欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
关于sink
下图来自Flink官方,红框中就是sink,可见实时数据从Source处开始,在Transformation阶段完成业务逻辑后在sink结束,因此sink可以用来处理计算结果,例如控制台输出或者保存数据库:
关于《Flink的sink实战》系列文章
本文是《Flink的sink实战》的第一篇,旨在初步了解sink,通过对基本API和addSink方法的分析研究,为后续的编码实战打好基础;
全系列链接
从一段实例代码开始
- 下面是个简单的flink应用代码,红框中的print方法就是sink操作:
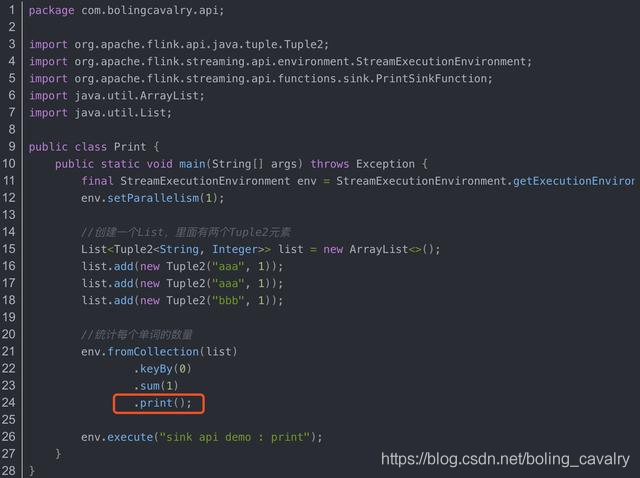
- 下图是官方给出的sink方式,都是DataStream类的API,直接调用即可实现sink,刚才代码中的print就是其中一个:

- 接下来看看上图中API的源码,先看print方法,在DataStream.java中,如下,实际上是调用了addSink方法,入参是PrintSinkFunction:

- 另一个常用API是writeAsText,源码如下,调用了writeUsingOutputFormat方法:

- 追踪writeUsingOutputFormat发现也是调用了addSink,入参是OutputFormatSinkFunction:

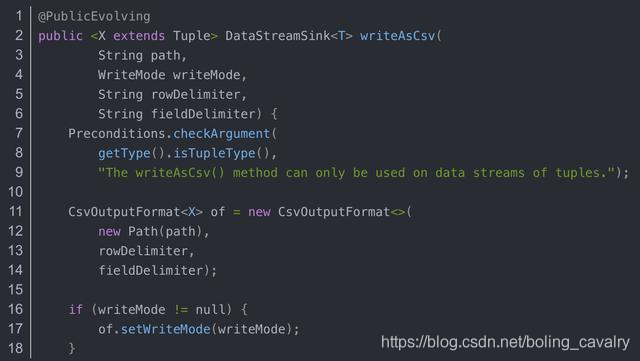
- print和writeAsText背后都在调用addSink,那么另一个常用的writeAsCsv方法呢?莫非也是调用addSink?打开一看果然,和writeAsText一样调用了writeUsingOutputFormat,而该方法里面就是在调用addSink:
- 综上所述,data sink的关键就是addSink的入参,即SinkFunction接口的实现,通过类图直观看到常见的sink能力是如何实现的:
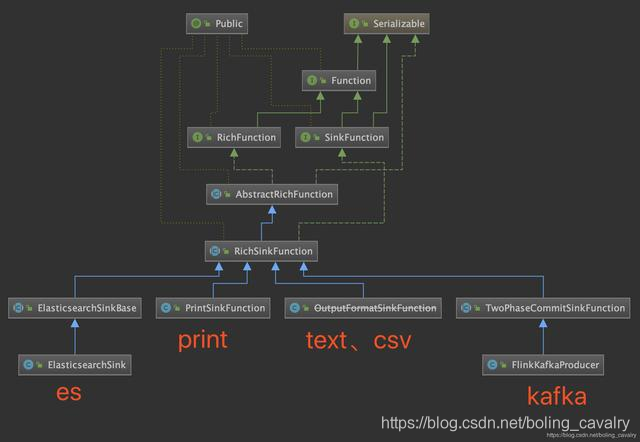
8. 从上图可见抽象类RichSinkFunction与各种sink能力的关系十分紧密,我们应该重点关注它,在类图上展示方法签名,如下图: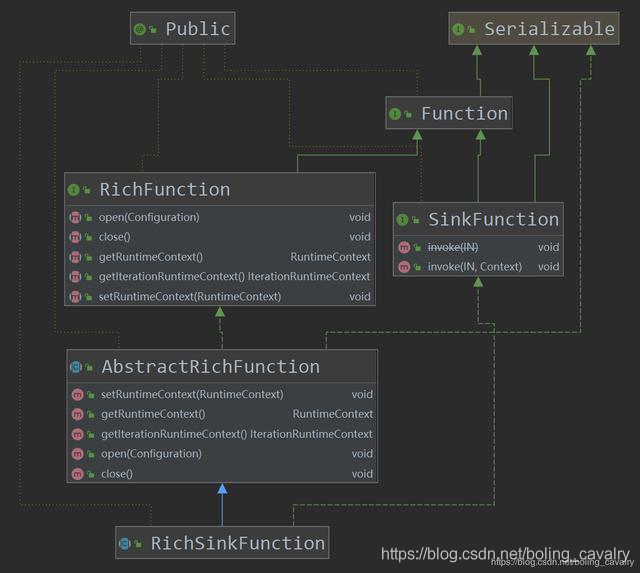
9. 如上图所示,RichSinkFunction本身没有内容,但是它实现SinkFunction,继承AbstractRichFunction,是RichFunction和SinkFunction这两种特性的结合;
10. RichFunction的特性在前面的《Flink的DataSource三部曲》中已经了解,就是资源的open和close;
11. SinkFunction的特性呢?显然是用来处理计算结果的,类图上显示的是两个invoke方法,来看看官方的PrintSinkFunction.java:
12. writer.write(record)的源码在PrintSinkOutputWriter.java,如下所示: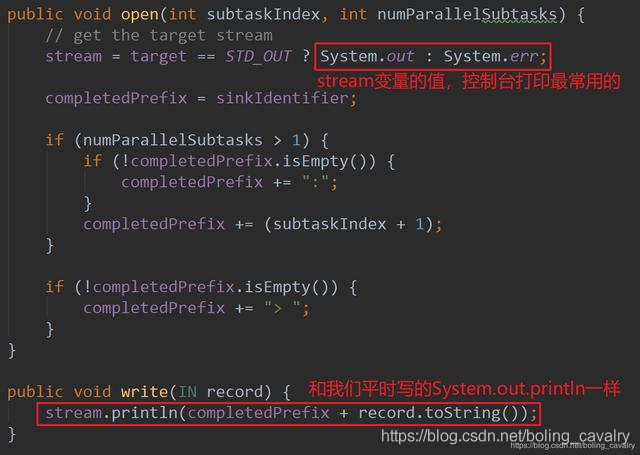
小结
至此,我们已经对Flink的sink有了基本了解:
- 负责实时计算结果的处理(如输出或持久化);
- 主要实现方式是调用DataStream.addSink方法;
- 各种sink能力的实现,主要途径是实现addSink方法的入参定义的接口;
后面的章节,一起进行sink方面的编码实战吧,实战的方向:体验官方提供的sink能力,自定义sink能力实现;
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos