原文地址:http://lwn.net/Articles/250967/
1 简介
早期计算机比现在更为简单。系统的各种组件例如CPU,内存,大容量存储器和网口,由于被共同开发因而有非常均衡的表现。例如,内存和网口并不比CPU在提供数据的时候更(特别的)快。
曾今计算机稳定的基本结构悄然改变,硬件开发人员开始致力于优化单个子系统。于是电脑一些组件的性能大大的落后因而成为了瓶颈。由于开销的原因,大容量存储器和内存子系统相对于其他组件来说改善得更为缓慢。
大容量存储的性能问题往往靠软件来改善: 操作系统将常用(且最有可能被用)的数据放在主存中,因为后者的速度要快上几个数量级。或者将缓存加入存储设备中,这样就可以在不修改操作系统的前提下提升性能。{然而,为了在使用缓存时保证数据的完整性,仍然要作出一些修改。}这些内容不在本文的谈论范围之内,就不作赘述了。
而解决内存的瓶颈更为困难,它与大容量存储不同,几乎每种方案都需要对硬件作出修改。目前,这些变更主要有以下这些方式:
- RAM的硬件设计(速度与并发度)
- 内存控制器的设计
- CPU缓存
- 设备的直接内存访问(DMA)
本文主要关心的是CPU缓存和内存控制器的设计。在讨论这些主题的过程中,我们还会研究DMA。不过,我们首先会从当今商用硬件的设计谈起。这有助于我们理解目前在使用内存子系统时可能遇到的问题和限制。我们还会详细介绍RAM的分类,说明为什么会存在这么多不同类型的内存。
本文不会包括所有内容,也不会包括最终性质的内容。我们的讨论范围仅止于商用硬件,而且只限于其中的一小部分。另外,本文中的许多论题,我们只会点到为止,以达到本文目标为标准。对于这些论题,大家可以阅读其它文档,获得更详细的说明。
当本文提到操作系统特定的细节和解决方案时,针对的都是Linux。无论何时都不会包含别的操作系统的任何信息,作者无意讨论其他操作系统的情况。如果读者认为他/她不得不使用别的操作系统,那么必须去要求供应商提供其操作系统类似于本文的文档。
在开始之前最后的一点说明,本文包含大量出现的术语“经常”和别的类似的限定词。这里讨论的技术在现实中存在于很多不同的实现,所以本文只阐述使用得最广泛最主流的版本。在阐述中很少有地方能用到绝对的限定词。
1.1文档结构
这个文档主要视为软件开发者而写的。本文不会涉及太多硬件细节,所以喜欢硬件的读者也许不会觉得有用。但是在我们讨论一些有用的细节之前,我们先要描述足够多的背景。
在这个基础上,本文的第二部分将描述RAM(随机寄存器)。懂得这个部分的内容很好,但是此部分的内容并不是懂得其后内容必须部分。我们会在之后引用不少之前的部分,所以心急的读者可以跳过任何章节来读他们认为有用的部分。
第三部分会谈到不少关于CPU缓存行为模式的内容。我们会列出一些图标,这样你们不至于觉得太枯燥。第三部分对于理解整个文章非常重要。第四部分将简短的描述虚拟内存是怎么被实现的。这也是你们需要理解全文其他部分的背景知识之一。
第五部分会提到许多关于Non Uniform Memory Access (NUMA)系统。
第六部分是本文的中心部分。在这个部分里面,我们将回顾其他许多部分中的信息,并且我们将给阅读本文的程序员许多在各种情况下的编程建议。如果你真的很心急,那么你可以直接阅读第六部分,并且我们建议你在必要的时候回到之前的章节回顾一下必要的背景知识。
本文的第七部分将介绍一些能够帮助程序员更好的完成任务的工具。即便在彻底理解了某一项技术的情况下,距离彻底理解在非测试环境下的程序还是很遥远的。我们需要借助一些工具。
第八部分,我们将展望一些在未来我们可能认为好用的科技。
1.2 反馈问题
作者会不定期更新本文档。这些更新既包括伴随技术进步而来的更新也包含更改错误。非常欢迎有志于反馈问题的读者发送电子邮件。
1.3 致谢
我首先需要感谢Johnray Fuller尤其是Jonathan Corbet,感谢他们将作者的英语转化成为更为规范的形式。Markus Armbruster提供大量本文中对于问题和缩写有价值的建议。
1.4 关于本文
本文题目对David Goldberg的经典文献《What Every Computer Scientist Should Know About Floating-Point Arithmetic》[goldberg]表示致敬。Goldberg的论文虽然不普及,但是对于任何有志于严格编程的人都会是一个先决条件。
2 商用硬件现状
鉴于目前专业硬件正在逐渐淡出,理解商用硬件的现状变得十分重要。现如今,人们更多的采用水平扩展,也就是说,用大量小型、互联的商用计算机代替巨大、超快(但超贵)的系统。原因在于,快速而廉价的网络硬件已经崛起。那些大型的专用系统仍然有一席之地,但已被商用硬件后来居上。2007年,Red Hat认为,未来构成数据中心的“积木”将会是拥有最多4个插槽的计算机,每个插槽插入一个四核CPU,这些CPU都是超线程的。{超线程使单个处理器核心能同时处理两个以上的任务,只需加入一点点额外硬件}。也就是说,这些数据中心中的标准系统拥有最多64个虚拟处理器。当然可以支持更大的系统,但人们认为4插槽、4核CPU是最佳配置,绝大多数的优化都针对这样的配置。
在不同商用计算机之间,也存在着巨大的差异。不过,我们关注在主要的差异上,可以涵盖到超过90%以上的硬件。需要注意的是,这些技术上的细节往往日新月异,变化极快,因此大家在阅读的时候也需要注意本文的写作时间。
这么多年来,个人计算机和小型服务器被标准化到了一个芯片组上,它由两部分组成: 北桥和南桥,见图2.1。
图2.1 北桥和南桥组成的结构
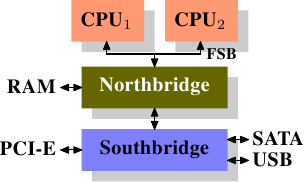
CPU通过一条通用总线(前端总线,FSB)连接到北桥。北桥主要包括内存控制器和其它一些组件,内存控制器决定了RAM芯片的类型。不同的类型,包括DRAM、Rambus和SDRAM等等,要求不同的内存控制器。
为了连通其它系统设备,北桥需要与南桥通信。南桥又叫I/O桥,通过多条不同总线与设备们通信。目前,比较重要的总线有PCI、PCI Express、SATA和USB总线,除此以外,南桥还支持PATA、IEEE 1394、串行口和并行口等。比较老的系统上有连接北桥的AGP槽。那是由于南北桥间缺乏高速连接而采取的措施。现在的PCI-E都是直接连到南桥的。
这种结构有一些需要注意的地方:
- 从某个CPU到另一个CPU的数据需要走它与北桥通信的同一条总线。
- 与RAM的通信需要经过北桥
- RAM只有一个端口。{本文不会介绍多端口RAM,因为商用硬件不采用这种内存,至少程序员无法访问到。这种内存一般在路由器等专用硬件中采用。}
- CPU与南桥设备间的通信需要经过北桥
在上面这种设计中,瓶颈马上出现了。第一个瓶颈与设备对RAM的访问有关。早期,所有设备之间的通信都需要经过CPU,结果严重影响了整个系统的性能。为了解决这个问题,有些设备加入了直接内存访问(DMA)的能力。DMA允许设备在北桥的帮助下,无需CPU的干涉,直接读写RAM。到了今天,所有高性能的设备都可以使用DMA。虽然DMA大大降低了CPU的负担,却占用了北桥的带宽,与CPU形成了争用。
第二个瓶颈来自北桥与RAM间的总线。总线的具体情况与内存的类型有关。在早期的系统上,只有一条总线,因此不能实现并行访问。近期的RAM需要两条独立总线(或者说通道,DDR2就是这么叫的,见图2.8),可以实现带宽加倍。北桥将内存访问交错地分配到两个通道上。更新的内存技术(如FB-DRAM)甚至加入了更多的通道。
由于带宽有限,我们需要以一种使延迟最小化的方式来对内存访问进行调度。我们将会看到,处理器的速度比内存要快得多,需要等待内存。如果有多个超线程核心或CPU同时访问内存,等待时间则会更长。对于DMA也是同样。
除了并发以外,访问模式也会极大地影响内存子系统、特别是多通道内存子系统的性能。关于访问模式,可参见2.2节。
在一些比较昂贵的系统上,北桥自己不含内存控制器,而是连接到外部的多个内存控制器上(在下例中,共有4个)。
图2.2 拥有外部控制器的北桥
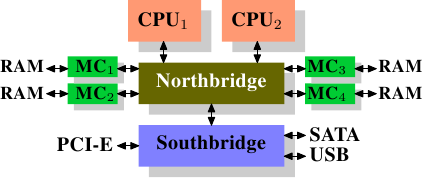
这种架构的好处在于,多条内存总线的存在,使得总带宽也随之增加了。而且也可以支持更多的内存。通过同时访问不同内存区,还可以降低延时。对于像图2.2中这种多处理器直连北桥的设计来说,尤其有效。而这种架构的局限在于北桥的内部带宽,非常巨大(来自Intel)。{出于完整性的考虑,还需要补充一下,这样的内存控制器布局还可以用于其它用途,比如说「内存RAID」,它可以与热插拔技术一起使用。}
使用外部内存控制器并不是唯一的办法,另一个最近比较流行的方法是将控制器集成到CPU内部,将内存直连到每个CPU。这种架构的走红归功于基于AMD Opteron处理器的SMP系统。图2.3展示了这种架构。Intel则会从Nehalem处理器开始支持通用系统接口(CSI),基本上也是类似的思路——集成内存控制器,为每个处理器提供本地内存。
图2.3 集成的内存控制器
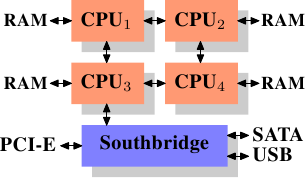
通过采用这样的架构,系统里有几个处理器,就可以有几个内存库(memory bank)。比如,在4 CPU的计算机上,不需要一个拥有巨大带宽的复杂北桥,就可以实现4倍的内存带宽。另外,将内存控制器集成到CPU内部还有其它一些优点,这里就不赘述了。
同样也有缺点。首先,系统仍然要让所有内存能被所有处理器所访问,导致内存不再是统一的资源(NUMA即得名于此)。处理器能以正常的速度访问本地内存(连接到该处理器的内存)。但它访问其它处理器的内存时,却需要使用处理器之间的互联通道。比如说,CPU 1如果要访问CPU 2的内存,则需要使用它们之间的互联通道。如果它需要访问CPU 4的内存,那么需要跨越两条互联通道。
使用互联通道是有代价的。在讨论访问远端内存的代价时,我们用「NUMA因子」这个词。在图2.3中,每个CPU有两个层级: 相邻的CPU,以及两个互联通道外的CPU。在更加复杂的系统中,层级也更多。甚至有些机器有不止一种连接,比如说IBM的x445和SGI的Altix系列。CPU被归入节点,节点内的内存访问时间是一致的,或者只有很小的NUMA因子。而在节点之间的连接代价很大,而且有巨大的NUMA因子。
目前,已经有商用的NUMA计算机,而且它们在未来应该会扮演更加重要的角色。人们预计,从2008年底开始,每台SMP机器都会使用NUMA。每个在NUMA上运行的程序都应该认识到NUMA的代价。在第5节中,我们将讨论更多的架构,以及Linux内核为这些程序提供的一些技术。
除了本节中所介绍的技术之外,还有其它一些影响RAM性能的因素。它们无法被软件所左右,所以没有放在这里。如果大家有兴趣,可以在第2.1节中看一下。介绍这些技术,仅仅是因为它们能让我们绘制的RAM技术全图更为完整,或者是可能在大家购买计算机时能够提供一些帮助。
以下的两节主要介绍一些入门级的硬件知识,同时讨论内存控制器与DRAM芯片间的访问协议。这些知识解释了内存访问的原理,程序员可能会得到一些启发。不过,这部分并不是必读的,心急的读者可以直接跳到第2.2.5节。
2.1 RAM类型
这些年来,出现了许多不同类型的RAM,各有差异,有些甚至有非常巨大的不同。那些很古老的类型已经乏人问津,我们就不仔细研究了。我们主要专注于几类现代RAM,剖开它们的表面,研究一下内核和应用开发人员们可以看到的一些细节。
第一个有趣的细节是,为什么在同一台机器中有不同的RAM?或者说得更详细一点,为什么既有静态RAM(SRAM {SRAM还可以表示「同步内存」。}),又有动态RAM(DRAM)。功能相同,前者更快。那么,为什么不全部使用SRAM?答案是,代价。无论在生产还是在使用上,SRAM都比DRAM要贵得多。生产和使用,这两个代价因子都很重要,后者则是越来越重要。为了理解这一点,我们分别看一下SRAM和DRAM一个位的存储的实现过程。
在本节的余下部分,我们将讨论RAM实现的底层细节。我们将尽量控制细节的层面,比如,在「逻辑的层面」讨论信号,而不是硬件设计师那种层面,因为那毫无必要。
2.1.1 静态RAM
图2.6 6-T静态RAM
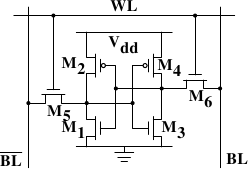
图2.4展示了6晶体管SRAM的一个单元。核心是4个晶体管M1-M4,它们组成两个交叉耦合的反相器。它们有两个稳定的状态,分别代表0和1。只要保持Vdd有电,状态就是稳定的。
当需要访问单元的状态时,升起字访问线WL。BL和BL上就可以读取状态。如果需要覆盖状态,先将BL和BL设置为期望的值,然后升起WL。由于外部的驱动强于内部的4个晶体管,所以旧状态会被覆盖。
更多详情,可以参考[sramwiki]。为了下文的讨论,需要注意以下问题:
一个单元需要6个晶体管。也有采用4个晶体管的SRAM,但有缺陷。
维持状态需要恒定的电源。
升起WL后立即可以读取状态。信号与其它晶体管控制的信号一样,是直角的(快速在两个状态间变化)。
状态稳定,不需要刷新循环。
SRAM也有其它形式,不那么费电,但比较慢。由于我们需要的是快速RAM,因此不在关注范围内。这些较慢的SRAM的主要优点在于接口简单,比动态RAM更容易使用。
2.1.2 动态RAM
动态RAM比静态RAM要简单得多。图2.5展示了一种普通DRAM的结构。它只含有一个晶体管和一个电容器。显然,这种复杂性上的巨大差异意味着功能上的迥异。
图2.5 1-T动态RAM
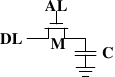
动态RAM的状态是保持在电容器C中。晶体管M用来控制访问。如果要读取状态,升起访问线AL,这时,可能会有电流流到数据线DL上,也可能没有,取决于电容器是否有电。如果要写入状态,先设置DL,然后升起AL一段时间,直到电容器充电或放电完毕。
动态RAM的设计有几个复杂的地方。由于读取状态时需要对电容器放电,所以这一过程不能无限重复,不得不在某个点上对它重新充电。
更糟糕的是,为了容纳大量单元(现在一般在单个芯片上容纳10的9次方以上的RAM单元),电容器的容量必须很小(0.000000000000001法拉以下)。这样,完整充电后大约持有几万个电子。即使电容器的电阻很大(若干兆欧姆),仍然只需很短的时间就会耗光电荷,称为「泄漏」。
这种泄露就是现在的大部分DRAM芯片每隔64ms就必须进行一次刷新的原因。在刷新期间,对于该芯片的访问是不可能的,这甚至会造成半数任务的延宕。(相关内容请察看【highperfdram】一章)
这个问题的另一个后果就是无法直接读取芯片单元中的信息,而必须通过信号放大器将0和1两种信号间的电势差增大。
最后一个问题在于电容器的冲放电是需要时间的,这就导致了信号放大器读取的信号并不是典型的矩形信号。所以当放大器输出信号的时候就需要一个小小的延宕,相关公式如下
![[Formulas]](https://img2020.cnblogs.com/blog/572188/202011/572188-20201117190128964-1223987188.png)
这就意味着需要一些时间(时间长短取决于电容C和电阻R)来对电容进行冲放电。另一个负面作用是,信号放大器的输出电流不能立即就作为信号载体使用。图2.6显示了冲放电的曲线,x轴表示的是单位时间下的R*C
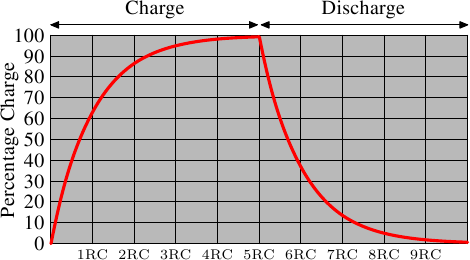
与静态RAM可以即刻读取数据不同的是,当要读取动态RAM的时候,必须花一点时间来等待电容的冲放电完全。这一点点的时间最终限制了DRAM的速度。
当然了,这种读取方式也是有好处的。最大的好处在于缩小了规模。一个动态RAM的尺寸是小于静态RAM的。这种规模的减小不单单建立在动态RAM的简单结构之上,也是由于减少了静态RAM的各个单元独立的供电部分。以上也同时导致了动态RAM模具的简单化。
综上所述,由于不可思议的成本差异,除了一些特殊的硬件(包括路由器什么的)之外,我们的硬件大多是使用DRAM的。这一点深深的影响了咱们这些程序员,后文将会对此进行讨论。在此之前,我们还是先了解下DRAM的更多细节。
2.1.3 DRAM 访问
一个程序选择了一个内存位置使用到了一个虚拟地址。处理器转换这个到物理地址最后将内存控制选择RAM芯片匹配了那个地址。在RAM芯片去选择单个内存单元,部分的物理地址以许多地址行的形式被传递。
它单独地去处理来自于内存控制器的内存位置将完全不切实际:4G的RAM将需要 232 地址行。地址传递DRAM芯片的这种方式首先必须被路由器解析。一个路由器的N多地址行将有2N 输出行。这些输出行能被使用到选择内存单元。使用这个直接方法对于小容量芯片不再是个大问题
但如果许多的单元生成这种方法不在适合。一个1G的芯片容量(我反感那些SI前缀,对于我一个giga-bit将总是230 而不是109字节)将需要30地址行和230 选项行。一个路由器的大小及许多的输入行以指数方式递增当速度不被牺牲时。一个30地址行路由器需要一大堆芯片的真实身份另外路由器也就复杂起来了。更重要的是,传递30脉冲在地址行同步要比仅仅传递15脉冲困难的多。较少列能精确布局相同长度或恰当的时机(现代DRAM类型像DDR3能自动调整时序但这个限制能让他什么都能忍受)
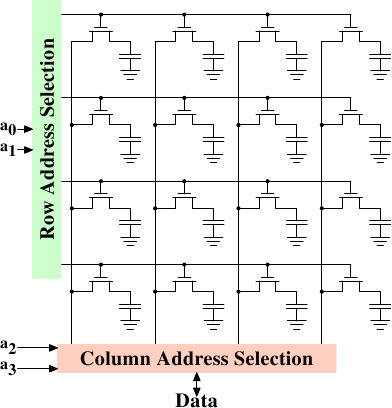
图2.7展示了一个很高级别的一个DRAM芯片,DRAM被组织在行和列里。他们能在一行中对奇但DRAM芯片需要一个大的路由器。通过阵列方法设计能被一个路由器和一个半的multiplexer获得{多路复用器(multiplexer)和路由器是一样的,这的multiplexer需要以路由器身份工作当写数据时候。那么从现在开始我们开始讨论其区别.}这在所有方面会是一个大的存储。例如地址linesa0和a1通过行地址选择路由器来选择整个行的芯片的地址列,当读的时候,所有的芯片目录能使其纵列选择路由器可用,依据地址linesa2和a3一个纵列的目录用于数据DRAM芯片的接口类型。这发生了许多次在许多DRAM芯片产生一个总记录数的字节匹配给一个宽范围的数据总线。
对于写操作,内存单元的数据新值被放到了数据总线,当使用RAS和CAS方式选中内存单元时,数据是存放在内存单元内的。这是一个相当直观的设计,在现实中——很显然——会复杂得多,对于读,需要规范从发出信号到数据在数据总线上变得可读的时延。电容不会像前面章节里面描述的那样立刻自动放电,从内存单元发出的信号是如此这微弱以至于它需要被放大。对于写,必须规范从数据RAS和CAS操作完成后到数据成功的被写入内存单元的时延(当然,电容不会立刻自动充电和放电)。这些时间常量对于DRAM芯片的性能是至关重要的,我们将在下章讨论它。
另一个关于伸缩性的问题是,用30根地址线连接到每一个RAM芯片是行不通的。芯片的针脚是非常珍贵的资源,以至数据必须能并行传输就并行传输(比如:64位为一组)。内存控制器必须有能力解析每一个RAM模块(RAM芯片集合)。如果因为性能的原因要求并发行访问多个RAM模块并且每个RAM模块需要自己独占的30或多个地址线,那么对于8个RAM模块,仅仅是解析地址,内存控制器就需要240+之多的针脚。
在很长一段时间里,地址线被复用以解决DRAM芯片的这些次要的可扩展性问题。这意味着地址被转换成两部分。第一部分由地址位a0和a1选择行(如图2.7)。这个选择保持有效直到撤销。然后是第二部分,地址位a2和a3选择列。关键差别在于:只需要两根外部地址线。需要一些很少的线指明RAS和CAS信号有效,但是把地址线的数目减半所付出的代价更小。可是地址复用也带来自身的一些问题。我们将在2.2章中提到。
2.1.4 总结
如果这章节的内容有些难以应付,不用担心。纵观这章节的重点,有:
- 为什么不是所有的存储器都是SRAM的原因
- 存储单元需要单独选择来使用
- 地址线数目直接负责存储控制器,主板,DRAM模块和DRAM芯片的成本
- 在读或写操作结果之前需要占用一段时间是可行的
