1.打开http://192.168.242.181:8080 登陆的用户名/密码是 : admin/admin
2.点击 “LAUNCH INSTALL WIZARD”,开始创建一个集群
3.为集群取一个名字
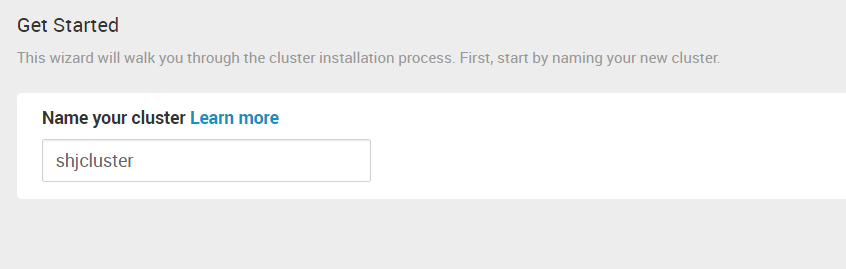
4.前面我们建了本地的资源库,这里选择 “Use Local Repository”。删除其它的OS,只留redhat7那一行。并且在BaseURL那一列里填入前面搭建的 web服务对应的地址。
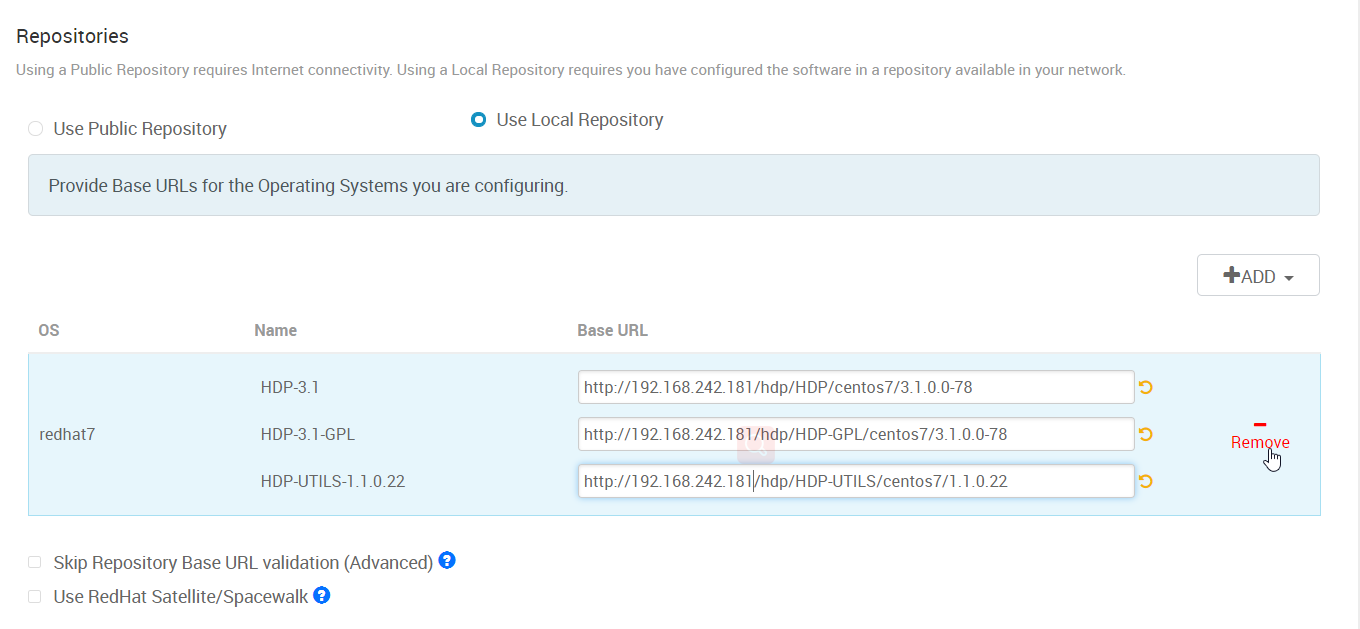
5.在 “TargetHosts”里填入hadoop集群需要部署到哪些机器。可以填IP。
SSH Private Key里选择的文件是从零开始安装 Ambari (1) -- 安装前的准备工作中配置免密登陆到其它机器的那台机器的 id_rsa这个文件(ambari主机)。我用的是root帐号,所以这个文件是在 /root/.ssh/目录下。
6. “ConfirmHosts”这一步,ambari会在上面的配置的hosts中安装ambariagent,只需等待即可。
7.根据需要,选择服务。如果某些服务依赖其它服务,而没有选择依赖的服务的话,点击“Next”时,会做相应的提示。
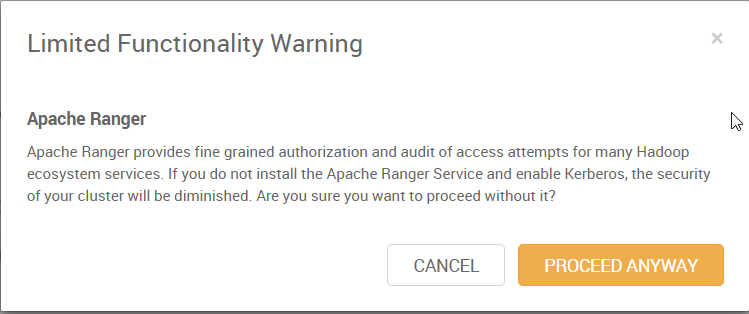
8.点击 “Next”,如果出现类似下面的警告的话,可以不用管,后续如果需要的话,可以再安装
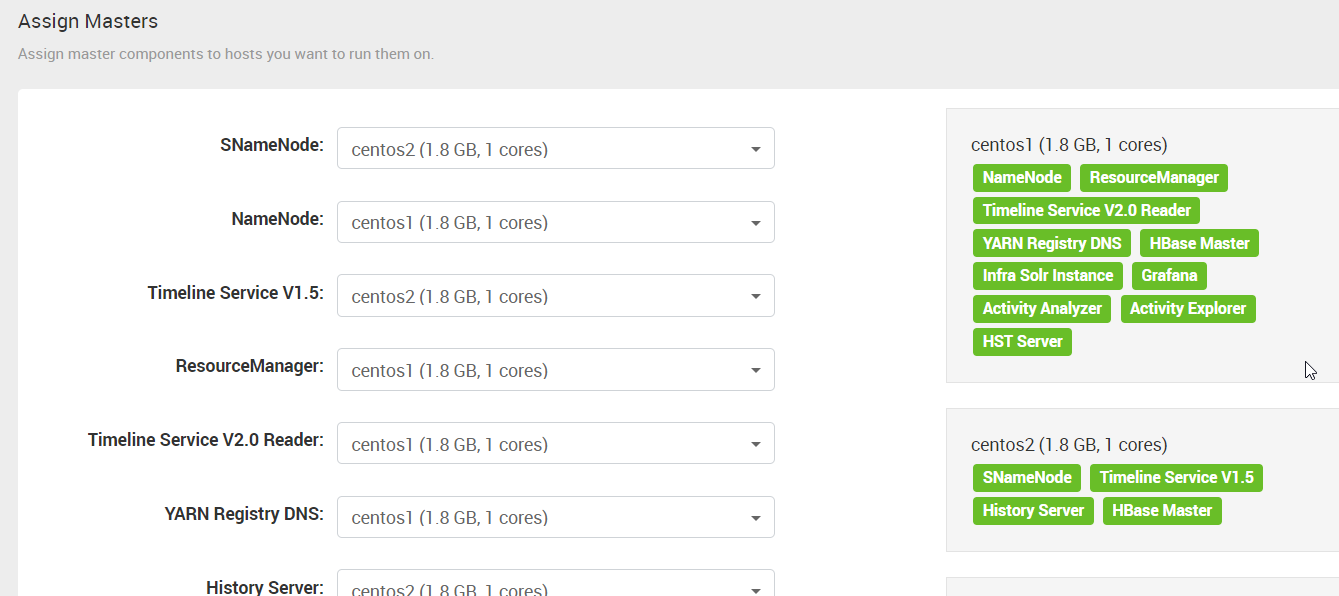
9. “Assign Masters”这一步,ambari会自动分配各种服务到不同的机器上。可以手动进行调整。
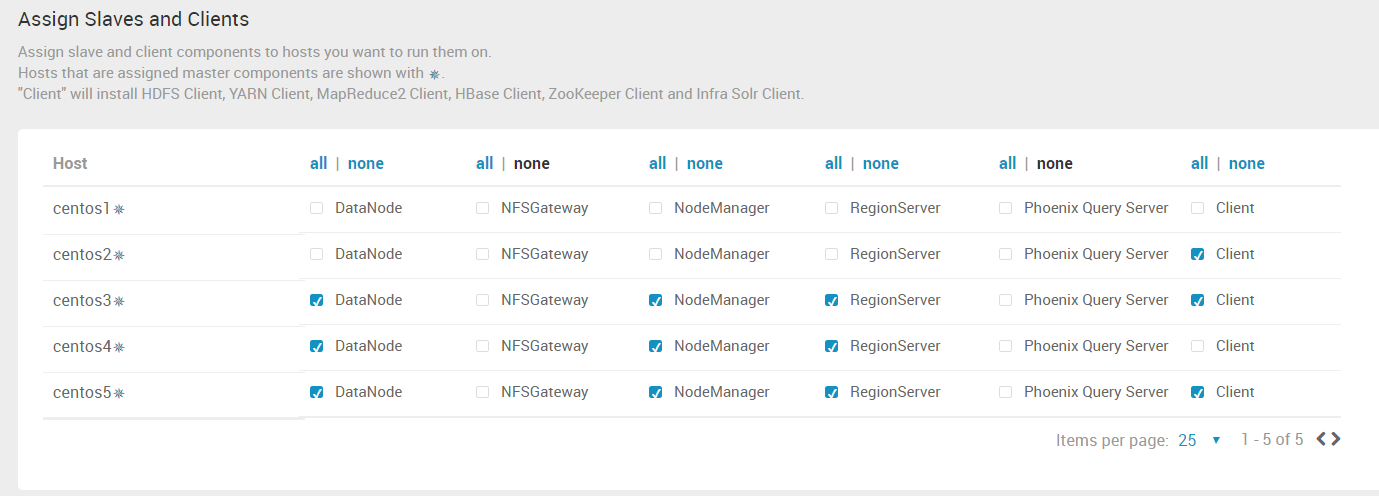
10. “Assign Slaves and Clients”这一步,手动分配 Hadoop的DataNode节点位置,YARN的NodeManager的位置......
