一、大数据架构
并发计算:
并行计算:
很少会说并发计算,一般都是说并行计算,但是并行计算用的是并发技术。并发更偏向于底层。并发通常指的是单机上的并发运行,通过多线程来实现。而并行计算的范围更广,他是散布到集群上的分布式计算。
Spark内存计算比hadoop快100倍,磁盘计算快10倍,在worker节点主要基于内存进行计算,避免了不必要的磁盘io。
二、Spark模块
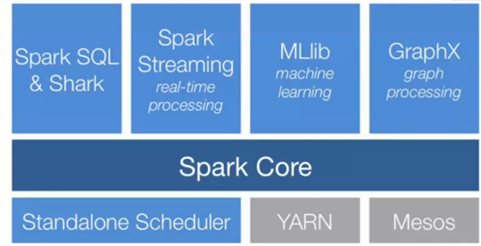
Spark是没有分布式存储的,必须借助hadoop的HDFS等。资源管理工具自带的是Standalone也支持hadoop的YARN。Spark最底层是SparkCore(内核位于执行引擎之上,所有功能都在其上进行构建),SparkCore集成了最原始的计算功能,基于SparkCore这种底层的API上层主要有四个,Spark SQL, Spark streaming, Mlib, Graphx
三、Spark部署三种模式
1. standalone独立模式
2. Hadoop yarn
3. Spark in mapreduce
Spark独立集群模式
独立部署,实质就是手动通过脚本一一启动所需要的进程,例如master进程,work进程。
在spark/bin目录下,提供了相应脚本,
start-master.sh // 启动master进程
start-slave.sh // 启动单个work进程
start-slaves.sh // 启动所有work进程
start-all.sh // 启动所有进程,在master上执行
stop-xxx.sh // 对应的停止进程
Spark独立集群配置
① [spark-env.sh]
Spark/conf/spark-env.sh
② [slaves]
S02
S03
S04
③ spark-default.conf 也不用动
④ 分发文件
cd /soft
xsync.sh spark-2.1.0-bin-hadoop2.7
xsync.sh spark
su root
xsync.sh /etc/profile
⑤ 重启电脑
⑥ 启动spark集群
[s201]
./start-master.sh
[s202, s203, s204]
./start-slave.sh spark://s201:7077
⑦ 进入webUI界面
Spark-shell连接到spark集群的模式
Spark-shell –master spark://s201:7077 #standalone模式,需要启动进程(前提是你已经搭建好了集群)但是缺点是,如果你在master上运行本地文件,必须传到其他work节点上,而如果是hadoop的hdfs文件就所有worker都可以访问
Spark-shell –master spark://ip:port #mesos模式
Yarn #结合hadoop,使用yarn资源调度框架
Spark-shell #本地模式
四、SparkRDD
Spark版本查看spark-submit –version
单独在主节点上运行 spark-shell –master spark://s201:7077
1. RDD基础
RDD resilient distributed dataset弹性式分布数据集
rdd里面是没有数据的,只是一些计算法则,有每个切片的计算函数,还有分区列表。你在每个分区上进行什么样的操作,这些操作封装起来就是rdd.
①是不可变,如果运行rdd的节点故障,driver就可以重建rdd并指派到新的节点。计算过程中数据一直是静态的。(RDD存的是变换过程,变换的函数,上下互相变换依赖的链条 )
②是分布式的。将大的RDD切割成小的rdd,分发到worker节点上运行,每个worker都有自己环境,最终组装结果。Spark在系统或其他运行故障后会有自己的机制进行恢复(可容错所以叫弹性式)
④驻留在内存。Spark高速的原因
⑤RDD是强类型
⑥RDD两种操作类型
Transformations:从前一个RDD,产生一个新的RDD,例如filter操作
Action:基于RDD计算一个结果/返回值给driver/存储文件导存储系统上。Count/take/first
⑦使用parallelize()创建RDD
Sc.parallelize(1 to 10, 3)产生3条切片
2. sparkConf
①设置spark参数,key-value对
②手动设置优先于系统属性
3. sparkContext
org.apache.spark.SparkContext
SparkContext,spark上下文,驱动程序Driver,是spark程序的主入口,类似于main函数,负责连接到spark的集群,可用创建RDD,在集群上创建累加器和广播变量。
每个虚拟机jvm只能激活一个Spark上下文对象,创建新的spark上下文对象时,必须stop原来的。
val rdd = sc.textFile(“d:/2.txt”)
rdd.flatMap(line => line.split(“ “).map(w=>(w, 1)).reduceByKey((a, b)=>a+b).collect()
4.读取文件sparkContext.textFile
Spark-shell下
Val lines = sc.textFile(“/user/ubuntu/xx.txt”) #读取hdfs文件,hadoop集群启动起来
Val lines = sc.textFile(“file:///home/ubuntu/xx.txt”) #读取本地文件
Lines.take(2) #提取前两行
Lines.first()
Val rdd2 = lines.filter(x => x.contains(“0000”))
每个spark应用由driver构成,由它启动各种并行操作。driver含有main函数和分布式数据集,并对他们应用各种操作。Spark-shell本身就是driver(包含Main)。
Driver通过sparkContext访问spark对象,代表和spark集群的连接
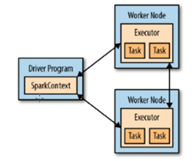
运行程序时,驱动程序需要管理一些叫做excuter的节点,如果是在分布式集群运行,则如下图spark在分布式上的执行主键所示。(在工作节点上有excutor执行线条,有若干task,task之间还可以相互通信)