接下来的章节会涉及更多的有关访问DRAM存储器的实际操作的细节。我们不会提到更多有关访问SRAM的具体内容,它通常是直接寻址。这里是由于速度和有限的SRAM存储器的尺寸。SRAM现在应用在CPU的高速缓存和芯片,它们的连接件很小而且完全能在CPU设计师的掌控之下。我们以后会讨论到CPU高速缓存这个主题,但我们所需要知道的是SRAM存储单元是有确定的最大速度,这取决于花在SRAM上的艰难的尝试。这速度与CPU核心相比略慢一到两个数量级。
2.2 DRAM访问细节
在上文介绍DRAM的时候,我们已经看到DRAM芯片为了节约资源,对地址进行了复用。而且,访问DRAM单元是需要一些时间的,因为电容器的放电并不是瞬时的。此外,我们还看到,DRAM需要不停地刷新。在这一节里,我们将把这些因素拼合起来,看看它们是如何决定DRAM的访问过程。
我们将主要关注在当前的科技上,不会再去讨论异步DRAM以及它的各种变体。如果对它感兴趣,可以去参考[highperfdram]及[arstechtwo]。我们也不会讨论Rambus DRAM(RDRAM),虽然它并不过时,但在系统内存领域应用不广。我们将主要介绍同步DRAM(SDRAM)及其后继者双倍速DRAM(DDR)。
同步DRAM,顾名思义,是参照一个时间源工作的。由内存控制器提供一个时钟,时钟的频率决定了前端总线(FSB)的速度。FSB是内存控制器提供给DRAM芯片的接口。在我写作本文的时候,FSB已经达到800MHz、1066MHz,甚至1333MHz,并且下一代的1600MHz也已经宣布。但这并不表示时钟频率有这么高。实际上,目前的总线都是双倍或四倍传输的,每个周期传输2次或4次数据。报的越高,卖的越好,所以这些厂商们喜欢把四倍传输的200MHz总线宣传为“有效的”800MHz总线。
以今天的SDRAM为例,每次数据传输包含64位,即8字节。所以FSB的传输速率应该是有效总线频率乘于8字节(对于4倍传输200MHz总线而言,传输速率为6.4GB/s)。听起来很高,但要知道这只是峰值速率,实际上无法达到的最高速率。我们将会看到,与RAM模块交流的协议有大量时间是处于非工作状态,不进行数据传输。我们必须对这些非工作时间有所了解,并尽量缩短它们,才能获得最佳的性能。
2.2.1 读访问协议
图2.8: SDRAM读访问的时序
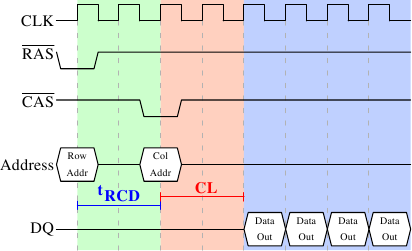
图2.8展示了某个DRAM模块一些连接器上的活动,可分为三个阶段,图上以不同颜色表示。按惯例,时间为从左向右流逝。这里忽略了许多细节,我们只关注时钟频率、RAS与CAS信号、地址总线和数据总线。首先,内存控制器将行地址放在地址总线上,并降低RAS信号,读周期开始。所有信号都在时钟(CLK)的上升沿读取,因此,只要信号在读取的时间点上保持稳定,就算不是标准的方波也没有关系。设置行地址会促使RAM芯片锁住指定的行。
CAS信号在tRCD(RAS到CAS时延)个时钟周期后发出。内存控制器将列地址放在地址总线上,降低CAS线。这里我们可以看到,地址的两个组成部分是怎么通过同一条总线传输的。
至此,寻址结束,是时候传输数据了。但RAM芯片任然需要一些准备时间,这个时间称为CAS时延(CL)。在图2.8中CL为2。这个值可大可小,它取决于内存控制器、主板和DRAM模块的质量。CL还可能是半周期。假设CL为2.5,那么数据将在蓝色区域内的第一个下降沿准备就绪。
既然数据的传输需要这么多的准备工作,仅仅传输一个字显然是太浪费了。因此,DRAM模块允许内存控制指定本次传输多少数据。可以是2、4或8个字。这样,就可以一次填满高速缓存的整条线,而不需要额外的RAS/CAS序列。另外,内存控制器还可以在不重置行选择的前提下发送新的CAS信号。这样,读取或写入连续的地址就可以变得非常快,因为不需要发送RAS信号,也不需要把行置为非激活状态(见下文)。是否要将行保持为“打开”状态是内存控制器判断的事情。让它一直保持打开的话,对真正的应用会有不好的影响(参见[highperfdram])。CAS信号的发送仅与RAM模块的命令速率(Command Rate)有关(常常记为Tx,其中x为1或2,高性能的DRAM模块一般为1,表示在每个周期都可以接收新命令)。
在上图中,SDRAM的每个周期输出一个字的数据。这是第一代的SDRAM。而DDR可以在一个周期中输出两个字。这种做法可以减少传输时间,但无法降低时延。DDR2尽管看上去不同,但在本质上也是相同的做法。对于DDR2,不需要再深入介绍了,我们只需要知道DDR2更快、更便宜、更可靠、更节能(参见[ddrtwo])就足够了。
2.2.2 预充电与激活
图2.8并不完整,它只画出了访问DRAM的完整循环的一部分。在发送RAS信号之前,必须先把当前锁住的行置为非激活状态,并对新行进行预充电。在这里,我们主要讨论由于显式发送指令而触发以上行为的情况。协议本身作了一些改进,在某些情况下是可以省略这个步骤的,但预充电带来的时延还是会影响整个操作。
图2.9: SDRAM的预充电与激活
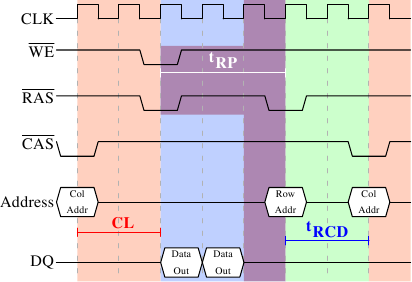
图2.9显示的是两次CAS信号的时序图。第一次的数据在CL周期后准备就绪。图中的例子里,是在SDRAM上,用两个周期传输了两个字的数据。如果换成DDR的话,则可以传输4个字。
即使是在一个命令速率为1的DRAM模块上,也无法立即发出预充电命令,而要等数据传输完成。在上图中,即为两个周期。刚好与CL相同,但只是巧合而已。预充电信号并没有专用线,某些实现是用同时降低写使能(WE)线和RAS线的方式来触发。这一组合方式本身没有特殊的意义(参见[micronddr])。
发出预充电信命令后,还需等待tRP(行预充电时间)个周期之后才能使行被选中。在图2.9中,这个时间(紫色部分)大部分与内存传输的时间(淡蓝色部分)重合。不错。但tRP大于传输时间,因此下一个RAS信号只能等待一个周期。
如果我们补充完整上图中的时间线,最后会发现下一次数据传输发生在前一次的5个周期之后。这意味着,数据总线的7个周期中只有2个周期才是真正在用的。再用它乘于FSB速度,结果就是,800MHz总线的理论速率6.4GB/s降到了1.8GB/s。真是太糟了。第6节将介绍一些技术,可以帮助我们提高总线有效速率。程序员们也需要尽自己的努力。
SDRAM还有一些定时值,我们并没有谈到。在图2.9中,预充电命令仅受制于数据传输时间。除此之外,SDRAM模块在RAS信号之后,需要经过一段时间,才能进行预充电(记为tRAS)。它的值很大,一般达到tRP的2到3倍。如果在某个RAS信号之后,只有一个CAS信号,而且数据只传输很少几个周期,那么就有问题了。假设在图2.9中,第一个CAS信号是直接跟在一个RAS信号后免的,而tRAS为8个周期。那么预充电命令还需要被推迟一个周期,因为tRCD、CL和tRP加起来才7个周期。
DDR模块往往用w-z-y-z-T来表示。例如,2-3-2-8-T1,意思是:
w 2 CAS时延(CL)
x 3 RAS-to-CAS时延(t RCD)
y 2 RAS预充电时间(t RP)
z 8 激活到预充电时间(t RAS)
T T1 命令速率
当然,除以上的参数外,还有许多其它参数影响命令的发送与处理。但以上5个参数已经足以确定模块的性能。
在解读计算机性能参数时,这些信息可能会派上用场。而在购买计算机时,这些信息就更有用了,因为它们与FSB/SDRAM速度一起,都是决定计算机速度的关键因素。
喜欢冒险的读者们还可以利用它们来调优系统。有些计算机的BIOS可以让你修改这些参数。SDRAM模块有一些可编程寄存器,可供设置参数。BIOS一般会挑选最佳值。如果RAM模块的质量足够好,我们可以在保持系统稳定的前提下将减小以上某个时延参数。互联网上有大量超频网站提供了相关的文档。不过,这是有风险的,需要大家自己承担,可别怪我没有事先提醒哟。
2.2.3 重充电
谈到DRAM的访问时,重充电是常常被忽略的一个主题。在2.1.2中曾经介绍,DRAM必须保持刷新。……行在充电时是无法访问的。[highperfdram]的研究发现,“令人吃惊,DRAM刷新对性能有着巨大的影响”。
根据JEDEC规范,DRAM单元必须保持每64ms刷新一次。对于8192行的DRAM,这意味着内存控制器平均每7.8125µs就需要发出一个刷新命令(在实际情况下,由于刷新命令可以纳入队列,因此这个时间间隔可以更大一些)。刷新命令的调度由内存控制器负责。DRAM模块会记录上一次刷新行的地址,然后在下次刷新请求时自动对这个地址进行递增。
对于刷新及发出刷新命令的时间点,程序员无法施加影响。但我们在解读性能参数时有必要知道,它也是DRAM生命周期的一个部分。如果系统需要读取某个重要的字,而刚好它所在的行正在刷新,那么处理器将会被延迟很长一段时间。刷新的具体耗时取决于DRAM模块本身。
2.2.4 内存类型
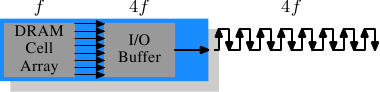
我们有必要花一些时间来了解一下目前流行的内存,以及那些即将流行的内存。首先从SDR(单倍速)SDRAM开始,因为它们是DDR(双倍速)SDRAM的基础。SDR非常简单,内存单元和数据传输率是相等的。
图2.10: SDR SDRAM的操作
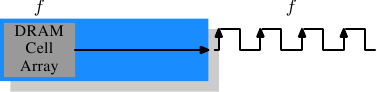
在图2.10中,DRAM单元阵列能以等同于内存总线的速率输出内容。假设DRAM单元阵列工作在100MHz上,那么总线的数据传输率可以达到100Mb/s。所有组件的频率f保持相同。由于提高频率会导致耗电量增加,所以提高吞吐量需要付出很高的的代价。如果是很大规模的内存阵列,代价会非常巨大。{功率 = 动态电容 x 电压2 x 频率}。而且,提高频率还需要在保持系统稳定的情况下提高电压,这更是一个问题。因此,就有了DDR SDRAM(现在叫DDR1),它可以在不提高频率的前提下提高吞吐量。
图2.11 DDR1 SDRAM的操作
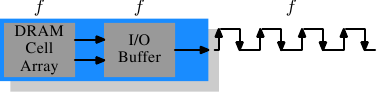
我们从图2.11上可以看出DDR1与SDR的不同之处,也可以从DDR1的名字里猜到那么几分,DDR1的每个周期可以传输两倍的数据,它的上升沿和下降沿都传输数据。有时又被称为“双泵(double-pumped)”总线。为了在不提升频率的前提下实现双倍传输,DDR引入了一个缓冲区。缓冲区的每条数据线都持有两位。它要求内存单元阵列的数据总线包含两条线。实现的方式很简单,用同一个列地址同时访问两个DRAM单元。对单元阵列的修改也很小。
SDR DRAM是以频率来命名的(例如,对应于100MHz的称为PC100)。为了让DDR1听上去更好听,营销人员们不得不想了一种新的命名方案。这种新方案中含有DDR模块可支持的传输速率(DDR拥有64位总线):
100MHz x 64位 x 2 = 1600MB/s
于是,100MHz频率的DDR模块就被称为PC1600。由于1600 > 100,营销方面的需求得到了满足,听起来非常棒,但实际上仅仅只是提升了两倍而已。{我接受两倍这个事实,但不喜欢类似的数字膨胀戏法。}
图2.12: DDR2 SDRAM的操作
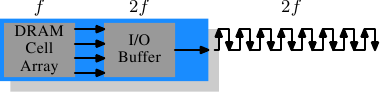
为了更进一步,DDR2有了更多的创新。在图2.12中,最明显的变化是,总线的频率加倍了。频率的加倍意味着带宽的加倍。如果对单元阵列的频率加倍,显然是不经济的,因此DDR2要求I/O缓冲区在每个时钟周期读取4位。也就是说,DDR2的变化仅在于使I/O缓冲区运行在更高的速度上。这是可行的,而且耗电也不会显著增加。DDR2的命名与DDR1相仿,只是将因子2替换成4(四泵总线)。图2.13显示了目前常用的一些模块的名称。
阵列频率 总线频率 数据率 名称(速率) 名称
(FSB)133MHz 266MHz 4,256MB/s PC2-4200 DDR2-533 166MHz 333MHz 5,312MB/s PC2-5300 DDR2-667 200MHz 400MHz 6,400MB/s PC2-6400 DDR2-800 250MHz 500MHz 8,000MB/s PC2-8000 DDR2-1000 266MHz 533MHz 8,512MB/s PC2-8500 DDR2-1066
图2.13: DDR2模块名
在命名方面还有一个拧巴的地方。FSB速度是用有效频率来标记的,即把上升、下降沿均传输数据的因素考虑进去,因此数字被撑大了。所以,拥有266MHz总线的133MHz模块有着533MHz的FSB“频率”。
DDR3要求更多的改变(这里指真正的DDR3,而不是图形卡中假冒的GDDR3)。电压从1.8V下降到1.5V。由于耗电是与电压的平方成正比,因此可以节约30%的电力。加上管芯(die)的缩小和电气方面的其它进展,DDR3可以在保持相同频率的情况下,降低一半的电力消耗。或者,在保持相同耗电的情况下,达到更高的频率。又或者,在保持相同热量排放的情况下,实现容量的翻番。
DDR3模块的单元阵列将运行在内部总线的四分之一速度上,DDR3的I/O缓冲区从DDR2的4位提升到8位。见图2.14。
图2.14: DDR3 SDRAM的操作
一开始,DDR3可能会有较高的CAS时延,因为DDR2的技术相比之下更为成熟。由于这个原因,DDR3可能只会用于DDR2无法达到的高频率下,而且带宽比时延更重要的场景。此前,已经有讨论指出,1.3V的DDR3可以达到与DDR2相同的CAS时延。无论如何,更高速度带来的价值都会超过时延增加带来的影响。
DDR3可能会有一个问题,即在1600Mb/s或更高速率下,每个通道的模块数可能会限制为1。在早期版本中,这一要求是针对所有频率的。我们希望这个要求可以提高一些,否则系统容量将会受到严重的限制。
图2.15显示了我们预计中各DDR3模块的名称。JEDEC目前同意了前四种。由于Intel的45nm处理器是1600Mb/s的FSB,1866Mb/s可以用于超频市场。随着DDR3的发展,可能会有更多类型加入。
图2.15: DDR3模块名
阵列频率 总线频率 数据速率 名称(速率) 名称
(FSB)100MHz 400MHz 6,400MB/s PC3-6400 DDR3-800 133MHz 533MHz 8,512MB/s PC3-8500 DDR3-1066 166MHz 667MHz 10,667MB/s PC3-10667 DDR3-1333 200MHz 800MHz 12,800MB/s PC3-12800 DDR3-1600 233MHz 933MHz 14,933MB/s PC3-14900 DDR3-1866
所有的DDR内存都有一个问题:不断增加的频率使得建立并行数据总线变得十分困难。一个DDR2模块有240根引脚。所有到地址和数据引脚的连线必须被布置得差不多一样长。更大的问题是,如果多于一个DDR模块通过菊花链连接在同一个总线上,每个模块所接收到的信号随着模块的增加会变得越来越扭曲。DDR2规范允许每条总线(又称通道)连接最多两个模块,DDR3在高频率下只允许每个通道连接一个模块。每条总线多达240根引脚使得单个北桥无法以合理的方式驱动两个通道。替代方案是增加外部内存控制器(如图2.2),但这会提高成本。
这意味着商品主板所搭载的DDR2或DDR3模块数将被限制在最多四条,这严重限制了系统的最大内存容量。即使是老旧的32位IA-32处理器也可以使用64GB内存。即使是家庭对内存的需求也在不断增长,所以,某些事必须开始做了。
一种解法是,在处理器中加入内存控制器,我们在第2节中曾经介绍过。AMD的Opteron系列和Intel的CSI技术就是采用这种方法。只要我们能把处理器要求的内存连接到处理器上,这种解法就是有效的。如果不能,按照这种思路就会引入NUMA架构,当然同时也会引入它的缺点。而在有些情况下,我们需要其它解法。
Intel针对大型服务器方面的解法(至少在未来几年),是被称为全缓冲DRAM(FB-DRAM)的技术。FB-DRAM采用与DDR2相同的器件,因此造价低廉。不同之处在于它们与内存控制器的连接方式。FB-DRAM没有用并行总线,而用了串行总线(Rambus DRAM had this back when, too, 而SATA是PATA的继任者,就像PCI Express是PCI/AGP的继承人一样)。串行总线可以达到更高的频率,串行化的负面影响,甚至可以增加带宽。使用串行总线后
- 每个通道可以使用更多的模块。
- 每个北桥/内存控制器可以使用更多的通道。
- 串行总线是全双工的(两条线)。
FB-DRAM只有69个脚。通过菊花链方式连接多个FB-DRAM也很简单。FB-DRAM规范允许每个通道连接最多8个模块。
在对比下双通道北桥的连接性,采用FB-DRAM后,北桥可以驱动6个通道,而且脚数更少——6x69对比2x240。每个通道的布线也更为简单,有助于降低主板的成本。
全双工的并行总线过于昂贵。而换成串行线后,这不再是一个问题,因此串行总线按全双工来设计的,这也意味着,在某些情况下,仅靠这一特性,总线的理论带宽已经翻了一倍。还不止于此。由于FB-DRAM控制器可同时连接6个通道,因此可以利用它来增加某些小内存系统的带宽。对于一个双通道、4模块的DDR2系统,我们可以用一个普通FB-DRAM控制器,用4通道来实现相同的容量。串行总线的实际带宽取决于在FB-DRAM模块中所使用的DDR2(或DDR3)芯片的类型。
我们可以像这样总结这些优势:
DDR2 FB-DRAM
DDR2 FB-DRAM 脚 240 69 通道 2 6 每通道DIMM数 2 8 最大内存 16GB 192GB 吞吐量 ~10GB/s ~40GB/s
如果在单个通道上使用多个DIMM,会有一些问题。信号在每个DIMM上都会有延迟(尽管很小),也就是说,延迟是递增的。不过,如果在相同频率和相同容量上进行比较,FB-DRAM总是能快过DDR2及DDR3,因为FB-DRAM只需要在每个通道上使用一个DIMM即可。而如果说到大型内存系统,那么DDR更是没有商用组件的解决方案。
2.2.5 结论
通过本节,大家应该了解到访问DRAM的过程并不是一个快速的过程。至少与处理器的速度相比,或与处理器访问寄存器及缓存的速度相比,DRAM的访问不算快。大家还需要记住CPU和内存的频率是不同的。Intel Core 2处理器运行在2.933GHz,而1.066GHz FSB有11:1的时钟比率(注: 1.066GHz的总线为四泵总线)。那么,内存总线上延迟一个周期意味着处理器延迟11个周期。绝大多数机器使用的DRAM更慢,因此延迟更大。在后续的章节中,我们需要讨论延迟这个问题时,请把以上的数字记在心里。
前文中读命令的时序图表明,DRAM模块可以支持高速数据传输。每个完整行可以被毫无延迟地传输。数据总线可以100%被占。对DDR而言,意味着每个周期传输2个64位字。对于DDR2-800模块和双通道而言,意味着12.8GB/s的速率。
但是,除非是特殊设计,DRAM的访问并不总是串行的。访问不连续的内存区意味着需要预充电和RAS信号。于是,各种速度开始慢下来,DRAM模块急需帮助。预充电的时间越短,数据传输所受的惩罚越小。
硬件和软件的预取(参见第6.3节)可以在时序中制造更多的重叠区,降低延迟。预取还可以转移内存操作的时间,从而减少争用。我们常常遇到的问题是,在这一轮中生成的数据需要被存储,而下一轮的数据需要被读出来。通过转移读取的时间,读和写就不需要同时发出了。
2.3 主存的其它用户
除了CPU外,系统中还有其它一些组件也可以访问主存。高性能网卡或大规模存储控制器是无法承受通过CPU来传输数据的,它们一般直接对内存进行读写(直接内存访问,DMA)。在图2.1中可以看到,它们可以通过南桥和北桥直接访问内存。另外,其它总线,比如USB等也需要FSB带宽,即使它们并不使用DMA,但南桥仍要通过FSB连接到北桥。
DMA当然有很大的优点,但也意味着FSB带宽会有更多的竞争。在有大量DMA流量的情况下,CPU在访问内存时必然会有更大的延迟。我们可以用一些硬件来解决这个问题。例如,通过图2.3中的架构,我们可以挑选不受DMA影响的节点,让它们的内存为我们的计算服务。还可以在每个节点上连接一个南桥,将FSB的负荷均匀地分担到每个节点上。除此以外,还有许多其它方法。我们将在第6节中介绍一些技术和编程接口,它们能够帮助我们通过软件的方式改善这个问题。
