一、欠拟合
首先欠拟合就是模型没有很好的捕捉到数据特征,不能够很好的拟合数据,如下面的例子:
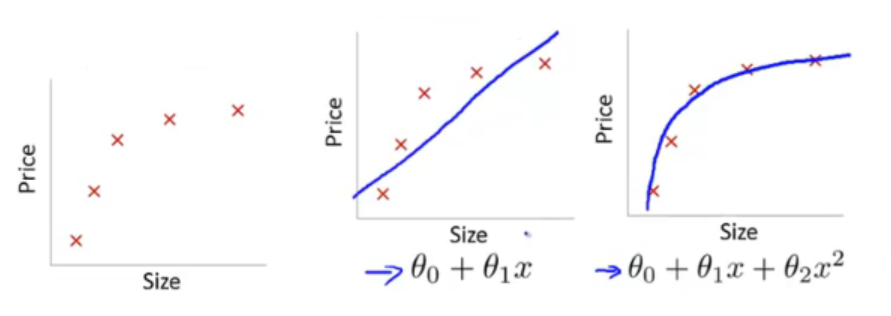
左图表示size和prize关系的数据,中间的图就是出现欠拟合的的模型,不能够很好的拟合数据,如果在中间的多项式上再加一个二项式,就可以很好的拟合数据了,如右图所示。
解决方法:
1、添加其它的特征项,有时候模型欠拟合是数据的特征项不够造成的,可以添加其它的特征项来很好的解决,例如"组合","范化",”相关性“三类特征是特征添加的重要手段,无论在什么场合,都可以照葫芦画瓢,总会得到满意的效果。除上面的特征外,“上下文特征”、“平台特征”等等,都 可以作为特征添加的首选项。
2、添加多项式特征,这个在机器学习算法里用的很普遍,例如上面的例子,将线性模型加入二次项或者三次项使模型范化能力更强
3、减少正则化参数,正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,则需要减少正则化参数
二、过拟合
通俗一点来说是模型把数据学习的太彻底,以至于把数据中的噪声特征也学到了,这样就会导致后期测试的时候不能很好的识别数据,即不能正确的分类数据,模型泛化能力太差,例如下面的例子:
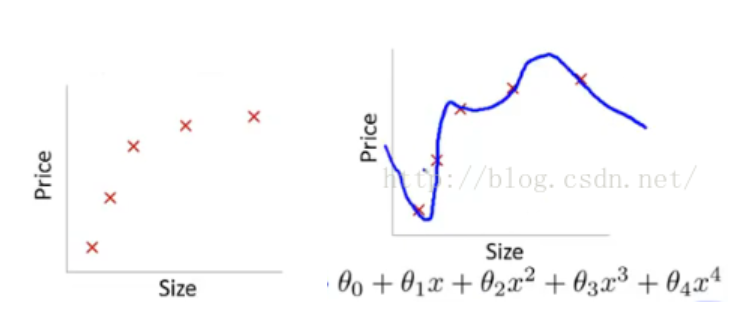
上图左边表示size和prize的关系,我们学习到的模型曲线如右图所示,虽然在训练的时候很好的匹配数据,但是很显然扭曲了曲线,不是真实的size和prize曲线。
解决方法:
1、重新清洗数据,导致过拟合的一个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。
2、增大数据的训练量,还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小
3、采用正则化方法。正则化方法包括L0正则,L1正则和L2正则,而正则一般是在目标函数之后加上对于的范数,但是在机器学习中一般用L2正则
4、采用dropout方法。这个方法在神经网络中很常用。dropout方法是imageNet中提出的一种方法,通俗一点讲就是dropout方法在训练时让神经元以一定概率的不工作,具体看下图:

如上图所示,左图(a)是没有使用dropout方法的标准神经网络,右边(b)图是在训练时使用了dropout方法的神经网络,即在训练的时候以一定的概率p来跳过一定的神经元