摘要:
多GPU计算已经可以说,只要是个成熟的模型,都使用了这一点。
多GPU计算已经可以说,只要是个成熟的模型,都使用了这一点。
例如:
gluoncv:https://github.com/dmlc/gluon-cv/blob/master/scripts/detection/faster_rcnn/train_faster_rcnn.py#L218
多GPU计算最常用的方法是:数据并行
流程如下图:
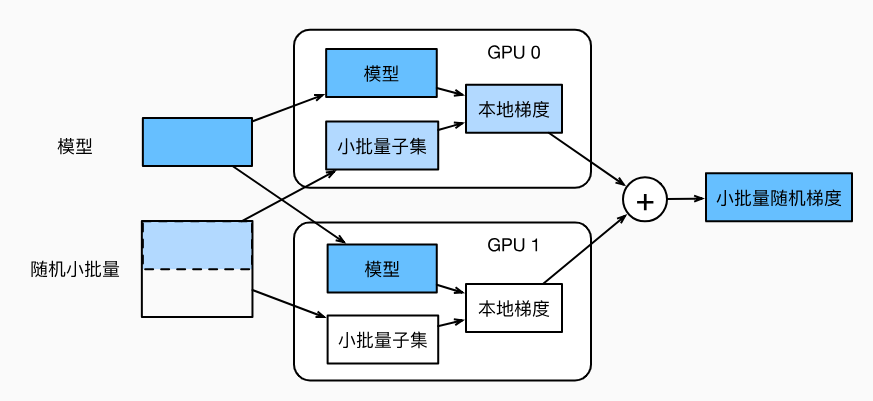
- 模型参数复制多份
- 批量数据,分成多份子集,在各自显卡的显存上计算梯度
- 再累加到一块显卡的显存上
- 最后广播到各个显存上
importmxnet as mx from mxnet importautograd, nd from mxnet.gluon importnn,loss as gloss importd2lzh as d2l scale = 0.01 W1 = nd.random.normal(scale=scale,shape=(20,1,3,3)) b1 = nd.zeros(shape=20) W2 = nd.random.normal(scale=scale,shape=(50,20,5,5)) b2 = nd.zeros(shape=50) W3 = nd.random.normal(scale=scale,shape=(800,128)) b3 = nd.zeros(shape=128) W4 = nd.random.normal(scale=scale,shape=(128,10)) b4 = nd.zeros(shape=10) params =[W1, b1, W2, b2, W3, b3, W4, b4] deflenet(X, params): h1_conv = nd.Convolution(data=X, weight=params[0],bias=params[1], kernel=(3,3),num_filter=20) h1_activation =nd.relu(h1_conv) h1 = nd.Pooling(data=h1_activation, pool_type='avg', kernel=(2,2), stride=(2,2)) h2_conv = nd.Convolution(data=h1, weight=params[2],bias=params[3], kernel=(5,5), num_filter=50) h2_activation =nd.relu(h2_conv) h2 = nd.Pooling(data=h2_activation, pool_type='avg', kernel=(2,2), stride=(2,2)) h2 =nd.flatten(h2) h3_linear = nd.dot(h2, params[4]) + params[5] h3 =nd.relu(h3_linear) y_hat = nd.dot(h3, params[6]) + params[7] returny_hat loss =gloss.SoftmaxCrossEntropyLoss() #多GPU之间的同步 #尝试把模型参数复制到gpu(0)上 defget_params(params, ctx): new_params = [p.copyto(ctx) for p inparams] for p innew_params: p.attach_grad() returnnew_params new_params =get_params(params,mx.gpu(0)) #给定分布在多块显卡的显存之间的数据 #把各块显卡的显存数据加起来,再广播到所有显存上 defallreduce(data): for i in range(1,len(data)): data[0][:] +=data[i].copyto(data[0].context) for i in range(1,len(data)): data[0].copyto(data[i]) #data = [nd.ones((1,2), ctx=mx.gpu(i)) * (i+1) for i in range(2)] #print(data) #将批量数据切分并复制到各个显卡的显存上去 defsplit_and_load(data, ctx): n, k =data.shape[0], len(ctx) m = n //k return [data[i*m:(i+1)*m].as_in_context(ctx[i]) for i inrange(k)] batch = nd.arange(24).reshape((6,4)) ctx = [mx.gpu(0),mx.gpu(1)] splitted =split_and_load(batch,ctx) #单个小批量上的多GPU训练 deftrain_batch(X, y, gpu_params, ctx, lr): gpu_Xs, gpu_ys =split_and_load(X, ctx), split_and_load(y, ctx) with autograd.record(): ls =[loss(lenet(gpu_X, gpu_W), gpu_y) for gpu_X, gpu_y, gpu_W inzip(gpu_Xs, gpu_ys, gpu_params)] #各块GPU上分别反向传播 for l inls: l.backward() #把各块显卡的显存上的梯度加起来,然后广播到所有显存上 for i inrange(len(gpu_params[0])): allreduce([gpu_params[c][i].grad for c inrange(len(ctx))]) #在各块显卡的显存上分别更新模型参数 for param ingpu_params: d2l.sgd(param, lr, X.shape[0]) importtime #定义训练模型 deftrain(num_gpus, batch_size, lr): train_iter, test_iter =d2l.load_data_fashion_mnist(batch_size) ctx = [mx.gpu(i) for i inrange(num_gpus)] print('running on:', ctx) #将模型参数复制到各块显卡的显存上 gpu_params = [get_params(params, c) for c inctx] for epoch in range(4): start =time.time() for X,y intrain_iter: #对单个小批量进行多GPU训练 train_batch(X,y, gpu_params, ctx, lr) nd.waitall() train_time = time.time() -start defnet(x): returnlenet(x, gpu_params[0]) test_acc =d2l.evaluate_accuracy(test_iter, net, ctx[0]) print('epoch %d, time %.1f sec, test acc %.2f'%(epoch+1, train_time, test_acc)) train(num_gpus=2, batch_size=256, lr=0.2)