一、分布式中的CAP原则
1.1 CAP的概念
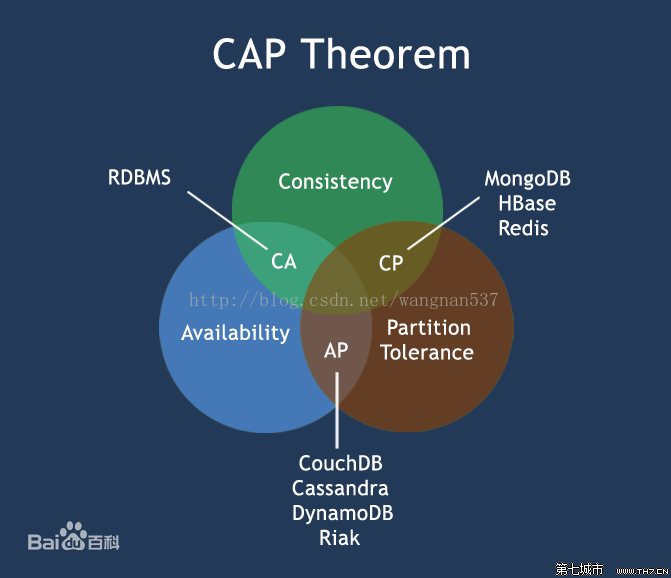
CAP原则指的是在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性),最多只能满足两个,三者不能兼得
- Consistency(一致性)
指的是对于每一次的读取操作,要么都能够读取到最新的写入数据,要么就错误
- Availability(可用性)
指的是对于每一次请求,都能够得到一个及时的、正确的响应,但是不保证请求的结果是基于最新写入的数据,不出现用户操作失败或者访问超时等用户体验不好的情况,
- Partition tolerance(分区容错性)
指的是节点之间的网络问题,即使一些消息对多包或者延迟,整个系统能继续提供服务
分区容错性能够让你的系统在部分断网的情况下仍然可以可以完全正常的运转。实现分区容错的一种常见方式就是服务切分成不同的“分区”,甚至可以处于不同的网络问题上,这样做的优势是,如果某个网段断线了,并不会把整个系统拖垮
1.2 为什么会有CAP原则?
现如今,对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,节点只会越来越多,所以节点故障、网络故障是常态,因此分区容错性也就成为了一个分布式系统必然要面对的问题。
1.3 zookeeper中是保证CP原则的
zookeeper会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得zk集群失 去master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。
1.4 zookeeper的实现原理
zookepper服务正常启动后,所有的zookepper客户端都会监听某一个节点,当这个节点内容发生个改变后,zookeeper的服务会给所有的zookeeper客户端发送一个事件通知,客户端收到这个事件通知后,会拉取最新的数据
1.5 Eureka是保证AP的
Eureka看明白了这一点,因此在设计时就保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响其他节点正常的工作,剩余的节点依旧可以提供注册和查询服务。而Eureka的客户端在向某个Eureka服务进行注册时,如果发现连接失败,则会自动切换至其他节点,只要有一台Eureka服务存在,就还能保证服务的注册可用(保证可用性),只不过查询到的信息不是最新的(不保证强一致性)
除此之外,Eureka还有一种自我保护机制,如果在十五分钟内超过百分之八十五的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了故障,此时会有以下几种情形:
1、Eureka不会从出册表移除因长时间没有收到心跳而移除的服务
2、Eureka仍然能够接收新服务的注册和查询请求,但是不会被同步到其他节点上,即保证当前节点依然可用
3、当网络稳定时,当前实例的注册信息会被同步到其他节点中
Eureka 自我保护机制是为了防止误杀服务而提供的一个机制。当个别客户端出现心跳失联时,则认为是客户端的问题,剔除掉客户端;当 Eureka 捕获到大量的心跳失败时,则认为可能是网络问题,进入自我保护机制;当客户端心跳恢复时,Eureka 会自动退出自我保护机制。
如果在保护期内刚好这个服务提供者非正常下线了,此时服务消费者就会拿到一个无效的服务实例,即会调用失败。对于这个问题需要服务消费者端要有一些容错机制,如重试,断路器等。
1.6 Eureka的实现原理
1、Eureka服务正常启动,如果存在集群的话就要互相同步
2、Eureka客户端启动的时候,会根据配置的地址,将该服务注册到Eureka服务中,
3、Eureka客户端会每隔30s发送一个心跳给Eureka服务
4、Eureka服务在90s之内没有收到Eureka客户端的心跳,会认为客户端出现故障,然后从服务列表中移除,
5、在一段时间内,Eureka服务端统计到有大量的(85%)Eureka客户端没有发送心跳Eureka服务会认为此时,自己出现了网络故障,就会触发自我保护机制,不会再移除eureka客户端。当前不会把数据同步给其他的Eureka服务,但是对外还是提供服务的
6、如果网络恢复正常,自我保护机制关闭,接着将数据同步到其他的Eureka服务器
7、Eureka客户端要调用其他服务,需要先到Eureka服务器中拉取其他服务的信息,然后再缓存到本地,再根据客户端的负载均衡策略进行负载均衡
8、Eureka客户端会在一段时间内从Eureka服务端拉取最新的数据,更新本地的缓存数据。
9、Eureka客户端关闭后,Eureka就不会再发送心跳,Eureka服务就从自己的列表中移除
1.7 Zookepper和Eureka的区别:
1、所属的组织不同,zookeeper是apache组织下的,而Eureka是netfix的
2、zookeeper选择的是CP原则,即一致性,而eureka选择的是AP,即可用性
3、zookeeper的集群中,zookeeper会存在三个角色,群首(leader),追随者(follower),观察者(observer),而Eureka中是不存在角色的,每个节点都是平等的
4、实现原理不一致
二、分布式锁
2.1 引言
由于传统的锁是基于Tomcat服务器内部的,搭建了集群之后,导致锁失效,使用分布式锁来处理。
2.2 回顾传统单体架构的锁
我们遇到多个线程操作同一资源的时候,我们往往会采用同步代码块synchronized的方式来处理,但是同步代码块中那个锁使用this(对象锁)和使用类名.class的又有什么区别呢,下面我们同过代码来试验
