大家好,我是阿辰。
今天带大家来看一下全国所有大学的数据信息(包括专本科,覆盖全国),一共是获取到了全国31个省份,共2769所大学。先预览一下数据:
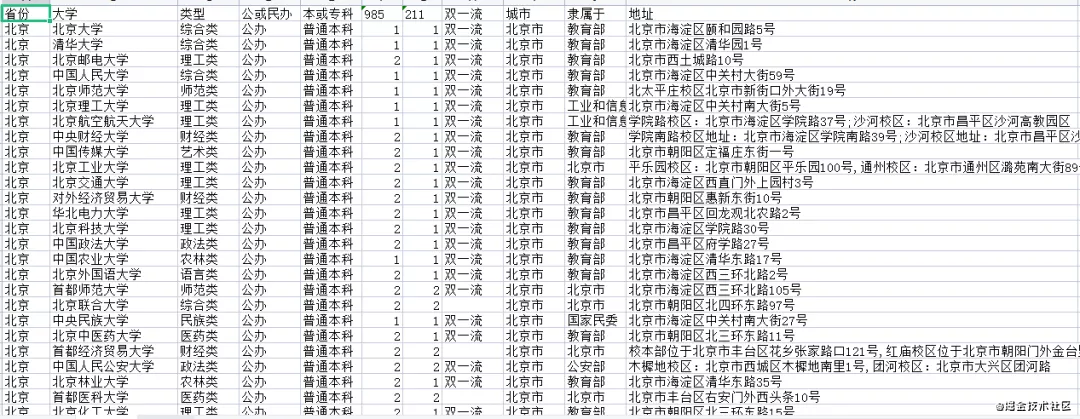
这里字段主要是包括了(省份、大学、类型、公或民办、本会专科、985、211、双一流、城市、隶属于、地址)
本文除了讲解怎么获取数据外,还将对这些数据进行可视化展示分析。
PS: 下面将一大把可视化动图袭来,别被震撼到,因为实在是太炫酷了(哈哈哈)
1.获取数据网页分析
在开始获取之前,先说一下数据的来源:
https://gkcx.eol.cn/school/search?schoolflag=&fromcoop=bdkp&is_recruitment=1&province=&cityname=
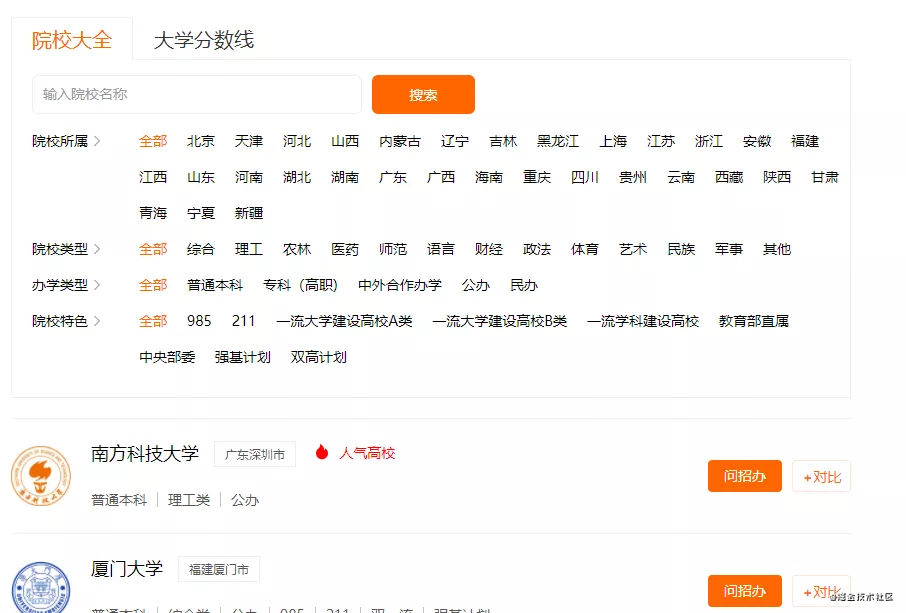
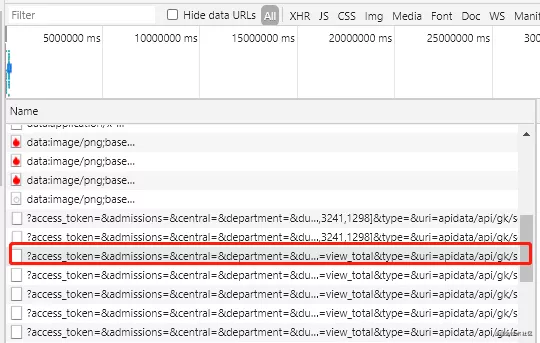
上图就是对应的网页,通过分析发现,数据是通过异步请求方式进行加载,因此打开Network,查看数据包,找到了数据在下面的数据包中
打开返回的json数据
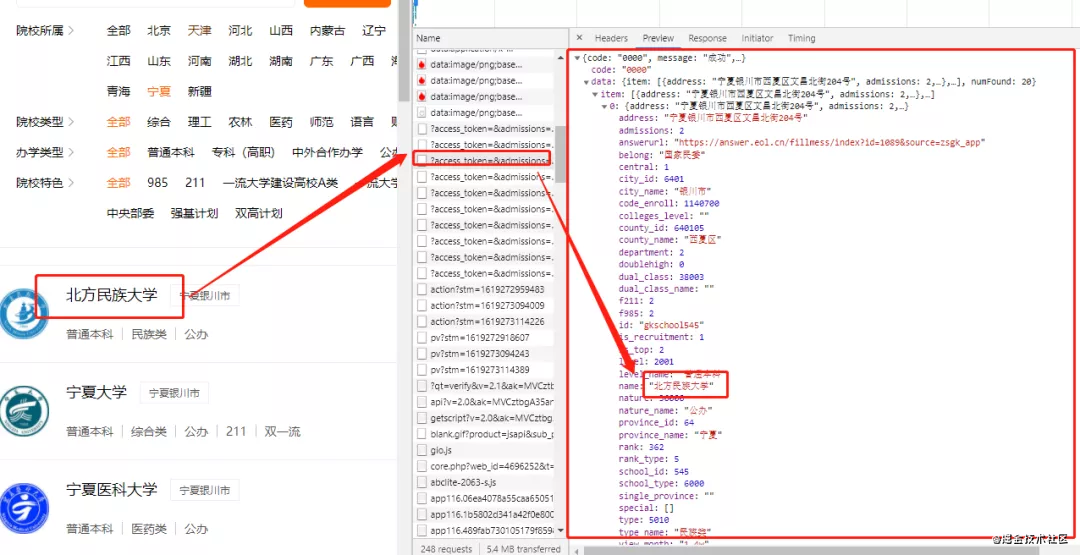
可以看到数据已经获取到了,并且是在data下的item里面。
下一页分析
