
从代码我们可以很清晰的看出这个zval的析构过程,关于引⽤计数字段做了以下两个操作:
- 如果变量的引⽤计数为1,即减⼀后引⽤计数为0,直接清除变量。如果当前变量如果被缓存,则需要清除缓存
- 如果变量的引⽤计数⼤于1,即减⼀后引⽤计数⼤于0,则将变量放⼊垃圾列表。如果变更存在引⽤,则去掉其引⽤。
将变量放⼊垃圾列表的操作是GC_ZVAL_CHECK_POSSIBLE_ROOT,这也是⼀个宏,其对应函数gc_zval_check_possible_root, 但是此函数仅对数组和对象执⾏垃圾回收操作。对于数组和对象变量,它会调⽤gc_zval_possible_root函数。
ZEND_API void gc_zval_possible_root(zval *zv TSRMLS_DC) { if (UNEXPECTED(GC_G(free_list) != NULL && GC_ZVAL_ADDRESS(zv) != NULL && GC_ZVAL_GET_COLOR(zv) == GC_BLACK) && (GC_ZVAL_ADDRESS(zv) < GC_G(buf) || GC_ZVAL_ADDRESS(zv) >= GC_G(last_unused))) { /* The given zval is a garbage that is going to be deleted by * currently running GC */ return; } if (zv->type == IS_OBJECT) { GC_ZOBJ_CHECK_POSSIBLE_ROOT(zv); return; }
GC_BENCH_INC(zval_possible_root); if (GC_ZVAL_GET_COLOR(zv) != GC_PURPLE) { GC_ZVAL_SET_PURPLE(zv); if (!GC_ZVAL_ADDRESS(zv)) { gc_root_buffer *newRoot = GC_G(unused); if (newRoot) { GC_G(unused) = newRoot->prev; } else if (GC_G(first_unused) != GC_G(last_unused)) { newRoot = GC_G(first_unused); GC_G(first_unused)++; } else { if (!GC_G(gc_enabled)) { GC_ZVAL_SET_BLACK(zv); return; } zv->refcount__gc++; gc_collect_cycles(TSRMLS_C); zv->refcount__gc--; newRoot = GC_G(unused); if (!newRoot) { return; } GC_ZVAL_SET_PURPLE(zv); GC_G(unused) = newRoot->prev; } newRoot->next = GC_G(roots).next; newRoot->prev = &GC_G(roots); GC_G(roots).next->prev = newRoot; GC_G(roots).next = newRoot; GC_ZVAL_SET_ADDRESS(zv, newRoot); newRoot->handle = 0; newRoot->u.pz = zv; GC_BENCH_INC(zval_buffered); GC_BENCH_INC(root_buf_length); GC_BENCH_PEAK(root_buf_peak, root_buf_length); } } }
在前⾯说到gc_zval_check_possible_root函数仅对数组和对象执⾏垃圾回收操作,然⽽在gc_zval_possible_root函数中, 针对对象类型的变量会去调⽤GC_ZOBJ_CHECK_POSSIBLE_ROOT宏。⽽对于其它的可⽤于垃圾回收的机制的变量类型其调⽤过程如下:
- 检查zval结点信息是否已经放⼊到结点缓冲区,如果已经放⼊到结点缓冲区,则直接返回,这样可以优化其性能。 然后处理对象结点,直接返回,不再执⾏后⾯的操作
- 判断结点是否已经被标记为紫⾊,如果为紫⾊则不再添加到结点缓冲区,此处在于保证⼀个结点只执⾏⼀次添加到缓冲区的操作。
- 将结点的颜⾊标记为紫⾊,表⽰此结点已经添加到缓冲区,下次不⽤再做添加找出新的结点的位置,如果缓冲区满了,则执⾏垃圾回收操作。
- 将新的结点添加到缓冲区所在的双向链表。
在gc_zval_possible_root函数中,当缓冲区满时,程序调⽤gc_collect_cycles函数,执⾏垃圾回收操
作。 其中最关键的⼏步就是:
- 第628⾏ 此处为其官⽅⽂档中算法的步骤 B ,算法使⽤深度优先搜索查找所有可能的根,找到后将每个变量容器中的引⽤计数减1, 为确保不会对同⼀个变量容器减两次“1”,⽤灰⾊标记已减过1的。
- 第629⾏ 这是算法的步骤 C ,算法再⼀次对每个根节点使⽤深度优先搜索,检查每个变量容器的引⽤计数。 如果引⽤计数是 0 ,变量容器⽤⽩⾊来标记。如果引⽤次数⼤于0,则恢复在这个点上使⽤深度优先搜索⽽将引⽤计数减1的操作(即引⽤计数加1), 然后将它们重新⽤黑⾊标记。
- 第630⾏ 算法的最后⼀步 D ,算法遍历根缓冲区以从那⾥删除变量容器根(zval roots), 同时,检查是否有在上⼀步中被⽩⾊标记的变量容器。每个被⽩⾊标记的变量容器都被清除。 在[gc_collect_cycles() -> gc_collect_roots() -> zval_collect_white() ]中我们可以看到, 对于⽩⾊标记的结点会被添加到全局变量zval_to_free列表中。此列表在后⾯的操作中有⽤到。
PHP的垃圾回收机制在执⾏过程中以四种颜⾊标记状态。
- GC_WHITE ⽩⾊表⽰垃圾
- GC_PURPLE 紫⾊表⽰已放⼊缓冲区
- GC_GREY 灰⾊表⽰已经进⾏了⼀次refcount的减⼀操作
- GC_BLACK 黑⾊是默认颜⾊,正常
相关的标记以及操作代码如下:
#define GC_COLOR 0x03 #define GC_BLACK 0x00 #define GC_WHITE 0x01 #define GC_GREY 0x02 #define GC_PURPLE 0x03 #define GC_ADDRESS(v) ((gc_root_buffer*)(((zend_uintptr_t)(v)) & ~GC_COLOR)) #define GC_SET_ADDRESS(v, a) (v) = ((gc_root_buffer*)((((zend_uintptr_t)(v)) & GC_COLOR) | ((zend_uintptr_t)(a)))) #define GC_GET_COLOR(v) (((zend_uintptr_t)(v)) & GC_COLOR) #define GC_SET_COLOR(v, c) (v) = ((gc_root_buffer*)((((zend_uintptr_t)(v)) & ~GC_COLOR) | (c))) #define GC_SET_BLACK(v) (v) = ((gc_root_buffer*)(((zend_uintptr_t)(v)) & ~GC_COLOR)) #define GC_SET_PURPLE(v)
(v) = ((gc_root_buffer*)(((zend_uintptr_t)(v)) | GC_PURPLE))
以上的这种以位来标记状态的⽅式在PHP的源码中使⽤频率较⾼,如内存管理等都有⽤到, 这是⼀种⽐较⾼效及节省的⽅案。但是在我们做数据库设计时可能对于字段不能使⽤这种⽅式, 应该是以⼀种更加直观,更加具有可读性的⽅式实现。
第五节 内存管理中的缓存
在维基百科中有这样⼀段描述: 凡是位于速度相差较⼤的两种硬件之间的,⽤于协调两者数据传输速度差异的结构,均可称之为Cache。 从最初始的处理器与内存间的Cache开始,都是为了让数据访问的速度适应CPU的处理速度, 其基于的原理是内存中“程序执⾏与数据访问的局域性⾏为”。 同样PHP内存管理
中的缓存也是基于“程序执⾏与数据访问的局域性⾏为”的原理。 引⼊缓存,就是为了减少⼩块内存块的查询次数,为最近访问的数据提供更快的访问⽅式。
PHP将缓存添加到内存管理机制中做了如下⼀些操作:
- 标识缓存和缓存的⼤⼩限制,即何时使⽤缓存,在某些情况下可以以最少的修改禁⽤掉缓存
- 缓存的存储结构,即缓存的存放位置、结构和存放的逻辑
- 初始化缓存
- 获取缓存中内容
- 写⼊缓存
- 释放缓存或者清空缓存列表
⾸先我们看标识缓存和缓存的⼤⼩限制,在PHP内核中,是否使⽤缓存的标识是宏ZEND_MM_CACHE(Zend/zend_alloc.c 400⾏), 缓存的⼤⼩限制与size_t结构⼤⼩有关,假设size_t占4位,则默认情况下,PHP内核给PHP内存管理的限制是128K(32 * 4 * 1024)。 如下所⽰代码:
#define ZEND_MM_NUM_BUCKETS (sizeof(size_t) << 3) #define ZEND_MM_CACHE 1 #define ZEND_MM_CACHE_SIZE (ZEND_MM_NUM_BUCKETS * 4 * 1024)
如果在某些应⽤下需要禁⽤缓存,则将ZEND_MM_CACHE宏设置为0,重新编译PHP即可。 为了实现这个⼀处修改所有地⽅都⽣效的功能,则在每个需要调⽤缓存的地⽅在编译时都会判断ZEND_MM_CACHE是否定义为1。
如果我们启⽤了缓存,则在堆层结构中增加了两个字段:
struct _zend_mm_heap { #if ZEND_MM_CACHE unsigned int cached; // 已缓存元素使⽤内存的总⼤⼩ zend_mm_free_block *cache[ZEND_MM_NUM_BUCKETS]; // 存放被缓存的块 #endif
如上所⽰,cached表⽰已缓存元素使⽤内存的总⼤⼩,zend_mm_free_block结构的数组装载被缓存的块。 在初始化内存管理时,会调⽤zend_mm_init函数。在这个函数中,当缓存启⽤时会初始化上⾯所说的两个字段,如下所⽰:
#if ZEND_MM_CACHE heap->cached = 0; memset(heap->cache, 0, sizeof(heap->cache)); #endif
程序会初始化已缓存元素的总⼤⼩为0,并给存放缓存块的数组分配内存。 初始化之后,如果外部调⽤需要PHP内核分配内存,此时可能会调⽤缓存, 之所以是可能是因为它有⼀个前提条件,即所有的缓存都只⽤于⼩于的内存块的申请。 所谓⼩块的内存块是其真实⼤⼩⼩于ZEND_MM_MAX_SMALL_SIZE(272)的。 ⽐如,在缓存启⽤的情况下,我们申请⼀个100Byte的内存块,则PHP内核会⾸先判断其真实⼤⼩, 并进⼊⼩块内存分配的流程,在此流程中程序会先判断对应⼤⼩的块索引是否存在,如果存在则直接从缓存中返回, 否则继续⾛常规的分配流程。
当⽤户释放内存块空间时,程序最终会调⽤_zend_mm_free_int函数。在此函数中,如果启⽤了缓存并且所释放的是⼩块内存, 并且已分配的缓存⼤⼩⼩于缓存限制⼤⼩时,程序会将释放的块放到缓存列表中。如下代码