使用this的方式
public class SynLockTest {
@Test
public void test1() throws IOException {
//创建连个对象
User user1 = new User("张三");
User user2 = new User("李四");
UserThread userThread1 = new UserThread(user1);
UserThread userThread2 = new UserThread(user2);
//2、启动线程
for (int i = 0; i < 10; i++) {
new Thread(userThread1).start();
new Thread(userThread2).start();
}
System.in.read();
}
}
//自定义一个线程类
class UserThread implements Runnable{
private User user;
public UserThread(User user){
this.user = user;
}
@Override
public void run() {
try {
user.info();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
class User{
public String username;
public User(String username){
this.username = username;
}
public void info() throws InterruptedException {
synchronized (this){
// System.out.println("this="+this);
Thread.sleep(1000);
System.out.println("当前线程的名字为:"+Thread.currentThread().getName()+"____"+username);
}
}
}
发现结果是两条数据一起打印的,说明当前的锁并没有起作用
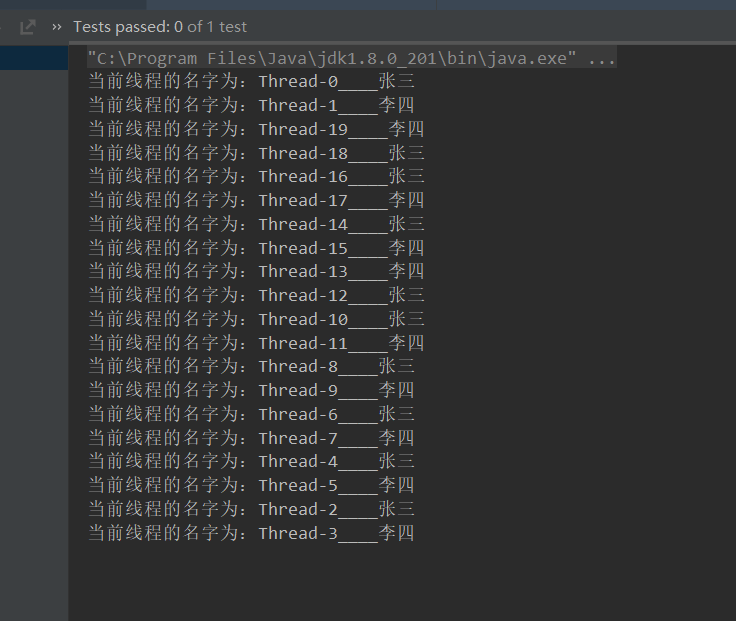
修改代码,使用类锁
public void info() throws InterruptedException {
synchronized (System.class){
// System.out.println("this="+this);
Thread.sleep(1000);
System.out.println("当前线程的名字为:"+Thread.currentThread().getName()+"____"+username);
}
}
发现数据是一行一行输出的,说明同步代码块中的锁起到了作用

2.3 双重锁机制
@Override
public List<User> getUserList() {
List<User> userList = null;
userList= (List<User>) redisTemplate.opsForValue().get("userList");
if(userList == null){
synchronized (this){
if(userList == null){
System.out.println("查询数据库");
userList = userDao.select(null);
// 进行缓存重建
redisTemplate.opsForValue().set("userList",userList);
redisTemplate.expire("userList",5, TimeUnit.SECONDS); // 5s后失效
}
}
}
return userList;
}
2.4 分布式锁实现原理
这里将演示两种分布式锁解决方式,分别是使用Redis和Zookeeper解决
实现原理:
reids:redis实现的原理是使用reids的setnx命令,当添加成功时认为拿到锁,逻辑业务执行完毕后删除key,认为是释放锁
Zookeeper:Zookeeper实现分布式锁的原理就是使用临时有序节点的方式,客户端在指定节点下创建临时有序节点时,如果说序号是最小的就获取了锁资源,如果说当前节点不是最小的,监听比自己小一号的节点,如果这个小一号节点被删除了,当前节点再次判断自己的是否为最小的节点,如果是就拿到锁资源
# 设置值,如果key已存在不添加且返回0,不存在添加且返回1
setnx key value
2.5 基于reids高并发抢票案例
1、导入依赖
<!--zookeeper的高级API,内部已经包含了zookeeper依赖-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>
2、将zookeeper客户端注入到spring容器中,当然也可以不注入,自己创建
@Configuration
public class ZookeeperClient {
//将zookeeper的高级客户端注入到容器
@Bean
public CuratorFramework cf() throws Exception{
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000,2);
CuratorFramework cf = CuratorFrameworkFactory.builder().
