Spark数据倾斜
产生原因
首先RDD的逻辑其实时表示一个对象集合。在物理执行期间,RDD会被分为一系列的分区,每个分区都是整个数据集的子集。当spark调度并运行任务的时候,Spark会为每一个分区中的数据创建一个任务。大部分的任务处理的数据量差不多,但是有少部分的任务处理的数据量很大,因而Spark作业会看起来运行的十分的慢,从而产生数据倾斜(进行shuffle的时候)。
数据倾斜只会发生在shuffle过程中。这里给大家罗列一些常用的并且可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出现数据倾斜时,可能就是你的代码中使用了这些算子中的某一个所导致的。例子:
多个key对应的values,比如一共是90万。可能某个key对应了88万数据,被分配到一个task上去面去执行。另外两个task,可能各分配到了1万数据,可能是数百个key,对应的1万条数据。这样就会出现数据倾斜问题。解决方法
(1):数据混洗的时候,使用参数的方式为混洗后的RDD指定并行度实现原理:提高shuffle操作的并行度,增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据,举例来说,如果原本有5个key,每个key对应10条数据,这5个key都是分配给一个task的,那么这个task就要处理50条数据。而增加了shuffle read task以后,每个task就分配到一个key,即每个task就处理10条数据,那么自然每个task的执行时间都会变短了(很简单,主要给我们所有的shuffle算子,比如groupByKey、countByKey、reduceByKey。在调用的时候,传入进去一个参数。那个数字,就代表了那个shuffle操作的reduce端的并行度。那么在进行shuffle操作的时候,就会对应着创建指定数量的reduce task)
方法的缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限,该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个key对应的数据量有100万,那么无论你的task数量增加到多少,这个对应着100万数据的key肯定还是会分配到一个task中去处理,因此注定还是会发生数据倾斜的。
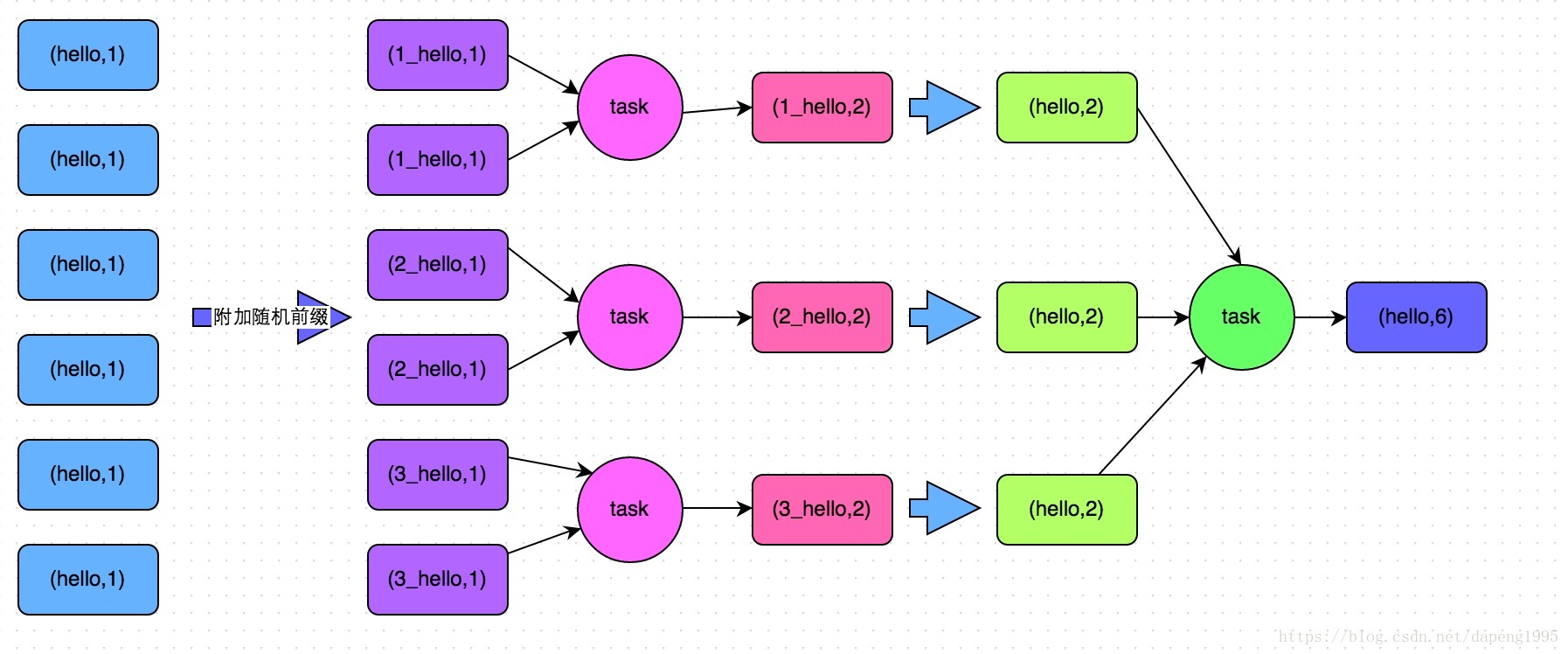
(2)使用随机key实现双重聚合(groupByKey、reduceByKey比较适合使用这种方式)
实现原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。
如下图所示:
代码:
object DataLean {
def main(args: Array[String]): Unit = {
//创建Spark配置对象
val conf = new SparkConf();
conf.setAppName("WordCountScala")
conf.setMaster("local") ;
//通过conf创建sc
val sc = new SparkContext(conf);
val rdd1=sc.textFile("F:/spark/b.txt",3);
rdd1.flatMap(_.split(" ")).map((_,1)).map(t=>{
val word=t._1
val r=Random.nextInt(100)
(word+"_"+r,1)
}).reduceByKey(_+_).map(t=>{
val word=t._1
val count=t._2
val w=word.split("_")(0)
(w,count)
}).reduceByKey(_+_).saveAsTextFile("F:/spark/lean/out")
}
}(3):过滤少数导致倾斜的key
如果我们判断那少数几个数据量特别多的key,对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉那少数几个key。比如,在Spark SQL中可以使用where子句过滤掉这些key或者在Spark Core中对RDD执行filter算子过滤掉这些key。如果需要每次作业执行时,动态判定哪些key的数据量最多然后再进行过滤,那么可以使用sample算子对RDD进行采样,然后计算出每个key的数量,取数据量最多的key过滤掉即可。
参考文章:
1.https://blog.csdn.net/qq_38247150/article/details/80366769
2.https://blog.csdn.net/qq_38534715/article/details/78707759