最后,还需要提一下某些廉价系统,它们的图形系统没有专用的显存,而是采用主存的一部分作为显存。由于对显存的访问非常频繁(例如,对于1024x768、16bpp、60Hz的显示设置来说,需要95MB/s的数据速率),而主存并不像显卡上的显存,并没有两个端口,因此这种配置会对系统性能、尤其是时延造成一定的影响。如果大家对系统性能要求比较高,最好不要采用这种配置。这种系统带来的问题超过了本身的价值。人们在购买它们时已经做好了性能不佳的心理准备。
继续阅读:
- 第2节: CPU的高速缓存
- 第3节: 虚拟内存
- 第4节: NUMA系统
- 第5节: 程序员可以做什么 - 高速缓存的优化
- 第6节: 程序员可以做什么 - 多线程的优化
- 第7节: 内存性能工具
- 第8节: 未来的技术
- 第9节: 附录与参考书目
今天的CPU比25年前复杂得多。在那些日子里,CPU内核的频率与内存总线的频率相同。内存访问仅比寄存器访问慢一点。但是在90年代初,情况发生了巨大变化,当时CPU设计人员增加了CPU内核的频率,但是内存总线的频率和RAM芯片的性能却没有成比例地增加。如上一节所述,这并不是由于无法构建更快的RAM。可能,但不经济。与当前CPU内核一样快的RAM比任何动态RAM贵几个数量级。
如果在具有很少,非常快的RAM的机器和具有很多相对较快的RAM的机器之间进行选择,则在工作集大小超过小RAM大小以及访问辅助存储介质的成本的情况下,第二个总是赢家。作为硬盘驱动器。这里的问题是辅助存储(通常是硬盘)的速度,必须使用辅助存储来容纳工作集的换出部分。访问这些磁盘要比DRAM访问慢几个数量级。
幸运的是,这不一定是一个全有或全无的决定。除了大量的DRAM外,计算机还可以具有少量的高速SRAM。一种可能的实现方式是将处理器的地址空间的某个区域专用为包含SRAM,其余为DRAM。操作系统的任务将是优化分配数据以利用SRAM。基本上,SRAM在这种情况下用作处理器寄存器集的扩展。
尽管这是一种可能的实现方式,但它并不可行。忽略将这种SRAM支持的内存的物理资源映射到进程的虚拟地址空间的问题(这本身很难做到),这种方法将需要每个进程在软件中管理该内存区域的分配。存储器区域的大小可能因处理器而异(即,处理器具有不同数量的昂贵的SRAM支持的存储器)。组成程序一部分的每个模块都将要求其共享快速存储器,这会通过同步要求而带来额外的成本。简而言之,具有快速内存的收益将被管理资源的开销完全吞噬。
因此,代替将SRAM置于OS或用户的控制之下,它成为一种资源,由处理器透明地使用和管理。在这种模式下,SRAM用于在主存储器中制作数据的临时副本(换句话说,用于缓存),该数据很可能会被处理器很快使用。这是可能的,因为程序代码和数据具有时间和空间局部性。这意味着在很短的时间内,很有可能重用相同的代码或数据。对于代码而言,这意味着代码中最有可能出现循环,从而使同一代码一遍又一遍地执行(空间局部性的完美案例 )。数据访问也理想地限于小区域。即使在短时间内使用的内存没有紧密结合在一起,也很可能在不久之后重新使用相同的数据(时间局部性)。对于代码,这意味着,例如,在循环中进行了一个函数调用,并且该函数位于地址空间中的其他位置。该函数可能在内存中很远,但是对该函数的调用将及时关闭。对于数据而言,这意味着一次限制使用的内存总量(工作集大小)是理想的,但由于RAM的随机访问性质,使用的内存并不紧密。认识到局部性是当今我们使用CPU缓存概念的关键。
一个简单的计算可以显示理论上缓存的有效性。假设对主存储器的访问需要200个周期,而对缓存的访问则需要15个周期。然后,如果没有缓存,则使用100个数据元素进行100次编码将在内存操作上花费2,000,000个周期,如果可以缓存所有数据,则仅花费168,500个周期。增长了91.5%。
用于缓存的SRAM的大小比主存储器小很多倍。根据作者使用带CPU缓存的工作站的经验,缓存大小始终约为主内存大小的1/1000(今天:4MB缓存和4GB主内存)。仅此一点并不构成问题。如果工作集(当前正在处理的数据集)的大小小于缓存大小,则没有关系。但是,计算机无缘无故拥有大量的主要记忆。工作集必然大于缓存。对于运行多个进程的系统尤其如此,其中工作集的大小是所有单个进程和内核的大小之和。
解决高速缓存的有限大小所需的是一组好的策略,以确定在任何给定时间应缓存的内容。由于并非完全同时使用工作集的所有数据,因此 我们可以使用技术将缓存中的某些数据临时替换为其他数据。也许可以在实际需要数据之前完成此操作。这种预取将消除访问主内存的一些成本,因为它相对于程序的执行是异步发生的。所有这些技术以及更多技术都可以用来使缓存看起来比实际更大。我们将在3.3节中讨论它们。一旦利用了所有这些技术,就应由程序员来帮助处理器。如何做到这一点将在第6节中讨论。
3.1概述中的CPU缓存
在深入研究CPU缓存实现的技术细节之前,一些读者可能会发现首先更详细地了解缓存如何适合现代计算机系统的“全局”是有用的。
图3.1:最低缓存配置
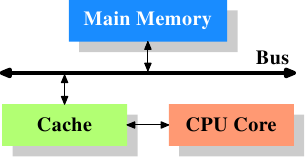
图3.1显示了最低缓存配置。它对应于在部署CPU缓存的早期系统中可以找到的体系结构。CPU内核不再直接连接到主存储器。{在更早的系统中,缓存也像CPU和主存储器一样被附加到系统总线上。这不是真正的解决方案,而是更多的技巧。}所有的加载和存储都必须经过缓存。CPU内核与缓存之间的连接是一种特殊的快速连接。在简化表示中,主存储器和高速缓存连接到系统总线,该系统总线也可用于与系统的其他组件进行通信。我们将系统总线称为“ FSB”,这是当今使用的名称。请参阅第2.2节。在本节中,我们将忽略北桥。假定存在它是为了促进CPU与主存储器的通信。
即使过去几十年的计算机使用了von Neumann架构,经验也表明,分离用于代码和数据的缓存是有利的。自1993年以来,英特尔一直使用独立的代码和数据缓存,从此再也没有回头。代码和数据所需的内存区域几乎彼此独立,这就是为什么独立的缓存可以更好地工作的原因。近年来,出现了另一个优势:最常用处理器的指令解码步骤很慢;缓存解码的指令可以加快执行速度,特别是当管道由于预测错误或无法预测的分支而为空时。
引入缓存后不久,系统变得更加复杂。高速缓存与主内存之间的速度差异再次增大,以至于添加了另一级高速缓存,该级别比第一级高速缓存更大,更慢。出于经济原因,仅增加一级缓存的大小是不可行的。如今,甚至有一些机器可以正常使用三级缓存。具有这种处理器的系统如图3.2所示。随着单个CPU中内核数量的增加,将来缓存级别的数量可能还会增加。
图3.2:具有3级缓存的处理器

图3.2显示了缓存的三个级别,并介绍了我们将在本文档的其余部分中使用的术语。L1d是1级数据高速缓存,L1i是1级指令高速缓存,以此类推。实际上,数据流不需要在从核心到主存储器的途中通过任何更高级别的缓存。CPU设计人员在设计缓存的接口时有很大的自由度。对于程序员来说,这些设计选择是看不见的。
另外,我们拥有具有多个核心的处理器,每个核心可以具有多个“线程”。芯和一个螺纹之间的区别是,单独的芯具有的单独的副本(几乎{早期多核处理器甚至有单独的2级级高速缓存和无3次级高速缓存。 })中的所有硬件资源。除非内核同时使用相同的资源(例如,与外部的连接),否则它们可以完全独立地运行。另一方面,线程几乎共享处理器的所有资源。英特尔的线程实现只为线程提供了单独的寄存器,即使这是有限的,某些寄存器也是共享的。因此,现代CPU的完整外观如图3.3所示。
图3.3:多处理器,多核,多线程
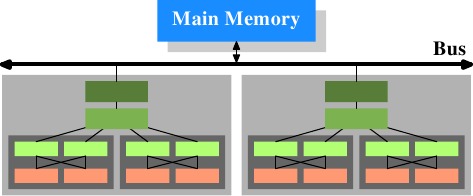
在此图中,我们有两个处理器,每个处理器具有两个内核,每个内核具有两个线程。线程共享1级缓存。核心(深灰色阴影)具有单独的1级缓存。CPU的所有内核共享更高级别的缓存。当然,这两个处理器(两个大盒子用浅灰色阴影表示)不共享任何缓存。所有这些都很重要,尤其是当我们讨论高速缓存对多进程和多线程应用程序的影响时。
3.2高速缓存操作
为了了解使用缓存的成本和节省,我们必须将第2节中有关机器体系结构和RAM技术的知识与上一节中描述的缓存结构相结合。
默认情况下,CPU内核读取或写入的所有数据都存储在缓存中。有一些无法缓存的内存区域,但这只是OS实现者必须关心的事情;应用程序程序员看不到它。还有一些指令允许程序员有意绕过某些缓存。这将在第6节中讨论。
如果CPU需要数据字,则首先搜索缓存。显然,缓存不能包含整个主内存的内容(否则我们就不需要缓存),但是由于所有内存地址都是可缓存的,因此每个缓存条目都使用主内存中数据字的地址进行标记。这样,读取或写入地址的请求可以在缓存中搜索匹配的标签。在此上下文中,该地址可以是虚拟地址,也可以是物理地址,具体取决于缓存的实现。
由于标签除了实际内存外还需要空间,因此选择单词作为缓存的粒度效率很低。对于x86机器上的32位字,标签本身可能需要32位或更多。此外,由于空间局部性是高速缓存所基于的原理之一,因此不考虑这一点将很不利。由于相邻的内存可能会一起使用,因此也应该一起将其加载到缓存中。还要记住我们在2.2.1节中学到的内容:如果RAM模块可以连续传输许多数据字而无需新的CAS甚至RAS,则它们的效率要高得多。信号。因此,存储在高速缓存中的条目不是单个单词,而是几个连续单词的“行”。在早期的缓存中,这些行的长度为32个字节。现在的标准是64个字节。如果内存总线为64位宽,则意味着每条高速缓存线进行8次传输。DDR有效地支持此传输模式。
当处理器需要内存内容时,整个高速缓存行将被加载到L1d中。通过根据缓存行大小屏蔽地址值来计算每个缓存行的内存地址。对于64字节的高速缓存行,这意味着低6位被清零。丢弃的位用作高速缓存行的偏移量。在某些情况下,剩余的位用于在缓存中定位该行并作为标记。实际上,地址值分为三个部分。对于32位地址,它可能如下所示:

高速缓存行大小为2 O时 ,低O位用作高速缓存行的偏移量。接下来的S位选择“缓存集”。我们很快将详细介绍为什么将集合而不是单个插槽用于高速缓存行。到目前为止,足以理解有2 S套高速缓存行。这样就剩下构成标签的前32 位-S - O = T位。这些T位是与每个高速缓存行相关联的值,以区分所有 别名{地址中具有相同S部分的所有高速缓存行都由相同别名知道。}缓存在同一缓存集中。用于寻址缓存集的S位不必存储,因为它们对于同一集合中的所有缓存行都是相同的。
当指令修改内存时,处理器仍然必须首先加载高速缓存行,因为没有一条指令会立即修改整个高速缓存行(规则除外:如第6.1节所述的写合并)。因此,必须加载写操作之前的高速缓存行的内容。缓存不可能保留部分缓存行。已被写入但尚未被写回到主存储器的高速缓存行被称为“脏”。一旦写入,脏标志将被清除。
为了能够在缓存中加载新数据,几乎总是首先需要在缓存中腾出空间。从L1d逐出将高速缓存行向下推入L2(使用相同的高速缓存行大小)。当然,这意味着必须在L2中放置空间。反过来,这可能会将内容推入L3并最终推入主存储器。每次搬迁都越来越昂贵。这里描述的是专用缓存的模型,这是现代AMD和VIA处理器首选的模型 。英特尔实现了包含性缓存{这种概括并不完全正确。一些缓存是互斥的,某些包含缓存具有互斥的缓存属性。} L1d中的每个高速缓存行也存在于L2中。因此,从L1d驱逐要快得多。有了足够的L2缓存,浪费在两个地方的内容上的内存的缺点是最小的,并且在收回时会得到回报。专用高速缓存的可能优点是,加载新的高速缓存行仅需触摸L1d而不是L2,这可能会更快。
只要不更改为处理器体系结构定义的内存模型,就可以允许CPU根据需要管理高速缓存。例如,处理器利用很少或没有内存总线活动,并主动将脏的缓存行写回到主内存是非常好的选择。x86和x86-64的处理器之间,制造商之间甚至同一制造商的模型之间的各种缓存体系结构,都证明了内存模型抽象的强大功能。
在对称多处理器(SMP)系统中,CPU的缓存不能彼此独立地工作。所有处理器都应该始终看到相同的内存内容。维持这种统一的内存视图称为“缓存一致性”。如果一个处理器仅查看其自己的缓存和主内存,它将看不到其他处理器中脏缓存行的内容。提供从另一处理器对一个处理器的高速缓存的直接访问将是非常昂贵的,并且是巨大的瓶颈。而是,处理器检测另一个处理器何时要读取或写入某个高速缓存行。
如果检测到写访问并且处理器在其高速缓存中具有该高速缓存行的干净副本,则将该高速缓存行标记为无效。将来的引用将需要重新加载缓存行。请注意,对另一个CPU的读取访问并不一定要使它无效,可以很好地保留多个干净副本。
更复杂的缓存实现允许发生另一种可能性。如果当前在第一个处理器的缓存中将另一个处理器要读取或写入的缓存行标记为脏,则需要采取不同的措施。在这种情况下,主存储器已过期,发出请求的处理器必须从第一个处理器获取缓存行内容。通过侦听,第一个处理器会注意到这种情况,并自动向发出请求的处理器发送数据。该操作绕过了主内存,尽管在某些实现中,内存控制器应该注意到这种直接传输并将更新的缓存行内容存储在主内存中。如果访问是为了写入第一个处理器,则使它的本地高速缓存行副本无效。
随着时间的流逝,已经开发了许多高速缓存一致性协议。最重要的是MESI,我们将在3.3.4节中介绍。所有这一切的结果可以归纳为一些简单的规则:
- 任何其他处理器的高速缓存中都没有脏高速缓存行。
- 同一缓存行的干净副本可以驻留在任意多个缓存中。
如果可以维持这些规则,那么即使在多处理器系统中,处理器也可以有效地使用其缓存。处理器所需要做的就是监视彼此的写访问,并将地址与其本地缓存中的地址进行比较。在下一节中,我们将进一步介绍有关实施的更多细节,尤其是成本。
最后,我们至少应该给与缓存命中和未命中相关的成本印象。这些是英特尔为奔腾M列出的数字:
去哪里 周期数 寄存器 <= 1 1天 〜3 L2 〜14 主记忆体 〜240
这些是以CPU周期为单位的实际访问时间。有趣的是,对于片上L2缓存,访问时间的很大一部分(可能甚至是大部分)是由线路延迟引起的。这是一个物理限制,只会随着高速缓存大小的增加而变得更糟。只有缩小工艺(例如,从Merom的60nm到Intel的Penryn的45nm)才能提高这些数字。
该表中的数字看起来很高,但是幸运的是,不必为每次发生的高速缓存加载和未命中支付全部费用。成本的某些部分可以隐藏。当今的处理器都使用不同长度的内部管线,在这些管线中对指令进行解码并准备执行。如果将值传输到寄存器,则准备工作的一部分是从内存(或缓存)中加载值。如果内存加载操作可以在管道中足够早地开始,则它可能与其他操作并行发生,并且可能隐藏了加载的全部成本。对于L1d,这通常是可能的;也适用于一些具有较长L2流水线的处理器。
尽早开始读取内存有很多障碍。这可能很简单,因为没有足够的资源来进行内存访问,或者可能是加载的最终地址由于另一条指令而变得较晚才可用。在这些情况下,无法完全隐藏负载成本。
对于写操作,CPU不必等待该值安全地存储在内存中。只要执行以下指令似乎与将值存储在内存中具有相同的效果,就不会阻止CPU使用快捷方式。它可以尽早开始执行下一条指令。在影子寄存器的帮助下,影子寄存器可以保存常规寄存器中不再可用的值,甚至可以更改要在不完整的写操作中存储的值。
图3.4:随机写入的访问时间

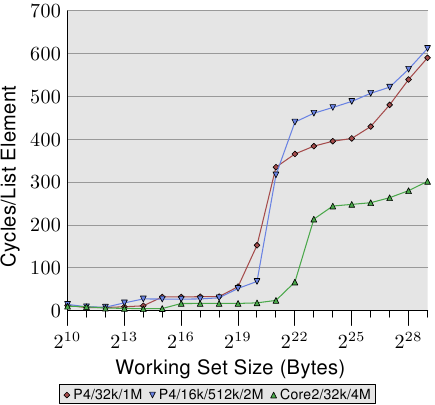
有关缓存行为的影响的说明,请参见图3.4。稍后我们将讨论生成数据的程序。它是对程序的简单模拟,该程序以随机方式重复访问可配置的内存量。每个数据项都有固定的大小。元素的数量取决于所选的工作集大小。Y轴显示处理一个元素所需的平均CPU周期数。请注意,Y轴的比例是对数的。在所有此类X轴图中同样如此。工作集的大小始终以2的幂表示。
该图显示了三个不同的平台。这并不奇怪:特定的处理器具有L1d和L2高速缓存,但没有L3。根据一些经验,我们可以推断出L1d的大小为2 13个字节,而L2的大小为2 20个字节。如果整个工作集都适合L1d,则每个元素的每次操作周期都小于10。一旦超出L1d大小,处理器就必须从L2加载数据,并且平均时间会上升到大约28。一旦L2不足现在,时间跃升至480个循环甚至更多。这是许多或大多数操作必须从主存储器加载数据的时候。更糟糕的是:由于数据正在被修改,脏的缓存行也必须被写回。
该图应有足够的动机来研究有助于改进缓存使用率的编码改进。在这里,我们谈论的不是百分之几;我们谈论的是有时可能的数量级改进。在第6节中,我们将讨论允许编写更有效代码的技术。下一节将详细介绍CPU缓存设计。有知识是好的,但对于本文的其余部分则不是必需的。因此可以跳过本节。
3.3 CPU缓存实现细节
高速缓存实现者的问题是,巨大的主内存中的每个单元都可能必须被高速缓存。如果程序的工作集足够大,则意味着有许多主内存位置会争用缓存中的每个位置。以前已经注意到,缓存与主内存大小的比例为1:1000并不罕见。
3.3.1关联性
有可能实现一个高速缓存,其中每个高速缓存行可以保存任何内存位置的副本。这称为完全关联缓存。为了访问高速缓存行,处理器核心将必须将每个高速缓存行的标签与请求地址的标签进行比较。标签将由地址的整个部分组成,而不是高速缓存行的偏移量(也就是说, 第3.2节中的S为零)。
有一些这样实现的缓存,但是通过查看当前使用的L2的数量,将表明这是不切实际的。给定一个具有64B高速缓存行的4MB高速缓存,该高速缓存将具有65,536个条目。为了获得足够的性能,缓存逻辑必须能够在短短几个周期内从所有这些条目中选择一个与给定标签匹配的条目。实现这一点的努力将是巨大的。
图3.5:完全关联的缓存原理图
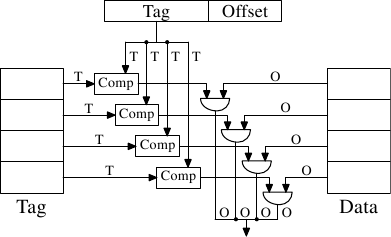
对于每个高速缓存行,都需要一个比较器来比较大标签(注意,S为零)。每个连接旁边的字母表示以位为单位的宽度。如果未给出,则为单条位线。每个比较器必须比较两个T位宽的值。然后,基于结果,选择适当的缓存行内容并使之可用。这需要合并尽可能多的 O数据行,因为有缓存桶。实现单个比较器所需的晶体管数量很大,特别是因为它必须非常快地工作。没有迭代比较器可用。节省比较器数量的唯一方法是通过迭代比较标签来减少比较器的数量。出于与迭代比较器不相同的原因,这是不合适的:它花费的时间太长。
完全关联的缓存适用于小型缓存(例如,某些Intel处理器上的TLB缓存是完全关联的),但这些缓存很小,甚至很小。我们最多谈论的是几十个条目。
对于L1i,L1d和更高级别的缓存,需要一种不同的方法。可以做的是限制搜索。在最极端的限制下,每个标签都恰好映射到一个缓存条目。计算很简单:给4MB / 64B高速缓存提供65,536个条目,我们可以使用地址的6至21位(16位)直接寻址每个条目。低6位是高速缓存行的索引。
图3.6:直接映射的缓存原理图
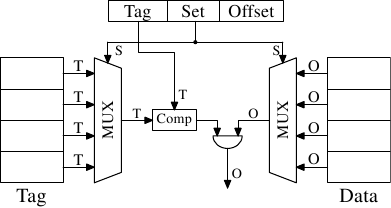
这样的直接映射缓存如图3.6所示,它非常快速且易于实施。它仅需要一个比较器,一个多路复用器(在此图中两个是将标签和数据分开的,但这对设计不是硬性要求),以及一些逻辑来仅选择有效的缓存行内容。由于速度要求,比较器很复杂,但是现在只有一个。结果,可以花更多的精力来加快速度。这种方法的真正复杂性在于多路复用器。简单多路复用器中的晶体管数量随O(log N)的增加而增加,其中N是高速缓存线的数量。这是可以忍受的,但可能会变慢,在这种情况下,可以通过在多路复用器中的晶体管上花费更多的空间来并行化某些工作并提高速度来提高速度。随着高速缓存大小的增加,晶体管的总数可以缓慢增长,这使得该解决方案非常有吸引力。但这有一个缺点:只有程序使用的地址相对于直接映射所使用的位均匀分布时,它才能很好地工作。如果不是这样(通常是这种情况),则某些缓存条目会被大量使用,因此会被重复逐出,而其他缓存条目则几乎不会被使用或保持为空。
图3.7:集关联缓存原理图
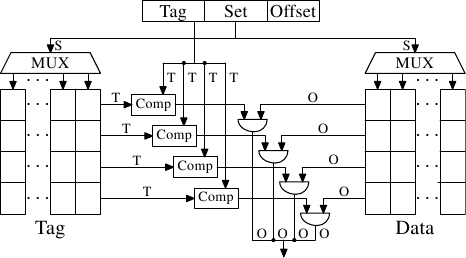
通过使缓存集具有关联性可以解决此问题。集关联缓存结合了完整关联缓存和直接映射缓存的功能,可以在很大程度上避免这些设计的缺点。图3.7显示了集合关联缓存的设计。标签和数据存储分为几组,由地址选择。这类似于直接映射的缓存。但是,对于缓存中的每个设置值而言,只有一个值被缓存,而不是每个设置值只有一个元素。并行比较所有set成员的标签,这与完全关联的缓存的功能类似。
