摘要:
defbuild_karate_club_graph():#所有78个边缘都不可重复。一个用于源端点,另一个用于目标端点。src=np.array([1,33])dst=np.arrange([0,
使用没有节点特征的图来跑DGL (输入特征为节点编号的embedding)
安装DGL :
pip install dgl
所需要的包
import dgl import numpy as np import networkx as nx import matplotlib.pyplot as plt import torch import torch.nn as nn import torch.nn.functional as F
构建无向图:
def build_karate_club_graph(): # All 78 edges are stored in two numpy arrays. One for source endpoints # while the other for destination endpoints. src = np.array([1, 2, 2, 3, 3, 3, 4, 5, 6, 6, 6, 7, 7, 7, 7, 8, 8, 9, 10, 10, 10, 11, 12, 12, 13, 13, 13, 13, 16, 16, 17, 17, 19, 19, 21, 21, 25, 25, 27, 27, 27, 28, 29, 29, 30, 30, 31, 31, 31, 31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33]) dst = np.array([0, 0, 1, 0, 1, 2, 0, 0, 0, 4, 5, 0, 1, 2, 3, 0, 2, 2, 0, 4, 5, 0, 0, 3, 0, 1, 2, 3, 5, 6, 0, 1, 0, 1, 0, 1, 23, 24, 2, 23, 24, 2, 23, 26, 1, 8, 0, 24, 25, 28, 2, 8, 14, 15, 18, 20, 22, 23, 29, 30, 31, 8, 9, 13, 14, 15, 18, 19, 20, 22, 23, 26, 27, 28, 29, 30, 31, 32]) # Edges are directional in DGL; Make them bi-directional. u = np.concatenate([src, dst]) v = np.concatenate([dst, src]) # Construct a DGLGraph return dgl.DGLGraph((u, v))
G = build_karate_club_graph()
print("G中节点数 %d."% G.number_of_nodes()) # 34
print("G中边数 %d."% G.number_of_edges()) # 156
转为networkX进行可视化
def visual(G): # 可视化 nx_G = G.to_networkx().to_undirected() pos = nx.kamada_kawai_layout(nx_G) ## 生成节点位置 nx.draw(nx_G, pos, with_labels=True, node_color=[[.7, .7, .7]]) plt.pause(10)

对每个节点做embedding并作为GCN的输入特征:
## 对 34 个节点做embedding embed = nn.Embedding(34, 5) # 34 nodes with embedding dim equal to 5 print(embed.weight) G.ndata['feat'] = embed.weight
训练GCN:
def train(G, inputs, embed, labeled_nodes,labels): net = GCN(5,5,2) import itertools optimizer = torch.optim.Adam(itertools.chain(net.parameters(), embed.parameters()), lr=0.01) all_logits = [] for epoch in range(50): logits = net(G, inputs) # we save the logits for visualization later all_logits.append(logits.detach()) # detach代表从当前计算图中分离下来的 logp = F.log_softmax(logits, 1) # 半监督学习, 只使用标记的节点计算loss loss = F.nll_loss(logp[labeled_nodes], labels) optimizer.zero_grad() loss.backward() optimizer.step() print('Epoch %d | Loss: %.4f' % (epoch, loss.item())) print(all_logits)
train(G, embed.weight, embed, torch.tensor([0,33]), torch.tensor([0,1]))