请求的异步链接:
https://api.eol.cn/gkcx/api/?access_token=&admissions=¢ral=&department=&dual_class=&f211=&f985=&is_doublehigh=&is_dual_class=&is_recruitment=1&keyword=&nature=&page=1&province_id=64&ranktype=&request_type=1&school_type=&signsafe=&size=20&sort=view_total&type=&uri=apidata/api/gk/school/lists
通过异步链接可以发现,参数page是页面,province_id是对应的省份id(id是从11开始,12、13…)
因此通过变化page和province_id即可获取不同省份以及该省份所有大学情况,其核心代码如下:
for province_id in range(11,70):
try:
page = 1
while(1):
url = "https://api.eol.cn/gkcx/api/?access_token=&admissions=¢ral=&department=&dual_class=&f211=&f985=&is_doublehigh=&is_dual_class=&is_recruitment=1&keyword=&nature=&page="+str(page)+"&province_id="+str(province_id)+"&ranktype=&request_type=1&school_type=&signsafe=&size=20&sort=view_total&type=&uri=apidata/api/gk/school/lists"
text = requests.get(url,headers=headers).json()
datas = text['data']['item']
page = page+1
if len(datas)>0:
for i in range(0,len(datas)):
print(datas[i]['province_name'])
print(datas[i]['name'])
print(datas[i]['type_name'])
print(datas[i]['nature_name'])
print(datas[i]['level_name'])
print(datas[i]['f985'])
print(datas[i]['f211'])
print(datas[i]['dual_class_name'])
print(datas[i]['city_name'])
print(datas[i]['belong'])
