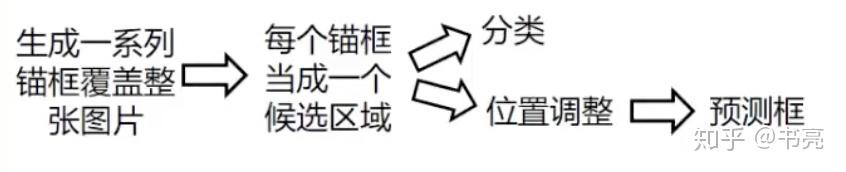
算法分类
两阶段目标检测算法
特征提取 -> 生成 Region Proposal -> 分类 + 位置调整(bounding box regression)
单阶段目标检测算法
特征提取 -> 分类 + 位置调整(bounding box regression)
基础名词
边界框:正好能包含物体的矩形框,bounding box, bbox。
真实框:数据集标注中给出的目标物体对应的边界框, ground truth box, 简称 gt_box。
预测框:由模型预测出的可能包含目标物体的边界框,prediction box, 简称 pred_box。
锚框:以某种规则生成边界框,经过位置调整后成为预测框, anchors。
锚框和真实框的重合程度可以用指标 IOU(Intersection of Union)来衡量。
指标
TP (True Positive): 正确的正样本。即检测器找出了样本区域,正确的判断。
FN (False Negative): 错误的负样本,即检测器把样本区域判定为背景,相当于『遗漏』。
TN (True Negative): 正确的负样本。即检测器把背景判定为背景,正确的判断。
FP (False Positive): 错误的正样本。即检测器把背景判定为样本区域,也叫『虚警』。
Precision - 正确率,也即检测结果的正确率:
[Precision=frac{TP}{TP+FP} ]Recall - 召回率,也即样本被检测出来的概率:
[Recall=frac{TP}{TP+FN} ]
判断检测器的优劣
每个框的输出如下
confidence 代表当前框是目标的置信度,(0<confidence<1)
PR曲线
threshold:阈值
调整(threshold),计算不同(threshold)下检测器的的 Precison 和 Recall 值,然后连接成曲线,就是 PR 曲线。
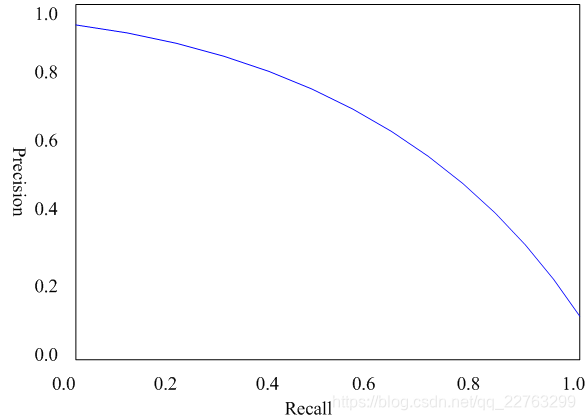
从积分的角度来看,PR 曲线下的面积就是检测器在各个(threshold)下的 AP(Average Precision)。
P-R曲线的总体趋势是,精度越高,召回越低,当召回到达1时,对应概率分数最低的正样本,这个时候正样本数量除以所有大于等于该阈值的样本数量就是最低的精度值。 另外,P-R曲线围起来的面积就是AP值,通常来说一个越好的分类器,AP值越高。
mAP
关于多类别检测器,考虑 mAP (mean Average Precision):
NMS
NMS(None Maximum Suppression),又名为非极大值抑制,是目标检测框架种的后处理模块,主要用于删除高度冗余的 bbox。
感受野——receptive field(RF)
在典型CNN结构中,FC层每个输出节点的值都依赖FC层所有输入,而CONV层每个输出节点的值仅依赖CONV层输入的一个区域,这个区域之外的其他输入值都不会影响输出值,该区域就是感受野。
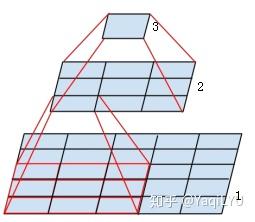
图中是个微型CNN,来自Inception-v3论文,原图是为了说明一个conv(5 imes5)可以用两个conv(3 imes3)代替,从下到上称为第1, 2, 3层:
- 第2层左下角的值,是第1层左下红框中(3 imes3)区域的值经过卷积,也就是乘加运算计算出来的,即第2层左下角位置的感受野是第1层左下红框区域
- 第3层唯一值,是第2层所有(3 imes3)区域卷积得到的,即第3层唯一位置的感受野是第2层所有(3 imes3)区域
- 第3层唯一值,是第1层所有(5 imes5)区域经过两层卷积得到的,即第3层唯一位置的感受野是第1层所有(5 imes5)区域
就是这么简单,某一层feature map(特性图——输入经过一个卷积核的计算后的输出就是一个feature map)中某个位置的特征向量,是由前面某一层固定区域的输入计算出来的,那这个区域就是这个位置的感受野。任意两个层之间都有位置—感受野对应关系,但我们更常用的是feature map层到输入图像的感受野,如目标检测中我们需要知道feature map层每个位置的特征向量对应输入图像哪个区域,以便我们在这个区域中设置anchor,检测该区域内的目标。
感受野区域之外图像区域的像素不会影响feature map层的特征向量,所以我们不太可能让CNN仅依赖某个特征向量去找到其对应输入感受野之外的目标。这里说“不太可能”而不是“绝无可能”,是因为CNN很强大,且图像像素之间有相关性,有时候感受野之外的目标是可以猜出来的,什么一叶知秋,管中窥豹,见微知著之类,对CNN目标检测都是有可能的,但猜出来的结果并不总是那么靠谱。
感受野有什么用呢?