结果是高速缓存不容易被不幸的或故意选择具有相同组号的地址所破坏,同时高速缓存的大小不受可并行实现的比较器数量的限制。如果缓存增长(在此图中),那么只有列数增加,而不是行数增加。仅当增加高速缓存的关联性时,行数才会增加。如今,处理器对二级缓存或更高级别使用的关联性级别高达16。L1缓存通常会加倍。
| L2 快取 大小 | 关联性 | |||||||
|---|---|---|---|---|---|---|---|---|
| 直接 | 2 | 4 | 8 | |||||
| CL = 32 | CL = 64 | CL = 32 | CL = 64 | CL = 32 | CL = 64 | CL = 32 | CL = 64 | |
| 512k | 27,794,595 | 20,422,527 | 25,222,611 | 18,303,581 | 24,096,510 | 17,356,121 | 23,666,929 | 17,029,334 |
| 1M | 19,007,315 | 13,903,854 | 16,566,738 | 12,127,174 | 15,537,500 | 11,436,705 | 15,162,895 | 11,233,896 |
| 2M | 12,230,962 | 8,801,403 | 9,081,881 | 6,491,011 | 7,878,601 | 5,675,181 | 7,391,389 | 5,382,064 |
| 4M | 7,749,986 | 5,427,836 | 4,736,187 | 3,159,507 | 3,788,122 | 2,418,898 | 3,430,713 | 2,125,103 |
| 8M | 4,731,904 | 3,209,693 | 2,690,498 | 1,602,957 | 2,207,655 | 1,228,190 | 2,111,075 | 1,155,847 |
| 1600万 | 2,620,587 | 1,528,592 | 1,958,293 | 1,089,580 | 1,704,878 | 883,530 | 1,671,541 | 862,324 |
表3.1:缓存大小,关联性和行大小的影响
给定我们的4MB / 64B高速缓存和8路集关联性,我们剩下的高速缓存具有8,192个集,并且仅13位标签用于寻址高速缓存集。为了确定高速缓存集中的哪些条目(如果有)包含所寻址的高速缓存行,必须比较8个标签。在很短的时间内这样做是可行的。通过实验我们可以看到这是有道理的。
表3.1列出了用于更改高速缓存大小,高速缓存行大小和关联集大小的程序(在这种情况下,gcc,这是所有程序中最重要的基准)的L2高速缓存未命中数。在第7.2节中,我们将介绍该工具来模拟此测试所需的缓存。
以防万一这还不是很明显,所有这些值之间的关系是缓存大小为
缓存行大小×关联性×套数
通过使用以下方式将地址映射到缓存中
O =日志2缓存行大小
S =日志2集数
按照第3.2节中的图所示。
图3.8:缓存大小与关联性(CL = 32)
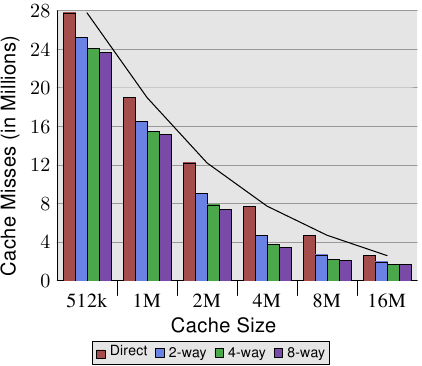
图3.8使表的数据更易理解。它显示了32字节的固定高速缓存行大小的数据。查看给定缓存大小的数字,可以发现关联确实可以帮助显着减少缓存未命中的次数。对于从直接映射到2路集关联高速缓存的8MB高速缓存,几乎可以节省44%的高速缓存未命中。与直接映射的缓存相比,处理器可以通过集合关联缓存将更多的工作集保留在缓存中。
在文献中,偶尔可以读到引入关联性与将缓存大小加倍具有相同的效果。在某些极端情况下确实如此,从4MB高速缓存到8MB高速缓存的跳转可以看出这一点。但是,对于进一步加倍的关联性而言,确实是不正确的。从数据中可以看出,连续增益要小得多。但是,我们不应该完全忽略这些影响。在示例程序中,峰值内存使用量为5.6M。因此,对于8MB高速缓存,同一高速缓存集不可能有太多(超过两个)用途。使用更大的工作集,可以节省更多的钱,正如我们从较小的缓存大小的关联性的更大好处中看到的那样。
通常,将高速缓存的关联性提高到8以上似乎对单线程工作负载几乎没有影响。随着使用共享L2的多核处理器的引入,情况发生了变化。现在,您基本上有两个程序在同一个缓存上命中,这实际上导致了关联性减半(或四核处理器四分之一)。因此可以预料,随着内核数量的增加,共享缓存的关联性应该会增加。一旦这不再可能(16路集关联已经很困难),处理器设计人员就必须开始使用共享的L3高速缓存以及更多,而L2高速缓存可能由一部分内核共享。
我们可以在图3.8中研究的另一个影响是高速缓存大小的增加如何帮助提高性能。在不知道工作集大小的情况下无法解释此数据。显然,与较小的缓存相比,与主内存一样大的缓存将带来更好的结果,因此,对具有可衡量的好处的最大缓存大小通常没有限制。
如上所述,工作集的峰值大小为5.6M。这没有给我们提供最大有用缓存大小的任何绝对数量,但可以让我们估计数量。问题在于,并非所有使用的内存都是连续的,因此,即使使用16M高速缓存和5.6M工作集,我们也会发生冲突(请参阅2路集关联16MB高速缓存相对于直接映射版本的好处) 。但是可以肯定的是,在相同的工作负载下,32MB高速缓存的好处可以忽略不计。但是谁说工作集必须保持不变?工作量随时间增长,因此缓存大小也应随之增加。当购买机器时,必须选择一个愿意支付的缓存大小,这是值得衡量的工作集大小。为什么如此重要,请参见图3.10。
图3.9:测试内存布局
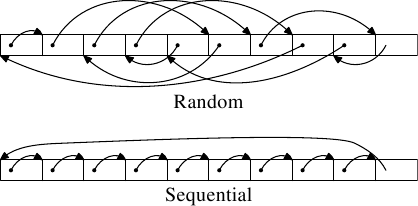
运行两种类型的测试。在第一个测试中,元素将被顺序处理。测试程序跟随指针n, 但是将数组元素链接在一起,以便按照在内存中找到它们的顺序遍历它们。这可以在图3.9的下部看到。最后一个元素有一个反向引用。在第二个测试中(该图的上部),以随机顺序遍历数组元素。在这两种情况下,数组元素都构成一个循环的单链列表。
3.3.2缓存效果的度量
通过测量程序可以创建所有图形,该程序可以模拟任意大小的工作集,读写访问权限以及顺序访问或随机访问。我们已经在图3.4中看到了一些结果。程序创建一个与该类型元素的工作集大小相对应的数组:
struct l { struct l * n; long int pad [NPAD]; };
使用n元素(按顺序或随机顺序)将所有条目链接在循环列表中。即使元素是按顺序排列的,从一个条目前进到下一个条目始终使用指针。该垫元素是有效载荷,它可以尽量增大。在某些测试中,数据被修改,而在另一些测试中,程序仅执行读取操作。
在性能度量中,我们谈论的是工作集大小。工作集由结构l 元素的数组组成。2 N字节的工作集包含
2 N / sizeof(结构l)
元素。显然sizeof(struct l)取决于NPAD的值 。对于32位系统,NPAD = 7表示每个数组元素的大小为32字节,对于64位系统,其大小为64字节。
单线程顺序访问
最简单的情况是遍历列表中的所有条目。列表元素顺序排列,密集排列。处理顺序是向前还是向后都无所谓,处理器可以很好地处理两个方向。我们在这里(以及随后的所有测试中)测量的是处理单个列表元素需要多长时间。时间单位是处理器周期。结果如图3.10所示。除非另有说明,所有测量均在64位模式下,这意味着结构的奔腾4的机器上制成升与NPAD = 0是在大小的8个字节。
图3.10:顺序读取访问,NPAD = 0
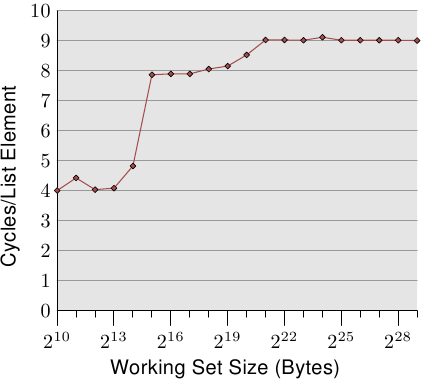
图3.11:几种尺寸的顺序读取
前两个测量值被噪声污染。测得的工作负载实在太小,无法滤除系统其余部分的影响。我们可以安全地假设所有值都处于4个循环级别。考虑到这一点,我们可以看到三个不同的级别:
- 工作集大小最大为2个14字节。
- 从2 15字节到2 20字节。
- 从2 21字节开始。
这些步骤很容易解释:处理器具有16kB L1d和1MB L2。我们看不到从一个级别到另一级别的过渡中的尖锐边缘,因为高速缓存也被系统的其他部分使用,因此高速缓存并非专门用于程序数据。特别地,L2缓存是统一缓存,也用于指令(注意:Intel使用包含性缓存)。
可能不太期望的是不同工作集大小的实际时间。L1d命中的时间是预期的:L1d命中后的加载时间在P4上约为4个周期。但是第二层访问呢?一旦L1d不足以保存数据,人们可能会期望每个元素要花费14个周期或更长时间,因为这是L2的访问时间。但是结果表明,仅需要大约9个周期。可以通过处理器中的高级逻辑来解释这种差异。预期使用连续的内存区域,处理器会预取下一条缓存行。这意味着当实际使用下一行时,它已经中途加载。因此,等待下一个缓存行加载所需的延迟比L2访问时间小得多。
一旦工作集大小超过L2大小,预取的效果就更加明显。在我们说主存储器访问需要200多个周期之前。只有通过有效的预取,处理器才可以将访问时间保持在9个周期之内。从200与9之间的差异中可以看出,这很好地实现了。
我们可以至少在间接预取的同时观察处理器。在图3.11中,我们看到了相同工作集大小的时间,但是这次我们看到了结构l的不同大小的图表 。这意味着列表中的元素较少但较大。不同的大小会导致(仍然连续)列表中n个元素之间的距离增加。在图形的四种情况下,距离分别为0、56、120和248个字节。
在底部,我们可以看到上图的线,但是这次它或多或少显示为一条平线。其他情况的时间简直糟透了。我们也可以在该图中看到三个不同的级别,并且可以看到工作集大小较小的测试中存在较大的错误(再次忽略它们)。只要只涉及L1d,这些线或多或少都相互匹配。无需预取,因此所有元素大小每次访问都只需达到L1d。
对于L2缓存命中,我们看到三个新行几乎完全匹配,但是它们处于较高级别(大约28个)。这是L2的访问时间级别。这意味着从L2到L1d的预取基本上是禁用的。即使NPAD = 7,我们也需要为循环的每次迭代添加一条新的缓存行;对于 NPAD = 0,相反,循环必须迭代八次才需要下一个缓存行。预取逻辑无法在每个周期加载新的缓存行。因此,我们看到在每次迭代中都有从L2加载的停顿。
一旦工作集大小超过L2容量,它将变得更加有趣。现在,所有四行的差异很大。不同的元素大小显然在性能差异中起很大作用。处理器应识别步幅的大小,而不要为NPAD提取不必要的缓存行= 15和31,因为元素大小小于预取窗口(请参见6.3.1节)。元素大小妨碍预取工作的原因是硬件预取的限制:它不能跨越页面边界。每次增加大小,我们都会将硬件调度程序的有效性降低50%。如果允许硬件预取器跨越页面边界并且下一页不驻留或有效,则OS必须参与定位页面。这意味着程序将遇到未启动的页面错误。这是完全不可接受的,因为处理器不知道页面是否存在或不存在。在后一种情况下,操作系统将不得不中止该过程。无论如何,对于NPAD= 7或更高版本,每个列表元素需要一个缓存行,而硬件预取器不能做很多事情。根本没有时间从内存中加载数据,因为处理器的全部工作都是读取一个字,然后加载下一个元素。
速度下降的另一个重要原因是TLB缓存未命中。这是一个高速缓存,其中存储了虚拟地址到物理地址的转换结果,如第4节中所述。TLB高速缓存非常小,因为它必须非常快。如果重复访问的页面多于TLB缓存具有的条目,则必须不断重复进行从虚拟地址到物理地址的转换。这是非常昂贵的操作。对于较大的元素,将在较少的元素上分摊TLB查找的成本。这意味着必须为每个列表元素计算的TLB条目总数较高。
要观察TLB的影响,我们可以运行其他测试。对于一种测量,我们像往常一样顺序排列元素。对于占一整个缓存行的元素,我们使用 NPAD = 7。对于第二个度量,我们将每个列表元素放在单独的页面上。每页的其余部分保持不变,我们不将其计入工作集大小的总数中。{是的,这有点不一致,因为在其他测试中,我们在元素大小中计算结构的未使用部分,并且可以定义NPAD,以便每个元素填充一页。在这种情况下,工作集的大小将有很大的不同。但是,这并不是该测试的重点,而且由于预取仍然无效,因此差异不大。}结果是,对于第一次测量,每个列表迭代都需要一个新的缓存行,并且对于每64个元素,都需要一个新页面。对于第二次测量,每次迭代都需要加载新页面上的新缓存行。
图3.12:TLB对顺序读取的影响
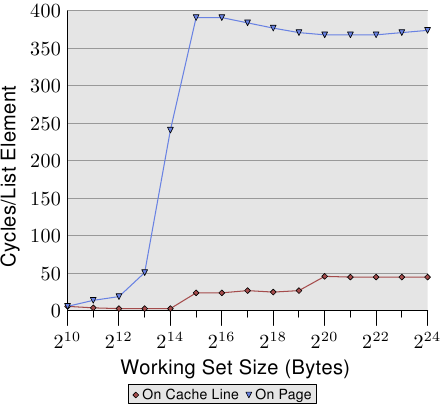
结果如图3.12所示。测量是在与图3.11相同的机器上进行的。由于可用RAM的限制,工作集大小必须限制为2 24字节,这需要1GB才能将对象放置在单独的页面上。下方的红色曲线恰好对应于图3.11中的 NPAD = 7曲线。我们看到了显示L1d和L2缓存大小的不同步骤。第二条曲线看起来截然不同。重要的功能是当工作台尺寸达到2 13时开始出现巨大的尖峰个字节。这是TLB缓存溢出时。使用64字节的元素大小,我们可以计算出TLB缓存具有64个条目。没有程序错误会影响成本,因为程序会锁定内存以防止其被换出。
可以看出,计算物理地址并将其存储在TLB中所需的周期数非常高。图3.12中的图形显示了极端情况,但现在应该清楚,对于较大的NPAD值,降低速度的一个重要因素是TLB缓存的效率降低。由于必须在可以读取L2或主存储器的高速缓存行之前计算物理地址,因此地址转换惩罚会增加存储器访问时间。这部分解释了为什么NPAD = 31时每个列表元素的总成本要比RAM的理论访问时间高。
图3.13:顺序读写NPAD = 1
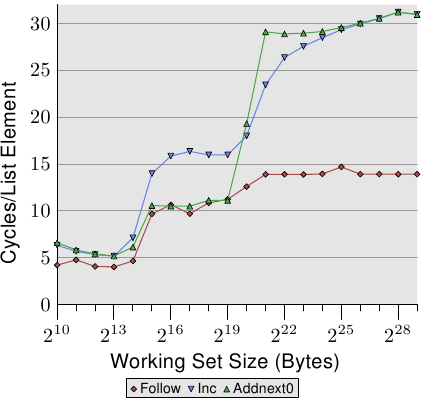
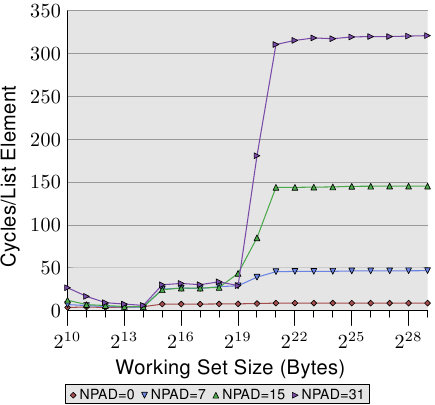
通过查看修改列表元素的测试运行的数据,我们可以瞥见预取实现的更多详细信息。图3.13显示了三行。元素宽度在所有情况下均为16个字节。第一行是现在熟悉的列表遍历,它是基准。第二行标记为“ Inc”,在继续进行下一个操作之前,仅增加当前元素的pad [0]成员。第三行标记为“ Addnext0”,将下一个元素的 pad [0]列表元素添加到当前列表元素的pad [0]成员中。
幼稚的假设是“ Addnext0”测试运行较慢,因为它需要做的工作更多。在前进到下一个列表元素之前,必须加载该元素中的值。这就是为什么令人惊讶的是,对于某些工作集大小,该测试实际上比“ Inc”测试运行得更快。对此的解释是,来自下一个列表元素的负载基本上是强制预取。只要程序前进到下一个列表元素,我们就可以确定该元素已经在L1d缓存中。结果,我们看到只要工作集大小适合L2缓存,“ Addnext0”的性能就和简单的“跟随”测试一样好。
不过,“ Addnext0”测试在L2中用完的速度比“ Inc”测试快。它需要从主存储器加载更多数据。这就是为什么“ Addnext0”测试在2个21字节的工作集大小下达到28个周期级别的原因。28个循环级别是“跟随”测试达到的14个循环级别的两倍。这也很容易解释。由于其他两个测试修改了内存,因此二级缓存逐出为新的缓存行腾出空间不能简单地丢弃数据。而是必须将其写入内存。这意味着FSB上的可用带宽减少了一半,因此将数据从主存储器传输到L2所需的时间加倍。
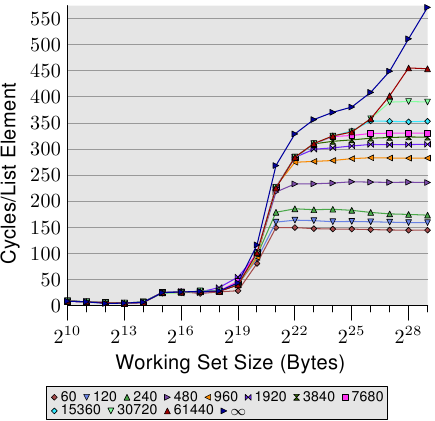
图3.14:更大的L2 / L3缓存的优势
顺序有效的缓存处理的最后一个方面是缓存的大小。这应该是显而易见的,但仍应指出。图3.14显示了具有128字节元素的增量基准测试的时序(在64位计算机上,NPAD = 15)。这次我们看到来自三台不同机器的测量结果。前两台机器是P4,最后一台是Core2处理器。前两个通过具有不同的缓存大小来区分自己。第一处理器具有32k L1d和1M L2。第二个具有16k L1d,512k L2和2M L3。Core2处理器具有32k L1d和4M L2。
图中有趣的部分不一定是Core2处理器相对于其他两个处理器的性能(尽管令人印象深刻)。这里的主要关注点是对于相应的最后一级缓存而言,工作集大小过大且主内存大量涉及的区域。
| 设定 尺寸 | 顺序的 | 随机 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| L2命中 | L2小姐 | #Iter | 丢失/击中率 | 每个迭代的L2访问 | L2命中 | L2小姐 | #Iter | 丢失/击中率 | 每个迭代的L2访问 | |
| 2 20 | 88,636 | 843 | 16,384 | 0.94% | 5.5 | 30,462 | 4721 | 1,024 | 13.42% | 34.4 |
| 2 21 | 88,105 | 1,584 | 8,192 | 1.77% | 10.9 | 21,817 | 15,151 | 512 | 40.98% | 72.2 |
| 2 22 | 88,106 | 1,600 | 4,096 | 1.78% | 21.9 | 22,258 | 22,285 | 256 | 50.03% | 174.0 |
| 2 23 | 88,104 | 1,614 | 2,048 | 1.80% | 43.8 | 27,521 | 26,274 | 128 | 48.84% | 420.3 |
| 2 24 | 88,114 | 1,655 | 1,024 | 1.84% | 87.7 | 33,166 | 29,115 | 64 | 46.75% | 973.1 |
| 2 25 | 88,112 | 1,730 | 512 | 1.93% | 175.5 | 39,858 | 32,360 | 32 | 44.81% | 2,256.8 |
| 2 26 | 88,112 | 1,906 | 256 | 2.12% | 351.6 | 48,539 | 38,151 | 16 | 44.01% | 5,418.1 |
| 2 27 | 88,114 | 2,244 | 128 | 2.48% | 705.9 | 62,423 | 52,049 | 8 | 45.47% | 14,309.0 |
| 2 28 | 88,120 | 2,939 | 64 | 3.23% | 1,422.8 | 81,906 | 87,167 | 4 | 51.56% | 42,268.3 |
| 2 29 | 88,137 | 4,318 | 32 | 4.67% | 2,889.2 | 119,079 | 163,398 | 2 | 57.84% | 141,238.5 |
表3.2:顺序游走和随机游走的L2命中和未命中,NPAD = 0
不出所料,最后一级缓存越大,曲线停留在与L2访问成本相对应的较低级别上的时间就越长。注意的重要部分是它提供的性能优势。第二个处理器(稍早一些)可以在2个20字节的工作集上执行工作,是第一个处理器的两倍。全部归功于末级缓存大小的增加。带有4M L2的Core2处理器性能更好。
对于随机的工作负载,这可能并不意味着那么多。但是,如果可以将工作负载调整为最后一级缓存的大小,则可以显着提高程序性能。这就是为什么有时值得花额外的钱购买具有更大缓存的处理器。
单线程随机访问测量
我们已经看到,通过将高速缓存行预取到L2和L1d中,处理器能够隐藏大多数主存储器甚至L2访问延迟。但是,只有在可预测的内存访问时,此方法才能很好地工作。
图3.15:顺序vs随机读取,NPAD = 0
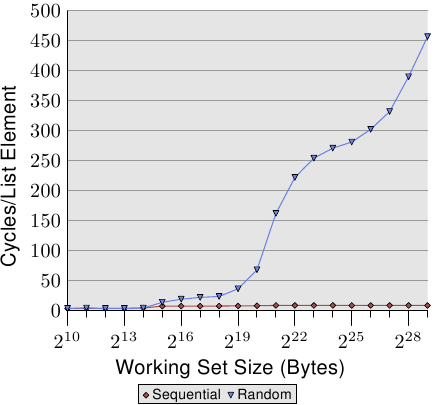
如果访问是不可预测的或随机的,则情况会大不相同。图3.15比较了顺序访问的每个列表元素的时间(与图3.10相同)与列表元素在工作集中随机分布的时间。顺序由随机确定的链表确定。处理器无法可靠地预取数据。如果彼此之间不久使用的元素在内存中也彼此靠近,这只能是偶然的。
图3.15有两点需要注意。首先,大量是增加工作集大小所需的周期。这台机器可以在200-300个周期内访问主存储器,但在这里我们可以达到450个周期甚至更多。我们之前已经看到过这种现象(比较图3.11)。自动预取实际上在这里不利。