Epoch 0 | Loss: 0.9247 Epoch 1 | Loss: 0.8673 Epoch 2 | Loss: 0.8160 Epoch 3 | Loss: 0.7713 Epoch 4 | Loss: 0.7328 Epoch 5 | Loss: 0.6999 Epoch 6 | Loss: 0.6748 Epoch 7 | Loss: 0.6551 Epoch 8 | Loss: 0.6392 Epoch 9 | Loss: 0.6252 Epoch 10 | Loss: 0.6120 Epoch 11 | Loss: 0.5989 Epoch 12 | Loss: 0.5854 Epoch 13 | Loss: 0.5713 Epoch 14 | Loss: 0.5559 Epoch 15 | Loss: 0.5391 Epoch 16 | Loss: 0.5210 Epoch 17 | Loss: 0.5031 Epoch 18 | Loss: 0.4867 Epoch 19 | Loss: 0.4696 Epoch 20 | Loss: 0.4522 Epoch 21 | Loss: 0.4347 Epoch 22 | Loss: 0.4168 Epoch 23 | Loss: 0.3987 Epoch 24 | Loss: 0.3808 Epoch 25 | Loss: 0.3627 Epoch 26 | Loss: 0.3448 Epoch 27 | Loss: 0.3269 Epoch 28 | Loss: 0.3090 Epoch 29 | Loss: 0.2913 Epoch 30 | Loss: 0.2738 Epoch 31 | Loss: 0.2566 Epoch 32 | Loss: 0.2396 Epoch 33 | Loss: 0.2230 Epoch 34 | Loss: 0.2069 Epoch 35 | Loss: 0.1913 Epoch 36 | Loss: 0.1762 Epoch 37 | Loss: 0.1618 Epoch 38 | Loss: 0.1479 Epoch 39 | Loss: 0.1347 Epoch 40 | Loss: 0.1224 Epoch 41 | Loss: 0.1111 Epoch 42 | Loss: 0.1007 Epoch 43 | Loss: 0.0910 Epoch 44 | Loss: 0.0822 Epoch 45 | Loss: 0.0742 Epoch 46 | Loss: 0.0670 Epoch 47 | Loss: 0.0605 Epoch 48 | Loss: 0.0546 Epoch 49 | Loss: 0.0494
对每轮的分类结果进行可视化
def draw(i): cls1color = '#00FFFF' cls2color = '#FF00FF' pos = {} colors = [] for v in range(34): pos[v] = all_logits[i][v].numpy() cls = pos[v].argmax() colors.append(cls1color if cls else cls2color) ax.cla() ax.axis('off') ax.set_title('Epoch: %d' % i) nx.draw_networkx(nx_G.to_undirected(), pos, node_color=colors, with_labels=True, node_size=300, ax=ax) nx_G = G.to_networkx().to_undirected() fig = plt.figure(dpi=150) fig.clf() ax = fig.subplots() for i in range(50): draw(i) plt.pause(0.2) plt.show()
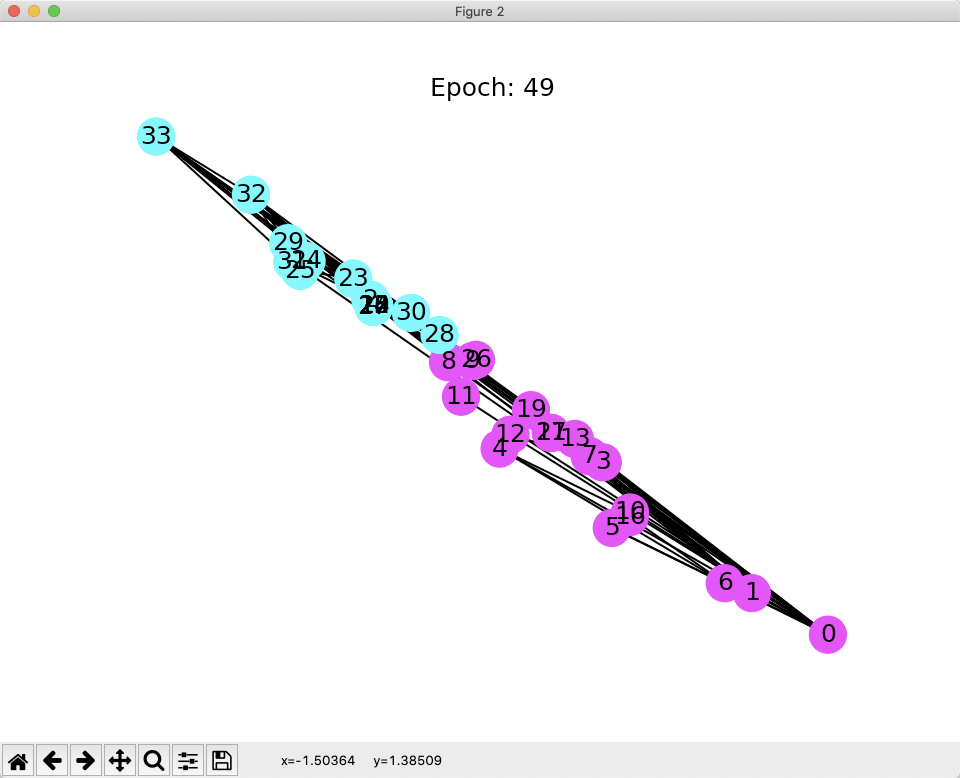
完整代码:
import dgl import numpy as np import networkx as nx import matplotlib.pyplot as plt import torch import torch.nn as nn import torch.nn.functional as F def build_karate_club_graph(): # All 78 edges are stored in two numpy arrays. One for source endpoints # while the other for destination endpoints. src = np.array([1, 2, 2, 3, 3, 3, 4, 5, 6, 6, 6, 7, 7, 7, 7, 8, 8, 9, 10, 10, 10, 11, 12, 12, 13, 13, 13, 13, 16, 16, 17, 17, 19, 19, 21, 21, 25, 25, 27, 27, 27, 28, 29, 29, 30, 30, 31, 31, 31, 31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33]) dst = np.array([0, 0, 1, 0, 1, 2, 0, 0, 0, 4, 5, 0, 1, 2, 3, 0, 2, 2, 0, 4, 5, 0, 0, 3, 0, 1, 2, 3, 5, 6, 0, 1, 0, 1, 0, 1, 23, 24, 2, 23, 24, 2, 23, 26, 