1、什么是字节对齐
在用sizeof运算符求算某结构体所占空间时,并不是简单地将结构体中所有元素各自占的空间相加,这里涉及到内存字节对齐的问题。从理论上讲,对于任何变量的访问都可以从任何地址开始访问,但实际上访问特定类型的变量只能在特定的地址访问,这就需要各个变量在空间上按一定的规则排列, 而不是简单地顺序排列,这就是内存对齐。
2、为什么要字节对齐
- 某些平台只能在特定的地址处访问特定类型的数据;
- 提高存取数据的速度。比如有的平台每次都是从偶地址处读取数据,对于一个int型的变量,若从偶地址单元处存放,则只需一个读取周期即可读取该变量;但是若从奇地址单元处存放,则需要2个读取周期读取该变量。
根本原因在于CPU访问数据的效率问题。假设上面整型变量的地址不是自然对齐,比如为0x00000002,则CPU如果取它的值的话需要访问两次内存,第一次取从0x00000002-0x00000003的一个short,第二次取从0x00000004-0x00000005的一个short然后组合得到所要的数据,如果变量在0x00000003地址上的话则要访问三次内存,第一次为char,第二次为short,第三次为char,然后组合得到整型数据。而如果变量在自然对齐位置上,则只要一次就可以取出数据。一些系统对对齐要求非常严格,比如sparc系统,如果取未对齐的数据会发生错误,举个例:
char ch[8];
char *p = &ch[1];
int i = *(int *)p;
运行时会报segment error,而在x86上就不会出现错误,只是效率下降。
3、字节对齐策略
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
先让我们看四个重要的基本概念:
a. 数据类型自身的对齐值:对于char型数据,其自身对齐值为1,对于short型为2,对于int,float,double类型,其自身对齐值为4,单位字节;
b. 结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值;
c. 指定对齐值:#pragma pack (value)或__attribute__((aligned(value))) 时的指定对齐值value;
d. 数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中小的那个值;
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
字节对齐策略如下:
- 数据成员自身对齐,对齐值为:min{ 类型自身对齐值,设定值 };
- 结构体或类对齐,对齐值为:min{ max{成员对齐值},设定值 };
PS:由于在x86下,GCC默认按4字节对齐
4、字节对齐实例
下面看一下sizeof在计算结构体大小的时候具体是怎样计算的
(1) 空结构体
typedef structnode
{
}S;
则sizeof(S)=1;或sizeof(S)=0;
在C++中占1字节,而在C中占0字节。
(2)不同的成员类型
typedef structnode1
{
inta;
charb;
shortc;
}S1;
则sizeof(S1)=8。这是因为结构体node1中最长的数据类型是int,占4个字节,因此结构体以4字节对齐,则该结构体的内存结构(黄色为补齐字节,绿色为占用字节,一个空格表示一个字节):
总共占8字节
(3)成员不同顺序
typedef structnode2
{
chara;
intb;
shortc;
}S2;
则siezof(S3)=12.最长数据类型为int,占4个字节。因此结构体以4字节对齐,内存空间存放方式:
总共占12个字节
(4)含有静态数据成员
typedef structnode3
{
inta;
shortb;
staticintc;
}S3;
则sizeof(S3)=8.这里结构体中包含静态数据成员,而静态数据成员的存放位置与结构体实例的存储地址无关(注意只有在C++中结构体中才能含有静态数据成员,而C中结构体中是不允许含有静态数据成员的)。其在内存中存储方式如下:
总共占用8个字节,变量c是单独存放在静态数据区的,因此用siezof计算其大小时没有将c所占的空间计算进来。
(5) 结构体嵌套
typedef structnode4
{
boola;
S1 s1; // 由前可知4字节对齐
shortb;
}S4;
则sizeof(S4)=16。是因为s1占8字节,而s1中最长数据类型为int,占4个字节,bool类型1个字节,short占2字节,因此结构体以4字节对齐,则存储方式为
(6)更复杂成员
typedef structnode5
{
boola;
S1 s1; // 由前可知4字节对齐
doubleb;
intc;
}S5;
则sizeof(S5)=32。是因为s1占8字节,而s1中最长数据类型为int,占4字节,而double占8字节,因此结构体以8字节对齐,则存放方式为: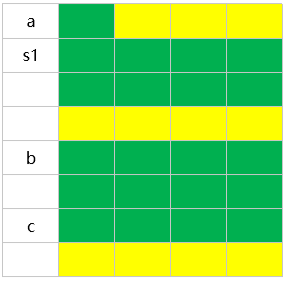
(7)使用了#pragma pack(n)
若需取消强制对齐方式,则可用命令#pragma pack()
如在程序开头使用命令#pragma pack(4),对于下面的结构体
typedef structnode5
{
boola;
S1 s1;
doubleb;
intc;
}S5;
则sizeof(S5)=24.因为强制以4字节对齐,而S5中最长数据类型为double,占8字节,因此结构体以4字节对齐。在内存中存放方式为: 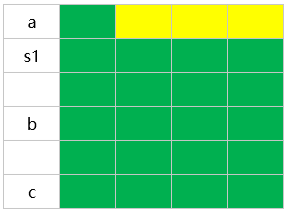
(8)union 类型 内存对齐
union DATE
{
char a;
int i[5];
double b;
};
DATE max;
cout<< sizeof(max) << endl;
这个问题很好回答,并且我把这个问题归结于基本概念题(就是入门书必须介绍的)。我想一般来说,做过内存管理的,对这个语言特性肯定不会陌生。
摘几句The C Programming Language里面讲述这个问题的原话,以说明读书还是必要的:
①联合就是一个结构;
②它的所有成员相对于基地址的偏移量都为0;
③此结构空间要大到足够容纳最“宽”的成员;
④并且,其对齐方式要适合于联合中所有类型的成员。
该结构要放得下int i[5]必须要至少占4×5=20个字节。如果没有double的话20个字节够用了,此时按4字节对齐。但是加入了double就必须考虑double的对齐方式,double是按照8字节对齐的,所以必须添加4个字节使其满足8×3=24,也就是必须也是8的倍数,这样一来就出来了24这个数字。综上所述,最终联合体的最小的size也要是所包含的所有类型的基本长度的最小公倍数才行。
PS:联合的使用
联合在存储分配的时候用很多,因为很少有像存储分配这样需要给多种不同类型的变量分配空间而又打算尽可能的节约内存的,这很适合联合的特性。上述对齐的方式有个很有趣的用法也就常在存储分配里面使用。(下面依旧用The C Programming Language中的例子作答)
typedef long Align;
union header {
struct {
union header *ptr;
unsigned size;
} s;
Align x;
}
这里的Align有什么用?作用只有一个,就是强迫分配的结构体按long的长度对齐。
PS:对齐是低地址到高地址对齐的,如下:
union DATE
{
char a;
int i[5];
double b;
};
DATE max;
max.a = 0x12;
printf(“0x%X/n”,max.i[0]);
printf(“0x%X/n”,max.i[1]);
输出为:
0xCCCCCC12
0xCCCCCCCC
5、reference
http://www.360doc.com/content/16/0510/14/7510008_557849893.shtml
https://blog.csdn.net/geekdonie/article/details/13627257
https://i.cnblogs.com/EditPosts.aspx?postid=11553650