Flink的部署有3种模式,分别是local模式、Standalone模式、yarn模式。其中local就是单机模式,一般来说用于本地开发测试;Standalone跟yarn模式都可以支撑集群部署、实现HA,但是两者在任务分配机制、内存管理等内容上有比较大的差异。一般在处理计算数据量级非常大的生产环境,使用flink on yarn的模式更多一些。
我们的Standalone模式部署目标:共有3台机器,其中1台配置为Master+Worker,2台配置为Worker。
本次安装的是目前的最新版本(1.13.2,2021年9月),下载地址:Apache Flink: 下载。目标机器为centos7,均已安装好了java1.8环境。
——172.18.88.44(master+worker);
——172.18.88.45(worker);
——172.18.88.46(worker);
1、将下载的flink安装包copy到44上,解压缩:
tar -xzf flink-1.13.2-bin-scala_2.11.tgz(题外话:此时如果作为local模式的话,直接执行 ./bin/start-cluster.sh 即可启动flink服务了)
2、进入解压缩出来的flink/conf目录,修改flink-conf.yaml中的jobmanager地址为44(默认为localhost):
jobmanager.rpc.address: 172.18.88.44(内存设置也在这个配置文件里,这里暂时不改,以后有需要再修改,有兴趣的可以看这篇帖子有详细介绍:Flink调优之前,必须先看懂的TaskManager内存模型 - 知乎 (zhihu.com))

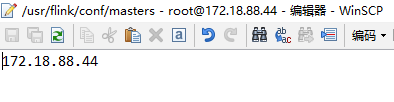
3、修改master文件,将master指定为44(默认为localhost:8081)
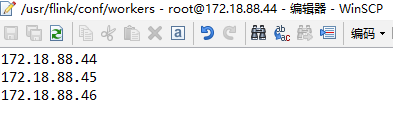
4、修改workers文件,将3个worker的IP配置上:
5、在45、46两台机器上同样解压缩安装包,并将44上的这3个配置文件copy到45、46上。注意:45、46的flink位置要与44上的位置保持一致。
6、正常情况下,在44上的flink目录下执行./bin/start-cluster.sh,即可启动集群了。
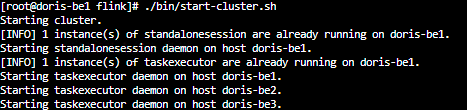
7、由于这3台机器没有配置ssh免登,会出现启动服务时,需要输入45、46两台机器密码的情况,不方便。为此,请配置ssh免登,参考centos7下配置免密码登录 - zouminglan - 博客园 (cnblogs.com)
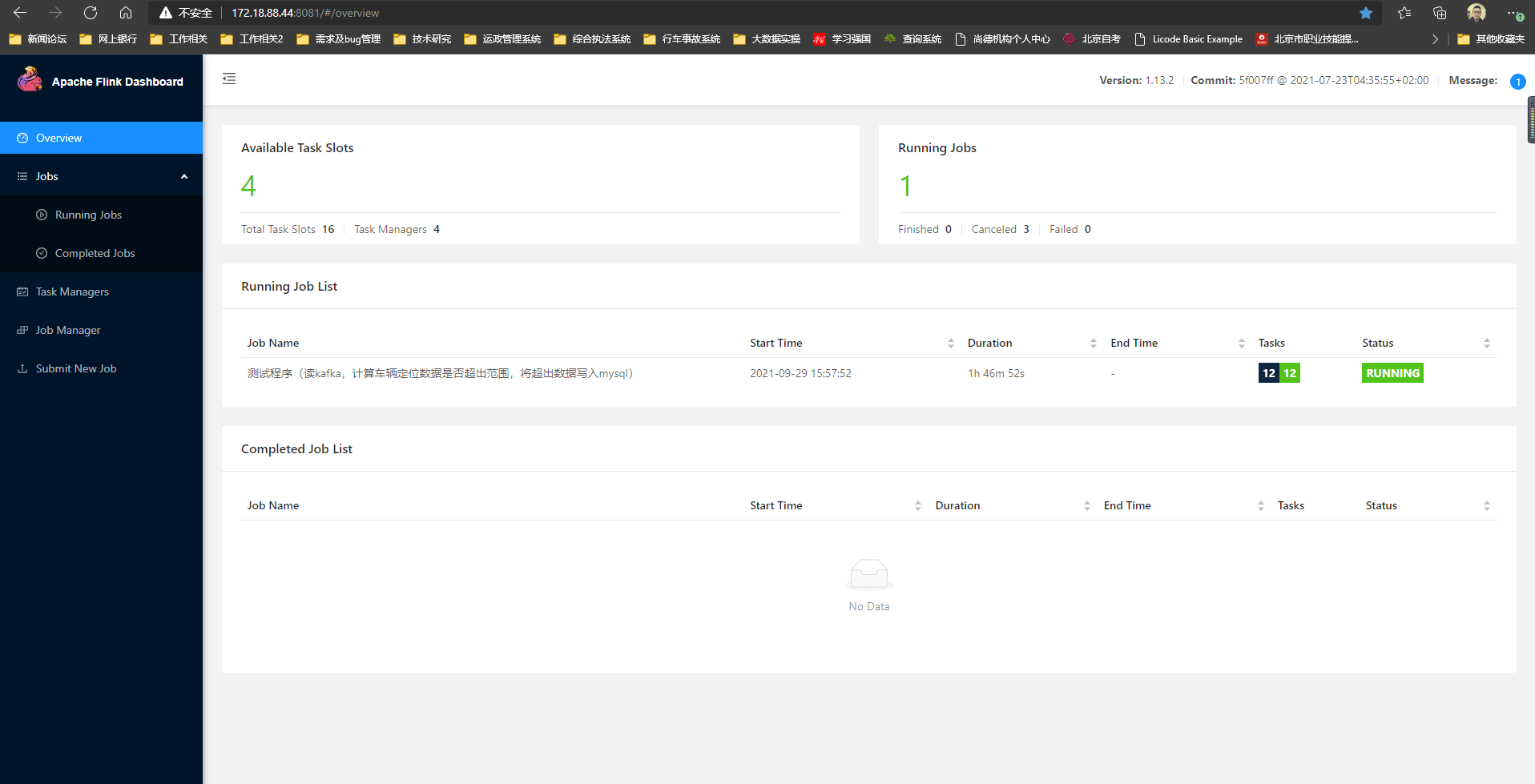
8、可通过master所在机器地址查看运行状态:172.18.88.44:8081
9、HA配置略。