- 一般task要求感受野越大越好,如图像分类中最后卷积层的感受野要大于输入图像,网络深度越深感受野越大性能越好
- 密集预测task要求输出像素的感受野足够的大,确保做出决策时没有忽略重要信息,一般也是越深越好
- 目标检测task中设置anchor要严格对应感受野,anchor太大或偏离感受野都会严重影响检测性能
感受野的计算
我们首先介绍一种从后向前计算方法,极其简单适合人脑计算,看看网络结构就知道感受野了,之后介绍一种通用的从前往后计算方法,比较规律适合电脑计算,简单编程就可以计算出感受野大小和位置。
感受野是一个矩形区域,如果卷积核全都长宽相等,则对应感受野就是正方形区域。输出feature map中每个位置都对应输入图像一个感受野区域,所有位置的感受野在输入图像上以固定步进的方式平铺。
我们要计算感受野的大小(r)(长或宽)和不同区域之间的步进S,从前往后的方法以感受野中心((x,y))的方式确定位置,从后往前的方法以等效padding P的方式确定位置。CNN的不同卷积层,用k表示卷积核大小,s表示步进((s1)表示步进是1,(s2)表示步进是2),下标表示层数。
从后往前计算——适合理解
从后往前的计算方式的出发点是:一个conv(5 imes5)的感受野等于堆叠两个conv(3 imes3),反之两个堆叠的conv(3 imes3)感受野等于一个conv(5 imes5),推广之,一个多层卷积构成的FCN感受野等于一个conv (r imes r),即一个卷积核很大的单层卷积,其kernelsize=r,padding=P,stride=S。
(如果我们将一个Deep ConvNet从GAP处分成两部分,看成是FCN (全卷积网络)+MLP (多层感知机),从感受野角度看FCN等价于一个单层卷积提取特征,之后特征经MLP得到预测结果,这个单层卷积也就比Sobel复杂一点,这个MLP可能还没SVM高端,CNN是不是就没那么神秘了~)
以下是一些显(bu)而(hui)易(zheng)见(ming)的结论:
- 初始feature map层的感受野是1
- 每经过一个conv(k imes k) s1的卷积层,感受野$ r = r + (k - 1)$,常用k=3感受野 (r = r + 2), k=5感受野(r = r + 4)
- 每经过一个conv(k imes k) s2的卷积层或max/avg pooling层,感受野 (r = (r imes 2) + (k -2)),常用卷积核k=3, s=2,感受野 (r = r imes 2 + 1),卷积核k=7, s=2, 感受野(r = r imes 2 + 5)
- 每经过一个maxpool(2 imes 2) s2的max/avg pooling下采样层,感受野 (r = r imes 2)
- 特殊情况,经过conv(1 imes 1) s1不会改变感受野,经过FC层和GAP层,感受野就是整个输入图像
- 经过多分枝的路径,按照感受野最大支路计算,shotcut也一样所以不会改变感受野
- ReLU, BN,dropout等元素级操作不会影响感受野
- 全局步进等于经过所有层的步进累乘,(S=s_{-1}cdot s_{-2}cdot s_{-3}cdot ...cdot s_1)
- 经过的所有层所加padding都可以等效加在输入图像,等效值(P),直接用卷积的输入输出公式(f_{out}=(f_{in}-r+2P)/S+1) 反推出(P)即可
这种计算方法有多简单呢?我们来计算目标检测中最常用的两个backbone的感受野。最初版本SSD和Faster R-CNN的backbone都是VGG-16,结构特点卷积层都是conv(3 imes 3) s1,下采样层都是maxpool(2 imes 2) s2。先来计算SSD中第一个feature map输出层的感受野,结构是conv4-3 (第4块的第3卷积层) backbone + conv(3 imes 3) classifier (为了写起来简单省掉了左边括号):
r = 1 +2 +2+2+2 )x2 +2+2+2 )x2 +2+2 )x2 +2+2 = 108
S = 2x2x2 = 8
P = floor(r/2 - 0.5) = 53
以上结果表示感受野的分布方式是:在paddding=53(上下左右都加) 的输入(224 imes 224)图像上,大小为(108 imes 108)的正方形感受野区域以stride=8平铺。
再来计算Faster R-CNN中conv5-3(第5块的第3卷积层) +RPN的感受野,RPN的结构是一个conv(3 imes 3)+两个并列conv(1 imes 1):
r = 1 +2 +2+2+2 )x2 +2+2+2 )x2 +2+2+2 )x2 +2+2 )x2 +2+2 = 228
S = 2x2x2x2 = 16
P =floor(r/2 - 0.5) = 113
