摘要:
前言 前言假设您执行一个脚本(.py)用例一分钟,那么100个脚本需要100分钟。当您的用例达到1000时,需要1000分钟,即超过16小时。。。这使用多线程。理论上,打开两个线程可以节省一半的时间,打开五个线程可以节约五倍的时间。
假设执行一条脚本(.py)用例一分钟,那么100个脚本需要100分钟,当你的用例达到一千条时需要1000分钟,也就是16个多小时。。。
那么如何并行运行多个.py的脚本,节省时间呢?这就用到多线程了,理论上开2个线程时间节省一半,开5个线程,时间就缩短五倍了。
1.项目结构跟之前的设计是一样的:
- case test开头的.py用例脚本
- common 放公共模块,如HTMLTestRunner
- report 放生成的html报告
- run_all.py 用于执行全部脚本
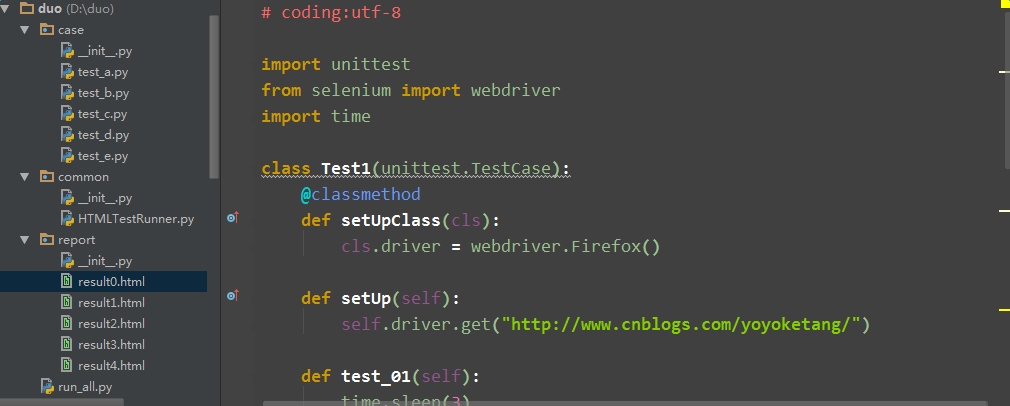
2.case文件夹里面用例参考
# coding:utf-8
import unittest
from selenium import webdriver
import time
class Test1(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Firefox()
def setUp(self):
self.driver.get("http://www.cnblogs.com/yoyoketang/")
def test_01(self):
time.sleep(3)
t = self.driver.title
print t
# 随便写的用例,没写断言
def test_02(self):
time.sleep(3)
t = self.driver.title
print t
h = self.driver.window_handles
print h
# 随便写的用例,没写断言
@classmethod
def tearDownClass(cls):
cls.driver.quit()
if __name__ == "__main__":
unittest.main()
1.多线程设计思路:
- 先写一个run的函数
- 保证for循环能跑的通
- 在run函数上加个装饰器 @threads(n),n是线程数
2.run_all参考代码
# coding=utf-8
import unittest
from common import HTMLTestRunner
import os
from tomorrow import threads
# python2需要这三行,python3不需要
import sys
reload(sys)
sys.setdefaultencoding('utf8')
# 获取路径
curpath = os.path.dirname(os.path.realpath(__file__))
casepath = os.path.join(curpath, "case")
reportpath = os.path.join(curpath, "report")
def add_case(case_path=casepath, rule="test*.py"):
'''加载所有的测试用例'''
discover = unittest.defaultTestLoader.discover(case_path,
pattern=rule,
top_level_dir=None)
return discover
@threads(3)
def run_case(all_case, report_path=reportpath, nth=0):
'''执行所有的用例, 并把结果写入测试报告'''
report_abspath = os.path.join(report_path, "result%s.html"%nth)
fp = open(report_abspath, "wb")
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,
title=u'自动化测试报告,测试结果如下:',
description=u'用例执行情况:')
# 调用add_case函数返回值
runner.run(all_case)
fp.close()
if __name__ == "__main__":
# 用例集合
cases = add_case()
# 之前是批量执行,这里改成for循环执行
for i, j in zip(cases, range(len(list(cases)))):
run_case(i, nth=j) # 执行用例,生成报告
3.生成报告,这里生成的报告是多个的,每个.py脚本生成一个html的报告,接下来遇到的难点就是合并报告了
如何把多个html报告合并成一个报告呢?