connectString("192.168.40.100:2181")
.retryPolicy(retryPolicy)
.build();
cf.start();
return cf;
}
}
3、编写秒杀业务
/**
* 测试秒杀的业务controller 使用的是zookeeper
* @param
* @return
*/
@RestController
public class SeckillControllerZookeeper {
//模拟数据库中的商品数据
private Map<String,Integer> stockMap = new HashMap<>();
//模拟数据库中的订单数据
private Map<String,Integer> orderMap = new HashMap<>();
//初始化数据
@PostConstruct
public void init(){
stockMap.put("手机",1000);//初始化手机数量数据库中的数据
orderMap.put("手机",0);//初始化数据库中的数据
}
private CuratorFramework cf;
@Autowired
RedisLock redisLock;
//秒杀
@RequestMapping("/seckillGoods")
public String seckillGoods(String gname) throws Exception {
//获取锁
boolean lock = redisLock.getLock(gname, "1", 1L);
if(lock){
//1、根据商品名称获取库存
Integer stock = stockMap.get(gname);
//2、判断
if(stock <= 0){
return "商品已经被抢光了,请等待下一轮秒杀";
}
//3、库存-1
stockMap.put(gname,stock-1);
Thread.sleep(200);//模拟修改数据库,需要耗时
//4、订单需要加1
Integer orderCount = orderMap.get(gname);
orderMap.put(gname,orderCount+1);
Thread.sleep(200);//模拟修改数据库,需要耗时
//释放锁
redisLock.unLock(gname);
//5、响应用户
return "抢购【"+gname+"】成功,商品数量还剩【"+stockMap.get(gname)+"】,订单量为【"+orderMap.get(gname)+"】";
}else {
return "当前访问人数过多~";
}
}
}
4、使用高并发测压工具进行测试
2.6 基于reids高并发抢票案例
1、导入依赖
<!-- springBoot整合reids的依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2、编写获取锁和释放锁的工具类
/**
* redis处理分布式锁的原理
* 拿到锁:redis使用setnx命令,如果存储成功就拿到锁
* 释放锁:删除对应的数据
* @param
* @return
*/
@Component
public class RedisLock {
@Autowired
private StringRedisTemplate template;
/**
* 获取资源的方法,其原理是redis的是使用redis的setnx命令,如果存储相同的值会返回一个标识
* @param key 存储的key
* @param val 存储的值
* @param ex 超时时间,谨防死锁的出现
* @return
*/
public boolean getLock(String key,String val,Long ex){
return template.opsForValue().setIfAbsent(key,val,ex, TimeUnit.SECONDS);