Spark-shell(本身就是驱动)下默认使用local模式运行spark程序,没有用到spark集群。类似于Hadoop的本地模式。Spark-shell是可以带参的,
Spark-shell –master local[1] #1表示你要打算开启1个线程来模拟spark集群
spark-shell --master local[4] #4表示4个线程,并发度
val lines = sc.textFile("file:///D:/borrowCardJson.txt",3) #3表示分区数minpatition
val rdd2 = lines.map(x=>{val tname=Thread.currentThread().getName; println(tname + ":" + x);x})
rdd2.count()
附注:scala命令界面退出 :quit
停止spark stop()
五、使用maven编译和运行scala的spark程序
①编写scala源码
import org.apache.spark.{ SparkContext, SparkConf}
object wcApp{
def main(args:Array[String]){
val conf = new SparkConf().setAppName("wordCount")
val sc = new SparkContext(conf)
val lines = sc.textFile("file:///D:/borrowCardJson.txt")
val words = lines.flatMap(x => x.split(","))
val counts = words.map(word => (word, 1)).reduceByKey((x, y) => x+y)
counts.saveAsTextFile("file:///D:/output.txt")
}
}
六. 调度相关核心概念
[Job]
//ActiveJob,在DAG运行job, 有两种类型,Result job和map-stage job.
Result job计算ResultStage来执行action
Map-stage job在以一个stage提交前,计算shuffleMapStage的output,并可以用作查询计划以及提交给下一阶段前查看map输出的统计内容,可以使用finalStage字段进行两种job类型的区分
[Stage]
在job中计算中间的结果的task集合,每个task在同一RDD的每个分区上计算同一函数。Stage是通过shuffle边界,引入一个障碍(必须等到前一完成后才能提取Output)
有两种stage,ResultStage和shuffleMapStage
ResultStage是执行action的final的stage
ShuffleMapStage是为shuffle过程将map的output进行write的
[task]
单独的工作单元,发送给一台主机。
[cache tracking]
DAG调度器分析出被缓存的RDD,以避免重复计算,也会记住在map阶段以及产生了output的shuffle避免重复map过程
[preferred location]
DAG调度器基于底层RDD的首选位置、缓存的配置或者shuffle的数据参数得到首选位置,并计算task的运行地点。
[cleanup]
Job完成后数据结构被清除防止内存泄漏。
taskset //task集合
stage //task集合
调度器
三级调度
1. DAGScheduler //有向五环图调度器 stage
2.TaskScheduler //任务调度器.Taskset调度任务,依赖于SchedulerBackend
//TaskSchedulerImp1 任务调度器就这一个 后台调度器有好几种实现
3.SchedulerBackend //后台调度器
//LocalSchedulerBackend针对本地模式调试
//CoarseGrainedSchedulerBackend粗粒度
//StandaloneSchedulerBackend继承于CoarseGrainedSchedulerBackend
4. SchedulableBuilder //调度构建器 FIFO和Fair两种
例如 RDD.collect()
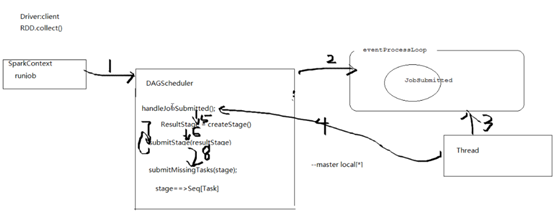
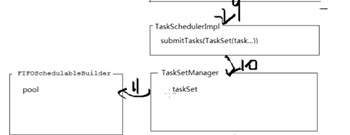
①首先collect()里面,启动SparkContext的runjob方法,最终调用到DAG调度器runjob方法,参数仍然有rdd、分区数、resultHandler(结果处理器),在DAG的runjob方法里面用了submitJob,DAG调度器把RDD封装成事件放到队列里面(DAGSchedulerEventProcessLoop)。然后有线程开启轮寻这个队列。轮寻后再次将结果给DAG调度器,使用里面封装的方法handleJobSubmitted,该方法里面有createResultStage(因为DAG是面向阶段的,必须在RDD里面找出阶段),然后再submitStage,然后submitMissingTask(stage),串行化rdd(将任务变成字节数组)以便分发到各节点(广播走),多个分区映射成多个任务shuffleMapTask。
②接着进入任务调度器TaskScheduler,taskScheduler.submitTasks(TaskSet)提交任务集,将任务集交给任务集管理器TaskSetManager
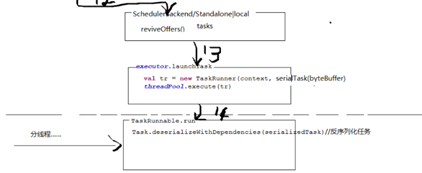
③进入第三层调度 SchedulerBackend 后台调度器,走的localEndPoint,走到rpc,分发消息,分发线程轮寻dispathcher.MessageLoop(),开启分线程运行各个作业threadpool,最终走到spark.executor,使用内部的rpc(远程过程调用)用于和driver通讯。Spark.ececutor启动launchTask(taskId, taskName, serializedTask…)
④进入分线程处理,反序列化 Task.run,再shuffleMapTask.run.Task()反序列化广播变量,然后调用shuffleWrite.write()处理我们程序里面自己写的代码。


