数据库介绍
数据库是在计算机出现以后,为了解决计算机存储问题而创建,数据库中包含表,表当中才是数据。
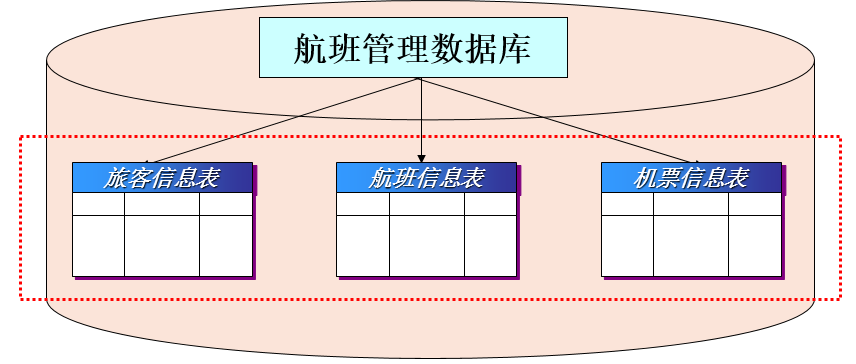
数据库的发展史
1. 萌芽阶段
所有存储依赖的都是文件,安全性低,查找非常困难。
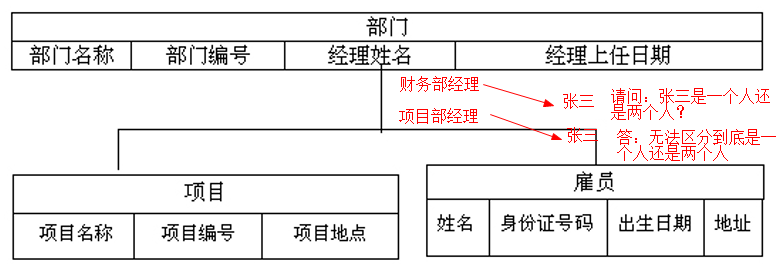
2. 层次模型
1). 优点:查询分类的效率高;
2). 缺点:导航结构:如果查找同类别数据,效率低。
数据不完整(如下图)
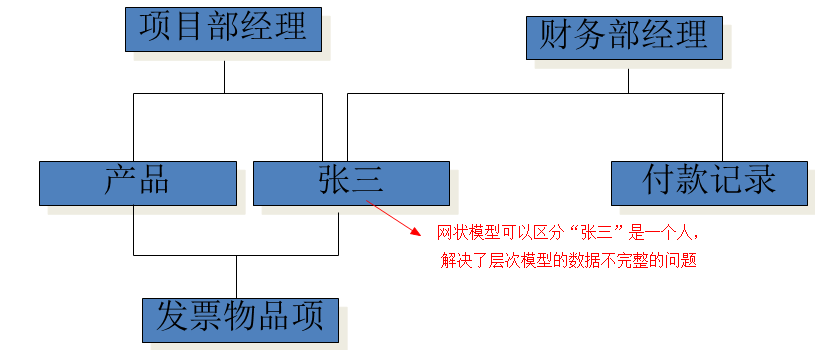
3. 网状模型
数据不完整性:我们认为每一行数据之间是独立不相关的,网状模型解决了数据不完整的问题,但是依然没有导航结构。
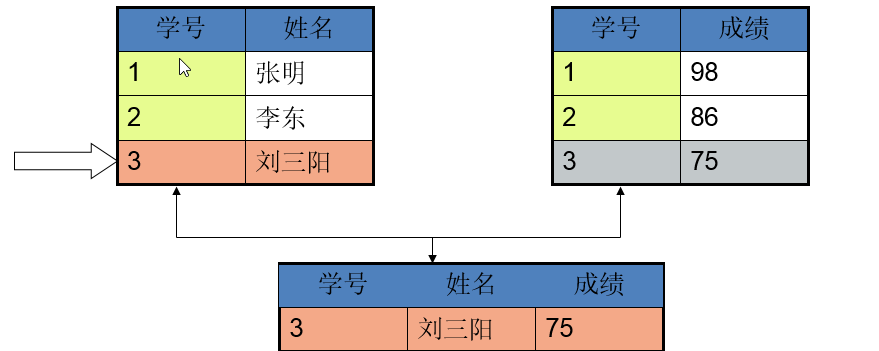
4. 关系模型
现在主流的数据库模型。特点:每张表都是独立的,没有导航结构,表和表之间通过公共字段建立关系,注意:公共的字段,名字可以不一样,但是数据类型必须一致,表达的含义必须一致.数据类型一致,但不一定是公共字段。
优点:有导航结构;
缺点:关系型数据库操作不便捷(关系可能比较复杂),执行效率低下。

补充:在项目中不是每一个业务都需要关系型数据库,可以使用非关系型数据库(NoSql)
简单概念认识
记录,字段,行列,表的属性,字段的属性。
1. 一条记录我们称之为一行数据;
2. 一个字段称之为一列;
3. 表的属性就是字段;
4. 字段的属性就是该字段的功能;
5. 数据冗余指的是数据重复率。
【补充】:
1)冗余只能减少,不能杜绝;
2)冗余减少了,表的体积就减少了,更新速度提高了,保证了数据额完整性;
3)减少了冗余,但是表的数量增加了,多表查询的效率降低了,在项目中,宁可减少数据冗余也要使用多表查询。
数据的完整性
正确性 + 准确性 = 数据的完整性
分析:人的年龄(age int)int数据类型最大11个长度,正确性如何?准确性如何? ===> 答:正确但是不准确
SQL语句
结构化查询语言(Structured Query Language)简称SQL ,是一种特殊的编程语言,是一种数据查询和程序设计语言。主要作用:用于存储数据和查询数据,更新和管理数据。
关系型数据库种类:
| 关系型数据库 | 公司 | 扩展 |
|---|---|---|
| access | 微软 | SQL |
| SQL-Server | 微软 | T-SQL |
| Oracle(收费) | 甲骨文 | PL/SQL |
| MySQL(收费失败) | 甲骨文 | MySQL |
| MariaDB | 开源社区 | MySQL |
下面主要介绍关系型数据库MySQL相关操作:
(1).启动MySQL
使用cmd终端开启客户端:
1 net strat[stop] mysql57第三方服务可以是.exe文件开启:进入mysql目录中的bin目录中,执行mysqld.exe
(2).连接MYSQL服务器
在cmd中输入:
1 mysql -hlocalhost -uroot -ppwd -P3306 2 ''' 3 loaclhost 代表本地IP地址 4 host 主机 -h 5 username 用户名 -u 6 passwd 密码 -p(小写字母) 7 port 端口号 -P(大写字母) 8 '''
(3).断开链接
1. exit 2. quit 3. q
数据库的库操作
1 '''(1)创建数据库语法:create database [if not exists] `数据库名` charset=字符编码(utf8mb4);''' 2 # 一般,创建已经存在的数据库会报错 3 create database `firstdb` charset=utf8mb4; 4 5 '''(2)查看数据库集''' 6 show databases; 7 8 '''(3)查看建库语句''' 9 show create database `数据库名`; 10 11 '''(4)修改数据库,只能修改数据库的字符集''' 12 alter database `数据库名` charset=你要修改的字符集; 13 14 '''(5)删除数据库''' 15 drop database [if exists] `数据库名`; 16 17 '''(6)选择数据库''' 18 use `数据库名`;