其中NFSGateway是通过挂载的方式,像访问本地文件系统一样访问Hadoop的文件系统。
Phoenix Query Server是一个HBase的开源SQL引擎。你可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据,查询你的HBase数据。
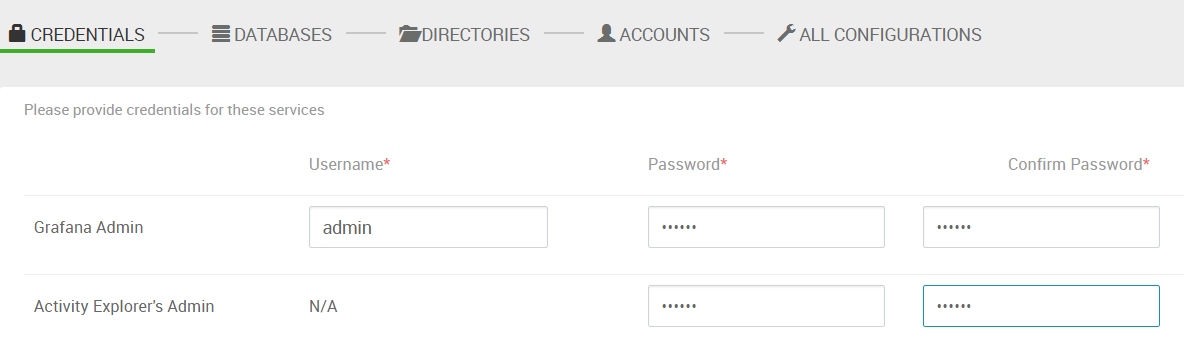
11.设置密码。(有一行的username是 N/A,比较奇怪,不知道用在哪)
12.数据库配置。如果选择了安装 hive或 Ranger,需要输入相关的数据库的信息。此例中没有这一步。
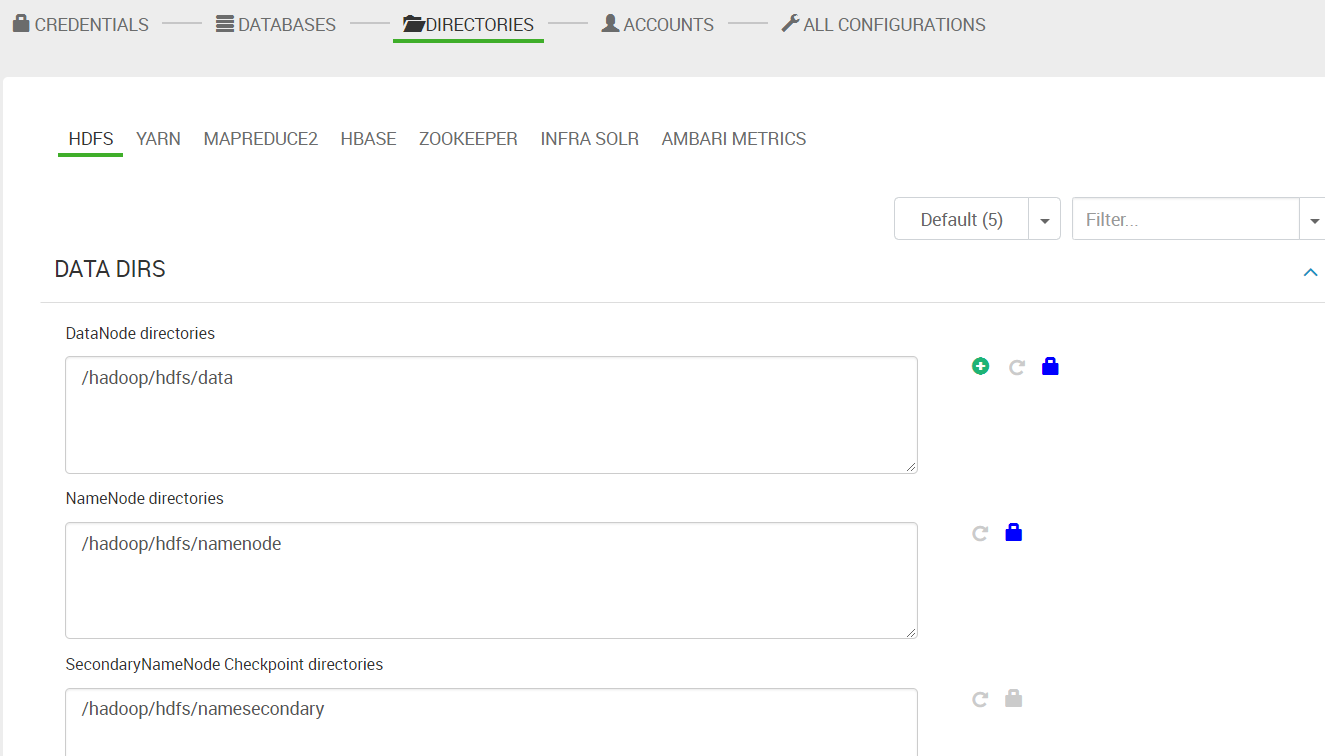