}
/**
* 释放锁,其原理是删除redis中的数据,
*/
public void unLock(String key){
template.delete(key);
}
}
3、编写秒杀业务
/**
* 测试秒杀的业务controller 使用的是zookeeper
* @param
* @return
*/
@RestController
public class SeckillControllerZookeeper {
//模拟数据库中的商品数据
private Map<String,Integer> stockMap = new HashMap<>();
//模拟数据库中的订单数据
private Map<String,Integer> orderMap = new HashMap<>();
//初始化数据
@PostConstruct
public void init(){
stockMap.put("手机",1000);//初始化手机数量数据库中的数据
orderMap.put("手机",0);//初始化数据库中的数据
}
@Autowired
private CuratorFramework cf;
@Autowired
RedisLock redisLock;
//秒杀
@RequestMapping("/seckillGoods")
public String seckillGoods(String gname) throws Exception {
//获取锁
boolean lock = redisLock.getLock(gname, "1", 1L);
if(lock){
//1、根据商品名称获取库存
Integer stock = stockMap.get(gname);
//2、判断
if(stock <= 0){
return "商品已经被抢光了,请等待下一轮秒杀";
}
//3、库存-1
stockMap.put(gname,stock-1);
Thread.sleep(200);//模拟修改数据库,需要耗时
//4、订单需要加1
Integer orderCount = orderMap.get(gname);
orderMap.put(gname,orderCount+1);
Thread.sleep(200);//模拟修改数据库,需要耗时
//释放锁
redisLock.unLock(gname);
//5、响应用户
return "抢购【"+gname+"】成功,商品数量还剩【"+stockMap.get(gname)+"】,订单量为【"+orderMap.get(gname)+"】";
}else {
return "当前访问人数过多~";
}
}
}
三、分布式事务
3.1 什么是分布式事务
分布式事务就是指事务的资源分别位于不同的分布式系统的不同节点之上的事务;
3.2 分布式事务产生的原因
3.2.1 数据库分库分表
在单库单表场景下,当业务数据量达到单库单表的极限时,就需要考虑分库分表,将之前的单库单表拆分成多库多表;分库分表之后,原来在单个数据库上的事务操作,可能就变成跨多个数据库的操作,此时就需要使用分布式事务;
3.2.3 业务服务化
业务服务化即业务按照面向服务(SOA)的架构拆分整个网站系统;
比如互联网金融网站SOA拆分,分离出交易系统、账务系统、清算系统等,交易系统负责交易管理和记录交易明细,账务系统负责维护用户余额,所有的业务操作都以服务的方式对外发布;
一笔金融交易操作需要同时记录交易明细和完成用户余额的转账,此时需要分别调用交易系统的交易明细服务和账务系统的用户余额服务,这种跨应用、跨服务的操作需要使用分布式事务才能保证金融数据的一致性;
3.4 Base理论
在我们之前的CAP原则 C:一致性, A:可用性,P:分区容错性,在分布式环境中,三者只能取其二
- Eureka:AP,保证了可用性,舍弃了一致性。