1, 8, 0, 24, 25, 28, 2, 8, 14, 15, 18, 20, 22, 23, 29, 30, 31, 8, 9, 13, 14, 15, 18, 19, 20, 22, 23, 26, 27, 28, 29, 30, 31, 32]) # Edges are directional in DGL; Make them bi-directional. u = np.concatenate([src, dst]) v = np.concatenate([dst, src]) # Construct a DGLGraph return dgl.DGLGraph((u, v)) def visual(G): # 可视化 nx_G = G.to_networkx().to_undirected() pos = nx.kamada_kawai_layout(nx_G) ## 生成节点位置 nx.draw(nx_G, pos, with_labels=True, node_color=[[.7, .7, .7]]) plt.pause(10) from dgl.nn.pytorch import GraphConv class GCN(nn.Module): def __init__(self, in_feats, hidden_size, num_classes): super(GCN, self).__init__() self.conv1 = GraphConv(in_feats, hidden_size) self.conv2 = GraphConv(hidden_size, num_classes) def forward(self, g, inputs): h = self.conv1(g, inputs) h = torch.relu(h) h = self.conv2(g, h) return h def train(G, inputs, embed, labeled_nodes,labels): net = GCN(5,5,2) import itertools optimizer = torch.optim.Adam(itertools.chain(net.parameters(), embed.parameters()), lr=0.01) all_logits = [] for epoch in range(50): logits = net(G, inputs) # we save the logits for visualization later all_logits.append(logits.detach()) # detach代表从当前计算图中分离下来的 logp = F.log_softmax(logits, 1) # 半监督学习, 只使用标记的节点计算loss loss = F.nll_loss(logp[labeled_nodes], labels) optimizer.zero_grad() loss.backward() optimizer.step() print('Epoch %d | Loss: %.4f' % (epoch, loss.item())) print(all_logits) def draw(i): cls1color = '#00FFFF' cls2color = '#FF00FF' pos = {} colors = [] for v in range(34): pos[v] = all_logits[i][v].numpy() cls = pos[v].argmax() colors.append(cls1color if cls else cls2color) ax.cla() ax.axis('off') ax.set_title('Epoch: %d' % i) nx.draw_networkx(nx_G.to_undirected(), pos, node_color=colors, with_labels=True, node_size=300, ax=ax) nx_G = G.to_networkx().to_undirected() fig = plt.figure(dpi=150) fig.clf() ax = fig.subplots() for i in range(50): draw(i) plt.pause(0.2) plt.show() def main(): G = build_karate_club_graph() print("G中节点数 %d."% G.number_of_nodes()) print("G中边数 %d."% G.number_of_edges()) visual(G) ## 对 34 个节点做embedding embed = nn.Embedding(34, 5) # 34 nodes with embedding dim equal to 5 print(embed.weight) G.ndata['feat'] = embed.weight # print out node 2's input feature print(G.ndata['feat'][2]) # print out node 10 and 11's input features print(G.ndata['feat'][[10, 11]]) train(G, embed.weight, embed, torch.tensor([0,33]), torch.tensor([0,1])) main()