分布方式为在paddding=113的输入(224 imes 224)图像上,大小为(228 imes 228)的正方形感受野区域以stride=16平铺。
接下来是Faster R-CNN+++和R-FCN等采用的重要backbone的ResNet,常见ResNet-50和ResNet-101,结构特点是block由conv(1 imes 1)+conv(3 imes 3)+conv(1 imes 1)构成,下采样block中conv(3 imes 3) s2影响感受野。先计算ResNet-50在conv4-6 + RPN的感受野 (为了写起来简单堆叠卷积层合并在一起):
r = 1 +2 +2x5 )x2+1 +2x3 )x2+1 +2x3 )x2+1 )x2+5 = 299
S = 2x2x2x2 = 16
P = floor(r/2 - 0.5) = 149
P不是整数,表示conv$7 imes 7 $s2卷积有多余部分。分布方式为在paddding=149的输入(224 imes 224)图像上,大小为(299 imes 299)的正方形感受野区域以stride=16平铺。
ResNet-101在conv4-23 + RPN的感受野:
r = 1 +2 +2x22 )x2+1 +2x3 )x2+1 +2x3 )x2+1 )x2+5 = 843
S = 2x2x2x2 = 16
P = floor(r/2 - 0.5) = 421
分布方式为在paddding=421的输入(224 imes 224)图像上,大小为(843 imes 843)的正方形感受野区域以stride=16平铺。
以上结果都可以反推验证,并且与后一种方法结果一致。从以上计算可以发现一些的结论:
- 步进1的卷积层线性增加感受野,深度网络可以通过堆叠多层卷积增加感受野
- 步进2的下采样层乘性增加感受野,但受限于输入分辨率不能随意增加
- 步进1的卷积层加在网络后面位置,会比加在前面位置增加更多感受野,如stage4加卷积层比stage3的感受野增加更多
- 深度CNN的感受野往往是大于输入分辨率的,如上面ResNet-101的843比输入分辨率大3.7倍
- 深度CNN为保持分辨率每个conv都要加padding,所以等效到输入图像的padding非常大
从前往后计算——适合编程
上式中n是feature map的大小,p是padding,k是kernel size,j是jump(前面的S),r是感受野大小,start是第一个特征向量(左上角位置)对应感受野的中心坐标位置。搬运并翻译:
- 公式一是通用计算卷积层输入输出特征图大小的标准公式
- 公式二计算输出特征图的jump,等于输入特征图的jump乘当前卷积层的步进s
- 公式三计算感受野大小,等于输入感受野加当前层的卷积影响因子(k - 1) * jin,注意这里与当前层的步进s没有关系
- 公式四计算输出特征图左上角位置第一个特征向量,对应输入图像感受野的中心位置,注意这里与padding有关系
从以上公式可以看出:start起始值为0.5,经过k=3, p=1时不变,经过k=5, p=2时不变。
计算示例:
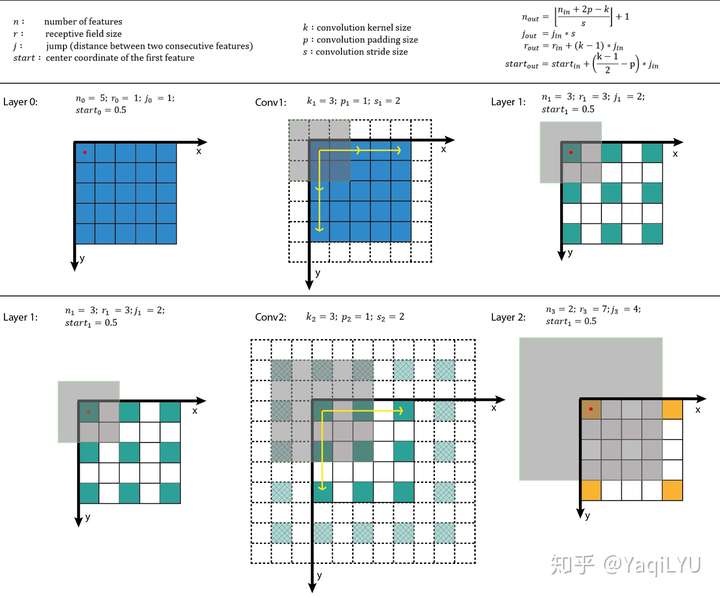
计算出r, j和start之后,所有位置感受野的大小都是r,其他位置的感受野中心是start按照j滑窗得到。这种方法比较规律,推荐编程实现。
有效感受野
NIPS 2016论文Understanding the Effective Receptive Field in Deep Convolutional Neural Networks提出了有效感受野(Effective Receptive Field, ERF)理论,论文发现并不是感受野内所有像素对输出向量的贡献相同,在很多情况下感受野区域内像素的影响分布是高斯,有效感受野仅占理论感受野的一部分,且高斯分布从中心到边缘快速衰减,下图第二个是训练后CNN的典型有效感受野。

这点其实也很好理解,继续回到最初那个微型CNN,我们来分析第1层,下图标出了conv3x3 s1卷积操作对每个输入值的使用次数,用蓝色数字表示,很明显越靠近感受野中心的值被使用次数越多,靠近边缘的值使用次数越少。5x5输入是特殊情况刚好符合高斯分布,3x3输入时所有值的使用次数都是1,大于5x5输入时大部分位于中心区域的值使用次数都是9,边缘衰减到1。每个卷积层都有这种规律,经过多层堆叠,总体感受野就会呈现高斯分布。
ECCV2016的SSD论文指出更好的anchar的设置应该对齐感受野:

锚框——Anchor
引例
在理解目标检测的锚框之前,我们首先通过一个不太严谨的例子对锚框进行一个简单的了解:
由于目前污染比较严重,导致海洋中漂浮着许多垃圾,这些垃圾既污染环境,又不利于鱼类的生存。假设我们面前有一片海域,海域中零星地漂浮着很多不同类型的垃圾,这些垃圾有的大,有的小,有的是方形的,有的是长条形的。为了保护环境,我们需要将所有的垃圾打捞起来,还海洋生物一个美好家园。
