写这篇博客的缘由:
对于专利《基于边缘自适应的高效图像盲去模糊方法》,是关于图像处理方面的,平时写代码和分析问题时一套一套的,很长时间不讲突然要向别人说就磕磕巴巴的也说不清楚。遂有了要认真思考,并陈述总结自己所学的想法。虽然以后并不定做盲去模糊方面的东西,但所学总有相通。遂写下这篇文章描述整体思路。
- 背景:拍照过程中相机抖动、离焦、散焦或目标物体移动等,带来图像模糊。
- 盲去模糊可以概括为:“模型的提出(最优化式的提出)”和“算法求解”两个方面。
- 盲去模糊的处理模型:
一般模糊图像y的数学模型是用清晰图像x卷积模糊核k加上加性高斯白噪声表示。图像盲去模糊是一个欠定的图像逆问题。(盲去模糊处理中“数据项”的根据)
为了获得清晰的数字图像,需要利用图像的先验知识,如何挖掘、利用准确的图像先验知识是图像盲去模糊的关键因素。(盲去模糊处理中“正则项”的根据)
4. 我们提出来的盲去模糊模型(正则项部分)及其根据
传统的正则项:L2范数、Lp 范数、此外,人们也提出利用学习的方法来获得自适应的滤波器以代替梯度算子。
利用上述现有的图像先验模型,通常难以得到一个清晰的图像。这是因为,上述先验图像模型对于模糊图像能获得更小的正则项能量,从而在目标函数能量最小化求解过程中得到原始模糊图像的局部极值。为了获得清晰图像,通常需要采用一些复杂的方法来对图像边缘进行锐化,但这种方法不仅复杂,而且从理论和效果上也难以保证其可行性。
为了提高恢复图像的清晰度,使其最大程度的逼近原始清晰图。提出如下技术方案:构造新的梯度加权正则模型,利用梯度的方差的倒数作为加权系数,使得图像先验模型对清晰自然图像具有更小的能量,而对模糊图像具有较大的能量,从而避免原始模糊图像成为目标函数的解;通过构造去均值的梯度正则模型,提升图像边缘和细节。
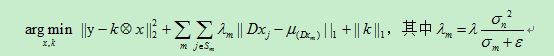
模型提出的根据:在模糊程度逐渐加大时,正则项的能量energy也即cost逐渐加大,在有轻微锐化的情况下,随着锐化程度加大时,energy逐渐加大,在清晰图像时,有最优值。
5. 每一个模块的解法
对上面提出的数据项+正则项组成的最优化式,采用如下三个模块计算出最终的清晰图像:
1) 求梯度域清晰图
采用迭代收缩阈值算法,ISTA (Iterative Shrinkage-Thresholding Algorithm)。ISTA是解决“二范数+一范数”形式的优化式的一种快速方法。先计算一个比较逼近的v(类似pcg共轭梯度法),然后按照软阈值收缩,去掉接近0的值。(整个过程即对应一范数的求解过程,按一范数的定义推导)
2) 在梯度域求模糊核k
pcg共轭梯度法。用已知点处的梯度构造一组共轭方向,并沿这组方向进行搜索,求出目标函数的极小点。
3) 非盲去模糊
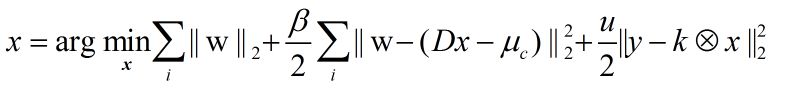
构造最优化式(全变差模式下的惩罚函数法),随着惩罚函数逐渐增大,为了energy最小则w越来越接近Dx(梯度域清晰图),然后根据w直接求解二范(求导为0得到最优点)得到清晰图。