数据库的表操作
注意:创建表之前必须先选择某一个数据库
1)创建表的语法:
1 create table [if not exists] `表名`( 2 字段 属性 3 )engine=myisam charset=utf8mb6;
示例代码:
1 create table [if not exists] `用户表1`( 2 id int not null auto_increment primary key comment '主键字段', 3 username char(64) comment '用户名' default 'root', 4 password varchar(64) comment '密码' 5 )engine=myisam charset=utf8mb4; 6 7 create table [if not exists] `用户表2`( 8 id int not null auto_increment primary key comment '主键字段', 9 username char(64) comment '用户名' default 'root', 10 password varchar(64) comment '密码' 11 )engine=innodb charset=utf8mb4;
注意:方法体中的最后一句不能加上逗号。
参数说明:
1.null | not null 字符是否为空,null是默认值
2.default 默认值,在null的时候配合使用
3.auto_increment 自增长,配合primary key
4.primary key 主键
5.engine 表的存储引擎(innodb | myisam),innodb是默认引擎
innodb 和 myisam的区别:
不同的引擎记录数据的方式也不一样。一个数据库对应一个文件夹,一张表对应一个文件。
myisam表引擎由三个文件组成:
1 demo1.frm -> 表的结构 2 demo1.MYD -> 保存数据的 3 demo1.MYI -> 保存索引的
innodb表引擎由两个文件组成:
1 demo1.frm -> 表结构+表索引 2 demo1.ibd -> 表中的数据
mysql中myisam的文件管理方式比较松散,myisam可以随便的剪切;innodb文件管理方式比较严格,像是一座监狱,不能移动。
给指定的数据库建表有两种方法:
1 '''1.先选择好库 再建立表''' 2 create table `demo1`( 3 id int primary key auto_increment, 4 name char(32) 5 ); 6 7 '''2.指定库的方式''' 8 create table firstdb.demo1( 9 id int primary key auto_increment, 10 name char(32) 11 );
表操作:
-- 1).显示表 show tables; -- 2).显示建表语句:show create table `表名`G show create table `demo1`G -- 3).删除表 drop table [if exists] `表1`,`表2`; -- 4).查看表结构:desc `表名` | describe `表名`; desc demo1;
5). 修改表