第二个有趣的点是,曲线在各个平稳阶段并没有变平,就像在顺序访问情况下一样。曲线不断上升。为了解释这一点,我们可以针对各种工作集大小来测量程序的L2访问。结果如图3.16和表3.2所示。
该图显示,当工作集大小大于L2大小时,缓存未命中率(L2未命中/ L2访问)开始增加。该曲线与图3.15中的曲线具有相似的形式:它迅速上升,略微下降并再次开始上升。与每个列表元素图的周期有很强的相关性。L2丢失率将一直增长,直到最终达到接近100%的水平。给定足够大的工作集(和RAM),可以任意降低任何随机选择的高速缓存行位于L2或正在加载的可能性。
仅增加的高速缓存未命中率就可以解释一些成本。但是还有另一个因素。查看表3.2,我们可以在L2 /#Iter列中看到该程序每次迭代使用的L2总数正在增长。每个工作集的大小是以前的两倍。因此,如果不进行缓存,我们期望主存储器访问量增加一倍。使用缓存和(几乎)完美的可预测性,我们看到数据中的L2使用量适度增加,用于顺序访问。该增加是由于工作集大小的增加而已。
图3.16:L2d丢失率
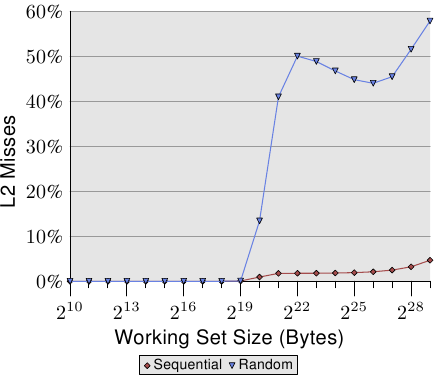
图3.17:页面明智随机化,NPAD = 7
对于随机访问,每增加一倍的工作集大小,每个元素的时间就会增加100%以上。这意味着每个列表元素的平均访问时间会增加,因为工作集的大小只会增加一倍。其背后的原因是TLB未命中率上升。在图3.17中,我们看到了NPAD随机访问的成本 = 7。仅这次,随机化才被修改。在正常情况下,将整个随机列表作为一个块(用标记∞表示),其他11条曲线则显示以较小块进行的随机化。对于标记为“ 60”的曲线,每组60页(245.760字节)分别被随机分配。这意味着在遍历下一个块中的元素之前,将遍历该块中的所有列表元素。这具有限制在任何一次使用的TLB条目数量的效果。
NPAD = 7 的元素大小为64字节,与缓存行大小相对应。由于列表元素的随机顺序,硬件预取器不太可能发挥作用,最肯定的是不会影响少数元素。这意味着L2高速缓存未命中率与一个块中整个列表的随机化没有显着差异。随着块大小的增加,测试的性能渐近地接近一块随机化的曲线。这意味着后一个测试用例的性能受到TLB遗漏的影响很大。如果可以降低TLB的未命中率,则性能将显着提高(在一项测试中,我们稍后将看到高达38%的信息)。
3.3.3写行为
在开始查看当多个执行上下文(线程或进程)使用同一内存时的缓存行为之前,我们必须探索缓存实现的详细信息。高速缓存应该是一致的,并且这种一致性对于用户级代码应该是完全透明的。内核代码是另一回事。有时需要刷新缓存。
这特别意味着,如果修改了缓存行,则在该时间点之后系统的结果与根本没有缓存并且主存储器位置本身已被修改的结果相同。这可以通过两种方式或策略来实现:
- 直写式缓存实现;
- 回写缓存实现。
直写式高速缓存是实现高速缓存一致性的最简单方法。如果写入了高速缓存行,则处理器也会立即将高速缓存行写入主内存。这样可以确保主存储器和缓存始终保持同步。只要替换缓存行,就可以简单地丢弃缓存内容。此缓存策略很简单,但不是很快。例如,一遍又一遍地修改局部变量的程序将在FSB上创建大量流量,即使该数据可能未在其他任何地方使用并且寿命很短。
回写策略更为复杂。在这里,处理器不会立即将修改后的高速缓存行写回到主存储器。而是,将缓存行仅标记为脏。当将来某个时候从缓存中删除缓存行时,脏位将指示处理器在那时写回数据,而不仅仅是丢弃内容。
回写式高速缓存有机会显着提高性能,这就是为什么具有良好处理器的系统中的大多数内存都以这种方式进行高速缓存的原因。处理器甚至可以利用FSB上的可用容量来存储必须排空的高速缓存行的内容。这样可以清除脏位,并且当需要缓存中的空间时,处理器可以删除缓存行。
但是回写实现存在一个重大问题。当有多个处理器(或核心或超线程)可用并访问相同的内存时,仍必须确保两个处理器始终都能看到相同的内存内容。如果一个处理器上的高速缓存行脏了(即尚未被写回),而第二个处理器试图读取相同的内存位置,则读取操作不能仅转到主内存。而是需要第一个处理器的缓存行的内容。在下一节中,我们将了解当前的实现方式。
在此之前,还有两个要提及的缓存策略:
- 写合并 和
- 无法缓存。
这两种策略都用于不由实际RAM支持的地址空间的特殊区域。内核为地址范围设置了这些策略(在x86处理器上使用内存类型范围寄存器MTRR),其余的自动发生。MTRR也可用于在直写和回写策略之间进行选择。
写合并是有限的缓存优化,更常用于图形卡等设备上的RAM。由于到设备的传输成本比本地RAM访问高得多,因此避免进行过多的传输就显得尤为重要。如果下一个操作修改了下一个字,那么仅因为写入了该行中的一个字而传输整个缓存行是浪费的。可以轻易想象这是一种普遍现象,在大多数情况下,屏幕上水平相邻像素的内存也是相邻的。顾名思义,写合并会在写出缓存行之前合并多个写访问。在理想情况下,整个缓存行逐字修改,只有在写入最后一个字之后,才将缓存行写入设备。这可以显着加快对设备上RAM的访问。
最后是不可缓存的内存。这通常意味着内存位置根本不受RAM支持。它可能是一个特殊的地址,该地址经过硬编码以在CPU外部具有某些功能。对于商用硬件,内存映射的地址范围通常是这种情况,它转换为对连接到总线(PCIe等)的卡和设备的访问。在嵌入式板上有时会找到这样的存储地址,该地址可用于打开和关闭LED。缓存这样的地址显然不是一个好主意。在这种情况下,LED用于调试或状态报告,因此希望尽快看到。PCIe卡上的内存可以在没有CPU交互的情况下进行更改,因此不应缓存此内存。
3.3.4多处理器支持
在上一节中,我们已经指出了多个处理器发挥作用时遇到的问题。对于那些不共享的缓存级别(至少是L1d),即使是多核处理器也存在问题。
提供从一个处理器到另一处理器的高速缓存的直接访问是完全不切实际的。刚开始时连接速度不够快。实际的选择是在需要时将缓存内容转移到另一个处理器。请注意,这也适用于不在同一处理器上共享的缓存。
现在的问题是,何时必须进行此高速缓存行传输?这个问题很容易回答:当一个处理器需要高速缓存行时,该高速缓存行在另一处理器的高速缓存中脏了以进行读取或写入。但是,处理器如何确定另一个处理器的缓存中的缓存行是否脏了?假定仅仅是因为高速缓存行由另一个处理器加载将是次优的(最好)。通常,大多数内存访问是读取访问,并且生成的高速缓存行不会变脏。高速缓存行上的处理器操作很频繁(当然,为什么还要写这篇论文?),这意味着在每次写访问之后广播有关已更改的高速缓存行的信息是不切实际的。
多年来开发的是MESI缓存一致性协议(已修改,互斥,共享,无效)。该协议以使用MESI协议时高速缓存行可以处于的四个状态命名:
- 已修改:本地处理器已修改高速缓存行。这也意味着它是任何缓存中的唯一副本。
- Exclusive(独占):缓存行未修改,但已知不会加载到任何其他处理器的缓存中。
- 共享:缓存行未修改,可能存在于另一个处理器的缓存中。
- 无效:缓存行无效,即未使用。
多年以来,该协议是从较简单的版本发展而来的,这些版本不那么复杂但也不太有效。通过这四个状态,可以有效地实现回写式高速缓存,同时还支持在不同处理器上并发使用只读数据。
图3.18:MESI协议转换
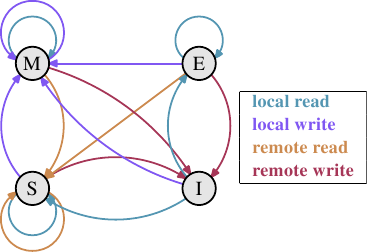
通过处理器侦听或监听其他处理器的工作,无需过多的工作即可完成状态更改。处理器执行的某些操作在外部引脚上宣告,从而使处理器的缓存处理对外部可见。所讨论的高速缓存行的地址在地址总线上可见。在以下状态及其转换的描述中(如图3.18所示),我们将指出何时涉及总线。
最初,所有缓存行都是空的,因此也是无效的。如果将数据加载到缓存中以进行写入,则缓存将更改为“已修改”。是否加载了数据以读取新状态取决于另一个处理器是否也加载了缓存行。如果是这种情况,则新状态为共享,否则为独占。
如果从本地处理器读取或写入了一条修改的高速缓存行,则指令可以使用当前的高速缓存内容,并且状态不会更改。如果第二个处理器要从缓存行中读取,则第一个处理器必须将其缓存的内容发送给第二个处理器,然后它才能将状态更改为“共享”。发送到第二处理器的数据也由将内容存储在存储器中的存储器控制器接收和处理。如果没有发生,则无法将缓存行标记为“共享”。如果第二处理器要写入高速缓存行,则第一处理器发送高速缓存行内容,并在本地将高速缓存行标记为无效。这是臭名昭著的“所有权请求”(RFO)操作。在上一级缓存中执行此操作,就像I→M转换相对昂贵一样。对于直写式缓存,我们还必须增加将新的缓存行内容写入下一个更高级别的缓存或主内存所需的时间,从而进一步增加了成本。
如果高速缓存行处于“共享”状态,并且本地处理器从中读取数据,则无需更改状态,并且可以从高速缓存中满足读取请求。如果将缓存行本地写入缓存行,也可以使用,但状态变为已修改。它还要求将其他处理器中缓存行的所有其他可能副本标记为无效。因此,必须通过RFO消息将写操作通知其他处理器。如果第二个处理器请求读取缓存行,则无需执行任何操作。主存储器包含当前数据,并且本地状态已共享。如果第二个处理器想要写入高速缓存行(RFO),则将高速缓存行简单标记为无效。无需总线操作。
独占状态几乎等于一个关键的区别共享状态:本地的写操作也没有必须要在总线上公布。已知本地缓存副本是唯一的副本。这可能是一个巨大的优势,因此处理器将尝试在“独占”状态而不是“共享”状态下保持尽可能多的缓存行。如果那一刻信息不可用,则后者是备用。还可以完全排除独占状态,而不会引起功能问题。由于E→M转换要比S→M转换快得多,因此只有性能会受到影响。
根据状态转换的描述,应该清楚多处理器操作所特有的成本在哪里。是的,填充缓存仍然很昂贵,但现在我们还必须注意RFO消息。每当必须发送这样的消息时,事情就会变慢。
在两种情况下,需要RFO消息:
- 线程从一个处理器迁移到另一个处理器,所有缓存行必须一次移到新处理器上。
- 在两个不同的处理器中确实需要高速缓存行。{在较小的级别上,同一处理器上的两个内核也是如此。成本略低。RFO消息可能会发送多次。}
在多线程或多进程程序中,总是需要同步。此同步是使用内存实现的。因此,存在一些有效的RFO消息。它们仍然必须保持尽可能少的频率。不过,还有其他来源的RFO消息。在第6节中,我们将解释这些情况。高速缓存一致性协议消息必须在系统的处理器之间分配。直到很明显,系统中的所有处理器都有机会回复该消息,MESI转换才能发生。这意味着答复可能花费的最长时间决定了一致性协议的速度。{这就是为什么我们今天看到例如带有三个插槽的AMD Opteron系统的原因。考虑到每个处理器只有三个超链接,而南桥连接则需要一个超链接,因此每个处理器都相距一跳。}总线上可能会发生冲突,在NUMA系统中延迟可能很高,当然,庞大的通信量也会减慢速度。所有充分的理由集中于避免不必要的流量。
还有一个以上的问题,涉及一个以上的处理器在运行。影响是高度特定于机器的,但原则上始终存在问题:FSB是共享资源。在大多数机器中,所有处理器都通过一条总线连接到内存控制器(请参见图2.1)。如果单个处理器可以使总线饱和(通常是这种情况),则共享同一总线的两个或四个处理器将限制每个处理器可用的带宽。
即使每个处理器都有自己的总线(如图2.2所示),也仍然有通向内存模块的总线。通常,这是一条总线,但是,即使在图2.2中的扩展模型中,对同一内存模块的并发访问也会限制带宽。
对于AMD模型,每个处理器可以具有本地内存也是如此。是的,所有处理器都可以快速并发访问其本地内存。但是多线程和多进程程序(至少有时会不时)必须访问相同的内存区域以进行同步。
并发受到可用于实现必要同步的有限带宽的严重限制。需要仔细设计程序,以最大程度地减少从不同处理器和内核对相同内存位置的访问。以下测量将显示此以及其他与多线程代码有关的缓存效果。
多线程测量
为了确保理解在不同处理器上同时使用相同的缓存行而引入的问题的严重性,我们将在此处查看以前使用的同一程序的更多性能图。但是,这一次,同时运行多个线程。测量的是所有线程中最快的运行时间。这意味着完成所有线程后完成运行的时间甚至更长。使用的机器有四个处理器;测试最多使用四个线程。所有处理器共用一条总线到内存控制器,而只有一条总线到内存模块。
图3.19:顺序读取访问,多线程
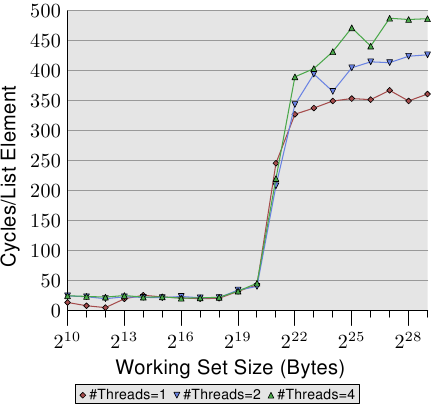
图3.19显示了128字节条目的顺序只读访问的性能(在64位计算机上,NPAD = 15)。对于一个线程的曲线,我们可以预期得到类似于图3.11的曲线。测量是针对另一台机器的,因此实际数字有所不同。
该图中的重要部分当然是运行多个线程时的行为。请注意,遍历链表时不会修改内存,也不会尝试使线程保持同步。即使不需要RFO消息并且可以共享所有缓存行,我们发现使用两个线程时最快的线程的性能下降最多18%,而使用四个线程时的性能下降高达34%。由于无需在处理器之间传输高速缓存行,因此,这种速度下降仅是由两个瓶颈之一或两者引起的:从处理器到内存控制器的共享总线,以及从内存控制器到内存模块的总线。一旦工作集大小大于此计算机中的L3缓存,所有三个线程将预取新的列表元素。
当我们修改内存时,事情变得更加难看。图3.20显示了顺序增量测试的结果。
图3.20:顺序递增,多线程
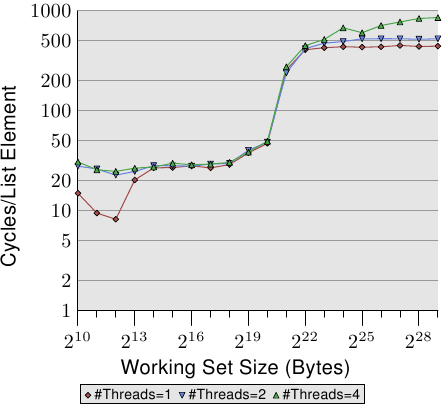
该图的Y轴使用对数刻度。因此,不要被表面上很小的差异所欺骗。运行两个线程仍然有18%的罚款,而运行四个线程现在却有93%的惊人罚款。这意味着当使用四个线程时,预取流量和回写流量会使总线大大饱和。
我们使用对数刻度显示L1d范围的结果。可以看到的是,一旦运行了多个线程,L1d基本上就失效了。仅当L1d不足以容纳工作集时,单线程访问时间才超过20个周期。当多个线程正在运行时,即使使用最小的工作集大小,这些访问时间也会立即达到。
问题的一方面未在此处显示。用这个特定的测试程序很难衡量。即使测试修改了内存,因此我们必须期待RFO消息,但是当使用多个线程时,我们不会看到L2范围的更高成本。该程序将不得不使用大量的内存,并且所有线程必须并行访问同一内存。如果没有大量的同步,那么这将很难实现,而这将占据执行时间。
图3.21:随机Addnextlast,多线程

最后,在图3.21中,我们获得了具有随机访问内存的Addnextlast测试的编号。提供此数字主要是为了显示惊人的数字。在极端情况下,现在需要大约1,500个周期来处理单个列表元素。使用更多线程甚至更成问题。我们可以总结一个表中多线程使用的效率。
#线程 顺序读 赛克公司 兰德添加 2 1.69 1.69 1.54 4 2.98 2.07 1.65 表3.3:多线程效率
该表在图3.21的三个图中显示了最大工作集大小的多线程运行的效率。该数字表示通过使用两个或四个线程,对于最大的工作集大小,测试程序可能会以最快的速度进行加速。对于两个线程,理论上的加速极限为2,对于四个线程,其理论极限为4。两个线程的数量还不错。但是对于四个线程,最后一次测试的数字表明,超过两个线程几乎不值得。额外的好处是微不足道的。如果我们稍微不同地表示图3.21中的数据,就可以更容易地看到这一点。
图3.22:通过并行加速
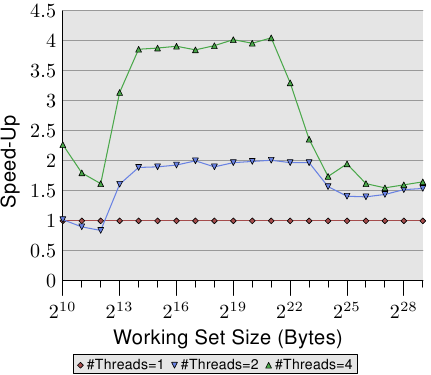
图3.22中的曲线显示了加速因子,即与单线程执行的代码相比的相对性能。我们必须忽略最小的尺寸,测量不够准确。对于L2和L3缓存的范围,我们可以看到我们确实实现了几乎线性的加速。我们几乎分别达到2和4的系数。但是,一旦L3缓存不足以容纳工作集,数字就会崩溃。它们崩溃到两个线程和四个线程的加速相同的程度(请参阅表3.3的第四列)。这就是为什么几乎找不到具有四个以上都使用同一个内存控制器的CPU插槽的主板的原因之一。具有更多处理器的机器必须以不同的方式构建(请参阅第5节)。
这些数字不是通用的。在某些情况下,即使适合最后一级缓存的工作集也不允许线性加速。实际上,这是规范,因为线程通常不像该测试程序中那样解耦。另一方面,可以使用大型工作集,并且仍然可以利用两个以上的线程。但是,这样做需要思考。我们将在第6节中讨论一些方法。
特殊情况:超线程
超线程(有时称为对称多线程,SMT)由CPU实现,是一种特殊情况,因为各个线程不能真正同时运行。它们都共享几乎所有的处理资源(寄存器集除外)。各个内核和CPU仍可并行工作,但是每个内核上实现的线程都受到此限制的限制。从理论上讲,每个内核可以有很多线程,但是到目前为止,英特尔的CPU最多每个内核只有两个线程。CPU负责线程的时间复用。但是,仅此一点并没有多大意义。真正的优势在于,当当前运行的超线程延迟时,CPU可以调度另一个超线程。在大多数情况下,这是由内存访问引起的延迟。
如果两个线程在一个超线程内核上运行,则当两个线程的组合运行时间低于单线程代码的运行时间时,该程序仅比单线程代码更有效 。通过重叠通常顺序发生的不同内存访问的等待时间,可以做到这一点。一个简单的计算显示了对高速缓存命中率的最低要求,以达到一定的速度。
程序的执行时间可以通过仅具有一级缓存的简单模型来估算,如下所示(请参见[htimpact]):
T exe = N [(1-F mem)T proc + F mem(G命中T缓存+(1-G命中)T miss)]
变量的含义如下:
ñ = 指令数。 ˚F MEM = 访问内存的N的分数。 G打 = 命中缓存的负载的分数。 Ť PROC = 每条指令的周期数。 T缓存 = 缓存命中的周期数。 Ť小姐 = 高速缓存未命中的周期数。 Ť EXE = 程序的执行时间。
为了使使用两个线程有意义,两个线程中每个线程的执行时间必须最多为单线程代码的一半。任一侧的唯一变量是高速缓存命中数。如果我们求解不使线程执行速度降低50%或更多所需的最小高速缓存命中率的等式,则会得到图3.23所示的图。
图3.23:加速时的最小高速缓存命中率
X轴表示单线程代码的缓存命中率G hit。Y轴显示了多线程代码所需的高速缓存命中率。该值永远不能高于单线程命中率,因为否则,单线程代码也将使用该改进的代码。对于低于55%的单线程命中率,程序在任何情况下都可以受益于使用线程。由于高速缓存未命中,CPU或多或少足够闲置,无法运行第二个超线程。
绿色区域是目标。如果线程的运行速度小于50%,并且每个线程的工作量减半,则合并的运行时可能少于单线程运行时。对于此处的建模系统(使用具有超线程的P4的数字),对于单线程代码,命中率为60%的程序对于双线程程序,命中率为至少10%。这通常是可行的。但是,如果单线程代码的命中率达到95%,那么多线程代码的命中率至少应达到80%。那更难。尤其是,这是超线程的问题,因为现在每个超线程可用的有效缓存大小(此处为L1d,实际上也为L2等等)减少了一半。两个超线程都使用相同的缓存来加载其数据。
因此,超线程仅在有限的情况下才有用。单线程代码的高速缓存命中率必须足够低,以使给定上述公式并减小高速缓存大小,新的命中率仍能达到目标。然后只有这样,使用超线程才有意义。在实践中,结果是否更快取决于处理器是否足以将一个线程中的等待时间与其他线程中的执行时间重叠。必须将代码并行化的开销添加到新的总运行时中,而这种额外的成本通常不能忽略。
在6.3.4节中,我们将看到一种技术,其中线程紧密协作,而通过公共缓存的紧密耦合实际上是一个优势。如果只有程序员愿意花时间和精力来扩展他们的代码,则该技术可以适用于许多情况。
应该清楚的是,如果两个超线程执行完全不同的代码(即,操作系统将两个线程视为单独的处理器来执行单独的进程),则缓存大小实际上减少了一半,这意味着缓存显着增加错过。除非缓存足够大,否则此类OS调度实践会令人怀疑。除非计算机的工作负载由通过其设计确实可以从超线程中受益的进程组成,否则最好关闭计算机BIOS中的超线程。{保持启用超线程的另一个原因是调试。SMT擅长在并行代码中发现一些问题。}
3.3.5其他详细信息
到目前为止,我们讨论的地址由三部分组成,即标签,设置索引和高速缓存行偏移量。但是实际使用什么地址?今天,所有相关的处理器都为进程提供虚拟地址空间,这意味着有两种不同的地址:虚拟和物理。
虚拟地址的问题在于它们不是唯一的。随着时间的推移,虚拟地址可以引用不同的物理内存地址。不同过程中的同一地址也可能是指不同的物理地址。因此,使用物理内存地址总是更好,对吧?
