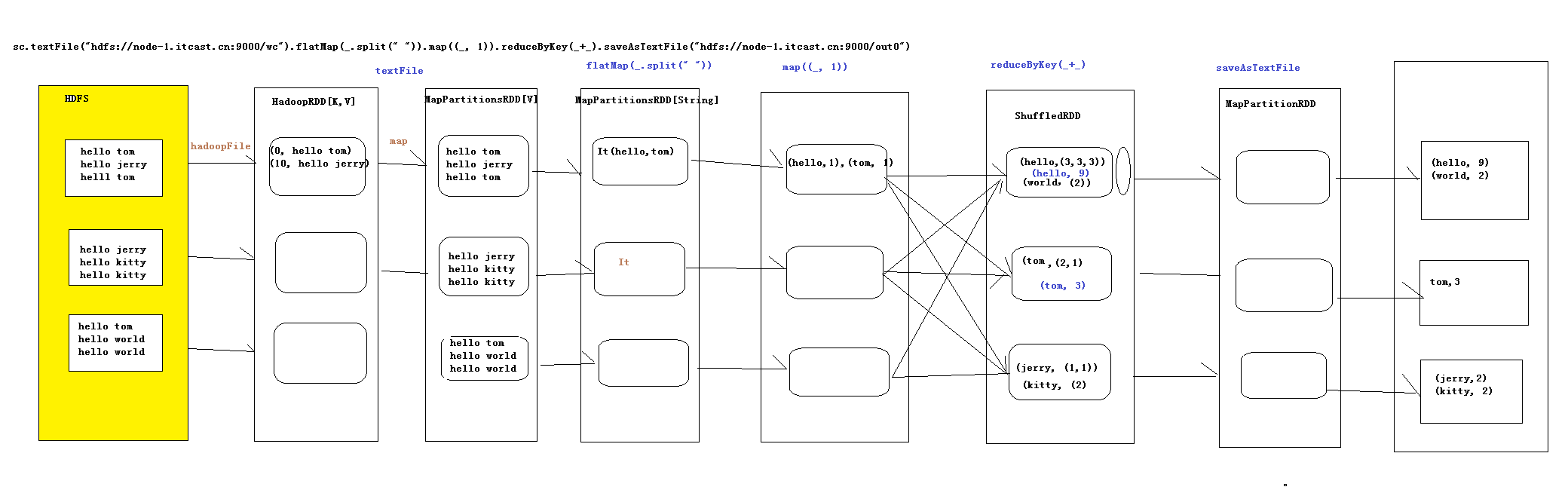
我们对于wordCount的这个流程,在清晰不过了,不过我们在使用spark以及hadoop本身的mapReduce的时候,我们是否理解其中的原理呢,今天我们就来介绍一下wordCount的执行原理,
1.首先我们都会这样子执行(wordCount执行在hadoop中)
val rdd = sc.textFile("hdfs://weekday01:9000/wc").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
rdd.saveAsTextFile("hdfs://weekday01:9000/out")
如果我们此时想看依赖的关系的话,我们可以这样操作
rdd.toDebugString(执行完这一步操作之后,你就可以看到你在hadoop中执行wordCount的这个过程,中间到底生成了
多少个rdd)
2.rdd与rdd的一些依赖关系
其实在我们每一次生成rdd的时候,都是由于后面的rdd要依赖前面的rdd
3.Lineage(血统)
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage记录下来,以便恢复丢失
的分区,
此时rdd不会记录这个血统中的各个rdd的具体的值是多少。RDD的Lineage会记录RDD的元数据信息和转换行为,
当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区
4.内部实现细节
1.textFile会产生两个RDD,1.HadoopRDD,为什么第一个是HadoopRDD,因为我们需要在hadoop里面读取数据,
读取数据的时候是以(key,value)的形式读取数据,其中的可以是偏移量,而value是一行的数据,
2.MapPartitionsRDD,以为我们调用了map方法,而这其中的map的作用是把key取消掉了,从而我们把value取出来
2.xxx.flatMap,则这个产生一个RDD,即MapPartionsRDD,
3.map((_,1)),这个是读取每一行的数据,然后在对每一行进行操作,然后在生成一个MapPartitionsRDD,
经过这个RDD之后,这个里面装的都是(key,value)类型的数据
4.reduceByKey,这个里面new了一个ShuffleRDD,要进行聚合,这个会经历两次聚合,第一聚合是在这个分区里面,
当聚合完成之后,从上游拉下来,在进行总体的聚合,这就是所谓的先分区,在总体
5..saveAsTextFile(path:String),因为这个的操作是往hdfs写数据,所以我们需要拿到hdfs的流,不过如果我们用map的话,
就相当于我的每一条数据我都会拿一个流,这样浪费资源,所以此时的我,使用的是mapPartition(),则此时是拿取一个分区里
面的数据,我们拿一个流,把这一个分区的数据都写进去
综上所述,一共产生了6个RDD
/** * Created by root on 2016/5/14. */ object WordCount { def main(args: Array[String]) { //非常重要,是通向Spark集群的入口 val conf = new SparkConf().setAppName("WC") .setJars(Array("C:\HelloSpark\target\hello-spark-1.0.jar")) .setMaster("spark://node-1.itcast.cn:7077") val sc = new SparkContext(conf) //textFile会产生两个RDD:HadoopRDD -> MapPartitinsRDD sc.textFile(args(0)).cache() // 产生一个RDD :MapPartitinsRDD .flatMap(_.split(" ")) //产生一个RDD MapPartitionsRDD .map((_, 1)) //产生一个RDD ShuffledRDD .reduceByKey(_+_) //产生一个RDD: mapPartitions .saveAsTextFile(args(1)) sc.stop() } }
流程图