print(datas[i]['address'])
else:
break
except:
pass
最后将数据保存到excel中


一共是2769所大学,下面开始进行可视化分析。
2.可视化分析1.不同省份大学数量
从excel中取出省份这一列,统计每一个省份行数,并进行排序
datafile = u'全国大学数据-李运辰.xls'
data = pd.read_excel(datafile)
attr = data['省份'].tolist()
result = Counter(attr)
# 排序
d = sorted(result.items(), key=lambda x: x[1], reverse=True)
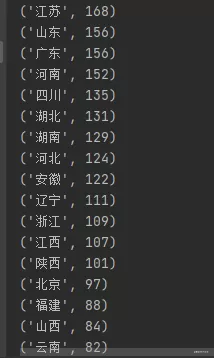
分析:
从排序上来看,江苏省的大学数量是最多的(168所),其次分别是山东、广东、河南、四川等
可视化效果:

2.统计省份对应不同市大学数量
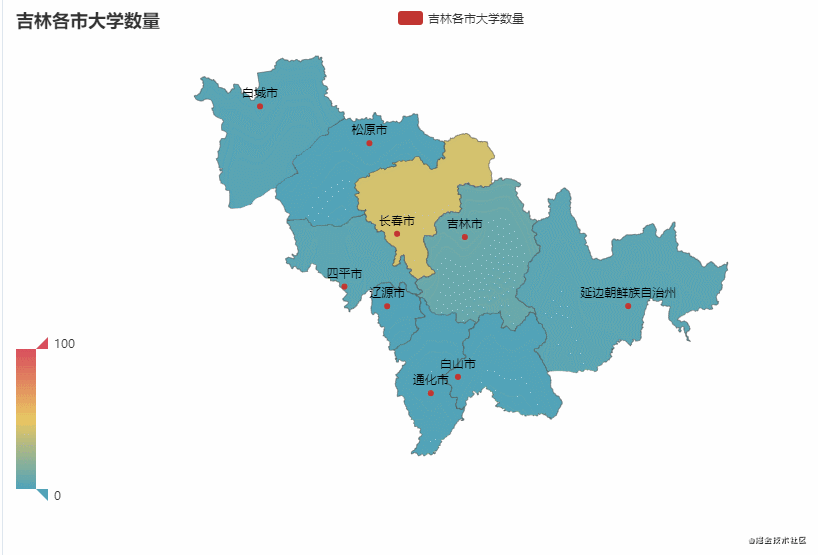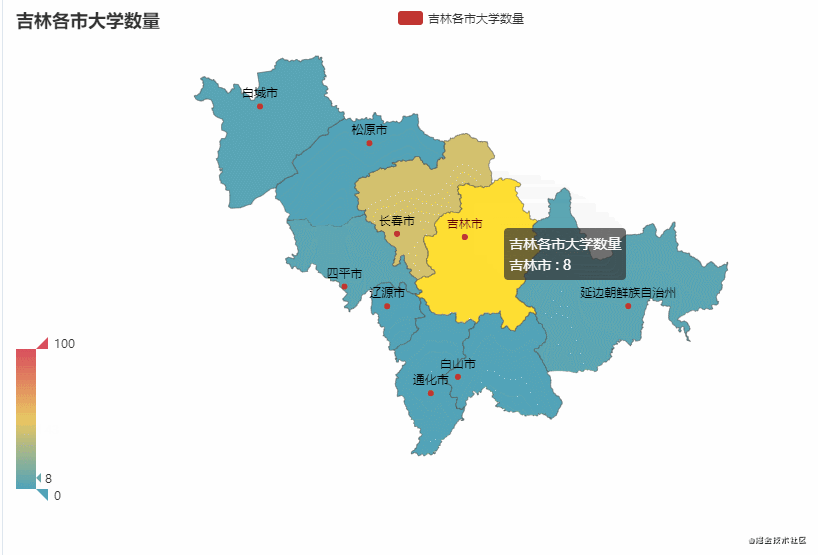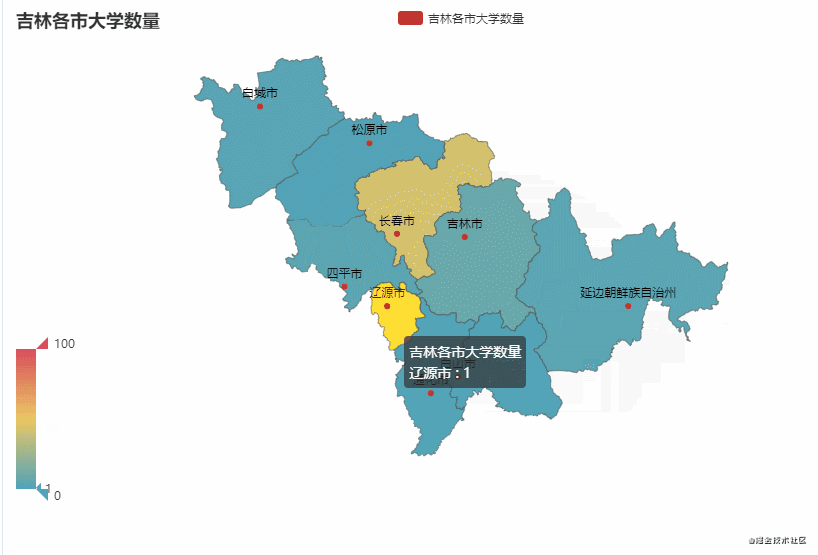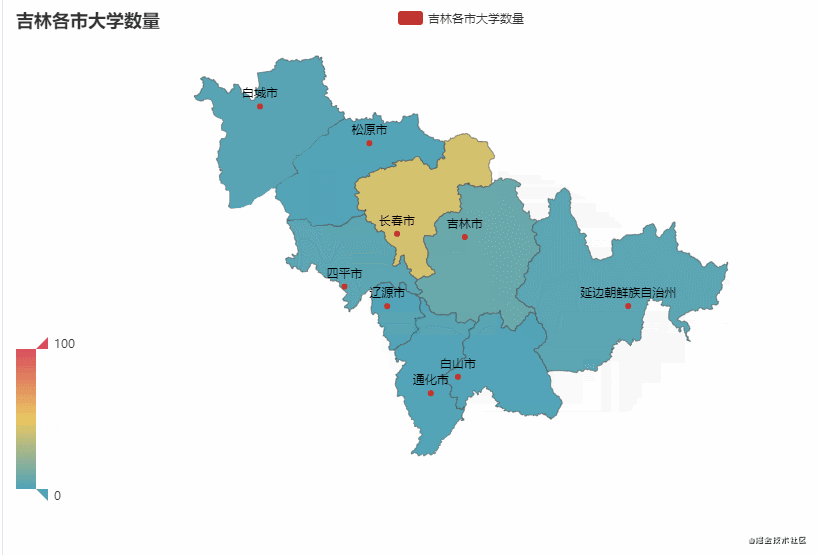