这里的问题是指令使用虚拟地址,并且这些虚拟地址必须在内存管理单元(MMU)的帮助下转换为物理地址。这是不平凡的操作。在执行指令的管道中,物理地址可能仅在以后的阶段可用。这意味着缓存逻辑必须非常快速地确定是否缓存了内存位置。如果可以使用虚拟地址,则可以在管道中更早地进行高速缓存查找,并且在高速缓存命中的情况下,可以使内存内容可用。结果是,管道可以隐藏更多的内存访问成本。
处理器设计者当前正在将虚拟地址标记用于第一级缓存。这些高速缓存很小,可以轻松清除。如果进程的页表树发生更改,则至少需要部分清除缓存。如果处理器具有指定已更改的虚拟地址范围的指令,则有可能避免完全刷新。鉴于L1i和L1d缓存的低延迟(〜3个周期),几乎必须使用虚拟地址。
对于较大的高速缓存,包括L2,L3,...,高速缓存需要物理地址标记。这些高速缓存具有更高的延迟,并且虚拟→物理地址转换可以及时完成。由于这些高速缓存较大(即,在清除高速缓存时会丢失大量信息),并且由于主内存访问延迟而重新填充高速缓存需要很长时间,因此刷新它们通常会很昂贵。
通常,没有必要知道这些缓存中地址处理的详细信息。它们无法更改,影响性能的所有因素通常都是应避免的或与高成本相关的事情。高速缓存容量的溢出很不好,如果大多数使用的高速缓存行属于同一组,则所有高速缓存都会尽早出现问题。使用虚拟寻址的缓存可以避免后者,但是对于用户级进程而言,避免使用物理地址寻址的缓存是不可能的。可能要记住的唯一细节是,如果可能的话,不要在同一过程中将同一物理内存位置映射到两个或多个虚拟地址。
缓存的另一个细节对程序员而言并不有趣,那就是缓存替换策略。大多数高速缓存会最先退出最近最少使用(LRU)元素。这始终是一个很好的默认策略。随着更大的关联性(由于增加了更多的核心,关联性的确在未来几年中可能会进一步增长),维护LRU列表变得越来越昂贵,我们可能会看到采用了不同的策略。
至于缓存的替换,程序员没有什么可以做的。如果高速缓存正在使用物理地址标签,则无法找出虚拟地址如何与高速缓存集相关联。可能所有逻辑页中的缓存行都映射到相同的缓存集,而许多缓存未使用。如果有的话,操作系统的工作就是安排这种情况不经常发生。
随着虚拟化技术的出现,事情变得更加复杂。现在,甚至连操作系统都无法控制物理内存的分配。虚拟机监视器(VMM,又名虚拟机管理程序)负责物理内存分配。
程序员可以做的最好的事情是:a)完全使用逻辑存储器页面,b)使用尽可能有意义的页面大小来尽可能地分散物理地址。页面大小也有其他好处,但这是另一个主题(请参见第4节)。
3.4指令缓存
不仅缓存了处理器使用的数据,还缓存了数据。由处理器执行的指令也被缓存。但是,此缓存比数据缓存的问题要少得多。有以下几个原因:
- 执行的代码量取决于所需代码的大小。通常,代码的大小取决于问题的复杂性。问题的复杂性是固定的。
- 尽管程序的数据处理是由程序员设计的,但程序的指令通常是由编译器生成的。编译器作者了解良好代码生成的规则。
- 程序流比数据访问模式更可预测。当今的CPU非常擅长检测模式。这有助于预取。
- 代码始终具有相当好的空间和时间局部性。
程序员应遵循一些规则,但是这些规则主要由有关如何使用工具的规则组成。我们将在第6节中讨论它们。在这里,我们仅讨论指令高速缓存的技术细节。
自从CPU的核心时钟急剧增加,并且高速缓存(甚至是一级高速缓存)和核心之间的速度差异不断增大以来,CPU一直在流水线化。这意味着一条指令的执行分阶段进行。首先解码一条指令,然后准备参数,最后执行它。这样的流水线可能会很长(对于Intel的Netburst架构,> 20个阶段)。较长的流水线意味着,如果流水线停滞(即,流经该流水线的指令流被中断),则需要一段时间才能恢复速度。例如,如果无法正确预测下一条指令的位置或加载下一条指令所需的时间太长(例如,当必须从内存中读取时),则会发生管道停顿。
结果,CPU设计人员在分支预测上花费了大量时间和芯片资源,从而尽可能少地发生管道停顿。
在CISC处理器上,解码阶段也可能需要一些时间。x86和x86-64处理器尤其受影响。因此,近年来,这些处理器不在L1i中缓存指令的原始字节序列,而是缓存已解码的指令。在这种情况下,L1i被称为“跟踪缓存”。跟踪高速缓存允许处理器在发生高速缓存命中的情况下跳过流水线的第一步,如果流水线停滞,则特别好。
如前所述,从L2开始的缓存是包含代码和数据的统一缓存。显然,这里的代码以字节序列形式缓存,并且不被解码。
为了获得最佳性能,只有少数与指令缓存相关的规则:
- 生成尽可能小的代码。当出于使用管道的原因而进行软件流水处理需要创建更多代码或使用小代码的开销过高时,会有例外。
- 只要有可能,请帮助处理器做出良好的预取决策。这可以通过代码布局或显式预取来完成。
这些规则通常由编译器的代码生成来实施。程序员可以做一些事情,我们将在第6节中讨论它们。
3.4.1自我修改代码
在早期的计算机时代,记忆是一种溢价。人们竭尽全力减小程序的大小,以便为程序数据腾出更多空间。经常部署的一个技巧是随着时间的推移更改程序本身。有时仍会发现这种自修改代码(SMC),主要是出于性能方面的原因或出于安全漏洞的考虑。
通常应避免使用SMC。尽管通常可以正确执行它,但在某些情况下并不能正确执行,如果执行不正确,则会造成性能问题。显然,更改后的代码无法保存在包含已解码指令的跟踪缓存中。但是,即使由于根本未执行代码(或一段时间未执行)而未使用跟踪缓存,处理器也可能会出现问题。如果即将到来的指令已经进入管道而被更改,则处理器必须放弃很多工作并重新开始。甚至在某些情况下,处理器的大多数状态都必须放弃。
最后,由于处理器(出于简单性的原因,并且因为在所有情况下99.9999999%的情况都是如此)假定代码页是不可变的,因此L1i实现不使用MESI协议,而是使用简化的SI协议。这意味着,如果检测到修改,则必须做出很多悲观的假设。
强烈建议尽可能避免使用SMC。内存不再是一种稀缺资源。最好编写单独的函数,而不是根据特定需要修改一个函数。也许有一天可以将SMC支持设为可选,并且我们可以检测到试图以这种方式修改代码的漏洞利用代码。如果绝对必须使用SMC,则写操作应绕过缓存,以免对L1i中所需的L1d中的数据造成问题。有关这些说明的更多信息,请参见第6.1节。
通常在Linux上,很容易识别包含SMC的程序。使用常规工具链构建时,所有程序代码均具有写保护。程序员必须在链接时执行大量的魔术操作,以创建代码页可写的可执行文件。发生这种情况时,现代的Intel x86和x86-64处理器具有专用的性能计数器,该计数器可对自修改代码的使用进行计数。在这些计数器的帮助下,即使程序由于宽松的权限而成功执行,也很容易用SMC识别程序。
3.5缓存缺失因素
我们已经看到,当内存访问错过高速缓存时,成本将飞涨。有时这是无法避免的,重要的是要了解实际成本以及可以采取哪些措施来缓解该问题。
3.5.1缓存和内存带宽
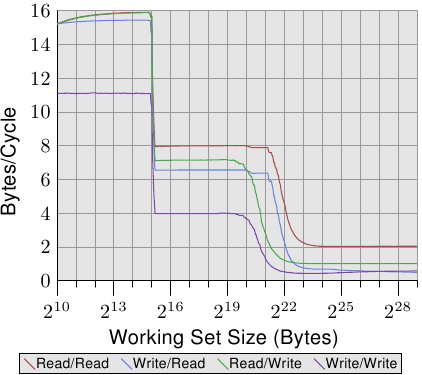
为了更好地了解处理器的功能,我们测量了最佳情况下可用的带宽。由于不同的处理器版本差异很大,因此这种测量特别有趣。这就是为什么此部分填充了几台不同机器的数据的原因。衡量性能的程序使用x86和x86-64处理器的SSE指令一次加载或存储16个字节。就像在其他测试中一样,工作集从1kB增加到512MB,并测量了每个周期可以加载或存储多少字节。
图3.24:Pentium 4带宽
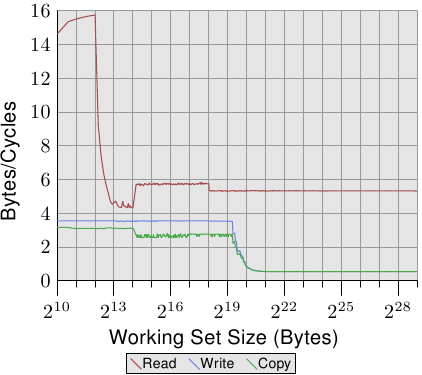
图3.24显示了64位Intel Netburst处理器的性能。对于适合L1d的工作集大小,处理器能够每个周期读取完整的16个字节,即,每个周期执行一条加载指令(movaps指令一次移动16个字节)。该测试对读取的数据没有任何作用,我们仅测试读取的指令本身。一旦L1d不再足够,性能就会急剧下降到每个周期少于6个字节。步骤2 18字节是由于DTLB缓存的耗尽而导致的,这意味着每个新页面都要进行额外的工作。由于读取是顺序的,因此预取可以完美地预测访问,并且对于所有大小的工作集,FSB可以以每个周期大约5.3字节的速度流传输内存内容。不过,预取的数据不会传播到L1d中。这些当然是在实际程序中永远无法实现的数字。将它们视为实际限制。
比读取性能更惊人的是写入和复制性能。即使对于较小的工作集大小,写入性能也永远不会超过每个周期4个字节。这表明,在这些Netburst处理器中,英特尔选择对L1d使用直写模式,而性能显然受到L2速度的限制。这也意味着从一个内存区域复制到第二个非重叠内存区域的复制测试的性能不会显着变差。必要的读取操作非常快,并且可能与写入操作部分重叠。一旦L2缓存不再足够,写入和复制测量的最值得注意的细节就是性能低下。性能下降到每个周期0.5个字节!这意味着写操作要比读操作慢十倍。这意味着优化这些操作对于程序的性能甚至更为重要。
在图3.25中,我们看到了在同一处理器上运行两个线程的结果,一个线程固定在处理器的两个超线程中的每个线程上。
图3.25:具有2个超线程的P4带宽
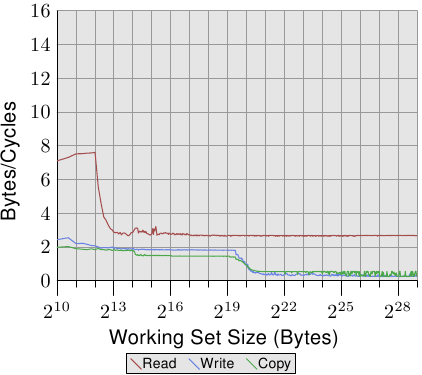
该图以与前一个相同的比例显示,以说明差异,并且曲线仅由于测量两个并发线程的问题而有些抖动。结果是预期的。由于超线程共享除寄存器之外的所有资源,因此每个线程仅具有可用缓存和带宽的一半。这意味着即使每个线程都需要等待很多时间并且可以在执行时间上授予另一个线程,但这没有任何区别,因为另一个线程也必须等待内存。这确实显示了超线程的最坏使用。
图3.26:核心2带宽
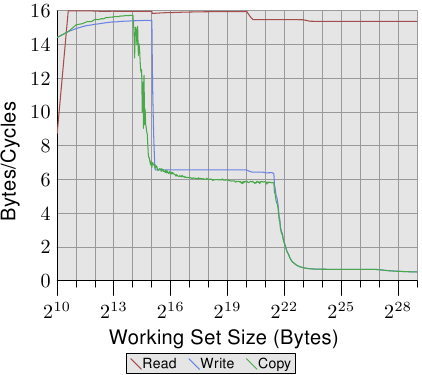
与图3.24和3.25相比,图3.26和3.27的结果对于英特尔酷睿2处理器而言有很大不同。这是一个共享L2的双核处理器,它是P4机器上L2的四倍。但是,这仅解释了写入和复制性能的延迟下降。
有更大的差异。在整个工作集范围内的读取性能在每个周期的最佳16字节左右徘徊。2 20字节后读取性能的下降再次是由于工作集对于DTLB而言太大。实现这些高数量意味着处理器不仅能够预取数据并及时传输数据。这也意味着数据已预取到L1d中。
写入和复制性能也大不相同。处理器没有直写策略;写入的数据存储在L1d中,仅在必要时驱逐。这样可以使写入速度接近每个周期的最佳16字节。一旦L1d不再足够,性能就会大大下降。与Netburst处理器一样,写入性能明显较低。由于具有较高的读取性能,因此此处的差异更大。实际上,即使L2不再足够,速度差也会增加20倍!这并不意味着Core 2处理器性能不佳。相反,它们的性能始终优于Netburst核心。
图3.27:具有2个线程的Core 2带宽
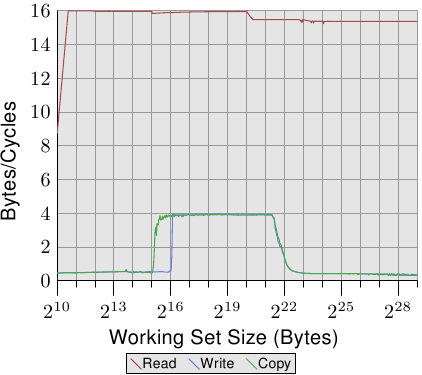
在图3.27中,测试运行两个线程,分别在Core 2处理器的两个内核中的每个内核上运行。但是,两个线程都访问相同的内存,但不一定完全同步。读取性能的结果与单线程情况没有区别。在任何多线程测试用例中,还会看到一些抖动。
有趣的一点是适合L1d的工作集大小的写入和复制性能。从图中可以看出,性能与必须从主存储器读取数据的性能相同。两个线程争夺相同的内存位置,并且必须发送用于缓存行的RFO消息。有问题的是,即使两个内核共享高速缓存,也无法以L2高速缓存的速度处理这些请求。一旦L1d缓存不足,就将修改后的条目从每个内核的L1d刷新到共享L2中。到那时,性能显着提高,因为现在L2高速缓存可以满足L1d丢失,并且仅在尚未刷新数据时才需要RFO消息。这就是为什么我们看到这些尺寸的工作集速度降低了50%的原因。
由于一个供应商的处理器版本之间存在显着差异,因此当然值得一提其他供应商的处理器的性能。图3.28显示了AMD系列10h Opteron处理器的性能。该处理器具有64kB L1d,512kB L2和2MB L3。L3缓存在处理器的所有内核之间共享。性能测试的结果如图3.28所示。
图3.28:AMD系列10h Opteron带宽
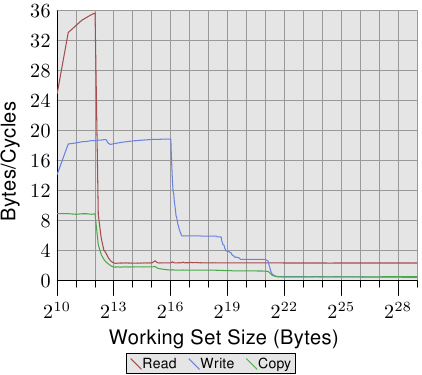
关于数字的第一个细节是,如果L1d高速缓存足够,则处理器能够在每个周期处理两条指令。每个周期的读取性能超过32个字节,甚至每个周期18.7字节的写入性能也很高。但是,读取曲线迅速变平,每个周期只有2.3个字节,非常低。此测试的处理器不会预取任何数据,至少不会有效。
另一方面,写入曲线根据各种高速缓存的大小执行。对于L1d的完整大小,可以达到最高性能,L2的每个周期降低到6个字节,L3的每个周期降低到2.8个字节,如果L3不能容纳所有数据,则最终每个周期只有0.5个字节。L1d缓存的性能超过(旧)Core 2处理器的性能,L2访问同样快(Core 2具有更大的缓存),并且L3和主内存访问更慢。
复制性能不能优于读取或写入性能。这就是为什么我们看到曲线最初由读取性能主导,然后由写入性能主导的原因。
Opteron处理器的多线程性能如图3.29所示。
图3.29:带2个线程的AMD Fam 10h带宽
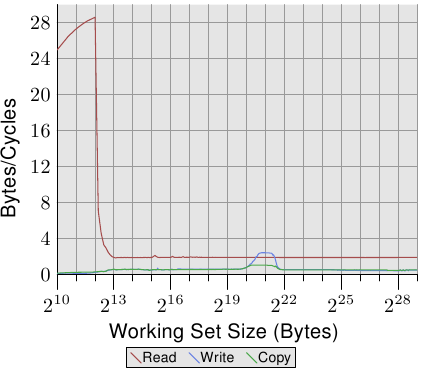
读取性能在很大程度上不受影响。每个线程的L1d和L2都像以前一样工作,在这种情况下,L3缓存也无法很好地预取。这两个线程不会对L3施加过大的压力。此测试中的最大问题是写入性能。线程共享的所有数据都必须通过L3缓存。这种共享似乎效率很低,因为即使L3高速缓存大小足以容纳整个工作集,其成本也明显高于L3访问。通过将该图与图3.27进行比较,我们可以看到,在适当的工作集大小范围内,Core 2处理器的两个线程以共享L2缓存的速度运行。仅在很小的工作范围内,Opteron处理器才能达到这种性能水平 仅L3的速度比Core 2的L2慢。
3.5.2关键单词加载
内存以小于缓存行大小的块形式从主内存传输到缓存中。今天,一次传输64位,并且缓存行大小为64或128字节。这意味着每条高速缓存行需要进行8或16次传输。
DRAM芯片可以突发模式传输这些64位块。这可以填充高速缓存行,而无需来自存储控制器的任何其他命令以及可能的相关延迟。如果处理器预取高速缓存行,则这可能是最佳的操作方式。
如果程序对数据的高速缓存访问或指令高速缓存未命中(这意味着这是强制性高速缓存未命中,因为数据是第一次使用,或者是容量高速缓存未命中,因为有限的高速缓存大小需要逐出高速缓存行)情况有所不同。程序继续执行所需的高速缓存行中的单词可能不是高速缓存行中的第一个单词。即使在突发模式下,并且具有双倍数据速率传输,各个64位块的到达时间也明显不同。每个块比上一个延迟到达4个CPU周期或更晚。如果程序需要继续的字是高速缓存行的第八行,则程序必须在第一个字到达后再等待30个或更多个周期。
事情不一定必须是这样。存储器控制器可以自由请求以不同顺序的高速缓存行的字。处理器可以传达程序正在等待哪个单词, 关键单词,并且存储控制器可以首先请求该单词。一旦字到达,程序就可以继续,而其余的高速缓存行到达并且高速缓存尚未处于一致状态。此技术称为“关键单词优先和早期重启”。
当今的处理器实现了这种技术,但是在某些情况下这是不可能的。如果处理器预取数据,则未知单词。如果处理器在预取操作进行期间请求高速缓存行,则它必须等到关键字到达后才能影响顺序。
图3.30:缓存行末尾的关键字
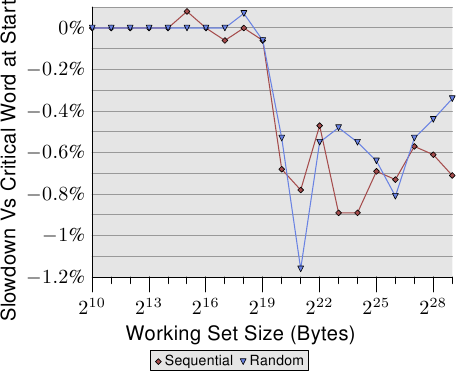
即使进行了这些优化,关键字在高速缓存行上的位置也很重要。图3.30显示了顺序访问和随机访问的跟踪测试。显示的是使用在第一个单词中追逐指针的指针运行测试的速度与在最后一个单词中指针的情况相比变慢。元素大小为64个字节,对应于缓存行大小。这些数字非常嘈杂,但是可以看出,一旦L2不足以容纳工作集大小,关键单词最后的情况下的性能就会降低大约0.7%。顺序访问似乎受到的影响更大。当预取下一个缓存行时,这将与上述问题一致。
3.5.3缓存放置
与超线程,内核和处理器相关的缓存位置不受程序员的控制。但是程序员可以确定在哪里执行线程,然后缓存与已使用的CPU之间的关系就变得很重要。
这里我们将不讨论何时选择运行线程的核心。我们将仅描述架构师在设置线程的亲和力时必须考虑的架构细节。
根据定义,超线程共享除寄存器集以外的所有内容。这包括L1缓存。这里没有更多要说的了。乐趣始于处理器的各个核心。每个内核至少具有自己的L1缓存。除此之外,今天没有太多共同之处:
- 早期的多核处理器具有单独的L2缓存,没有更高的缓存。
- 后来的英特尔机型共享了双核处理器的二级缓存。对于四核处理器,我们必须为两个内核的每对分别处理单独的二级缓存。没有更高级别的缓存。
- AMD的10h系列处理器具有单独的L2缓存和统一的L3缓存。
在处理器供应商的宣传材料中已经写了很多有关其各自型号优势的文章。如果内核处理的工作集不重叠,则单独的L2缓存具有优势。这对于单线程程序非常有效。由于今天仍然经常发生这种情况,因此这种方法的效果并不差。但是总会有一些重叠。缓存都包含公共运行时库中使用最频繁的部分,这意味着浪费了一些缓存空间。
像英特尔的双核处理器一样,完全共享L1之外的所有缓存可以具有很大的优势。如果在两个内核上工作的线程的工作集明显重叠,则总可用高速缓存将增加,并且工作集可以更大而不会降低性能。如果工作集不重叠,那么英特尔的高级智能缓存管理应该可以防止任何一个内核独占整个缓存。
但是,如果两个内核将大约一半的缓存用于其各自的工作集,则会产生一些摩擦。缓存必须不断权衡两个内核的缓存使用情况,而作为这种重新平衡的一部分而执行的逐出可能会选择得很差。为了查看问题,我们看了另一个测试程序的结果。
图3.31:具有两个进程的带宽
测试程序具有一个过程,该过程使用SSE指令不断读取或写入2MB的内存块。之所以选择2MB,是因为它是该Core 2处理器的L2缓存的一半。该进程固定到一个核心,而第二个进程固定到另一个核心。第二个过程读取和写入大小可变的存储区域。该图显示了每个周期读取或写入的字节数。显示了四个不同的图形,每个图形分别用于读写过程。读/写图用于后台进程,该进程始终使用2MB的工作集进行写操作,而使用可变工作组的被测进程则进行读取。