#if ZEND_MM_CACHE if (EXPECTED(ZEND_MM_SMALL_SIZE(size)) && EXPECTED(heap->cached < ZEND_MM_CACHE_SIZE)) { size_t index = ZEND_MM_BUCKET_INDEX(size); zend_mm_free_block **cache = &heap->cache[index]; ((zend_mm_free_block*)mm_block)->prev_free_block = *cache; *cache = (zend_mm_free_block*)mm_block; heap->cached += size; ZEND_MM_SET_MAGIC(mm_block, MEM_BLOCK_CACHED); #if ZEND_MM_CACHE_STAT if (++heap->cache_stat[index].count > heap->cache_stat[index].max_count) { heap->cache_stat[index].max_count = heap->cache_stat[index].count; } #endif return; } #endif
当堆的内存溢出时,程序会调⽤zend_mm_free_cache释放缓存中。整个释放的过程是⼀个遍历数组, 对于每个数组的元素程序都遍历其所在链表中在⾃⼰之前的元素,执⾏合并内存操作,减少堆结构中缓存计量数字。 具体实现参见Zend/zend_alloc.c的909⾏。
在上⾯的⼀些零碎的代码块中我们有看到在ZEND_MM_CACHE宏出现时经常会出现ZEND_MM_CACHE_STAT宏。 这个宏是标记是否启⽤缓存统计功能,默认情况下为不启⽤。缓存统计功能也有对应的存储结构,在分配,释放缓存中的值时, 缓存统计功能都会有相应的实现。
第六节 写时复制(Copy On Write)
在开始之前,我们可以先看⼀段简单的代码:
<?php //例⼀ $foo = 1; $bar = $foo; echo $foo + $bar; ?>
执⾏这段代码,会打印出数字2。从内存的⾓度来分析⼀下这段代码“可能”是这样执⾏的: 分配⼀块内存给foo变量,⾥⾯存储⼀个1; 再分配⼀块内存给bar变量,也存⼀个1,最后计算出结果输出。 事实上,我们发现foo和bar变量因为值相同,完全可以使⽤同⼀块内存,这样,内存的使⽤就节省了⼀个1, 并且,还省去了分配内存和管理内存地址的计算开销。 没错,很多涉及到内存管理的系统,都实现了这种相同值共享内存的策略:写时复制。
很多时候,我们会因为⼀些术语⽽对其概念产⽣莫测⾼深的恐惧,⽽其实,他们的基本原理往往⾮常简单。 本⼩节将介绍PHP中写时复制这种策略的实现:
写时复制(Copy on Write,也缩写为COW)的应⽤场景⾮常多, ⽐如Linux中对进程复制中内存使⽤的优化,在各种编程语⾔中,如C++的STL等等中均有类似的应⽤。 COW是常⽤的优化⼿段,可以归类于:资源延迟分配。只有在真正需要使⽤资源时才占⽤资源, 写时复制通常能减少资源的占⽤。
注: 为节省篇幅,下⽂将统⼀使⽤COW来表⽰“写时复制”;
推迟内存复制的优化
正如前⾯所说,PHP中的COW可以简单描述为:如果通过赋值的⽅式赋值给变量时不会申请新内存来存放新变量所保存的值,⽽是简单的通过⼀个计数器来共⽤内存,只有在其中的⼀个引⽤指向变量的值发⽣变化时才申请新空间来保存值内容以减少对内存的占⽤。 在很多场景下PHP都COW进⾏内存的优化。⽐如:变量的多次赋值、函数参数传递,并在函数体内修改实参等。
下⾯让我们看⼀个查看内存的例⼦,可以更容易看到COW在内存使⽤优化⽅⾯的明显作⽤:
<?php //例⼆ $j = 1; var_dump(memory_get_usage()); $tipi = array_fill(0, 100000, 'php-internal'); var_dump(memory_get_usage()); $tipi_copy = $tipi; var_dump(memory_get_usage()); foreach($tipi_copy as $i){ $j += count($i); } var_dump(memory_get_usage()); //-----执⾏结果----- $ php t.php int(630904) int(10479840) int(10479944) int(10480040)