- Zookeeper,Redis:CP,每一个节点必须能够找到Master才能对外提供服务,舍弃了可用性。
一致性:
强一致性:任何时候查询任何节点都要保证数据是最新的状态,如zookeeper
最终一致性:允许任何时间查询的数据不一致,但是要保证最终数据一致,如reids的主从复制
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的简写,BASE是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的结论,是基于CAP定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)
基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性——但请注意,这绝不等价于系统不可用,以下两个就是“基本可用”的典型例子。
- 响应时间上的损失:正常情况下,一个在线搜索引擎需要0.5秒内返回给用户相应的查询结果,但由于出现异常(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了1~2秒。
- 功能上的损失:正常情况下,在一个电子商务网站上进行购物,消费者几乎能够顺利地完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。
弱状态也称为软状态,和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据听不的过程存在延时。
最终一致性
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性
亚马逊首席技术官Werner Vogels在于2008年发表的一篇文章中对最终一致性进行了非常详细的介绍。他认为最终一致性时一种特殊的弱一致性:系统能够保证在没有其他新的更新操作的情况下,数据最终一定能够达到一致的状态,因此所有客户端对系统的数据访问都能够胡渠道最新的值。同时,在没有发生故障的前提下,数据达到一致状态的时间延迟,取决于网络延迟,系统负载和数据复制方案设计等因素。
在实际工程实践中,最终一致性存在以下五类主要变种。
因果一致性:
因果一致性是指,如果进程A在更新完某个数据项后通知了进程B,那么进程B之后对该数据项的访问都应该能够获取到进程A更新后的最新值,并且如果进程B要对该数据项进行更新操作的话,务必基于进程A更新后的最新值,即不能发生丢失更新情况。与此同时,与进程A无因果关系的进程C的数据访问则没有这样的限制。
读己之所写:
读己之所写是指,进程A更新一个数据项之后,它自己总是能够访问到更新过的最新值,而不会看到旧值。也就是说,对于单个数据获取者而言,其读取到的数据一定不会比自己上次写入的值旧。因此,读己之所写也可以看作是一种特殊的因果一致性。
会话一致性:
会话一致性将对系统数据的访问过程框定在了一个会话当中:系统能保证在同一个有效的会话中实现“读己之所写”的一致性,也就是说,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。
单调读一致性:
单调读一致性是指如果一个进程从系统中读取出一个数据项的某个值后,那么系统对于该进程后续的任何数据访问都不应该返回更旧的值。
单调写一致性:
单调写一致性是指,一个系统需要能够保证来自同一个进程的写操作被顺序地执行。