图中有趣的部分是2 20和2 23字节之间的部分。如果两个内核的L2缓存完全分开,我们可以预期所有四个测试的性能将在2 21和2 22之间下降。字节,这意味着L2缓存一旦耗尽。如图3.31所示,情况并非如此。对于后台进程正在编写的情况,这是最明显的。在工作集大小达到1MB之前,性能开始下降。这两个进程不共享内存,因此这些进程不会导致生成RFO消息。这些是纯粹的缓存逐出问题。智能缓存处理存在以下问题,即每个可用核心的高速缓存大小比每个可用核心2MB的缓存更接近1MB。只能希望,如果内核之间共享的高速缓存仍然是即将到来的处理器的功能,那么用于智能高速缓存处理的算法将是固定的。
在引入更高级别的缓存之前,拥有带有两个L2缓存的四核处理器只是一个权宜之计。与单独的插槽和双核处理器相比,该设计没有明显的性能优势。两个内核通过同一总线进行通信,该总线在外部显示为FSB。没有特殊的快速通道数据交换。
多核处理器的缓存设计的未来将位于更多的层。AMD的10h处理器家族起步。我们是否将继续看到较低级别的高速缓存由处理器核心的子集共享,还有待观察。高速缓存和频繁使用的高速缓存无法在许多内核之间共享,因此需要额外的高速缓存级别。性能将受到影响。它还将需要具有高关联性的超大型缓存。高速缓存大小和关联性这两个数字都必须随共享高速缓存的核心数成比例。使用大型L3缓存和合理大小的L2缓存是一个合理的权衡。L3高速缓存较慢,但理想情况下不如L2高速缓存使用得那么频繁。
对于程序员而言,所有这些不同的设计都意味着制定计划决策时的复杂性。必须了解工作负载和机器体系结构的详细信息才能获得最佳性能。幸运的是,我们有支持来确定机器体系结构。这些接口将在后面的部分中介绍。
3.5.4 FSB影响
FSB在机器性能中起着核心作用。缓存内容只能在与内存的连接允许的情况下尽快存储和加载。我们可以通过在两台机器上运行一个程序来显示出多少,这两个机器的内存模块的速度只是不同。图3.32显示了在64位计算机上NPAD = 7时Addnext0测试的结果(将下一个元素pad [0]元素的内容添加到自己的pad [0]元素中) 。这两台机器都具有Intel Core 2处理器,第一台使用667MHz DDR2模块,第二台使用800MHz模块(增加了20%)。
图3.32:FSB速度的影响
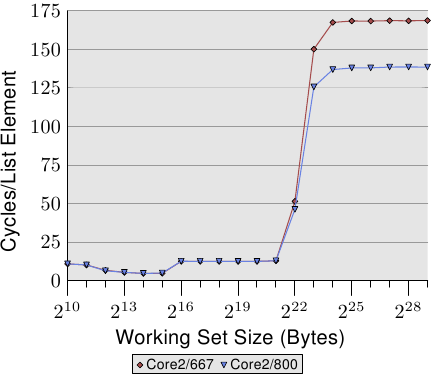
数据显示,当FSB真正承受大型工作台尺寸的压力时,我们的确受益匪浅。此测试中测得的最大性能提升为18.2%,接近理论最大值。这表明,更快的FSB确实可以节省大量时间。工作集是否适合高速缓存(这些处理器具有4MB的L2)并不重要。必须记住,我们正在这里测量一个程序。系统的工作集包括所有同时运行的进程所需的内存。这样,使用较小的程序很容易超过4MB内存。
今天,某些英特尔处理器支持FSB速度高达1,333MHz,这意味着将再增加60%。未来将看到更高的速度。如果速度很重要并且工作集大小更大,那么快速的RAM和较高的FSB速度无疑是值得的。但是,必须谨慎,因为即使处理器可能支持更高的FSB速度,主板/北桥也可能不支持。检查规格至关重要。
内存部分3:虚拟内存4个虚拟内存
处理器的虚拟内存子系统实现提供给每个进程的虚拟地址空间。这使每个进程都认为它在系统中是单独存在的。虚拟内存的优点列表将在其他地方详细介绍,因此在此不再赘述。相反,本节着重于虚拟内存子系统的实际实现细节以及相关的成本。
虚拟地址空间由CPU的内存管理单元(MMU)实现。操作系统必须填写页表数据结构,但是大多数CPU自己完成其余工作。这实际上是一个非常复杂的机制。理解它的最好方法是介绍用于描述虚拟地址空间的数据结构。
MMU执行的地址转换输入是虚拟地址。通常,对其价值的限制很少(如果有的话)。虚拟地址在32位系统上是32位值,在64位系统上是64位值。在某些系统上,例如x86和x86-64,所使用的地址实际上涉及另一个间接级别:这些体系结构使用段,这些段仅导致将偏移量添加到每个逻辑地址。我们可以忽略地址生成的这一部分,它是微不足道的,而不是程序员在内存处理性能方面必须关心的部分。{ x86上的细分限制与性能相关,但这是另一回事。}
4.1最简单的地址转换
有趣的部分是虚拟地址到物理地址的转换。MMU可以逐页重新映射地址。正如寻址高速缓存行时一样,虚拟地址也分为不同的部分。这些部分用于索引各种表,这些表用于构建最终物理地址。对于最简单的模型,我们只有一层表。
图4.1:1级地址转换
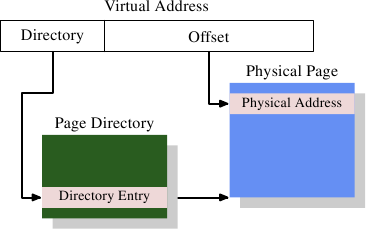
图4.1显示了如何使用虚拟地址的不同部分。顶部用于选择页面目录中的条目;操作系统可以单独设置该目录中的每个条目。页面目录条目确定物理内存页面的地址;页面目录中的多个条目可以指向相同的物理地址。通过将页面目录中的页面地址与虚拟地址中的低位组合在一起,可以确定存储单元的完整物理地址。页面目录条目还包含有关页面的一些其他信息,例如访问权限。
页面目录的数据结构存储在内存中。操作系统必须分配连续的物理内存,并将该内存区域的基地址存储在特殊寄存器中。然后,将虚拟地址的适当位用作页面目录的索引,该目录实际上是目录条目的数组。
举一个具体的例子,这是用于x86机器上4MB页面的布局。虚拟地址的偏移量部分为22位,足以寻址4MB页中的每个字节。虚拟地址的其余10位选择页面目录中的1024个条目之一。每个条目包含一个4MB页面的10位基址,该地址与偏移量结合在一起形成一个完整的32位地址。
4.2多层页表
4MB页面不是常态,它们会浪费大量内存,因为OS必须执行的许多操作都需要与内存页面对齐。对于4kB页(32位计算机上的规范,并且仍然经常在64位计算机上使用),虚拟地址的Offset部分的大小仅为12位。这留下20位作为页面目录的选择器。具有2 20个条目的表是不实际的。即使每个条目只有4个字节,表的大小也将是4MB。由于每个进程可能具有其自己的不同页面目录,因此系统的许多物理内存将被这些页面目录占用。
解决方案是使用多个级别的页表。然后,它们可以代表一个稀疏的大页面目录,其中未实际使用的区域不需要分配的内存。因此,表示形式更加紧凑,可以在内存中使用许多进程的页表,而不会对性能造成太大影响。
今天,最复杂的页表结构包含四个级别。图4.2显示了这种实现的示意图。
图4.2:4级地址转换
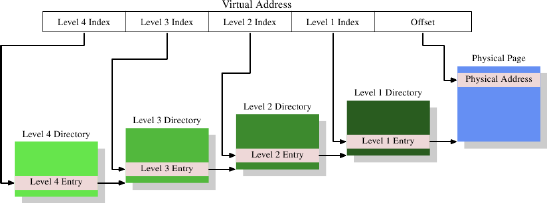
在此示例中,虚拟地址被分为至少五个部分。其中四个部分是各个目录的索引。使用CPU中的专用寄存器来引用4级目录。4级到2级目录的内容是对下一个较低目录的引用。如果目录条目标记为空,则显然不需要指向任何较低的目录。这样,页面表树可以稀疏而紧凑。如图4.1所示,级别1目录的条目是部分物理地址,以及诸如访问权限之类的辅助数据。
为了确定对应于虚拟地址的物理地址,处理器首先确定最高级别目录的地址。该地址通常存储在寄存器中。然后,CPU获取与该目录相对应的虚拟地址的索引部分,并使用该索引来选择适当的条目。此项是下一个目录的地址,该目录使用虚拟地址的下一部分进行索引。此过程一直进行到到达1级目录为止,此时目录条目的值是物理地址的高位。通过添加虚拟地址中的页面偏移位来完成物理地址。此过程称为页面树漫游。一些处理器(例如x86和x86-64)在硬件中执行此操作,其他处理器则需要操作系统的帮助。
系统上运行的每个进程可能都需要自己的页表树。可以部分共享树,但这是一个例外。因此,如果页表树所需的内存尽可能小,则对性能和可伸缩性都有好处。理想的情况是将使用的内存在虚拟地址空间中放置在一起。实际使用的物理地址无关紧要。一个小型程序可能只需要在2、3和4级别的每个目录中使用一个目录,以及几个1级目录。在具有4kB页和每个目录512个条目的x86-64上,这允许寻址2MB的地址,总共有4个目录(每个级别一个)。1GB的连续内存可以使用一个目录访问2至4级,使用512个目录访问1级。
但是,假设所有内存都可以连续分配太简单了。出于灵活性的考虑,在大多数情况下,进程的堆栈和堆区域分配在地址空间的相对两端。如果需要,这可以使任何一个区域尽可能多地增长。这意味着最有可能需要两个2级目录,并相应地有更多的较低级目录。
但是,即使这样也不总是符合当前的做法。出于安全原因,可执行文件的各个部分(代码,数据,堆,堆栈,DSO,aka共享库)都映射在随机地址[nonselsec]。随机化扩展到各个部分的相对位置。这意味着在一个进程中使用的各种内存区域遍布整个虚拟地址空间。通过对随机化的地址位数施加一些限制,可以限制范围,但是可以肯定的是,在大多数情况下,对于第2级和第3级,进程只允许一个或两个目录运行。
如果性能确实比安全性重要得多,则可以关闭随机化。然后,操作系统通常通常至少将所有DSO连续加载到虚拟内存中。
4.3优化页表访问
页表的所有数据结构都保存在主存储器中;这是OS构造和更新表的地方。创建过程或更改页表后,将通知CPU。页表用于使用上述页表遍历将每个虚拟地址解析为物理地址。更重要的是:在解析虚拟地址的过程中,每个级别至少使用一个目录。这需要多达四个内存访问(对于正在运行的进程的单个访问),这很慢。可以将这些目录表条目视为普通数据,并将其缓存在L1d,L2等中,但这仍然太慢了。
从虚拟内存的早期开始,CPU设计人员就使用了不同的优化方法。一个简单的计算可以表明,仅将目录表条目保留在L1d和更高级别的缓存中将导致可怕的性能。每次绝对地址计算将需要对应于页表深度的多个L1d访问。这些访问不能并行化,因为它们取决于前一个查询的结果。在具有四个页表级别的计算机上,仅此一项就至少需要12个周期。加上L1d未命中的可能性,结果是指令流水线无法隐藏的结果。附加的L1d访问也将宝贵的带宽窃取到缓存。
因此,不仅可以缓存目录表条目,还可以缓存对物理页面地址的完整计算。出于代码和数据缓存起作用的相同原因,这种缓存的地址计算是有效的。由于虚拟地址的页面偏移部分在物理页面地址的计算中不起作用,因此仅将虚拟地址的其余部分用作缓存的标签。根据页面大小,这意味着成百上千的指令或数据对象共享相同的标签,因此也共享相同的物理地址前缀。
计算值存储在其中的缓存称为转换后备缓冲区(TLB)。它通常是一个很小的缓存,因为它必须非常快。就像其他高速缓存一样,现代CPU提供了多级TLB高速缓存。较高级别的缓存更大且更慢。L1TLB的小尺寸通常是通过使高速缓存与LRU逐出策略完全关联来弥补的。最近,此高速缓存的大小不断增长,并且在此过程中已更改为设置为关联的。因此,无论何时必须添加新条目,它都可能不是被驱逐并替换的最旧条目。
如上所述,用于访问TLB的标签是虚拟地址的一部分。如果标签在高速缓存中具有匹配项,则通过将虚拟地址的页面偏移量与高速缓存的值相加来计算最终的物理地址。这是一个非常快速的过程。之所以必须这样做,是因为对于使用绝对地址的每条指令,物理地址必须是可用的;在某些情况下,对于使用 物理地址作为键的L2查找,物理地址必须是可用 的。如果TLB查找未命中,则处理器必须执行页表遍历;这可能会非常昂贵。
如果地址在另一页上,则通过软件或硬件预取代码或数据可以隐式预取TLB的条目。硬件预取不能这样做,因为硬件可能会启动无效的页表遍历。因此,程序员无法依靠硬件预取来预取TLB条目。必须使用预取指令明确地完成此操作。就像数据和指令缓存一样,TLB可以出现在多个级别中。就像数据缓存一样,TLB通常以两种形式出现:一条指令TLB(ITLB)和一条数据TLB(DTLB)。像L2TLB这样的高层TLB通常是统一的,其他缓存也是如此。
4.3.1使用TLB的注意事项
TLB是处理器核心的全局资源。在处理器内核上执行的所有线程和进程都使用相同的TLB。由于虚拟地址到物理地址的转换取决于安装的页面表树,因此如果更改了页面表,则CPU无法盲目地重用缓存的条目。每个进程都有一个与内核和VMM(管理程序)(如果存在)不同的页表树(但不是同一进程中的线程)。进程的地址空间布局也可能会更改。有两种方法可以解决此问题:
- 每当更改页表树时,都会刷新TLB。
- TLB条目的标签被扩展以额外且唯一地标识它们引用的页表树。
在第一种情况下,只要执行上下文切换,就会刷新TLB。因为在大多数操作系统中,从一个线程/进程切换到另一个线程/进程需要执行一些内核代码,所以TLB刷新仅限于进入和离开内核地址空间。在虚拟化系统上,当内核必须调用VMM并返回时也会发生这种情况。如果内核和/或VMM不必使用虚拟地址,或者可以重用与进行系统/ VMM调用的进程或内核相同的虚拟地址,则仅在离开内核或VMM时才需要刷新TLB。 ,处理器将恢复执行其他进程或内核。
冲洗TLB是有效的,但价格昂贵。例如,在执行系统调用时,内核代码可能仅限于数千条指令,这些指令可能会触及几个新页面(或一个巨大的页面,在某些体系结构上就是Linux的情况)。这项工作将仅替换与触摸页面一样多的TLB条目。对于具有128条ITLB和256条DTLB条目的Intel Core2架构,完全刷新将意味着不必要地刷新了100多个和200个条目(分别)。当系统调用返回到相同的进程时,所有已刷新的TLB条目都可以再次使用,但它们将消失。对于内核或VMM中的常用代码也是如此。即使内核和VMM的页表通常不更改,在每次进入内核时,TLB也必须从头开始填充,并且 因此,从理论上讲,TLB条目可以保存很长时间。这也解释了为什么今天的处理器中的TLB缓存不更大:为什么程序很可能不会运行足够长的时间来填充所有这些条目。
当然,这一事实并没有使CPU架构师幸免。优化缓存刷新的一种可能性是单独使TLB条目无效。例如,如果内核代码和数据属于特定的地址范围,则仅必须将属于该地址范围的页面从TLB中逐出。这仅需要比较标签,因此不是很昂贵。如果部分地址空间发生更改(例如,通过调用munmap),此方法也很有用。
更好的解决方案是扩展用于TLB访问的标签。如果除了虚拟地址的一部分之外,还为每个页表树添加了唯一的标识符(即,进程的地址空间),则根本不必完全清除TLB。内核,VMM和各个进程都可以具有唯一的标识符。该方案的唯一问题是可用于TLB标签的位数受到严格限制,而地址空间的数目却没有受到限制。这意味着必须重复使用一些标识符。发生这种情况时,必须对TLB进行部分冲洗(如果可能的话)。所有带有重用标识符的条目都必须清除,但是希望这是一个更小的集合。
当系统上运行多个进程时,这种扩展的TLB标记具有一般优势。如果每个可运行进程的内存使用(以及由此产生的TLB条目使用)受到限制,则当再次调度该进程时,该进程最近使用的TLB条目很有可能仍位于TLB中。但是还有另外两个优点:
- 特殊的地址空间(例如内核和VMM使用的地址空间)通常只输入很短的时间。之后,控制权通常返回到发起呼叫的地址空间。没有标签,将执行两次TLB刷新。使用标记,将保留调用地址空间的缓存转换,并且由于内核和VMM地址空间根本不经常更改TLB条目,因此仍可以使用来自先前系统调用等的转换。
- 在同一进程的两个线程之间切换时,根本不需要进行TLB刷新。但是,如果没有扩展的TLB标签,进入内核的条目将破坏第一个线程的TLB条目。
某些处理器已经实现了一些扩展标签。AMD在Pacifica虚拟化扩展中引入了1位标签扩展。在虚拟化的上下文中,此1位地址空间ID(ASID)用于将VMM的地址空间与来宾域的地址空间区分开。这样,操作系统就可以避免每次输入VMM(例如,处理页面错误)或在控制权返回给来宾时VMM的TLB条目时都刷新来宾的TLB条目。该架构将允许将来使用更多位。其他主流处理器可能也会效仿并支持此功能。
4.3.2影响TLB性能
有几个因素会影响TLB的性能。第一个是页面的大小。显然,页面越大,越多的指令或数据对象将适合该页面。因此,较大的页面大小会减少所需的地址转换的总数,这意味着TLB缓存中需要的条目较少。大多数体系结构允许使用多种不同的页面大小。某些尺寸可以同时使用。例如,x86 / x86-64处理器的正常页面大小为4kB,但它们也可以分别使用4MB和2MB页面。IA-64和PowerPC允许将64kB之类的大小作为基本页面大小。
但是,使用大页面会带来一些问题。用于大页的内存区域在物理内存中必须是连续的。如果将用于管理物理内存的单位大小增加到虚拟内存页面的大小,则浪费的内存量将增加。各种内存操作(如加载可执行文件)都需要对齐页面边界。平均而言,这意味着每个映射都会浪费物理内存中每个映射的页面大小的一半。这种浪费很容易累加起来。因此,它为物理内存分配的合理单位大小设置了上限。
将单元大小增加到2MB以容纳x86-64上的大页面当然是不切实际的。大小太大。但这又意味着每个大页面必须由许多较小的页面组成。这些小页面在物理内存中必须是连续的 。分配2MB的连续物理内存(单位页面大小为4kB)可能很困难。它需要找到一个具有512个连续页面的空闲区域。在系统运行一段时间并且物理内存碎片化之后,这可能非常困难(或不可能)。
因此,在Linux上,有必要使用特殊的hugetlbfs文件系统在系统启动时预先分配这些大页面。保留一定数量的物理页面,以供大型虚拟页面专用。这限制了可能不总是使用的资源。这也是一个有限的池;增加它通常意味着重新启动系统。不过,在性能非常重要,资源充足且设置麻烦的情况下,较大的页面仍然是行之有效的方法。数据库服务器就是一个例子。
增加最小虚拟页面大小(与可选的大页面相对)也有其问题。内存映射操作(例如,加载应用程序)必须符合这些页面大小。不可能有更小的映射。对于大多数体系结构,可执行文件各个部分的位置具有固定的关系。如果页面大小增加到超出构建可执行文件或DSO时考虑的范围,则无法执行加载操作。记住此限制很重要。图4.3显示了如何确定ELF二进制文件的对齐要求。它被编码在ELF程序标头中。
$ eu-readelf -l / bin / ls 程序标题: 类型偏移VirtAddr PhysAddr FileSiz MemSiz Flg对齐 ... 负载0x000000 0x0000000000400000 0x0000000000400000 0x0132ac 0x0132ac RE 0x200000 负载0x0132b0 0x00000000006132b0 0x00000000006132b0 0x001a71 0x001a71 RW 0x200000 ...
