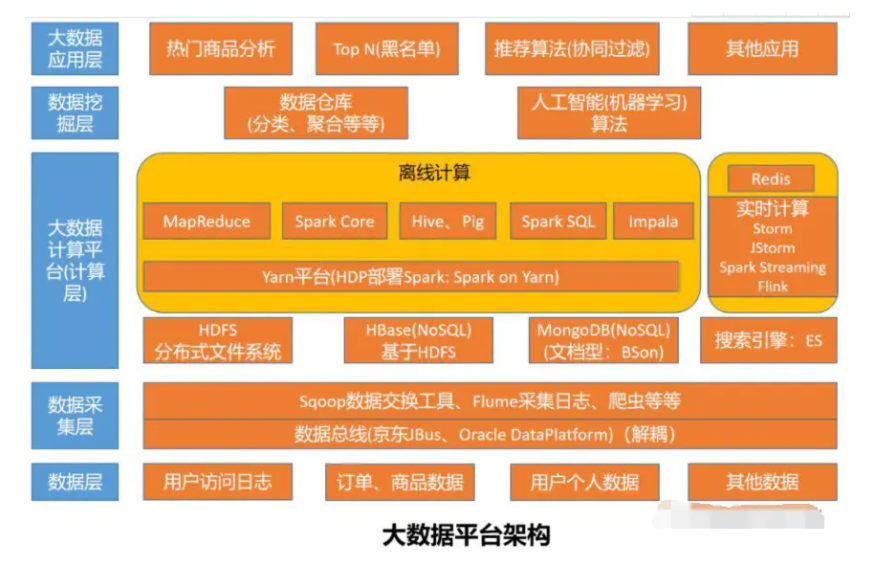
数据来源:系统中可以采集到的数据,如用户数据、业务数据等,也包含系统运行时产生的日志数据等。
数据采集:不同数据源生成数据类型格式存在差异,在数据采集前可能增加数据总线(如京东JBus)对业务进行解耦,Sqoop和Flume是常用的数据采集工具。
Sqoop:用于和关系型数据库进行交互,使用SQL语句在Hadoop和关系型数据库间传送数据,Sqoop使用JDBC连接关系型数据库。
Flume:一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。一个Flume代理由三个部分组成:Source、Channel和Sink。Source类似于接受缓冲器,将接收的事件存储在一个或多个Channel中。Channel被动存储事件,直到事件被Sink使用。Sink从Channel提取事件将其传给HDFS或者下一个Flume代理。Flume使用不同的Source接收不同的网络流,如使用Avro Flume接收Avro(一种数字序列化格式)事件。其支持的流行网络流如:Thrift、Syslog和Netcat。
数据处理:包含实时的业务逻辑处理以及离线的数据整合存储等。大数据框架多采用主从(Master/Slave)架构,存在Master单点故障的问题,多采用Zookeeper实现高可用性。
HDFS:分布式文件系统,由NameNode和一定数目的DataNodes组成集群。HDFS中数据通常有三个备份,用户只需上传1次数据,通过机架感知和水平复制自动备份数据。HDFS 2.0默认存储文件大小为128M,适合存储大文件。
Yarn:新的MapReduce框架。分布式主从架构,并行处理大数据。主要分文Mapper和Reducer两个阶段。Mapper主要对数据进行分类整理,Reducer实现数据的规约汇总。2.0版本中MapReduce存在大量IO操作影响效率,在大数据平台中多用Spark代替。
Spark:通用的大数据分析引擎,功能类似MapReduce。主要包含Spark Core,Spark SQL,Spark Streaming,Spark MLLib(协同过滤、ALS、逻辑回归等算法库),Spark Graphx(图计算)。
Hive:用于开发SQL类型脚本用于做MapReduce操作的平台,用于处理结构化数据。
Pig:用于开发MapReduce操作的脚本程序语言平台,用于处理结构化和半结构化数据。
Storm:流处理(实时计算)框架,不同于HDFS的批处理方式,Storm通过创建拓扑结构来转换持续抵达的数据流,实时处理消息并更新数据库。
数据挖掘:结合业务需求,合理选择算法模式(包含机器学习)深入分析当前累积的海量数据,挖掘数据背后价值。
大数据应用:通过上述一系列复杂的数据处理,最终通过应用展示数据的价值。如基于系统日志的大数据分析平台,自动快速识别系统运行风险,及时通知相关人员跟进处理。
Apache Flink
Apache Flink是一种可以处理批处理任务的流处理框架。该技术可将批处理数据视作具备有限边界的数据流,借此将批处理任务作为流处理的子集加以处理。为所有处理任务采取流处理为先的方法会产生一系列有趣的副作用。
这种流处理为先的方法也叫做Kappa架构,与之相对的是更加被广为人知的Lambda架构(该架构中使用批处理作为主要处理方法,使用流作为补充并提供早期未经提炼的结果)。Kappa架构中会对一切进行流处理,借此对模型进行简化,而这一切是在最近流处理引擎逐渐成熟后才可行的。
流处理模型
Flink的流处理模型在处理传入数据时会将每一项视作真正的数据流。Flink提供的DataStream API可用于处理无尽的数据流。Flink可配合使用的基本组件包括:
Stream(流)是指在系统中流转的,永恒不变的无边界数据集
Operator(操作方)是指针对数据流执行操作以产生其他数据流的功能
Source(源)是指数据流进入系统的入口点
Sink(槽)是指数据流离开Flink系统后进入到的位置,槽可以是数据库或到其他系统的连接器
为了在计算过程中遇到问题后能够恢复,流处理任务会在预定时间点创建快照。为了实现状态存储,Flink可配合多种状态后端系统使用,具体取决于所需实现的复杂度和持久性级别。
此外Flink的流处理能力还可以理解“事件时间”这一概念,这是指事件实际发生的时间,此外该功能还可以处理会话。这意味着可以通过某种有趣的方式确保执行顺序和分组。
批处理模型
Flink的批处理模型在很大程度上仅仅是对流处理模型的扩展。此时模型不再从持续流中读取数据,而是从持久存储中以流的形式读取有边界的数据集。Flink会对这些处理模型使用完全相同的运行时。
Flink可以对批处理工作负载实现一定的优化。例如由于批处理操作可通过持久存储加以支持,Flink可以不对批处理工作负载创建快照。数据依然可以恢复,但常规处理操作可以执行得更快。
另一个优化是对批处理任务进行分解,这样即可在需要的时候调用不同阶段和组件。借此Flink可以与集群的其他用户更好地共存。对任务提前进行分析使得Flink可以查看需要执行的所有操作、数据集的大小,以及下游需要执行的操作步骤,借此实现进一步的优化。
优势和局限
Flink目前是处理框架领域一个独特的技术。虽然Spark也可以执行批处理和流处理,但Spark的流处理采取的微批架构使其无法适用于很多用例。Flink流处理为先的方法可提供低延迟,高吞吐率,近乎逐项处理的能力。
Flink的很多组件是自行管理的。虽然这种做法较为罕见,但出于性能方面的原因,该技术可自行管理内存,无需依赖原生的Java垃圾回收机制。与Spark不同,待处理数据的特征发生变化后Flink无需手工优化和调整,并且该技术也可以自行处理数据分区和自动缓存等操作。
Flink会通过多种方式对工作进行分许进而优化任务。这种分析在部分程度上类似于SQL查询规划器对关系型数据库所做的优化,可针对特定任务确定最高效的实现方法。该技术还支持多阶段并行执行,同时可将受阻任务的数据集合在一起。对于迭代式任务,出于性能方面的考虑,Flink会尝试在存储数据的节点上执行相应的计算任务。此外还可进行“增量迭代”,或仅对数据中有改动的部分进行迭代。
在用户工具方面,Flink提供了基于Web的调度视图,借此可轻松管理任务并查看系统状态。用户也可以查看已提交任务的优化方案,借此了解任务最终是如何在集群中实现的。对于分析类任务,Flink提供了类似SQL的查询,图形化处理,以及机器学习库,此外还支持内存计算。
Flink能很好地与其他组件配合使用。如果配合Hadoop 堆栈使用,该技术可以很好地融入整个环境,在任何时候都只占用必要的资源。该技术可轻松地与YARN、HDFS和Kafka 集成。在兼容包的帮助下,Flink还可以运行为其他处理框架,例如Hadoop和Storm编写的任务。
目前Flink最大的局限之一在于这依然是一个非常“年幼”的项目。现实环境中该项目的大规模部署尚不如其他处理框架那么常见,对于Flink在缩放能力方面的局限目前也没有较为深入的研究。随着快速开发周期的推进和兼容包等功能的完善,当越来越多的组织开始尝试时,可能会出现越来越多的Flink部署。
总结
Flink提供了低延迟流处理,同时可支持传统的批处理任务。Flink也许最适合有极高流处理需求,并有少量批处理任务的组织。该技术可兼容原生Storm和Hadoop程序,可在YARN管理的集群上运行,因此可以很方便地进行评估。快速进展的开发工作使其值得被大家关注。