以上就是最终一致性的五类常见的变种,在时间系统实践中,可以将其中的若干个变种互相结合起来,以构建一个具有最终一致性的分布式系统。事实上,可以将其中的若干个变种相互结合起来,以构建一个具有最终一致性特性的分布式系统。事实上,最终一致性并不是只有那些大型分布式系统才设计的特性,许多现代的关系型数据库都采用了最终一致性模型。在现代关系型数据库中,大多都会采用同步和异步方式来实现主备数据复制技术。在同步方式中,数据的复制国耻鞥通常是更新事务的一部分,因此在事务完成后,主备数据库的数据就会达到一致。而在异步方式中,备库的更新往往存在延时,这取决于事务日志在主备数据库之间传输的时间长短,如果传输时间过长或者甚至在日志传输过程中出现异常导致无法及时将事务应用到备库上,那么狠显然,从备库中读取的的数据将是旧的,因此就出现了不一致的情况。当然,无论是采用多次重试还是认为数据订正,关系型数据库还是能搞保证最终数据达到一致——这就是系统提供最终一致性保证的经典案例。
总的来说,BASE理论面向的是大型高可用可扩展的分布式系统,和传统事务的ACID特性使相反的,它完全不同于ACID的强一致性模型,而是提出通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性与BASE理论往往又会结合在一起使用。
其他关于Base的资料
- 基于CAP理论演化而来的,是对CAP定理中一致性和可用性的一个权衡结果。
- 核心思想:我们无法做到强一致性,但是每一个应用都可以根据自身的业务特点,采用一些适当的方式来权衡,最终达到一致性。
- 基本可用:分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。如,电商网站交易付款出现问题了,商品依然可以正常浏览。
- 软状态:由于不要求强一致性,所以BASE允许系统中存在中间状态(也叫软状态),这个状态不影响系统可用性,如订单的"支付中"、“数据同步中”等状态,待数据最终一致后状态改为“成功”状态。
- 最终一致:最终一致是指经过一段时间后,所有节点数据都将会达到一致。如订单的"支付中"状态,最终会变为“支付成功”或者"支付失败",使订单状态与实际交易结果达成一致,但需要一定时间的延迟、等待。
四、分布式事务的解决方案
4.1 2pc两段提交
两阶段提交协议(Two Phase Commitment Protocol)是分布式事务的基础协议。
在此协议中,一个事务协调器(TM, transaction manager)协调多个资源管理器(RM, resource manager)的活动;在一阶段所有资源管理器(RM)向事务管理器(TM)汇报自身活动状态,在第二阶段事务管理器(TM)根据各资源管理器(RM)汇报的状态,来决定各RM是执行提交操作还是回滚操作;具体描述如下:
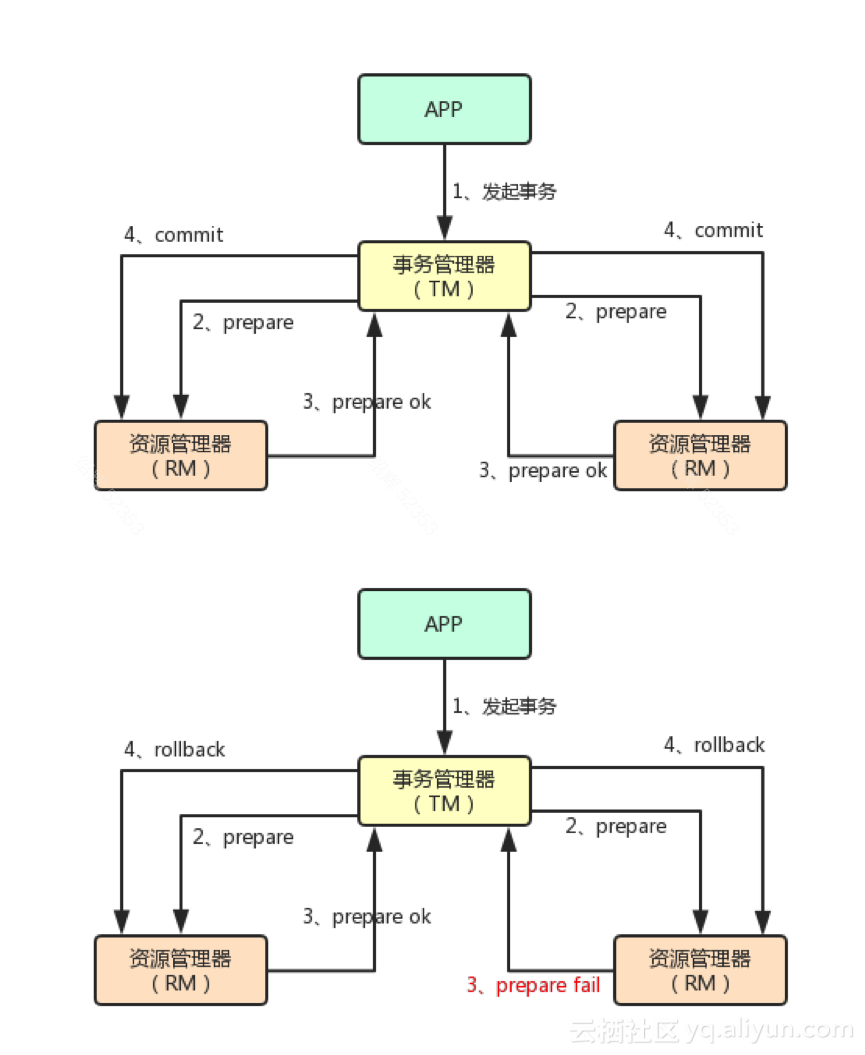
应用程序向事务管理器(TM)提交请求,发起方分布式事务;
一阶段,事务管理器(TM)联络所有资源管理器(RM),通知它们执行准备操作;
资源管理器(RM)返回准备成功,或者失败的消息给TM(响应超时算作失败);
二阶段,如果所有RM均准备成功,TM会通知所有RM执行提交;如果任一RM准备失败,TM会通知所有RM回滚;
通过事务管理器2阶段协调资源管理器,使所有资源管理器的状态最终都是一致的,要么全部提交,要么全部回滚。
4.1.1 2PC两段提交存在的问题
问题1:执行的性能是很低的。一般是传统事务的10倍以上。
问题2:TransactionManager是没有超时时间的。
问题3:TransactionManager存在单点故障的问题
4.2 3PC三段提交
三段提交在二段提交的基础上,引入了超时时间机制,并且在二段提交的基础上,又多了一个步骤,在提交事务之前,再询问一下,数据库的日志信息,是否已经完善。

4.2.1 undo
undo日志用于存放数据修改被修改前的值,假设修改 tba 表中 id=2的行数据,把Name=’B’ 修改为Name = ‘B2’ ,那么undo日志就会用来存放Name=’B’的记录,如果这个修改出现异常,可以使用undo日志来实现回滚操作,保证事务的一致性 。即是记录修改前的内容,方便事务的回滚
4.2.2 redo
redo是当数据库对数据做修改的时候,需要把数据页从磁盘读到buffer pool中,然后在buffer pool中进行修改,那么这个时候buffer pool中的数据页就与磁盘上的数据页内容不一致,如果这个时候发生非正常的DB服务重启,数据并没有同步到磁盘文件中,也就是会发生数据丢失,如果这个时候,能够在有一个文件,当buffer pool 中的data page变更结束后,把相应修改记录记录到这个文件,那么当DB服务发生宕机的情况,恢复DB的时候,也可以根据这个文件的记录内容,重新应用到磁盘文件,数据保持一致。即记录事务修改以后的内容
4.2.3 Buffer Pool
应用系统分层架构,为了加速数据访问,会把最常访问的数据,放在缓存(cache)里,避免每次都去访问数据库。
操作系统,会有缓冲池(buffer pool)机制,避免每次访问磁盘,以加速数据的访问。
MySQL作为一个存储系统,同样具有缓冲池(buffer pool)机制,以避免每次查询数据都进行磁盘IO。缓冲池(buffer pool)是一种常见的降低磁盘访问的机制;
缓冲池通常以页(page)为单位缓存数据;
4.3 TCC机制
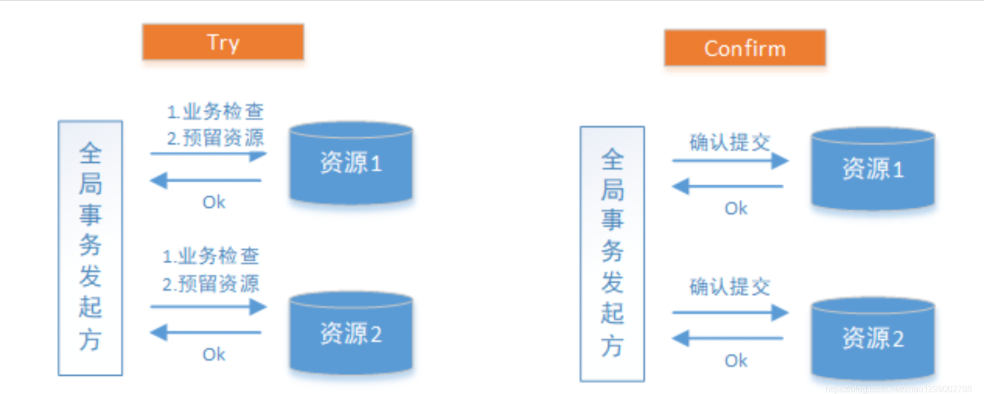
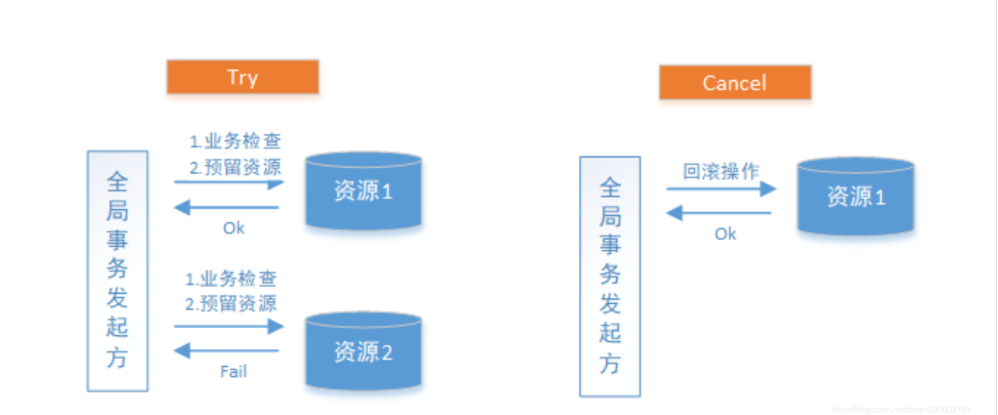
TCC(Try,Confirm,Cancel),和你的业务代码切合在一起。
Try:尝试去预执行具体业务代码。 下单订ing。。。
try成功了:Confirm:再次执行Confirm的代码。
try失败了:Cancel:再次执行Cancel的代码。
| TCC成功情况 |
|---|
 |
| TCC失败情况 |
|---|
 |
TCC分为三个阶段 :
Try阶段是做业务检查(一致性)及资源预留(隔离),此阶段仅是一个初步操作,它和后续的Confirm一起才能真正构成一个完整的业务逻辑。
Confirm阶段是做确认提交,Try阶段所有分支事务执行成功后开始执行Confirm。通常情况下,采用TCC则认为Confirm阶段是不会出错的。即 :只要Try成功,Confirm一定成功。若Confirm阶段真的出错了,需引入重试机制或人工处理。
Cancel阶段是在业务执行错误需要回滚的状态下执行分支事务的业务取消,预留资源释放。通常情况下,采用TCC则认为Cancel阶段也是一定成功的。若Cancel阶段真的出错了,需引入重试机制或人工处理。
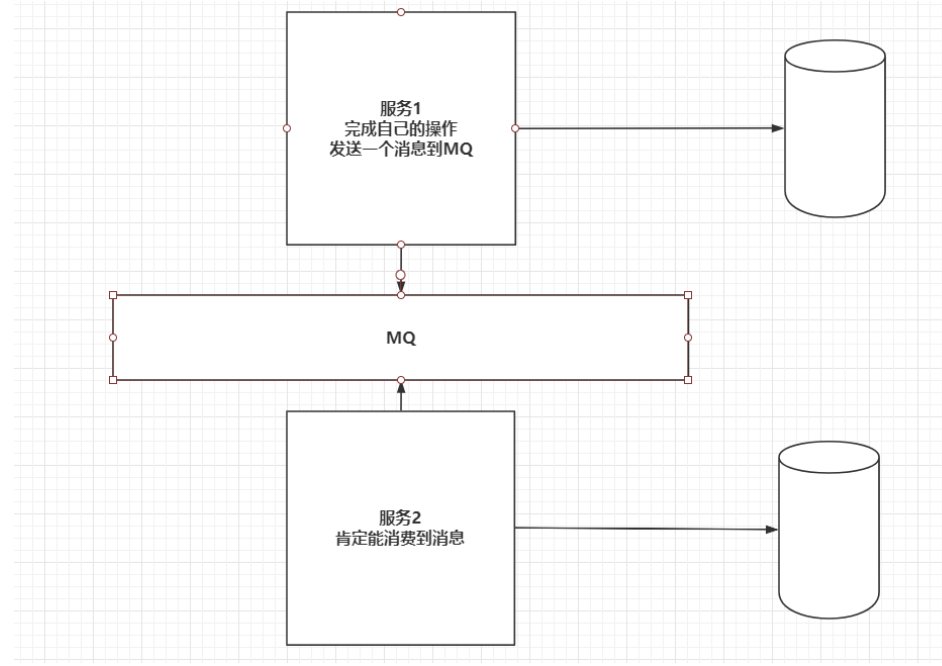
4.4 MQ分布式事务
RabbitMQ在发送消息时,confirm机制,可以保证消息发送到MQ服务中,消费者有手动ack机制,保证消费到MQ中的消息。
| MQ分布式事务 |
|---|
 |
总结
1、2pc
a)分为两个阶段
b)准备阶段:开启事务,执行的sql
c)提交阶段:事务的参与者要么回滚事务,要么提交事务
2、3PC
a)分为3ge阶段
b)准备阶段:开启事务,执行的sql
c)询问阶段:是否写入undo,redo日志文件成功
a)undo:记录修改的之前的日志,方便事务回滚
b)redo:记录修改的后的内容,DB宕机后方便恢复数据
b)Buffer pool:减少和磁盘的交互
d)提交阶段:事务的参与者要么回滚事务,要么提交事务
3、TCC
a)尝试执行:开启事务,执行sql
b)确认执行:删除日志
c)取消:读取日志,回滚数据
4、MQ
a)处理的过程
a)服务1操作完给MQ发送一个消息
b)服务2负责监听MQ,
c)由于MQ自带消息确认机制,可以包保证消息肯定能发出或者被消费。
b)如何保证操作数据库和发送消息队列是原子性的操作
a)操作数据库
b)写入表中一个消息
c)定时任务扫描这个表,再发送消息给队列中
4.5 TX-LCN实现分布式事务
基于三段提交和TCC实现的
TX-LCN分布式事务框架,LCN并不生产事务,LCN只是本地事务的协调工,LCN是一个高性能的分布式事务框架,兼容dubbo、springcloud框架,支持RPC框架拓展,支持各种ORM框架、NoSQL、负载均衡、事务补偿.