这里以广东省和吉林省为例,统计该省不同市有多少所大学
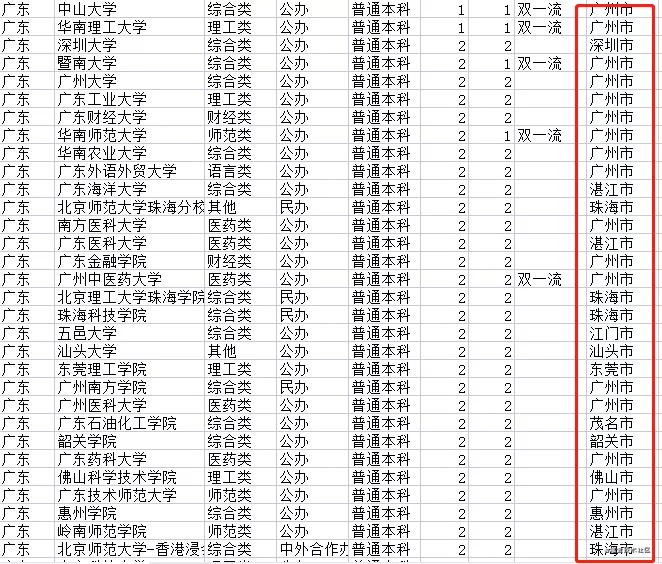
###广东所有城市
gd_city = []
###吉林所有城市
jl_city = []
for index, row in data.iterrows():
if row[0]=="广东":
gd_city.append(row[8])
if row[0]=="吉林":
jl_city.append(row[8])
print(gd_city)
print(jl_city)

下面开始统计城市数量并进行排序
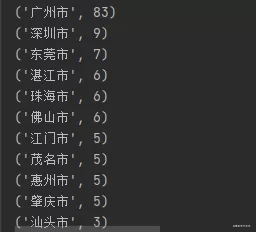

分析:
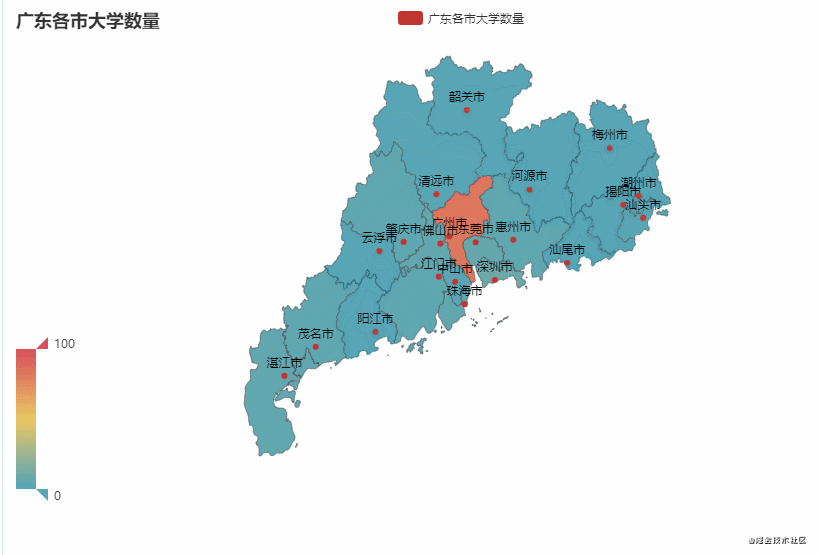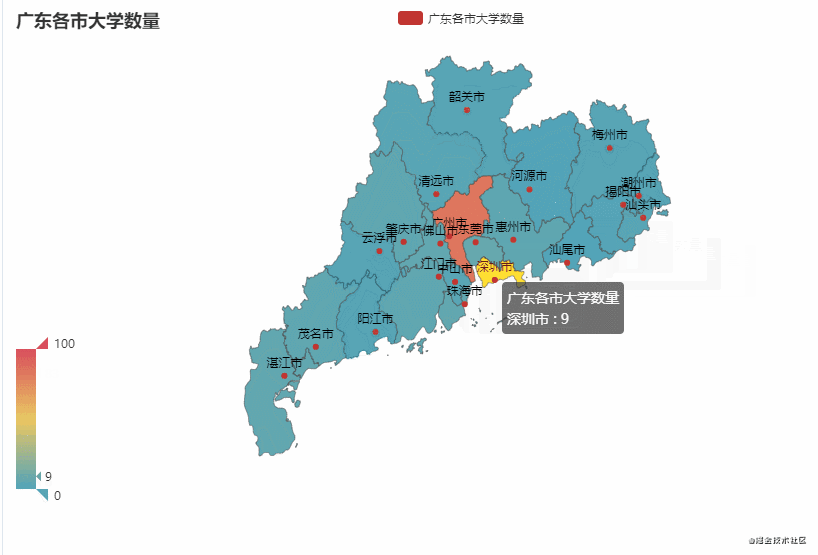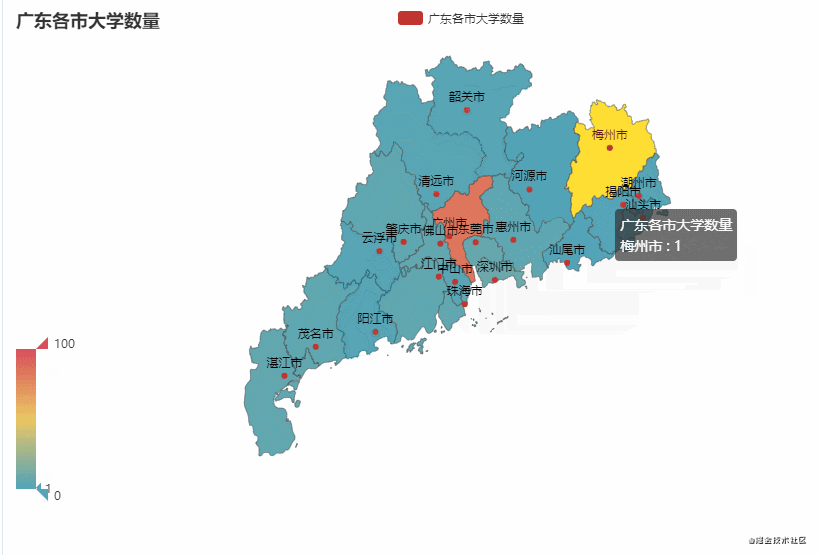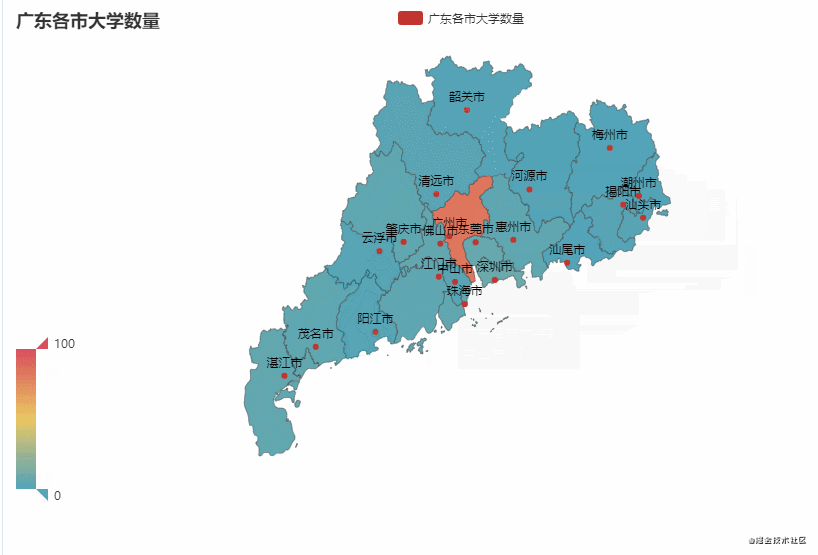
从图中可以看到,广东省的大学主要聚集在广州市较多(83),占比约50%。吉林省的大学主要聚集在长春市较多(43),占比约65%。
可视化效果:
3. 985、211以及双一流数量
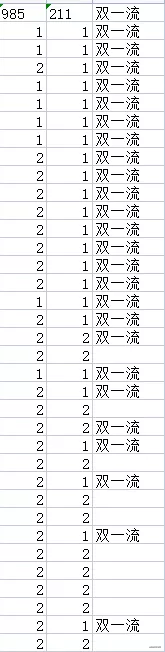