为此,我们设计了一种打捞机器,该机器能够在一定范围内撒下网,进行垃圾打捞,且只有一定大小的网能够打捞到对应一定大小的垃圾,这里我们认为当网与垃圾的IoU小于0.5时,该区域不存在垃圾;网与垃圾的IoU大于0.5时,该区域存在垃圾,当然该机器能够对网进行后续的调整(调整网的位置,形状)。
由于该机器有些简陋,无法智能识别该海域中哪个区域包含垃圾,为了能够尽可能的打捞到所有的垃圾,我们需要在这片海域的不同位置下网,进行垃圾的打捞,且为了打捞不同类型的垃圾,我们需要在同一位置下多个不同形状(不同大小,不同长宽比)的网。实际上,我们希望既能打捞到所有的垃圾,同时我们又希望能够下最少的网,减少工作量。
锚框
对应到目标检测任务
- 海域相当于网络的输入图像
- 不同类型的垃圾,对应不同类型的目标类别
- 在海域上抛下的网相当于锚框,通过锚框来判断该区域中是否包含目标
首先预设一组不同尺度不同位置的固定参考框,覆盖几乎所有位置和尺度,每个参考框负责检测与其交并比大于阈值 (训练预设值,常用0.5或0.7) 的目标,anchor技术将问题转换为"这个固定参考框中有没有认识的目标,目标框偏离参考框多远",不再需要多尺度遍历滑窗,真正实现了又好又快,如在Faster R-CNN和SSD两大主流目标检测框架及扩展算法中anchor都是重要部分。
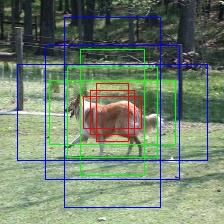
不同尺度的锚框
在引例我们说到,为了打捞不同类型的垃圾,我们需要在同一位置下多个不同形状(不同大小,不同长宽比)的网。同样在目标检测中,在图中的同一个位置,我们会设置几个不同尺度的锚框。
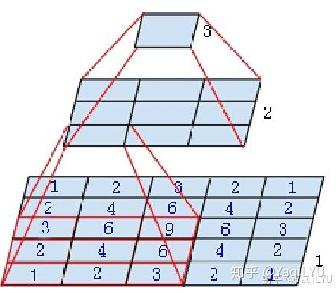
先验框与特征图的对应
在引例我们说到,我们需要在海域的不同位置下网,进行垃圾的打捞。同样在目标检测中,需要在图片的不同位置上设置锚框。
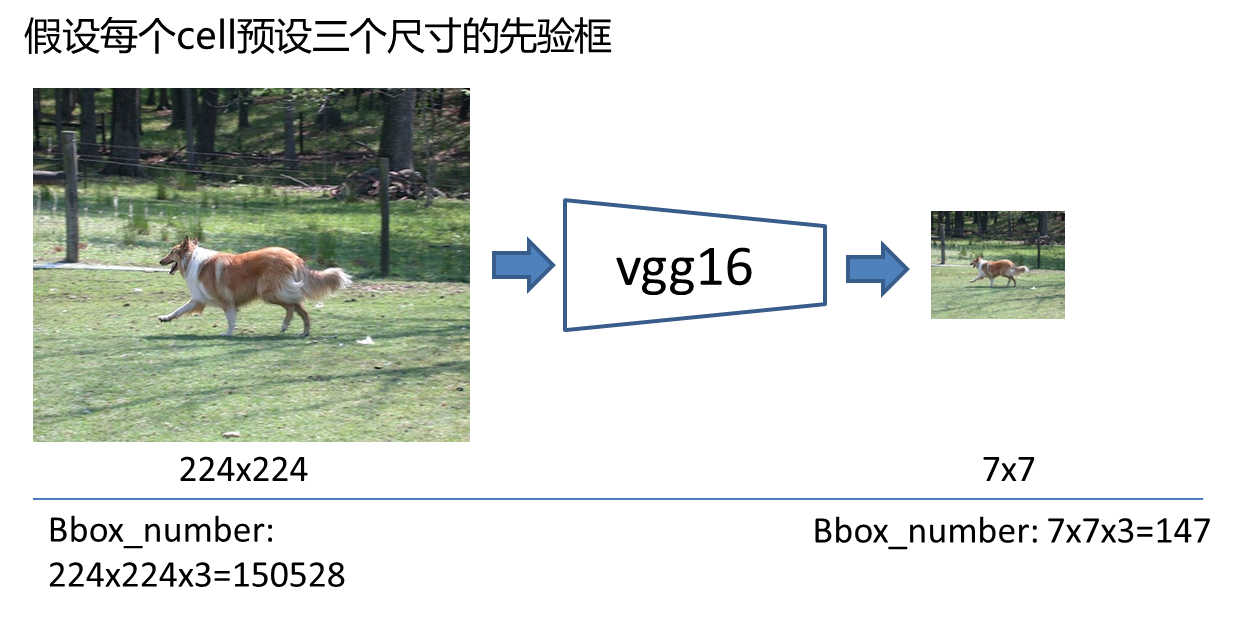
但是实际上如果遍历原图每个像素,设置的锚框就太多了,完全没必要。假设一个(224 imes224)的图片,每个位置设置3个不同尺寸的锚框,那么就有(224 imes224 imes3=150528)个,但是如果我们不去遍历原图,而是去遍历原图对应的feature map呢?以vgg16的backbone为例,下采样了5次,得到(7 imes7)的feature map,那就只需要得到(7 imes7 imes3=147)个先验,这样的设置大大减少了锚框的数量,同时也能覆盖大多数情况。
因此,我们就将锚框的设置位置与特征图建立一一对应的关系。而且,通过建立这种映射关系,我们可以通过特征图,直接一次性的输出所有先验框的类别信息以及坐标信息,而不是想前面一直描述的那样,每个候选框都去独立的进行一次分类的预测,这样太慢了
锚框类别信息的确定
在目标检测中,我们先设置了许多锚框,我们先要给出这些锚框的类别信息,才能让模型学着去预测每个先验框是否对应着一个目标物体。
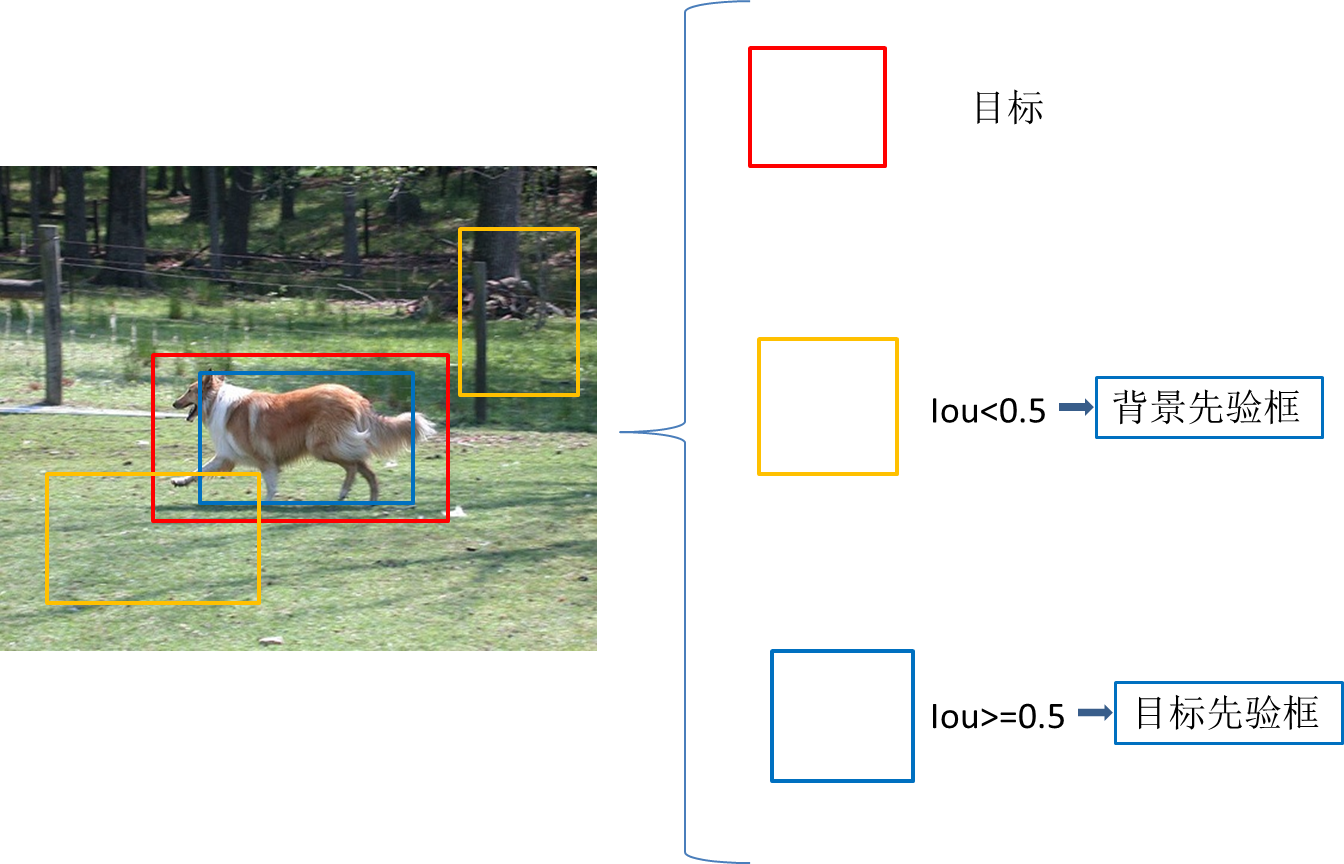
这些锚框中有很多是和图片中我们要检测的目标完全没有交集或者有很小的交集,
我们的做法是,设定一个IoU阈值,例如iou=0.5,与图片中目标的iou<0.5的先验框,这些框我们将其划分为背景,Iou>=0.5的被归到目标先验框,通过这样划分,得到供模型学习的ground truth信息。
锚框生成
"""
设置细节介绍:
1. 离散程度 fmap_dims = 7: VGG16最后的特征图尺寸为 7*7
2. 在上面的举例中我们是假设了三种尺寸的先验框,然后遍历坐标。在先验框生成过程中,先验框的尺寸是提前设置好的,
本教程为特征图上每一个cell定义了共9种不同大小和形状的候选框(3种尺度*3种长宽比=9)
生成过程:
0. cx, cy表示中心点坐标
1. 遍历特征图上每一个cell,i+0.5是为了从坐标点移动至cell中心,/fmap_dims目的是将坐标在特征图上归一化
2. 这个时候我们已经可以在每个cell上各生成一个框了,但是这个不是我们需要的,我们称之为base_prior_bbox基准框。
3. 根据我们在每个cell上得到的长宽比1:1的基准框,结合我们设置的3种尺度obj_scales和3种长宽比aspect_ratios就得到了每个cell的9个先验框。
4. 最终结果保存在prior_boxes中并返回。
需要注意的是,这个时候我们的到的先验框是针对特征图的尺寸并归一化的,因此要映射到原图计算IOU或者展示,需要:
img_prior_boxes = prior_boxes * 图像尺寸
"""
def create_prior_boxes():
"""
Create the 441 prior (default) boxes for the network, as described in the tutorial.