上⾯的代码⽐较典型的突出了COW的作⽤,在数组变量$tipi被赋值给$tipi_copy时, 内存的使⽤并没有⽴刻增加⼀半,在循环遍历数$tipi_copy时也没有发⽣显著变化, 在这⾥$tipi_copy和$tipi变量的数据共同指向同⼀块内存,⽽没有复制。
也就是说,即使我们不使⽤引⽤,⼀个变量被赋值后,只要我们不改变变量的值 ,也不会新申请内存⽤来存放数据。 据此我们很容易就可以想到⼀些COW可以⾮常有效的控制内存使⽤的场景: 只是使⽤变量进⾏计算⽽很少对其进⾏修改操作,如函数参数的传递,⼤数组的复制等等等不需要改变变量值的情形。
复制分离变化的值
多个相同值的变量共⽤同⼀块内存的确节省了内存空间,但变量的值是会发⽣变化的,如果在上⾯的例⼦中, 指向同⼀内存的值发⽣了变化(或者可能发⽣变化),就需要将变化的值“分离”出去,这个“分离”的操作, 就是“复制”。
在PHP中,Zend引擎为了区别同⼀个zval地址是否被多个变量共享,引⼊了ref_count和is_ref两个变量进⾏标识:
ref_count和is_ref是定义于zval结构体中(见第⼀章第⼀⼩节)。is_ref标识是不是⽤户使⽤ & 的强制引⽤;ref_count是引⽤计数,⽤于标识此zval被多少个变量引⽤,即COW的⾃动引⽤,为0时会被销毁;
关于这两个变量的更多内容,跳转阅读:第三章第六节:变量的赋值和销毁的实现。注:由此可见, $a=$b; 与 $a=&$b; 在PHP对内存的使⽤上没有区别(值不变化时);
下⾯我们把例⼆稍做变化:如果$copy的值发⽣了变化,会发⽣什么?:
<?php //例三 //$tipi = array_fill(0, 3, 'php-internal'); //这⾥不再使⽤array_fill来填充 ,为什么? $tipi[0] = 'php-internal'; $tipi[1] = 'php-internal'; $tipi[2] = 'php-internal'; var_dump(memory_get_usage()); $copy = $tipi; xdebug_debug_zval('tipi', 'copy'); var_dump(memory_get_usage()); $copy[0] = 'php-internal'; xdebug_debug_zval('tipi', 'copy'); var_dump(memory_get_usage()); //-----执⾏结果----- $ php t.php int(629384) tipi: (refcount=2, is_ref=0)=array (0 => (refcount=1, is_ref=0)='php-internal', 1 => (refcount=1, is_ref=0)='php-internal', 2 => (refcount=1, is_ref=0)='php-internal') copy: (refcount=2, is_ref=0)=array (0 => (refcount=1, is_ref=0)='php-internal', 1 => (refcount=1, is_ref=0)='php-internal', 2 => (refcount=1, is_ref=0)='php-internal') int(629512) tipi: (refcount=1, is_ref=0)=array (0 => (refcount=1, is_ref=0)='php-internal', 