13.目录配置。配置各个服务需要用到的目录。使用默认值即可。
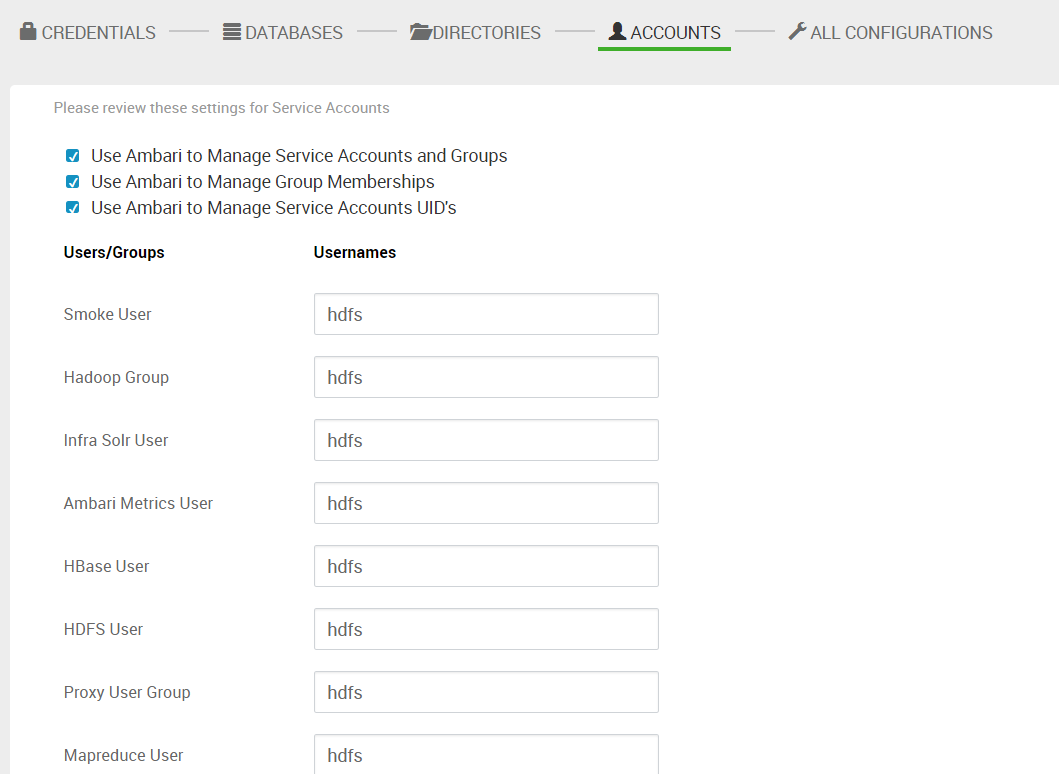
14.创建用户。默认情况下,ambari会为每个服务创建一个linux的用户,用不同的用户启动不同的服务。我设成了同一个用户。
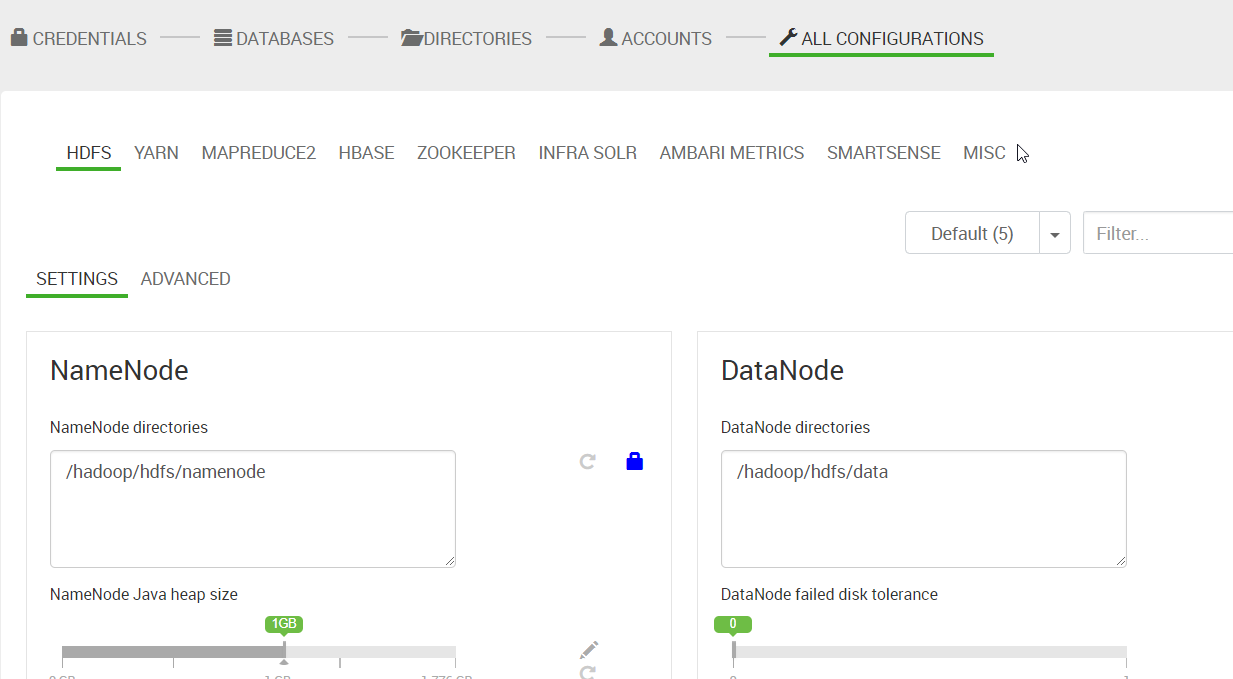