VGG16最后的特征图尺寸为 7*7
我们为特征图上每一个cell定义了共9种不同大小和形状的候选框(3种尺度*3种长宽比=9)
因此总的候选框个数 = 7 * 7 * 9 = 441
:return: prior boxes in center-size coordinates, a tensor of dimensions (441, 4)
"""
fmap_dims = 7
obj_scales = [0.2, 0.4, 0.6]
aspect_ratios = [1., 2., 0.5]
prior_boxes = []
for i in range(fmap_dims):
for j in range(fmap_dims):
cx = (j + 0.5) / fmap_dims
cy = (i + 0.5) / fmap_dims
for obj_scale in obj_scales:
for ratio in aspect_ratios:
prior_boxes.append([cx, cy, obj_scale * sqrt(ratio), obj_scale / sqrt(ratio)])
prior_boxes = torch.FloatTensor(prior_boxes).to(device) # (441, 4)
prior_boxes.clamp_(0, 1) # (441, 4)
return prior_boxes
Faster R-CNN中的Anchor
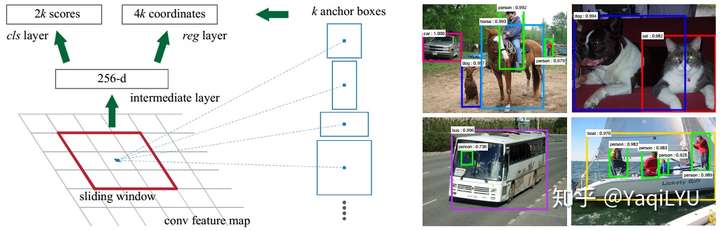
Faster R-CNN这里仅分析与anchor有关的VGG16+RPN部分(后面简称RPN):主干输出stride16的feature map,RPN是一个conv3x3+两个并列的conv1x1,一边预测anchor中是否包含目标,一边预测目标框偏离固定anchor多远。
设置:RPN用stride 16的单feature map进行预测,anchor为三尺度{128, 256, 512}三比例{1:1, 1:2, 2:1},feature map上每个位置设置9个参考anchor,这些大约能覆盖边长70~768的目标。下图是Faster R-CNN论文中个anchor形状训练后学习到的平均proposal大小。
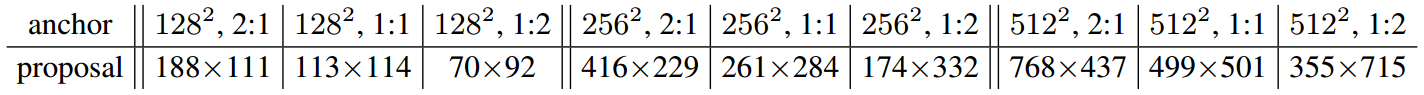
感受野:典型1000x600输入图像,经过conv5-3 + RPN,用于预测的feature map层分辨率是63x38,计算这一层的感受野:
r = 1 + 2 + 2x3 )x2 + 2x3 )x2 + 2x3 )x2 + 2x2 )x2 + 2x2 = 228 < 512
分析:Faster R-CNN最早提出了anchor概念,首先,backbone+RPN实质上是一个FCN,上一篇分析过FCN本质上是密集滑窗,所以就没必要显式密集滑窗了;其次,anchor的设置是多尺度的,这样就没必要显式图像金字塔;最后,RPN与检测网络共享backbone部分的计算量,能大幅提升速度;注意,输入图像大小相比后面的SSD(512x512)更大,相当于小目标放大去检测,性能会有提升,但这是牺牲速度换来的。
Anchor设置方面有三个问题(从今天的算法水平往回看,事后诸葛角度):
- 最小的anchor是128x128尺度,而COCO小目标很多,且小目标很小,远小于这个尺度,为了能检测这些小目标,Faster R-CNN不得不放大输入图像(~1000x600),导致计算速度成倍增加,而同时被放大的大目标可能超过最大anchor尺度,又不得不加入多尺度测试保证从大到小anchor全覆盖,进一步影响速度;
- 最大的anchor是512x512尺度,而预测层的感受野仅228,上一篇讨论过,一般来说感受野一定要大于anchor大小,而且越大越好,这里感受野明显不足以支撑最大尺度的anchor,导致大尺度目标检测性能不够好;
- 三尺度按照检测目标的大小,我们简称为大、中、小锚框,那么三个尺度的anchor分别有63x38x3=7182个,共计7182x3=21546个anchor。通常anchor需要覆盖训练集的所有目标,即每个groundtruth box都能匹配到一个anchor,因此理想情况下目标越小anchor应该越多越密集,才能覆盖所有的候选区域,目标越大anchor应该越少越稀疏,否则互相高度重叠造成冗余计算量,反观RPN这里的单一feature map三尺度三比例设置,导致检测小目标的anchor太少太疏,而检测大目标的anchor太多太密。论文提到Faster R-CNN训练中忽略了所有跨边界的anchor否则训练无法收敛,尺度越大跨边界越多,所以训练中忽略掉的很多都是大锚框。
SSD中的Anchor
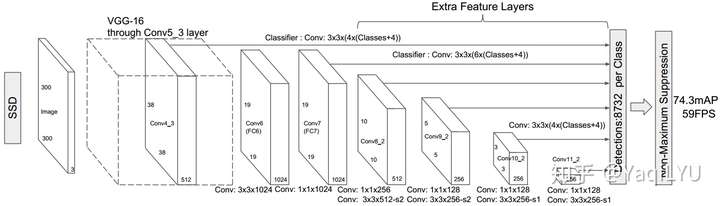
SSD是VGG16+conv3x3进行检测,输出目标分类和边框回归结果,从6个stride递增的feature map进行预测,网络结构从conv7之前是标准的VGG16结构,之后每一组conv1x1 + conv3x3s2输出一个stride的feature map。
设置:feature map从stride8开始共6层,每层4或6个形状的anchor,anchor共6个尺度(0.2~0.9)x300,6个形状是{1, 2, 3, 1/2, 1/3}比例框,外加较大的{1}比例框,依然按照大、中、小锚框进行划分,典型300x300输入图像:
- 小锚框:从{conv4_3} feature map检测单一小尺度{60}目标,4个anchor形状,共38x38x4=5776个anchor;
- 中锚框:从{conv7, conv8_2, conv9_2} feature map检测三个中尺度{102, 144, 186}目标,6形状anchor,共19x19x6 + 10x10x6 + 5x5x6=2916个anchor;
- 大锚框:从{conv10_2, conv11_2}检测两个大尺度{228, 270}目标,4形状anchor,共3x3x4 + 1x1x4=40个anchor;
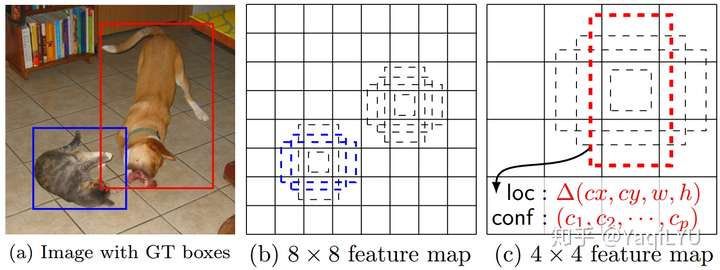
感受野:计算conv4-3+conv3x3 ~ conv11_2+conv3x3的感受野
r1 = 1 + 2 + 2x3 )x2 + 2x3 )x2 + 2x2 )x2 + 2x2 = 108 > 60
r2 = 1 + 2 + 2 + 2x3 )x2 + 2x3 )x2 + 2x3 )x2 + 2x2 )x2 + 2x2 = 260 > 102
r3 = 1 + 2 )x2+1 + 2 + 2x3 )x2 + 2x3 )x2 + 2x3 )x2 + 2x2 )x2 + 2x2 = 324 > 144
r3 = 1 + 2 )x2+1 )x2+1 + 2 + 2x3 )x2 + 2x3 )x2 + 2x3 )x2 + 2x2 )x2 + 2x2 = 452 > 186
...
可以看到各层的感受野都是大于anchor大小的。
分析:6个feature map共计5776 + 2916 + 40=8732个anchor,总数量比RPN少了很多,而且小尺度锚框多且密,大尺度锚框少且疏,更合理;anchor的尺度范围从60到284,输入图像不用故意放大去检测小目标,计算速度更快;大尺度分布合理,不忽略跨边界anchor训练结果更好。
Anchor设置方面有三个问题(继续马后炮角度):
- 论文中提到的anchor设置没有对齐感受野,通常几个像素的中心位置偏移,对大目标来说IOU变化不会很大,但对小目标IOU变化剧烈,尤其感受野不够大的时候,anchor很可能偏移出感受野区域,影响性能。

- 还是论文中提到的,anchor尺度和比例都是人工给定的,尺度和比例必须要覆盖相应任务的可能出现的所有目标,如PASCAL VOC评价每图目标数较少、目标较大,所以SSD中最小60x60的anchor或许够用,但MS COCO中目标密集且小、数量多,对anchor的密度和最小尺度都有严格要求,60x60的最小框完全不够看,只能放大输入图像。

一种方法是针对特定数据集设计anchor,如YOLOv2中的聚类,和近期有论文CNN训练anchor的设置,这些方法或许更适合某一数据集,但也可能影响模型的泛化能力,换一个库是否依然够用。另一种方法就是多尺度测试,尺度不够,缩放来凑,常用multi-test,和SNIP等等方法,都牺牲了速度,实用性打折。
- 深度悖论(杜撰):SSD检测小目标是从conv4-3拉出来的,共经过11个conv3x3,检测中目标是从{conv7, conv8_2, conv9_2}拉出来的,分别经过{15, 16, 17}个conv3x3,检测大目标经过的卷积层就更多了,一般经过的conv3x3越多,深度越深,感受野越大,特征越强 (这一说法有否正确?)。
一般来说,目标越小,像素数量少,清晰度低,细节丢失严重,检测难度越大,反之目标越大,检测难度越小。RPN框架检测各尺度的特征深度相同,但SSD框架目标越小越难的,特征深度反而越浅,特征越弱。
- 继续来看最小anchor不够小的问题:我们能否将stride4的feature map拉出来,设置更小anchor检测比60更小的目标呢?实际操作当然可行,我们将conv3_3的feature map上加一个检测头,假设anchor设置为{30},计算这一层感受野,看看能支持多小目标:
r0 = 1 + 2 + 2x3 )x2 + 2x2 )x2 + 2x2 = 48 > 30
直观来看conv3_3可以支持这一anchor,但小目标更需要大感受野来提供上下文信息,如果感受野太小误检率会非常高。
FPN中的Anchor
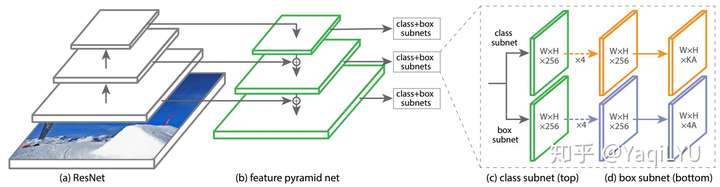
设置:FPN + ResNet标配后,Faster R-CNN和SSD分别进化为Faster R-CNN+FPN/Mask R-CNN(简写FPN)和RetinaNet,Pn表示对应feature map的stride是 ,尺度都是 {32, 64, 128, 256, 512}:不同点是:
- FPN从 {P2, P3, P4, P5, P6} 拉出5个feature map进行检测,每个位置预测三比例,不同尺度不同形状的anchor共15个
- RetinaNet从 {P3, P4, P5, P6, P7} 拉出5个feature map进行检测,每个位置预测三尺度三比例,每个尺度预测9个形状anchor
感受野:首先忽略FPN的top-down pathway,考虑RPN中的conv3x3卷积层,直接计算ResNet-50各个feature map的感受野,{P2, P3, P4, P5}分别对应{conv2_3, conv3_4, conv4_6, conv5_3}:
P2 = 1 +2 +2x3 )x2+1 )x2+5 = 43
P3 = 1 +2 +2x3 )x2+1 +2x3 )x2+1 )x2+5 = 107