分别统计985、211以及双一流数量,先看一下数据(其中985和211这两列,1表示是,2表示不是)
for index, row in data.iterrows():
if row[5] == 1:
data_985.append(row[1])
if row[6] == 1:
data_211.append(row[1])
if row[7] == "双一流":
data_two_one.append(row[1])
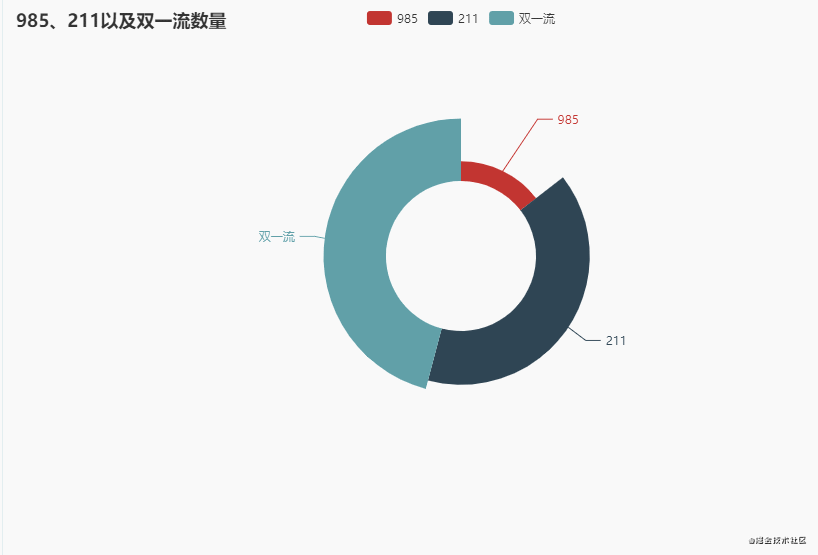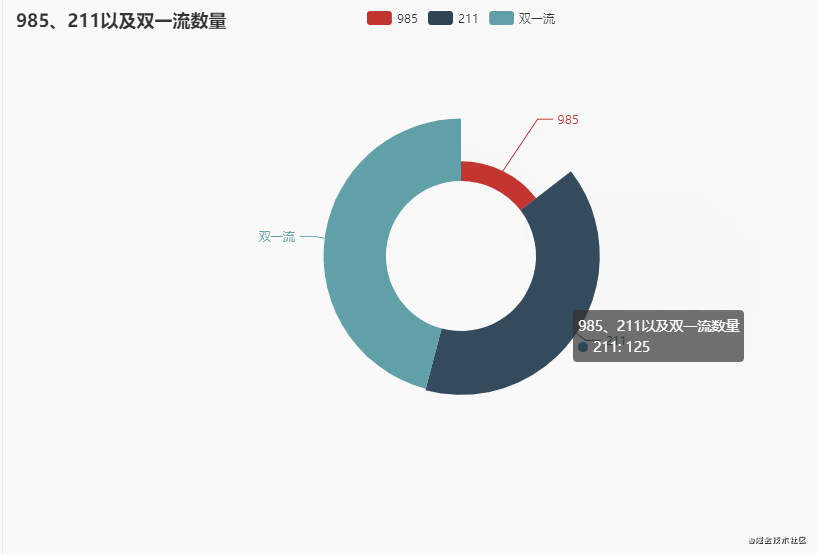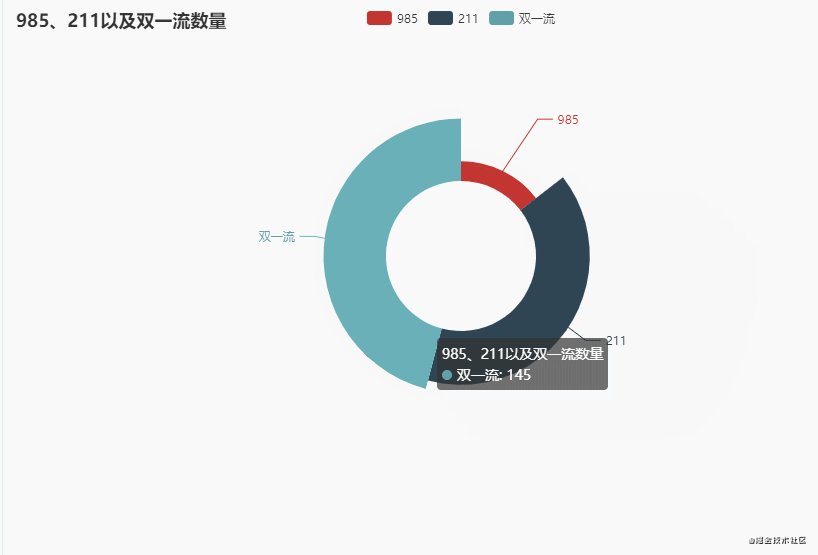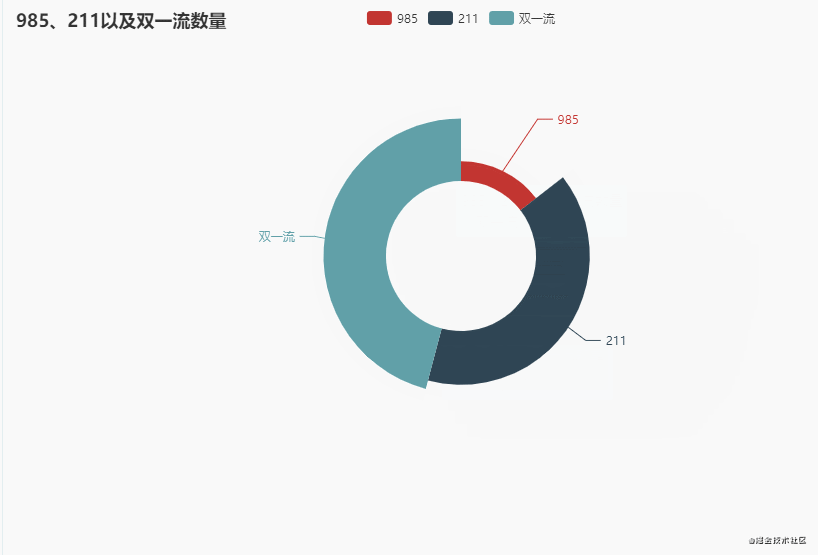
我们都知道985院校是39所,这里显示46所,这个是没错的,因为一些985院校有分校,所以就累计了46所,比如北京大学和北京大学医学部,这都是985
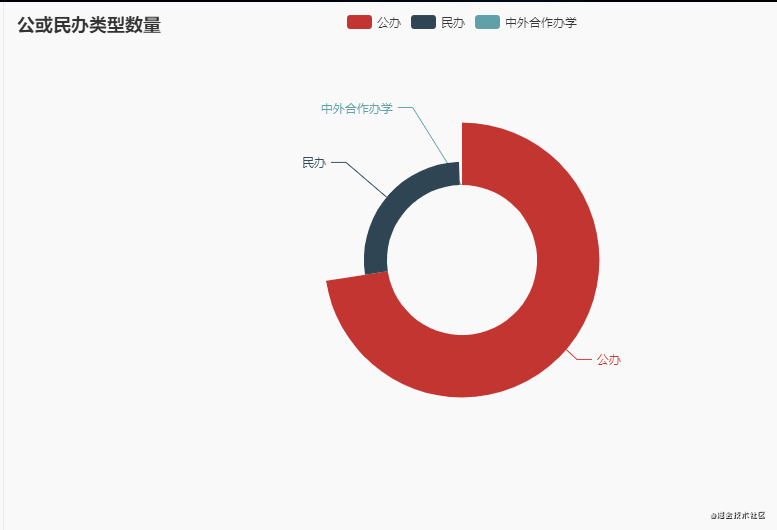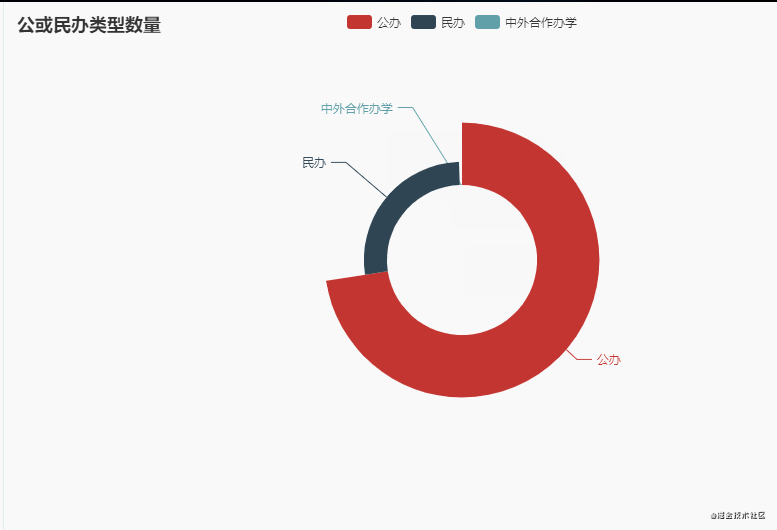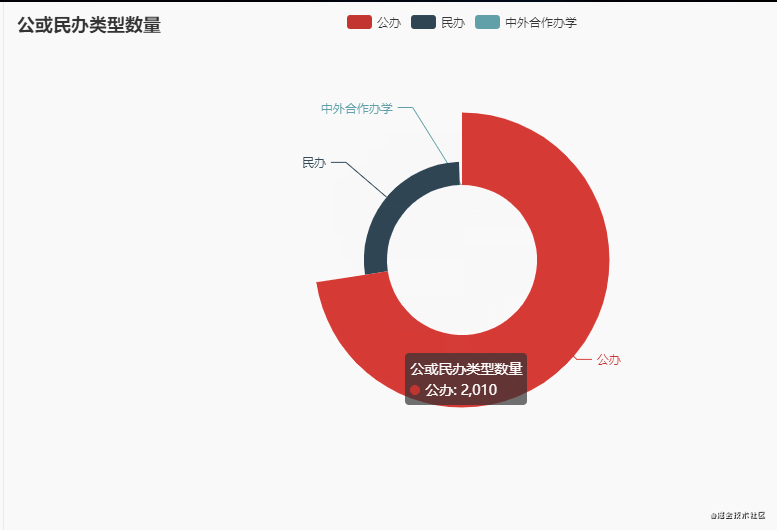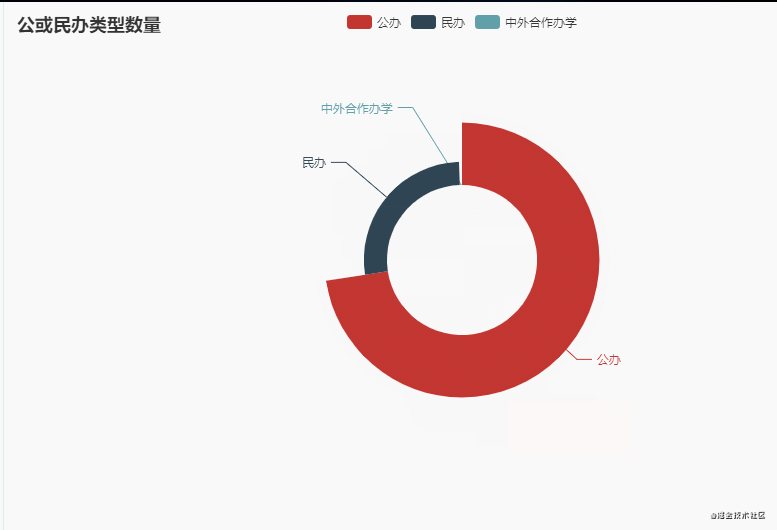
