正则化的主要作用是防止过拟合,对模型添加正则化项可以限制模型的复杂度,使得模型在复杂度和性能达到*衡。
常用的正则化方法有L1正则化和L2正则化。L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。 L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归。但是使用正则化来防止过拟合的原理是什么?L1和L2正则化有什么区别呢?
1.1 L1-norm L2-norm
L1正则化与L2正则化又称为L1-norm,L2-norm。即是L1范数与L2范数。
范数:范数是衡量某个向量空间或者矩阵每个向量的长度或者大小。
范数的数学的一般定义为:
2. 区别于联系L1范数: p=1时,表示所有元素的绝对值之和。
L2范数, p=2时,表示某个向量所有元素*方和再开根。也就是我们所说的欧几里距离
| L1-norm | L2-norm | |
|---|---|---|
| 稀疏解 | 可获得 | 不可获得 |
| 正则化方式 | 减少特征数量(获得稀疏解) | 减少w的大小 |
| 鲁棒性 | 具有(对异常值不敏感) |
3.1 直观理解
当模型较为复杂的时候,模型尝试去兼顾每一个点,导致模型函数处于一种动荡的状态。这就意味着函数在某个很小的区间导数非常大,由于自变量可大可小,所以只要系数足够大,导师值就很大。当我们的参数(lambda)增加的时候,为了是目标函数减少,所有的( heta)都会一定程度上的减小。从而达到了解决过拟合的目的。
Ridge:
如果发生了过拟合,那么( heta)一般都是比较大的值,加入(lambda)过后只要控制(lambda)的大小。
(lambda)很大的时候,$$ heta$$就会变得很小。
就达到了约束数量庞大的特征的目的。
3.2 贝叶斯角度理解
文章《深入理解线性回归算法(二):正则项的详细分析》提到,当先验分布是拉普拉斯分布时,正则化项为L1范数;当先验分布是高斯分布时,正则化项为L2范数。本节通过先验分布来推断L1正则化和L2正则化的性质。
画高斯分布和拉普拉斯分布图(来自知乎某网友):
由上图可知,拉普拉斯分布在参数w=0点的概率最高,因此L1正则化相比于L2正则化更容易使参数为0;高斯分布在零附*的概率较大,因此L2正则化相比于L1正则化更容易使参数分布在一个很小的范围内。
3.3 纯数学解释
记录他们的损失函数为
假设只有一个变量x和一个参数w,模型为
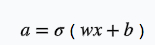
损失函数为
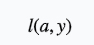
加上L1正则后损失函数为
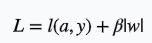
损失函数对w求导
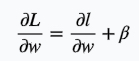
第一项是本来就有的,我们用一个常数字母c代替
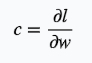
更新w
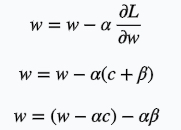
可以看到w更新的时候多减了一项,所以它会更快的趋向0
同理看看L2正则的情况
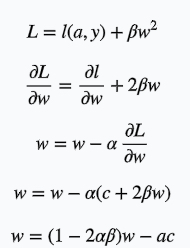
可以看到w的系数变小了,它的更新方式跟L1不一样。
因此,可以说L1会让系数趋向于0,而L2会让系数变小。
3.4 PRML的图形角度分析
因为L1正则化在零点附*具有很明显的棱角,L2正则化则在零附*比较*缓。所以L1正则化更容易使参数为零,L2正则化则减小参数值,如下图。
(1)L1正则化使参数为零 (2)L2正则化使参数减小
3.5 知乎点赞最多的图形角度分析
函数极值的判断定理:
(1)当该点导数存在,且该导数等于零时,则该点为极值点;
(2)当该点导数不存在,左导数和右导数的符号相异时,则该点为极值点。
如下面两图:
左图对应第一种情况的极值,右图对应第二种情况的极值。本节的思想就是用了第二种极值的思想,只要证明参数w在0附*的左导数和右导数符合相异,等价于参数w在0取得了极值。
图形角度分析
损失函数L如下:
黑色点为极值点x1,由极值定义:L'(x1)=0;
含L2正则化的损失函数:
由结论可定性的画含L2正则化的图:
极值点为黄色点,即正则化L2模型的参数变小了。
含L1正则化的损失函数****:
因此,只要C满足推论的条件,则损失函数在0点取极值(粉红色曲线),即L1正则化模型参数个数减少了。
How to decide which regularization (L1 or L2) to use?
Is there collinearity among some features? L2 regularization can improve prediction quality in this case, as implied by its alternative name, "ridge regression." However, it is true in general that either form of regularization will improve out-of-sample prediction, whether or not there is multicollinearity and whether or not there are irrelevant features, simply because of the shrinkage properties of the regularized estimators. L1 regularization can't help with multicollinearity; it will just pick the feature with the largest correlation to the outcome. Ridge regression can obtain coefficient estimates even when you have more features than examples... but the probability that any will be estimated precisely at 0 is 0.
What are the pros & cons of each of L1 / L2 regularization?
L1 regularization can't help with multicollinearity. L2 regularization can't help with feature selection. Elastic net regression can solve both problems. L1 and L2 regularization are taught for pedagogical reasons, but I'm not aware of any situation where you want to use regularized regressions but not try an elastic net as a more general solution, since it includes both as special cases.
实际使用过程中,如果数据量不是很大,用L2的精度要好。
多重共线性(multicollinearity)指的是你建模的时候,解释变量之间有高度相关性。

5. 参考
周志华《机器学习西瓜书》