P4 = 1 +2 +2x5 )x2+1 +2x3 )x2+1 +2x3 )x2+1 )x2+5 = 299
P5 = 1 +2 +2x2 )x2+1 +2x5 )x2+1 +2x3 )x2+1 +2x3 )x2+1 )x2+5 = 491
随着block增加,感受野也对应越多,如果考虑检测需要上下文,stride32的感受野足够大,但stride4的感受野不够大。FPN中的bottom-up pathway将深度层特征上采样后与当前层相加,相加时感受野取最大,即相加后感受野等于深度层的感受野,FPN仅用微小计算量,实现了浅层feature map的感受野大幅提升,高效解决了“深度悖论”,目前是目标检测的标配。
分析:同样尺度为32的anchor,FPN用P2进行检测,而RetinaNet用P3进行检测,这是因为FPN的前景阈值是0.7需要anchor更密集,RetinaNet前景阈值是0.5 anchor相对稀疏,FPN技术继承了前面SSD的所有优点,还以极低计算量克服了浅层感受野不足的问题。
Anchor设置方面的问题(这么完美还有问题? 后面全是瞎说):
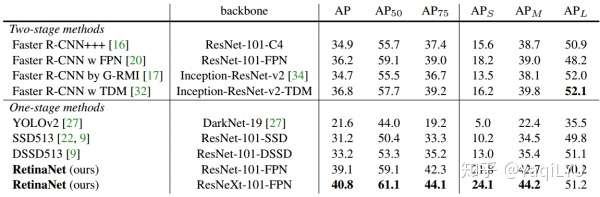
- 小框的问题:MS COCO上数据库上小目标的AP(S)远低于大目标的AP(L),如下表,从anchor角度来看可能是两方面的问题:
- 来自高层的feature map上采样用了最简单的最近邻插值,太过于粗糙,而且高层特征训练用于检测大目标,可能已经丢失了小目标相关的语义
- 低层自己的feature map感受野本来比较小,缺乏上下文信息
实验:某直筒型检测网络,用stride4的feature map层设置16x16的anchor检测小目标,为了提高小目标的检测性能,采用两种不同方法增加感受野
- stride4加深度(加2个conv3x3卷积层)
- 加入FPN技术,用P2层进行检测
实现发现第一种方法对小目标检测的提升更大,但第一种方法由于分辨率较大引入了很多额外计算量,模型大小和训练所需内测都大幅上升,相反第二种方法额外计算量非常少,在速度方面优势非常大。
- 大框的问题:用大stride层的feature map检测大目标,步进等于stride,anchor数量少且疏,造成边框回归的难度增加,而且感官上更容易看到大目标的检测偏差。
为了提高高层feature map的分辨率,近期很多论文都在stride16之后用空洞卷积代替下采样block,在提高感受野的同时保持空间分辨率不下降,以获得更密集的大目标anchor,提升大目标的检测性能。空洞卷积的理论计算量与标准卷积相同但更难优化,如果采用空洞卷积则通道数不用翻倍,否则速度无法接受。
Anchor设计总结
总结以上几篇论文,设计目标检测算法时,anchor设置应该考虑一下几个方面 (以RetinaNet为例):
- anchor的密度:由检测所用feature map的stride决定,这个值与前景阈值密切相关,如同样检测{32}尺度,FPN阈值0.7用P2,RetinaNet前景阈值0.5用P3。
- anchor的范围:RetinaNet中是anchor范围是32~512,这里应根据任务检测目标的范围确定,按需调整anchor范围,或目标变化范围太大如MS COCO,这时候应采用多尺度测试,当然,实际应用中需考虑多尺度测试的复杂度问题。
- anchor的形状数量:RetinaNet每个位置预测三尺度三比例共9个形状的anchor,这样可以增加anchor的密度,但stride决定这些形状都是同样的滑窗步进,需考虑步进会不会太大,如RetinaNet框架前景阈值是0.5时,一般anchor大小是stride的4倍左右。
- 检测层Pn的数量:RetinaNet中是P3~P7共5个检测层,如需检测更小的目标,可以考虑加入P2检测层。
- 检测层Pn的感受野:前面计算了RetinaNet中是ResNet+FPN的感受野在检测中、大目标时都是够用的,检测小目标时略显疲乏,kaiming最新论文《Rethinking ImageNet Pre-training》既然告诉我们预训练模型没那么重要时,那检测任务就可以着重考虑按照感受野的需求设计ConvNet。
总之,要做到anchor以足够密度实现全覆盖。
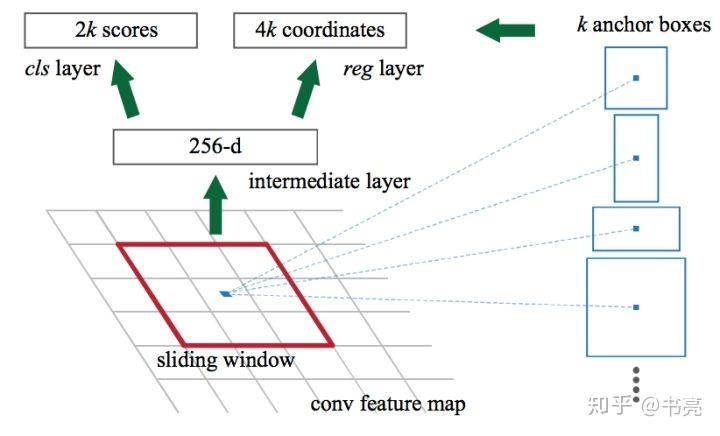
候选区域网络——Region Proposal Network(RPN)
经典的检测方法生成检测框都非常耗时,Faster-RCNN 首创直接使用 RPN 生成检测框,能极大提升检测框的生成速度。RPN (Region Proposal Network) 用于生成候选区域(Region Proposal)。
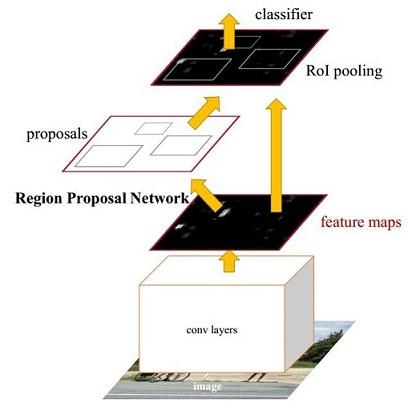
RPN 的输入为 backbone (VGG16, ResNet, etc) 的输出(简称 feature maps)。
作为初学者,在学习 RPN 之前,我遇到过以下几个疑问:
- RPN 是如何由 feature maps 来产生边界框(bounding boxes) ?
- 什么是 anchors?
- anchors 是如何 reshape 成各种形状的?
- 如何 RPN 的训练效果?
RPN产生边界框的方法
Just like how CNNs learn classification from feature maps, RPN also learns the proposals from feature maps.
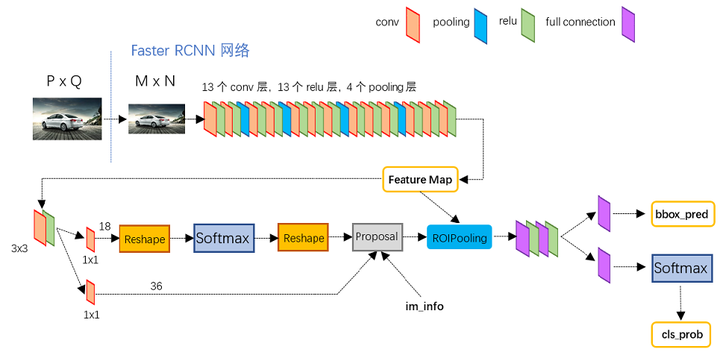
RPN 包括以下部分:
- 生成 anchor boxes
- 判断每个 anchor box 为 foreground(包含物体) 或者 background(背景) ,二分类
- 边界框回归(bounding box regression) 对 anchor box 进行微调,使得 positive anchor 和真实框(Ground Truth Box)更加接近
anchor boxes
例如

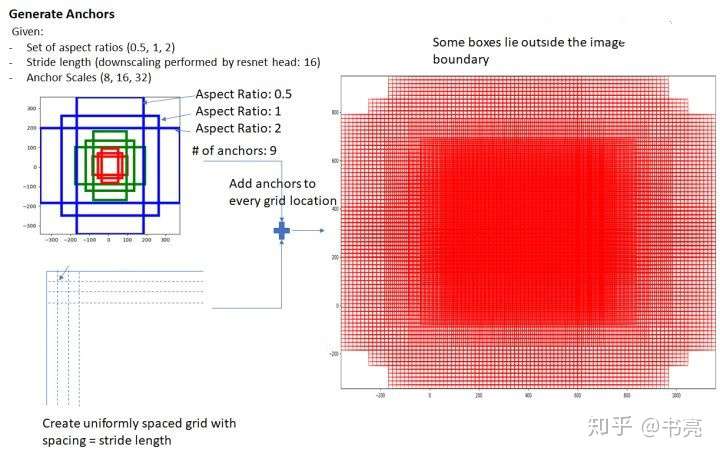
其中每行的4个值((x_1,y_1,x_2,y_2))表示矩形左上角和右下角点坐标。9个矩形共有3种形状,长宽比(heightin{1:1,1:2,2:1}),如下图,通过anchor box 就引入了检测中常用到的多尺度方法。
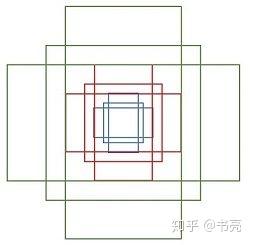
遍历,为 feature maps 的每一个点都配9个锚框,作为初始的检测框。虽然这样得到的检测框很不准确,但后面可通过2次 bounding box regression 来修正检测框的位置。
设 feature maps 的尺寸为(W imes H),那么总共有(W imes H imes 9)个 锚框。
RPN中的卷积
当我们已经得到锚框(anchor boxes)后,需要完成以下两项任务:
(1)anchor box 中是否包含识别物体,foreground/background,二分类问题
(2)如果 anchor box 包含物体,怎么调整,才能使得 anchor box 与 ground truth 更接近。
下面的卷积网络可实现这两项任务:
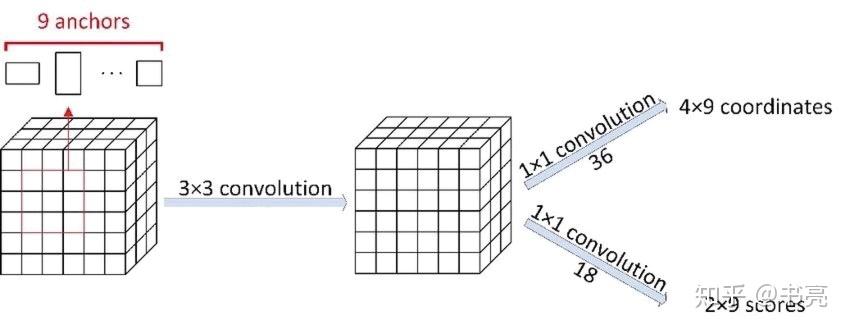
总结:
设 backbone 输出的 feature maps 的尺寸为(W imes H imes C),设置了(W imes H imes k)个
anchor boxes,则上面的卷积神经网络的输出为:
- 大小为 (W imes H imes k imes 2)的 positive/negative Softmax 分类矩阵,可记为(rpn\_cls\_score)
- 大小为 (W imes H imes k imes 4) 的 Bounding Box Regression 坐标偏移矩阵,也就是在原始锚框的基础上做的修改和缩放([d_x(A),d_y(A),d_w(A),d_h(A)]),可记为(rpn\_bbox\_pred)
Bounding Box Regression 的原理
给定anchor (A=(A_x,A_y,A_w,A_h))和(GT=[G_x,G_y,G_w,G_h]),找到一组变换([d_x(A),d_y(A),d_w(A),d_h(A)]),s.t.((G_x',G_y',G_w',G_h')approx (G_x,G_y,G_w,G_h))
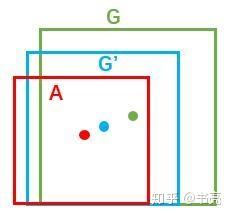
比较简单的思路:
先做平移
[G_x''=A_wcdot d_x(A)+A_x ][G_y''=A_hcdot d_y(A)+A_y ]再做缩放
[G_w''=A_wcdot exp(d_x(A)) ][G_h''=A_hcdot exp(d_y(A)) ]
RPN 中的 Proposal
Proposal 的输入有三个,分别是:
- softmax 分类矩阵(rpn\_cls\_score)
- Bounding Box Regression 坐标矩阵(rpn\_bbox\_pred)
- (im\_info):设输入图片尺寸为(P imes Q),在 Faster-RCNN 的预处理中,会 reshape 为(M imes N) ,则(im\_info=[M,N,scale\_factor])则保存了缩放的信息。
从而 RPN 的输出为:
- rpn_rois: RPN 产生的 ROIs (Region of Interests)
- rpn_roi_probs: 表示 ROI 包含物体的概率
简而言之,RPN 只挑选出了可能包含物体的区域(rpn_rois)以及其包含物体的概率(rpn_roi_probs)。在后续处理中,设定一个阈值 threshold,如果某个ROI 的(rpn\_roi\_probs>threshold),则再判定其类别。如果某个 ROI 的(rpn\_roi\_probs<threshold) ,则忽略。