特性一览
1、一致性,通过TxManager协调控制与事务补偿机制确保数据一致性
2、易用性,仅需要在业务方法上添加@TxTransaction注解即可
3、高可用,项目模块不仅可高可用部署,事务协调器也可集群化部署
4、扩展性,支持各种RPC框架扩展,支持通讯协议与事务模式扩展
实现原理图
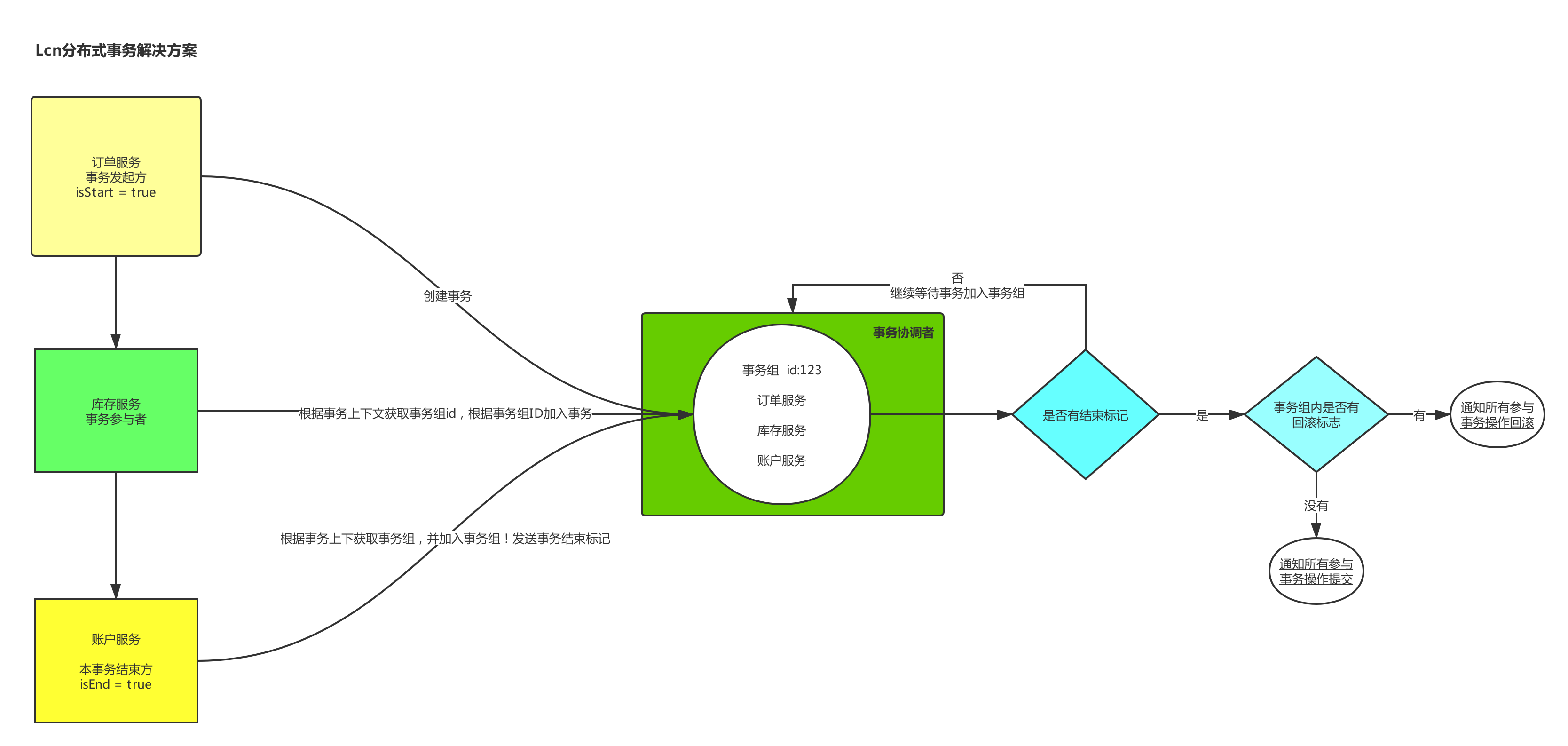
执行过程:
1、服务发起者会在事务协调者创建事务组,并且将这个事务加入到事务组,并生成一个事务组id
2、将这个事务组id放到了上下文中,其他事务参与者一直添加到事务组中,直到有结束标识出现
3、事务协调者向所有的事务参与者发送询问,是否能够进行提交,如果是全部返回可以提交,那么进行提交,否则只要有一个回滚的标记则整个事务组回滚
4、事务组执行操作后,释放所有资源