一、建立ik中文分词器
1、下载ik中文分词器
进入https://github.com/medcl/elasticsearch-analysis-ik
使用第一种方式安装,进入https://github.com/medcl/elasticsearch-analysis-ik/releases

选择版本7.4.2 。和ES7.4.2的版本保持一致。
下载elasticsearch-analysis-ik-7.4.2.zip
将下载的分词器放到 192.168.127.130 这台服务器的 /home/tools 路径下

2、安装分词器
解压 unzip elasticsearch-analysis-ik-7.4.2.zip /usr/local/eleasticsearch-7.4.2/plugins/ik

tar.gz 格式解压如下
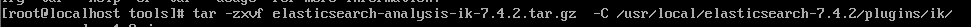
前提是ik这个文件夹存在。
3、重启ES
ps -ef | grep elasticsearch
kill xxx
切换成esuser用户
cd /user/local/elasticsearch-7.4.2/bin
./elasticsearch -d
这样中文分词器就安装成功了。
4、测试中文分词器
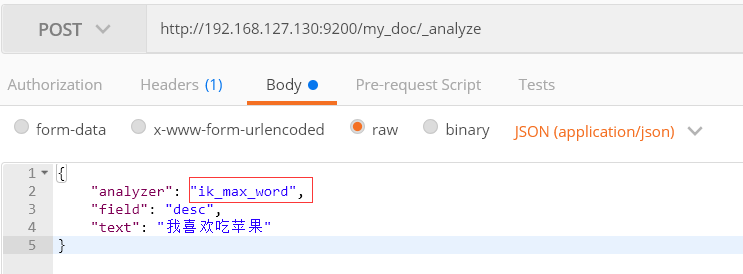
分析器 analyzer值为
ik_max_word : 最细粒度拆分
ik_smart : 最粗粒度拆分
返回分词结果为:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "喜欢吃",
"start_offset": 1,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "喜欢",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 2
},
{
"token": "吃",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 3
},
{
"token": "苹果",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 4
}
]
} 可以看出中文分词器已经有效果了。
二、自定义中文词库
1、如下图,对“我在中华学习网学习”进行分词
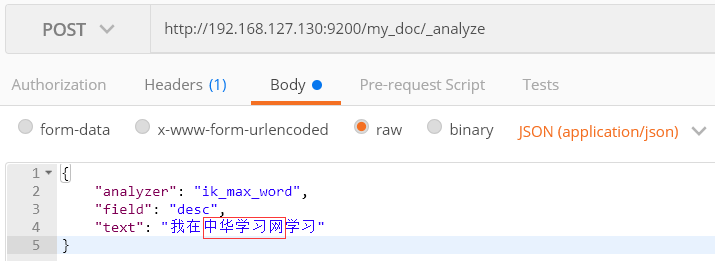
返回结果
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "在",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中华",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": "学习网",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 3
},
{
"token": "学习",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 4
},
{
"token": "网",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 5
},
{
"token": "学习",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 6
}
]
} 可以看到“中华学习网” 并没有做为一个分词。
那么,如何将“中华学习网”作为一个词汇呢?
进入ik插件 cd /usr/local/elasticsearch-7.4.2/plugins/ik/config
vi IKAnalyzer.cfg.xml

vi custom.doc

然后保存。重启ES。
2、测试自定义分词
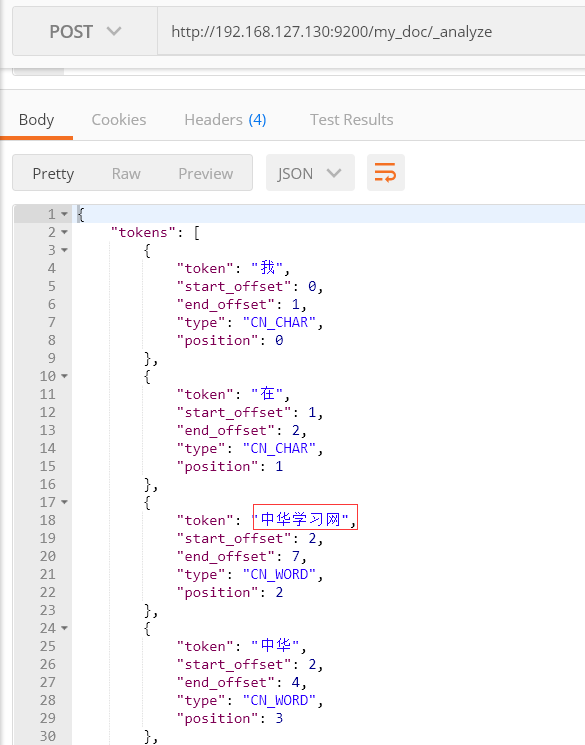
可以看到,自定义分词“中华学习网”已经生效了。