15. “ALL CONFIGURATIONS”,这一步可以修改前面的一些配置
16.点击 “Next”后,出现总结页。可以下载创建这个集群的元数据信息。点击 “DEPLOY”后,就开始部署了。
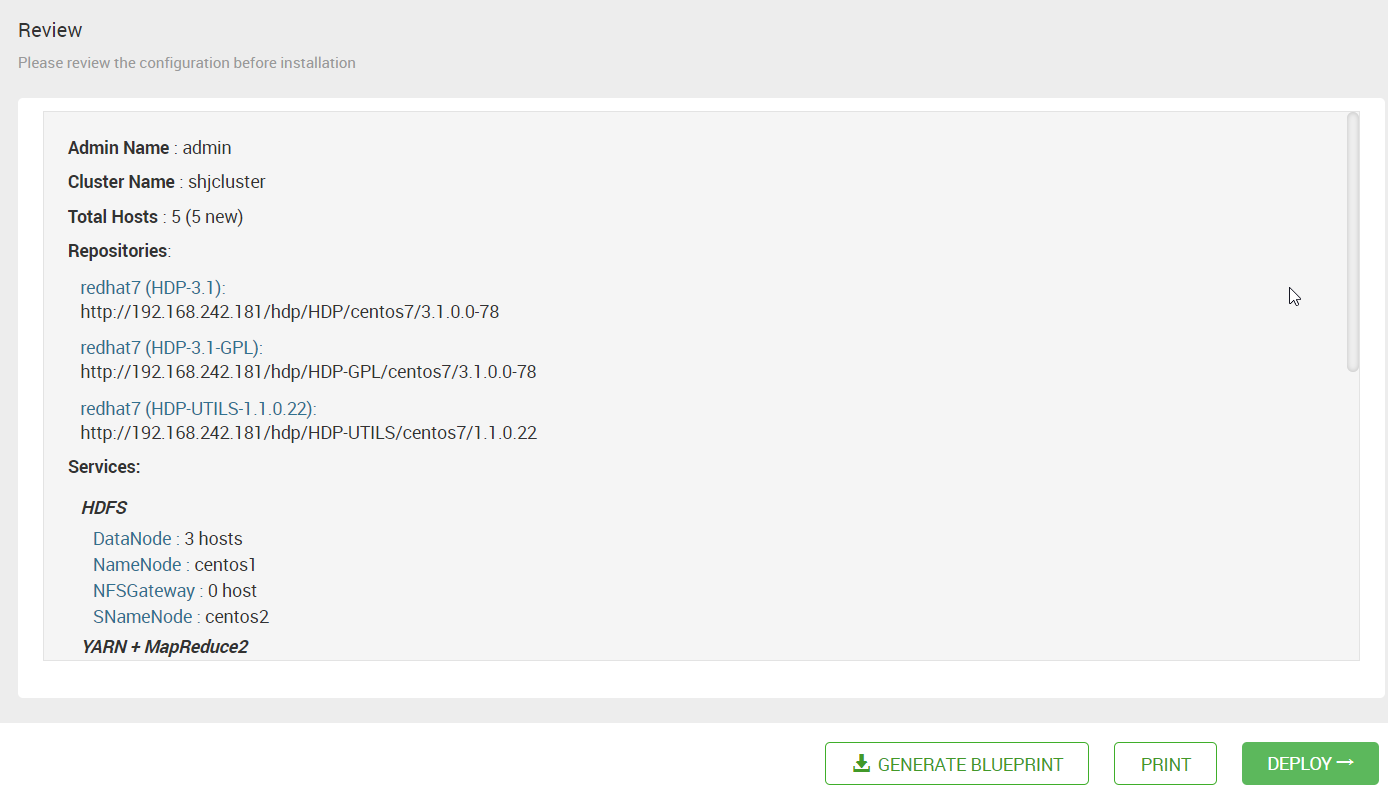
17. 效果展示。
