OCR技术起源
OCR最早的概念是由德国人Tausheck最先提出的,1966年他们发表了第一篇关于汉字识别的文章,采用了模板匹配法识别了1000个印刷体汉字。早在60、70年代,世界各国就开始有OCR的研究,而研究的初期,多以文字的识别方法研究为主,且识别的文字仅为0至9的数字。以同样拥有方块文字的日本为例,1960年左右开始研究OCR的基本识别理论,初期以数字为对象,直至1965至1970年之间开始有一些简单的产品,如印刷文字的邮政编码识别系统,识别邮件上的邮政编码,帮助邮局作区域分信的作业;也因此至今邮政编码一直是各国所倡导的地址书写方式。
20世纪70年代初,日本的学者开始研究汉字识别,并做了大量的工作。中国在OCR技术方面的研究工作起步较晚,在70年代才开始对数字、英文字母及符号的识别进行研究,70年代末开始进行汉字识别的研究,到1986年汉字识别的研究进入一个实质性的阶段,不少研究单位相继推出了中文OCR产品.早期的OCR软件,由于识别率及产品化等多方面的因素,未能达到实际要求。同时,由于硬件设备成本高,运行速度慢,也没有达到实用的程度。只有个别部门,如信息部门、新闻出版单位等使用OCR软件。1986年以后我国的OCR研究有了很大进展,在汉字建模和识别方法上都有所创新,在系统研制和开发应用中都取得了丰硕的成果,不少单位相继推出了中文OCR产品。进入20世纪90年代以后,随着平台式扫描仪的广泛应用,以及我国信息自动化和办公自动化的普及,大大推动了OCR技术的进一步发展,使OCR的识别正确率、识别速度满足了广大用户的要求。(文章摘自百度百科)
OCR技术第一次商用及生活中的各类用途(车牌号识别、银行卡号识别、车架号识别,快递单号识别等),OCR技术的各家性能比较。
IBM公司最早开发了OCR产品,1965年在纽约世界博览会上展出了IBM公司的OCR产品——IBMl287。当时的这款产品只能识别印刷体的数字、英文字母及部分符号,并且必须是指定的字体。20世纪60年代末,日立公司和富士通公司也分别研制出各自的OCR产品。全世界第一个实现手写体邮政编码识别的信函自动分拣系统是由日本东芝公司研制的,两年后NEC公司也推出了同样的系统。到了1974年,信函的自动分拣率达到92%左右,并且广泛地应用在邮政系统中,发挥着较好的作用。1983年日本东芝公司发布了其识别印刷体日文汉字的OCR系统OCRV595,其识别速度为每秒70~100个汉字,识别率为99.5%。其后东芝公司又开始了手写体日文汉字识别的研究工作。
中国OCR技术领头羊是谁,做到什么程度?
中国在OCR技术方面的研究工作相对起步较晚,在20世纪70年代才开始对数字、英文字母及符号的识别技术进行研究,20世纪70年代末开始进行汉字识别的研究。1986年,国家863计划信息领域课题组织了清华大学、北京信息工程学院、沈阳自动化所三家单位联合进行中文OCR软件的开发工作。至1989年,清华大学率先推出了国内第一套中文OCR软件--清华文通TH-OCR1.0版,至此中文OCR正式从实验室走向了市场。清华OCR印刷体汉字识别软件其后又推出了TH-OCR 92高性能实用简/繁体、多字体、多功能印刷汉字识别系统,使印刷体汉字识别技术又取得重大进展。到1994年推出的TH-OCR 94高性能汉英混排印刷文本识别系统,则被专家鉴定为“是国内外首次推出的汉英混排印刷文本识别系统,总体上居国际领先水平”。上个世纪90年代中后期,清华大学电子工程系提出并进行了汉字识别综合研究,使汉字识别技术在印刷体文本、联机手写汉字识别、脱机手写汉字识别和脱机手写数字符号识别等领域全面地取得了重要成果。具有代表性的成果是TH-OCR 97综合集成汉字识别系统,它可以完成多文种(汉、英、日)印刷文本、联机手写汉字、脱机手写汉字和手写数字的识别输入。几年来,除清华文通TH-OCR外,其它如尚书SH-OCR等各具风格的OCR软件也相继问世,中文OCR市场稳步扩大,用户遍布世界各地。
可以说目前印刷体OCR的识别技术已经达到较高水平。OCR产品已由早期的只能识别指定的印刷体数字、英文字母和部分符号,发展成为可以自动进行版面分析、表格识别,实现混合文字、多字体、多字号、横竖混排识别的强大的计算机信息快速录入工具。对印刷体汉字的识别率达到98%以上,即使对印刷质量较差的文字其识别率也达到95%以上。可识别宋体、黑体、楷体、仿宋体等多种字体的简、繁体,并且可以对多种字体、不同字号混合排版进行识别,对手写体汉字的识别率达到70%以上。特别是我国的汉字OCR技术经过十几年的努力,克服了起步晚、汉字字符集异常庞大等困难,单字的识别速度(指在单位时间内所完成的从特征提取到识别结果输出的字数)可以达到70字/秒以上。

OCR技术的基本原理
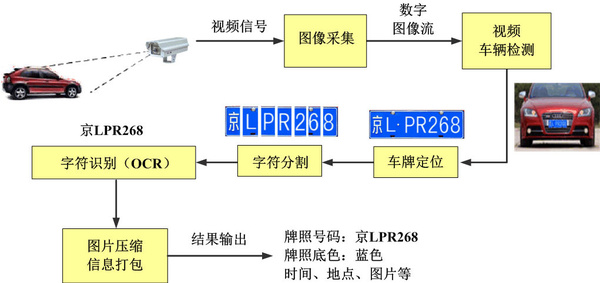
所谓OCR(Optical Character Reconginition 光字符识别技术),是指电子设备检查纸上打印的字符,通过检测暗亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。以车牌识别为例(文章来自CSDN的一篇博客):
1、车牌识别预处理:噪声过滤、自动白平衡、自动曝光以及伽马校对、边缘增强、对比度调整等。
2、车牌识别车牌定位:在通过图像预处理今后的灰度图像上进行部队扫描,判定车牌区域。
3、车牌识别字符切开:在图像中定位出车牌区域后,通过灰度化道闸、二值化等处理,精判定位字符区域,然后依据字符尺度特征进行字符切开。
4、字符识别:对切开后的字符进行缩放、特征提取,与字符数据库模板中的标准字符表达形式进行匹配区别。
5、效果输出:将车牌识别的效果以文本格式输出。
比较成熟的OCR产品有证件识别SDK、车牌识别SDK、文档识别SDK、银行卡识别SDK、表格识别SDK、票据识别SDK、名片识别SDK、护照识别SDK、身份证识别SDK等。