七、在spark集群上对hdfs文件进行单词统计
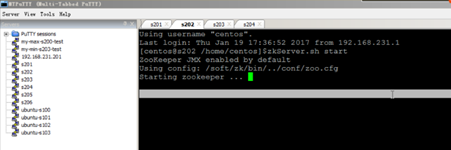
1. 启动zk
[s202, s203, s204]
zkServer.sh start
2. 启动hadoop集群
[s201]
只启动hdfs即可
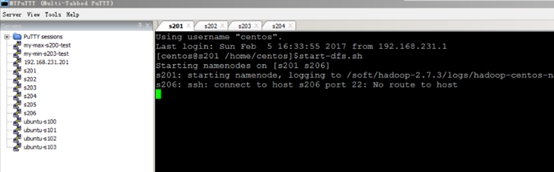
hdfs haadmin -transtionToActive –forcemanul nnl //强行切换active态
查看下 http:s201:50070
3. 启动spark集群
[s201]
Cd soft/spark/sbin目录下,./start-all.shell
查看下 http:s201:8080

4. 准备文件 在HDFS上面放个文件
hdfs dfs -put words /user/centos

5. Spark-shell –master spark://s201:7077

6. 在shell环境下编写单词统计的wordCount程序

八、导出spark应用成jar,提交spark集群上执行
有两种方法,一种是IDEA 打可执行jar 包,
https://blog.csdn.net/freecrystal_alex/article/details/78296851
IntellIJ IDEA 中配置Maven
https://www.cnblogs.com/phpdragon/p/7216626.html
https://blog.csdn.net/westos_linux/article/details/78968012
另一种是idea maven 打可执行jar 包
https://www.cnblogs.com/seaspring/p/5615976.html
在pom.xml文件中<build><plugins>后加入两个插件org.apache.maven.plugins和net.alchim31.maven
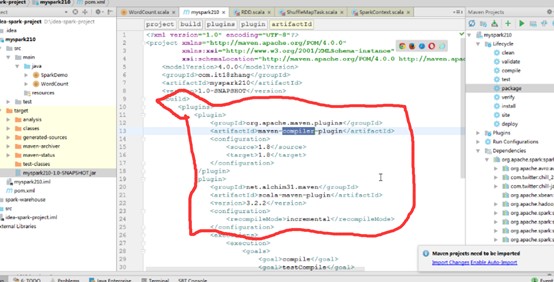
在你jar包所在文件下,使用spark-submit,后面添加各种参数,如果依赖第三方包用--jars

Spark Application基于python编写以后,如何提交spark运行呢? 一样用spark-submit,
把该python文件上传到hdfs文件系统上去 ,spark安装目录相同文件夹
需要修改下spark环境变量为运行的集群地址,os.environ['SPARK_HOME'] = '/opt/cdh-5.3.6/spark-1.6.1-bin-2.5.0'
.setMaster就不用指定了,通过程序来指定
bin/spark-submit spark://so21:7077 /opt/cdh-5.3.6/spark-1.6.1-bin-2.5.0/spark_wordCount.py