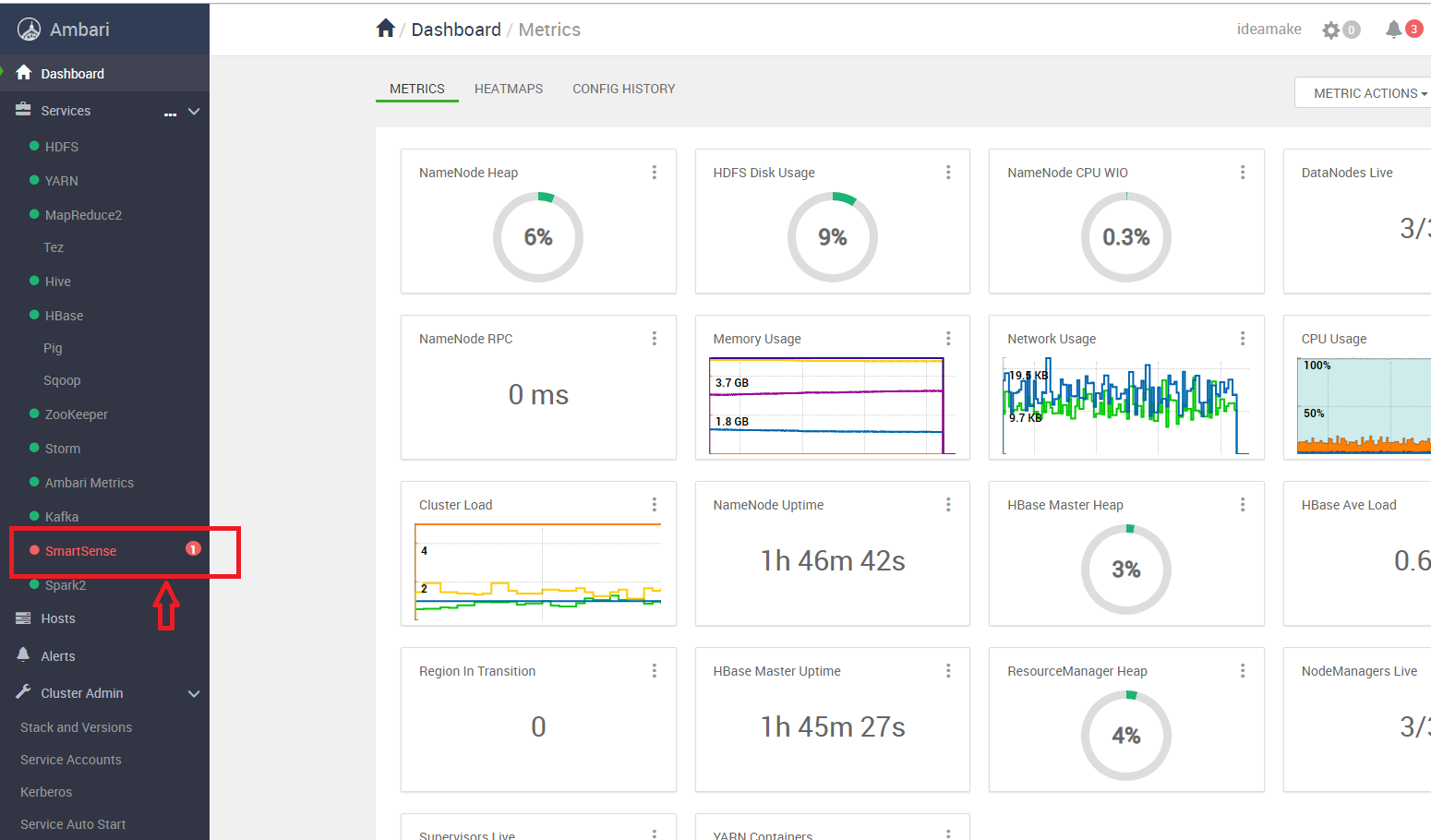
此时SmartSense有报错,
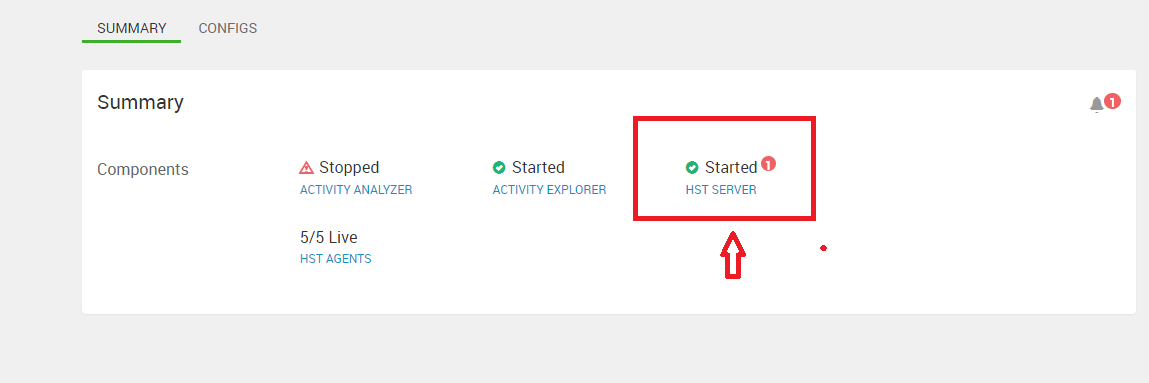
这是HST SERVER未安装,HST是ambari的收费子项目,安装在集群子节点,用于集群整体的性能反馈调优。这里没有安装,如何需要安装,可单独进行。