4.公或民办类型数量
分析:
从动图上来看,公办大学数量最多(2010),这个结果毫无疑问!其次还有少部分是中外合作办学
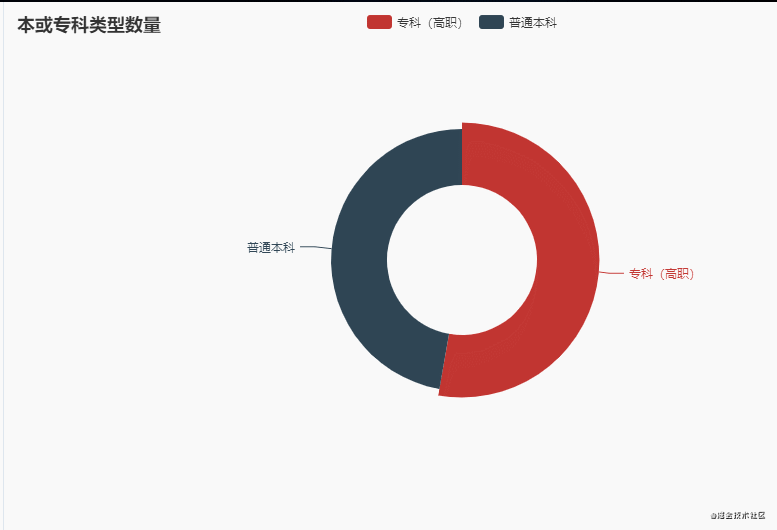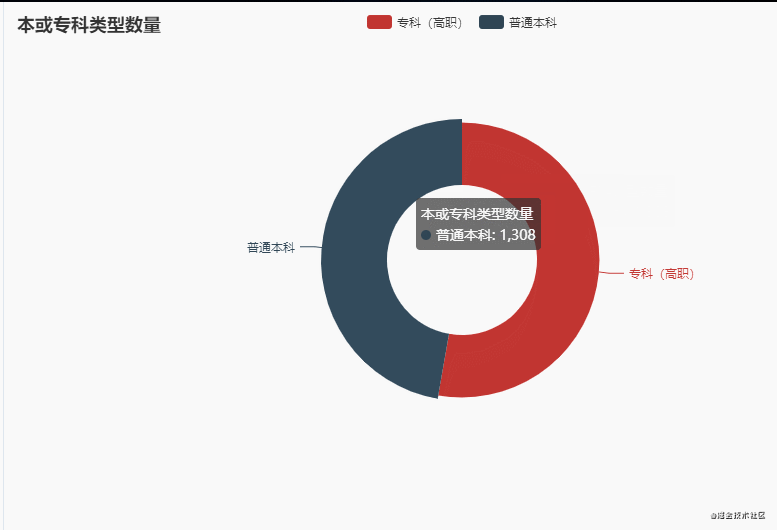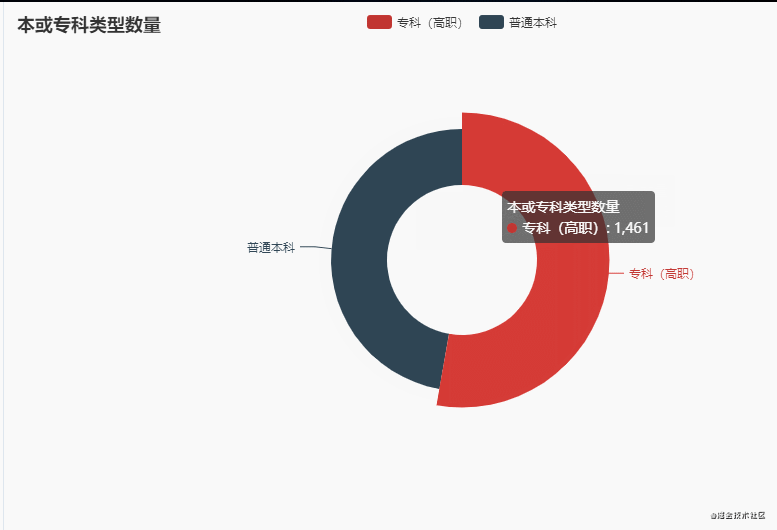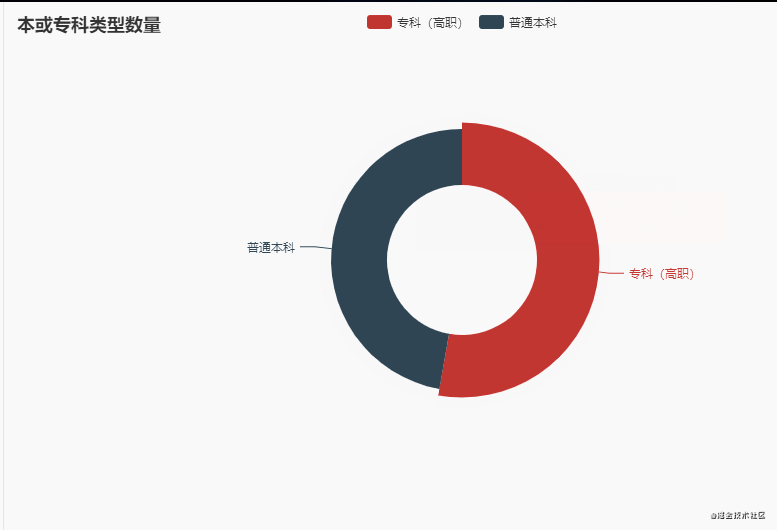
5.本或专科数量
分析:
从整体趋势上来看,本科和专科大学数量相差大概是在100左右!!
6.全国不同类型大学数量情况
先看一下数据

下面开始统计不同类型个数,并进行可视化展示分析
attr = data['类型'].tolist()
result = Counter(attr)
# 排序
d = sorted(result.items(), key=lambda x: x[1], reverse=True)
print(d)
key = [i[0] for i in d]
value = [i[1] for i in d]
可视化效果:

分析:
从图上来看,理工类和综合类大学居多,师范类和财经类以及医药类其次。
7.全国不同大学隶属情况
同样的先看一下数据
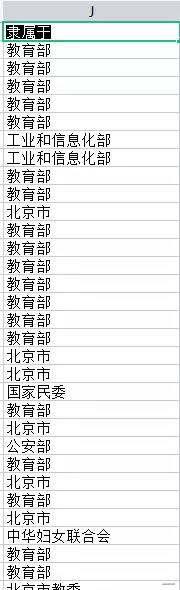