-- 1.修改表名 alter table `老名字` rename `新名字`; -- 2.修改字段名:alter table `表名` change `原字段名` `新字段名` 字段属性; alter table `b` change `sex` `sexx` char(3); -- 3.修改字段的属性:alter table `表名` modify `字段名` 字段属性; alter table `b` modify `age` int comment '年纪'; -- 4.修改字段的位置 alter table `表名` change `原字段名` `新字段名` after `字段名`; -- 5.修改表的引擎 alter table `表名` engine=innodb|myisam; -- 6.移动表到指定的数据库 alter table `表名` rename 数据库名.表名;
增加一个字段:
-- 7.增加一个字段:alter table `表名` add `字段名` 字段属性; alter table `b` add `age` int comment '年龄'; -- 将手机号的位置添加在id的后面 alter table `b` add `mobile` char(11) after id; -- 将字段添加在第一个位置 alter table `b` add `sex` bool first;
6). 复制表
注意:复制表是SQL语句,不是数据库或表的操作语句
-- create table `新表名` select * from `要被复制的表名`; create table `a` select * from `b`;
特点:
1.把数据可以复制过来
2.不能复制主键
这里可以通过修改属性的方法添加一个主键。
-- create table `新表名` like `要被复制的表名`; create table `c` like `b`;
特点:
1.它可以复制主键
2.但是它不能复制数据
-- 可以拷贝数据,将查询的数据插入到新的表中 insert into c select * from b; -- 弊端:如果表中有百万条数据,效率太慢
数据库的数据操作
a. 插入数据
关键字:insert
-- 挑选可用字段 insert into b(`sexx`,`id`,`mobile`,`name`,`age`) values('男',null,'123','jack',20),('男',null,'123','jack',20); -- 默认使用全部字段,支持一次性插入多条 insert into b values('男',null,'123','jack',20),('男',null,'223','jack',70); -- 一次插入一条,mysql中数值类型可以自动转变为字符串 insert into b set `sexx`='男',`mobile`=12345678901,`name`='tom',`age`=23;
b.修改数据
关键字:update
/* 修改指定的一个条件,where以后的就是条件 */ update `b` set `mobile`=110 where id=1; /* 指定多个条件 */ update `b` set `mobile`=110,`age`=18 where id=2 and `name`='jack'; /* 作死性,不指定条件 */ update `b` set `mobile` = 110;
c.删除数据
关键字:delete
-- 删除单个数据 delete from `b` where id=3; -- 删除所有数据 delete from `b` where True; --删出所有数据 delete from `b`; /* id是唯一的,被删除以后,永久保留(数据恢复) 销毁表,在按照原来的建表语句恢复表,数据全消失,id依然从1开始 */ -- 重置,在开发阶段,经常用到 truncate `表名`;
以上为mysql数据库增删改的简单操作。