1 => (refcount=2, is_ref=0)='php-internal', 2 => (refcount=2, is_ref=0)='php-internal') copy: (refcount=1, is_ref=0)=array (0 => (refcount=1, is_ref=0)='php-internal', 1 => (refcount=2, is_ref=0)='php-internal', 2 => (refcount=2, is_ref=0)='php-internal') int(630088)
在这个例⼦中,我们可以发现以下特点:
1. $copy = $tipi;这种基本的赋值操作会触发COW的内存“共享”,不会产⽣内存复制;
2. COW的粒度为zval结构,由PHP中变量全部基于zval,所以COW的作⽤范围是全部的变量,⽽对于zval结构体组成的集合(如数组和对象等), 在需要复制内存时,将复杂对象分解为最⼩粒度来处理。这样可以使内存中复杂对象中某⼀部分做修改时, 不必将该对象的所有元素全部“分离复制”出⼀份内存拷贝;
array_fill()填充数组时也采⽤了COW的策略,可能会影响对本例的演⽰,感兴趣的读者可以 阅读:$PHP_SRC/ext/standard/array.c中PHP_FUNCTION(array_fill)的实现。
xdebug_debug_zval()是xdebug扩展中的⼀个函数,⽤于输出变量在zend内部的引⽤信息。如果你没有安装xdebug扩展,也可以使⽤debug_zval_dump()来代替。 参考:http://www.php.net/manual/zh/function.debug-zval-dump.php
实现写时复制
看完上⾯的三个例⼦,相信⼤家也可以了解到PHP中COW的实现原理: PHP中的COW基于引⽤计数ref_count和is_ref实现, 多⼀个变量指针,就将ref_count加1, 反之减去1,减到0就销毁; 同理,多⼀个强制引⽤&,就将is_ref加1,反之减去1。
这⾥有⼀个⽐较典型的例⼦:
<?php //例四 $foo = 1; xdebug_debug_zval('foo'); $bar = $foo; xdebug_debug_zval('foo'); $bar = 2; xdebug_debug_zval('foo'); ?> //-----执⾏结果----- foo: (refcount=1, is_ref=0)=1 foo: (refcount=2, is_ref=0)=1 foo: (refcount=1, is_ref=0)=1
经过前⾯对变量章节的介绍,我们知道当$foo被赋值时,$foo变量的值的只由$foo变量指向。 当$foo的值被赋给$bar时,PHP并没有将内存复制⼀份交给$bar,⽽是把$foo和$bar指向同⼀个地址。 同时引⽤计数增加1,也就是新的2。 随后,我们更改了$bar的值,这时如果直接需该$bar变量指向的内存,则$foo的值也会跟着改变。 这不是我们想要的结果。于是,PHP内核将内存复制出来⼀份,并将其值更新为赋值的:2(这个操作也称为变量分离操作), 同时原$foo变量指向的内存只有$foo指向,所以引⽤计数更新为:refcount=1。
看上去很简单,但由于&运算符的存在,实际的情形要复杂的多。 见下⾯的例⼦:
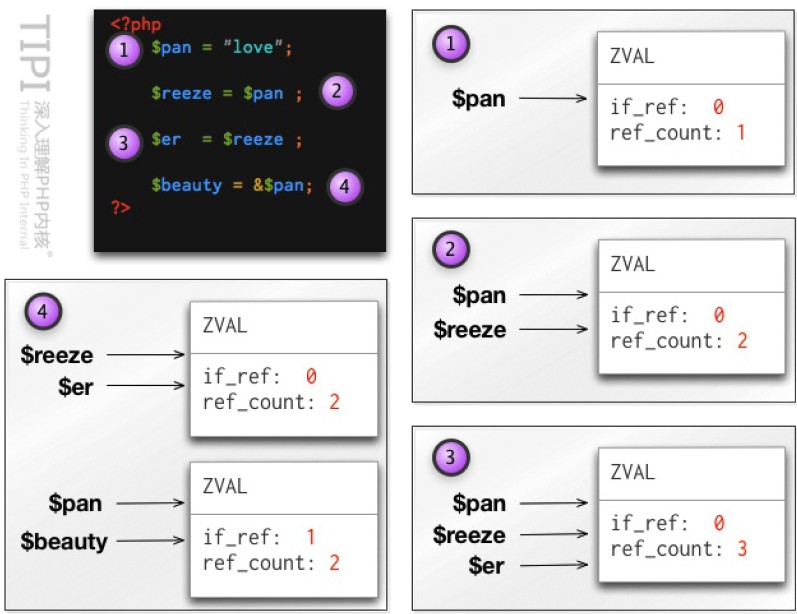
图6.6 &操作符引起的内存复制分离
从这个例⼦可以看出PHP对&运算符的⼀个容易出问题的处理:当 $beauty=&$pan; 时, 两个变量本质上都变成了引⽤类型,导致看上去的普通变量$pan, 在某些内部处理中与&$pan⾏为相同, 尤其是在数组元素中使⽤引⽤变量,很容易引发问题。(见最后的例⼦)