下面开始统计不同类型个数,并进行可视化展示分析
attr = data['隶属于'].tolist()
result = Counter(attr)
# 排序
d = sorted(result.items(), key=lambda x: x[1], reverse=True)
print(d)
key = [i[0] for i in d]
value = [i[1] for i in d]
可视化效果:
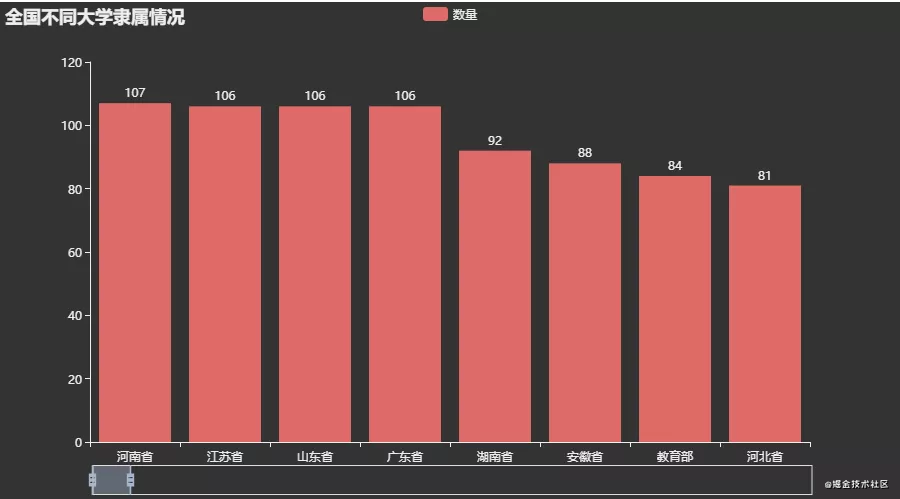
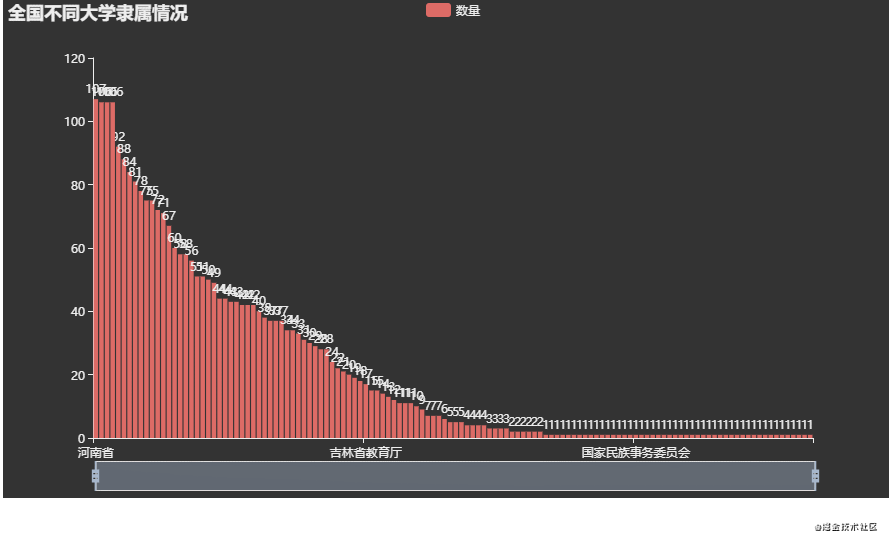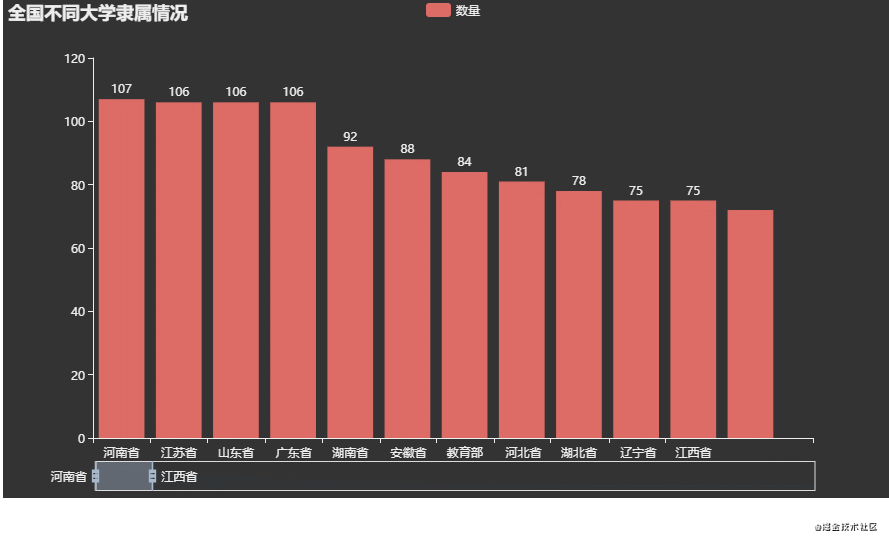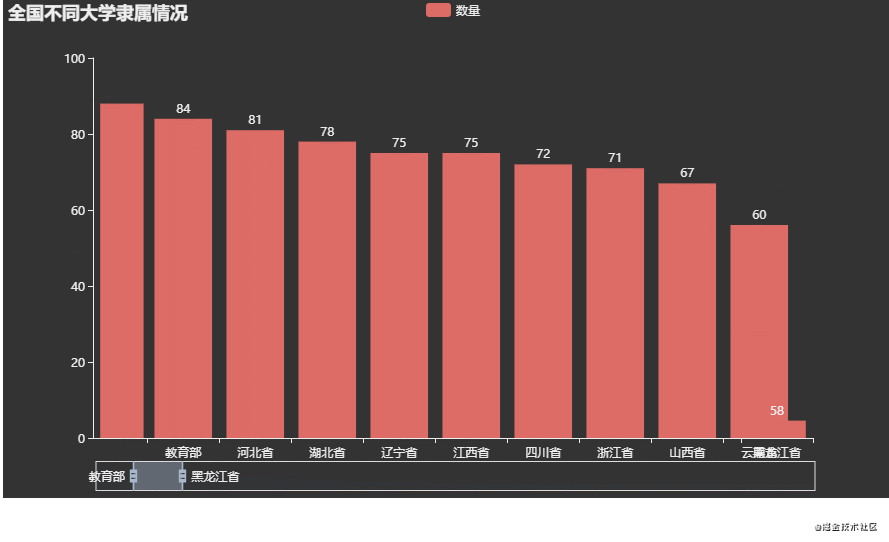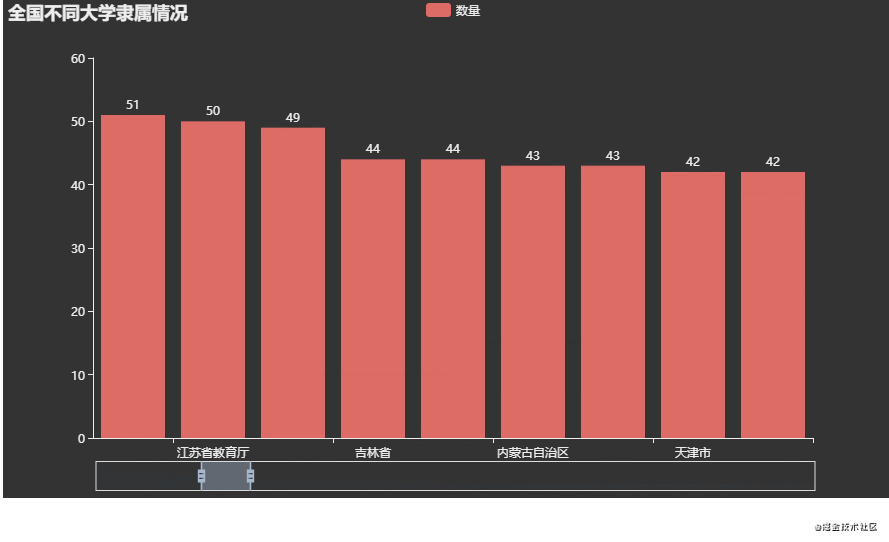
分析:
从图上可以看到前几名(河南、江苏、山东、广东)是属于省份的,猜测可能是普通本科以及专科院校居多,因此学校类型属于省份。
3.小结
本文讲解了如何去获取全国大学数据,最后通过可视化的方式展示数据,并进行分析。
如果想要学习python的小伙伴,可以下方扫码加我微信,备注:加群,我拉入进群交流学习(广告者勿扰,立刻踢),里面有大神免费答疑还有各种志同道合的小伙伴也在里面,现在就差你了!!!