PHP的⼤多数⼯作都是进⾏⽂本处理,⽽变量是载体,不同类型的变量的使⽤贯穿着PHP的⽣命周期, 变量的COW策略也就体现了Zend引擎对变量及其内存处理,具体可以参阅源码⽂件相关的内容:
Zend/zend_execute.c ======================================== zend_assign_to_variable_reference(); zend_assign_to_variable(); zend_assign_to_object(); zend_assign_to_variable(); //以及下列宏定义的使⽤ Zend/zend.h ======================================== #define Z_REFCOUNT(z) Z_REFCOUNT_P(&(z)) #define Z_SET_REFCOUNT(z, rc) Z_SET_REFCOUNT_P(&(z), rc) #define Z_ADDREF(z) Z_ADDREF_P(&(z)) #define Z_DELREF(z) Z_DELREF_P(&(z)) #define Z_ISREF(z) Z_ISREF_P(&(z)) #define Z_SET_ISREF(z) Z_SET_ISREF_P(&(z)) #define Z_UNSET_ISREF(z) Z_UNSET_ISREF_P(&(z)) #define Z_SET_ISREF_TO(z, isref) Z_SET_ISREF_TO_P(&(z), isref)
最后,请慎⽤引⽤&
引⽤和前⾯提到的变量的引⽤计数和PHP中的引⽤并不是同⼀个东⻄, 引⽤和C语⾔中的指针的类似,他们都可以通过不同的标⽰访问到同样的内容, 但是PHP的引⽤则只是简单的变量别名,没有C指令的灵活性和限制。
PHP中有⾮常多让⼈觉得意外的⾏为,有些因为历史原因,不能破坏兼容性⽽选择 暂时不修复,或者有的使⽤场景⽐较少。在PHP中只能尽量的避开这些陷阱。 例如下⾯这个例⼦。
由于引⽤操作符会导致PHP的COW策略优化,所以使⽤引⽤也需要对引⽤的⾏为有明确的认识才不⾄于误⽤, 避免带来⼀些⽐较难以理解的的Bug。如果您认为您已经⾜够了解了PHP中的引⽤,可以尝试解释下⾯这个例⼦:
<?php $foo['love'] = 1; $bar = &$foo['love']; $tipi = $foo; $tipi['love'] = '2'; echo $foo['love'];
这个例⼦最后会输出 2 , ⼤家会⾮常惊讶于$tipi怎么会影响到$foo, $bar变量的引⽤操作,将$foo['love']污染变成了引⽤,从⽽Zend没有 对$tipi['love']的修改产⽣内存的复制分离。
第七节 ⼩结
我们平常在讨论算法时会讲到空间复杂度,⼀般来说这⾥的空间复杂度是指所占内存的⼤⼩。 这就突显了内存管理在我们编程过程中的重要性。从某种意见上来说内存也属于缓存的⼀种, 它的作⽤就是将硬盘或其它较慢存储介质中的数据更快的提供给处理器(或处理器缓存)。
PHP内核以接⼝的⽅式提供了内存管理,将内存管理对PHP内核的其它模块透明,从⽽提供更加⾼效的内存管理,减少内存碎⽚。 在本章,我们从内存管理概述开始,介绍了内存管理的意义及必要性,然后从PHP内存管理的整体结构、内存管理宏的具体实现等⽅⾯做了详细的说明。 并在第四⼩节详细介绍了PHP5.3才引⼊的垃圾收集机制,之后介绍了内存管理中的缓存优化,虽然PHP有实现缓存的统计功能,但是在默认情况下是关闭的, 最后我们以写时复制这样⼀个特性结束了本章。
虽然PHP内核提供了内存管理机制,但是我们也可以通过环境变量设置绕过内存管理直接使⽤某些系统级的内存管理函数。 这适⽤于调试或⼀些特定的应⽤场景,⼀般情况下,我们还是使⽤PHP内核替我们实现的内存管理吧。
下⼀章,我们将介绍PHP的虚拟机。