图4.3:ELF程序标头指示对齐要求
在此示例中,为x86-64二进制,值是0x200000 = 2,097,152 = 2MB,它对应于处理器支持的最大页面大小。
使用较大页面大小的第二个效果是:页面表树的级别数减少了。由于虚拟地址中与页面偏移量相对应的部分增加了,因此剩下的比特数很少,需要通过页面目录进行处理。这意味着,在TLB丢失的情况下,必须完成的工作量减少了。
除了使用大页面大小之外,还可以通过将同时使用的数据移动到更少的页面来减少所需的TLB条目数。这类似于我们上面讨论的一些针对缓存使用的优化。只是现在所需的对齐方式很大。鉴于TLB条目的数量非常少,这可能是一个重要的优化。
4.4虚拟化的影响
OS映像的虚拟化将越来越普遍。这意味着将另一层内存处理添加到图片中。进程(基本上是监狱)或OS容器的虚拟化不属于此类,因为仅涉及一个OS。Xen或KVM之类的技术(无论有无处理器帮助)都可以执行独立的OS映像。在这些情况下,只有一个软件可以直接控制对物理内存的访问。
图4.4:Xen虚拟化模型
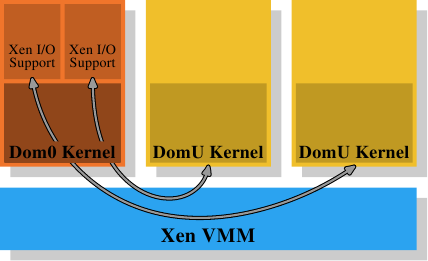
对于Xen(参见图4.4),Xen VMM是该软件。但是,VMM本身并未实现许多其他硬件控件。与其他早期系统(以及Xen VMM的第一个版本)上的VMM不同,内存和处理器之外的硬件由特权Dom0域控制。当前,该内核与非特权DomU内核基本上是同一内核,就内存处理而言,它们没有区别。在此重要的是,VMM将物理内存分发给Dom0和DomU内核,而Dom0和DomU内核本身将实现通常的内存处理,就好像它们直接在处理器上运行一样。
为了实现完成虚拟化所需的域的分离,Dom0和DomU内核中的内存处理不能不受限制地访问物理内存。VMM不会通过发出单独的物理页面并让来宾OS处理寻址来分发内存。这将无法为故障域或恶意来宾域提供任何保护。相反,VMM为每个来宾域创建自己的页表树,并使用这些数据结构分发内存。好处是,可以控制对页表树的管理信息的访问。如果代码没有适当的特权,它将无法执行任何操作。
Xen提供的虚拟化技术都利用了这种访问控制,无论使用了半虚拟化还是硬件虚拟化(也称为完整虚拟化)。来宾域为每个进程构造其页表树,其方式对于参数虚拟化和硬件虚拟化而言非常相似。每当访客OS修改其页表时,都会调用VMM。然后,VMM使用来宾域中的更新信息来更新其自己的影子页表。这些是硬件实际使用的页表。显然,此过程非常昂贵:对页面表树的每次修改都需要调用VMM。如果没有虚拟化,对内存映射的更改并不便宜,但现在它们变得更加昂贵。
考虑到从来宾OS到VMM以及自身的更改已经非常昂贵,因此额外的费用可能确实很大。这就是为什么处理器开始具有其他功能以避免创建影子页表的原因。这不仅好于速度方面的考虑,而且还可以减少VMM的内存消耗。英特尔具有扩展页表(EPT),而AMD称其为嵌套页表(NPT)。基本上,这两种技术都使来宾OS的页表产生虚拟物理地址。然后必须使用每个域的EPT / NPT树将这些地址进一步转换为实际的物理地址。这将允许以几乎非虚拟化情况的速度进行内存处理,因为已删除了大多数用于内存处理的VMM条目。
附加地址转换步骤的结果也存储在TLB中。这意味着TLB不存储虚拟物理地址,而是存储完整的查找结果。已经解释了AMD的Pacifica扩展引入了ASID,以避免在每个条目上进行TLB刷新。在处理器扩展的初始发行版中,ASID的位数为1。这足以区分VMM和来宾OS。英特尔具有用于相同目的的虚拟处理器ID(VPID),但其中有更多。但是VPID对于每个来宾域都是固定的,因此不能用于标记单独的进程,也不能避免在该级别进行TLB刷新。
每次地址空间修改所需的工作量是虚拟化OS的一个问题。但是,基于VMM的虚拟化还存在另一个固有的问题:无法围绕两层内存处理。但是内存处理很困难(尤其是考虑到诸如NUMA之类的复杂性时,请参见第5节)。Xen使用单独的VMM的方法使最佳处理(或什至是好的处理)变得困难,因为必须在VMM中复制内存管理实现的所有复杂性,包括发现内存区域等“琐碎”的事情。操作系统具有完善和优化的实现;一个人真的想避免重复它们。
图4.5:KVM虚拟化模型
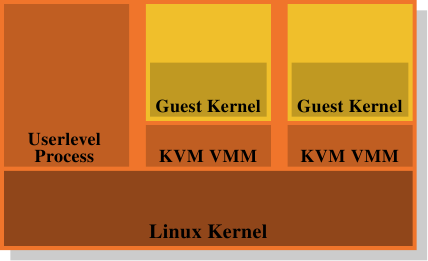
这就是为什么将VMM / Dom0模型作为结论如此诱人的原因。图4.5显示了KVM Linux内核扩展如何尝试解决该问题。没有单独的VMM直接在硬件上运行并控制所有guest虚拟机。相反,普通的Linux内核将接管此功能。这意味着Linux内核中完整而复杂的内存处理功能用于管理系统的内存。来宾域在创建者称为“来宾模式”的情况下与正常的用户级过程一起运行。虚拟化功能(部分或完全虚拟化)由另一个用户级别的流程KVM VMM控制。这只是另一个使用内核实现的特殊KVM设备控制来宾域的过程。
与使用Xen模型的单独VMM相比,该模型的优势在于,即使使用来宾OS时仍有两个内存处理程序在工作,但仅需要一个实现(在Linux内核中)。不必在另一段代码(例如Xen VMM)中复制相同的功能。这导致更少的工作,更少的错误,并且可能减少两个内存处理程序接触的摩擦,因为Linux guest虚拟机中的内存处理程序做出的假设与在裸机上运行的外部Linux内核中的内存处理程序相同。
总体而言,程序员必须意识到,使用虚拟化后,内存操作的成本甚至比没有虚拟化时还要高。任何减少这项工作的优化将在虚拟化环境中带来更大的回报。随着时间的流逝,处理器设计人员将通过EPT和NPT之类的技术越来越减少这种差异,但是它永远不会消失。
内存第4部分:NUMA支持5 NUMA支持
在第2节中,我们看到,在某些计算机上,对物理内存特定区域的访问成本取决于访问的来源。此类硬件需要操作系统和应用程序特别注意。我们将从NUMA硬件的一些细节开始,然后我们将介绍Linux内核为NUMA提供的一些支持。
5.1 NUMA硬件
不统一的存储体系结构变得越来越普遍。在NUMA的最简单形式中,处理器可以具有本地内存(请参见图2.3),该内存比其他处理器本地的内存便宜。这种类型的NUMA系统的成本差异不高,即NUMA系数很低。
NUMA尤其是在大型机器中也使用。我们已经描述了让许多处理器访问同一内存的问题。对于商用硬件,所有处理器都将共享同一北桥(目前忽略AMD Opteron NUMA节点,它们有自己的问题)。这使得北桥成为一个严重的瓶颈,因为所有内存流量都通过北桥进行 路由。大型计算机当然可以使用自定义硬件代替北桥,但是,除非所用的存储芯片具有多个端口(即可以从多个总线使用它们),否则仍然存在瓶颈。多端口RAM的构建和支持非常复杂且昂贵,因此,几乎从未使用过。
复杂性的下一步是AMD使用的模型,其中互连机制(在AMD的情况下为超传输,他们从Digital获得许可的技术)可为未直接连接到RAM的处理器提供访问权限。除非人们想要任意增加直径(即,任意两个节点之间的最大距离),否则可以以这种方式形成的结构的尺寸受到限制。
图5.1:超立方体
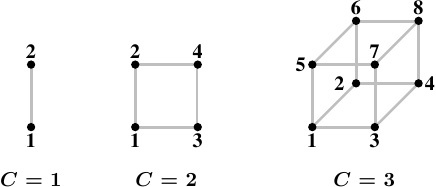
超级多维数据集是节点的有效拓扑,它可以将节点数限制为2 C,其中C是每个节点具有的互连接口数。对于拥有2 n个CPU的所有系统,超立方体的直径最小。图5.1显示了前三个超立方体。每个超立方体的直径C为绝对最小值。AMD第一代Opteron处理器每个处理器具有三个超传输链接。至少一个处理器必须具有连接到一个链路的南桥,这意味着当前可以直接和有效地实现C = 2的超立方体。宣布下一代具有四个链接,此时C = 3 超立方体将是可能的。
但是,这并不意味着不能支持更大的处理器累积量。有些公司已经开发了交叉开关,可以使用更大的处理器集(例如,Newisys的Horus)。但是这些交叉开关增加了NUMA因子,并且在一定数量的处理器上不再有效。
下一步意味着连接CPU组并为所有CPU实现一个共享内存。所有这些系统都需要专门的硬件,绝不是商品系统。这样的设计存在多个复杂程度。仍然非常接近商用机器的系统是IBM x445和类似机器。可以购买带有x86和x86-64处理器的普通4U,8路机器。然后,可以将其中两台计算机(有时最多四台)连接起来,作为具有共享内存的单台计算机工作。所使用的互连引入了重要的NUMA因素,操作系统以及应用程序都必须考虑这一因素。
另一方面,像SGI的Altix这样的机器是专门为互连而设计的。SGI的NUMAlink互连结构非常快且延迟低。这两个都是高性能计算(HPC)的要求,尤其是在使用消息传递接口(MPI)时。缺点当然是,这种复杂性和专业性非常昂贵。它们使NUMA因子相当低,但由于这些计算机可以具有的CPU数量(数千个)和互连能力有限,因此NUMA因子实际上是动态的,根据工作负载可以达到不可接受的水平。
更常用的解决方案是使用高速网络连接商用机器集群。但是,这些不是NUMA机器。它们不实现共享地址空间,因此不属于此处讨论的任何类别。
5.2对NUMA的操作系统支持
为了支持NUMA计算机,操作系统必须考虑内存的分布式性质。例如,如果某个进程在给定的处理器上运行,则分配给该进程的地址空间的物理RAM应该来自本地内存。否则,每个指令都必须访问远程存储器以获取代码和数据。需要考虑的特殊情况仅在NUMA机器中存在。DSO的文本段通常在机器的物理RAM中仅存在一次。但是,如果所有CPU上的进程和线程都使用DSO(例如,基本运行时库,如libc),这意味着除少数处理器外,所有其他处理器都必须具有远程访问权限。理想情况下,操作系统会将此类DSO“镜像”到每个处理器的物理RAM中并使用本地副本。这是一种优化,而不是要求,通常很难实现。它可能不受支持或仅受限制。
为避免使情况变得更糟,操作系统不应将进程或线程从一个节点迁移到另一个节点。操作系统应该已经尝试避免在普通的多处理器计算机上迁移进程,因为从一个处理器迁移到另一个处理器意味着缓存内容丢失。如果负载分配需要从处理器迁移进程或线程,则OS通常可以选择具有足够容量的任意新处理器。在NUMA环境中,新处理器的选择受到更多限制。新选择的处理器对进程正在使用的内存的访问成本不应比旧处理器高。这限制了目标列表。如果没有符合该标准的免费处理器,则操作系统别无选择,只能迁移到内存访问成本更高的处理器。
在这种情况下,有两种可能的解决方法。首先,我们可以希望情况是暂时的,并且可以将过程迁移回更适合的处理器。另外,操作系统还可以将进程的内存迁移到更接近新使用的处理器的物理页面。这是相当昂贵的操作。可能必须复制大量内存,尽管不一定要一步一步。在这种情况下,至少必须短暂停止该过程,以便正确迁移对旧页面的修改。为了使页面迁移高效,快速,还列出了其他要求。简而言之,除非确实必要,否则操作系统应避免使用它。
通常,不能假定NUMA机器上的所有进程都使用相同数量的内存,这样,随着处理器之间进程的分布,内存使用也将平均分布。实际上,除非在计算机上运行的应用程序非常具体(在HPC世界中很常见,但在外部不是),否则内存使用将非常不平等。一些应用程序将使用大量的内存,而其他应用程序几乎不会使用。如果始终向发出请求的处理器本地分配内存,则迟早会导致问题。系统最终将耗尽运行大型进程的节点的本地内存。
为了应对这些严重问题,默认情况下,内存不是专门在本地节点上分配的。要利用系统的所有内存,默认策略是分拆内存。这样可以保证平等使用系统的所有内存。副作用是,由于平均而言,对所使用的所有内存的访问成本不会改变,因此可以在处理器之间自由迁移进程。对于较小的NUMA因数,条带化是可以接受的,但仍不是最佳选择(请参见5.4节中的数据)。
这是一种悲观化,有助于系统避免严重问题并使其在正常操作下更可预测。但是,在某些情况下,它确实会降低整体系统性能。这就是Linux允许每个进程选择内存分配规则的原因。流程可以为其自身及其子级选择不同的策略。我们将在第6节中介绍可用于此的接口。
5.3发布信息
内核通过sys伪文件系统(sysfs)发布有关以下处理器缓存的信息
/ sys / devices / system / cpu / cpu * / cache
在6.2.1节中,我们将看到可用于查询各种缓存大小的接口。这里重要的是缓存的拓扑。上面的目录包含子目录(名为index *),这些子目录列出了有关CPU拥有的各种缓存的信息。 就拓扑而言,文件类型,level和shared_cpu_map是这些目录中的重要文件。对于Intel Core 2 QX6700,信息如表5.1所示。
类型 水平 shared_cpu_map cpu0 索引0 数据 1个 00000001 索引1 指令 1个 00000001 索引2 统一 2 00000003 cpu1 索引0 数据 1个 00000002 索引1 指令 1个 00000002 索引2 统一 2 00000003 cpu2 索引0 数据 1个 00000004 索引1 指令 1个 00000004 索引2 统一 2 0000000c cpu3 索引0 数据 1个 00000008 索引1 指令 1个 00000008 索引2 统一 2 0000000c 表5.1:Core 2 CPU缓存的sysfs信息
该数据的含义如下:
- 每个核心{关于cpu0到cpu3 是核心的知识来自另一个地方,我们将在后面简要说明。}具有三个缓存:L1i,L1d,L2。
- L1d和L1i高速缓存不与任何人共享-每个核心都有自己的高速缓存集。这由shared_cpu_map中的位图仅具有一个设置位来指示。
- 共享cpu0和cpu1上的L2缓存,以及cpu2和cpu3上的L2 。
如果CPU具有更多的缓存级别,则将有更多的index * 目录。
对于四插槽双核皓龙计算机,缓存信息如下表5.2所示:
类型 水平 shared_cpu_map cpu0 索引0 数据 1个 00000001 索引1 指令 1个 00000001 索引2 统一 2 00000001 cpu1 索引0 数据 1个 00000002 索引1 指令 1个 00000002 索引2 统一 2 00000002 cpu2 索引0 数据 1个 00000004 索引1 指令 1个 00000004 索引2 统一 2 00000004 cpu3 索引0 数据 1个 00000008 索引1 指令 1个 00000008 索引2 统一 2 00000008 cpu4 索引0 数据 1个 00000010 索引1 指令 1个 00000010 索引2 统一 2 00000010 cpu5 索引0 数据 1个 00000020 索引1 指令 1个 00000020 索引2 统一 2 00000020 cpu6 索引0 数据 1个 00000040 索引1 指令 1个 00000040 索引2 统一 2 00000040 cpu7 索引0 数据 1个 00000080 索引1 指令 1个 00000080 索引2 统一 2 00000080 表5.2:Opteron CPU缓存的sysfs信息
可以看出,这些处理器还具有三个缓存:L1i,L1d,L2。没有一个内核共享任何级别的缓存。该系统有趣的部分是处理器拓扑。没有这些附加信息,就无法理解缓存数据。该SYS文件系统暴露在下面的文件信息
/ sys / devices / system / cpu / cpu * /拓扑
表5.3显示了此层次结构中SMP Opteron机器的有趣文件。
physical_
package_idcore_id core_
兄弟姐妹thread_
兄弟姐妹cpu0 0 0 00000003 00000001 cpu1 1个 00000003 00000002 cpu2 1个 0 0000000c 00000004 cpu3 1个 0000000c 00000008 cpu4 2 0 00000030 00000010 cpu5 1个 00000030 00000020 cpu6 3 0 000000c0 00000040 cpu7 1个 000000c0 00000080 表5.3:Opteron CPU拓扑的sysfs信息
将表5.2和表5.3放在一起,我们可以看到没有CPU具有超线程(thread_siblings 位图设置了一位),系统实际上有四个处理器(physical_package_id 0到3),每个处理器有两个核,并且没有一个内核共享任何缓存。这恰好与早期的Opteron相对应。
到目前为止提供的数据中完全缺少的是有关此计算机上NUMA性质的信息。任何SMP Opteron机器都是NUMA机器。对于此数据,我们必须查看NUMA计算机上存在的sys文件系统的另一部分,即下面的层次结构
/ sys / devices / system / node
该目录包含系统上每个NUMA节点的子目录。在特定于节点的目录中,有许多文件。表5.4中显示了前两个表中描述的Opteron机器的重要文件及其内容。
cpumap 距离 节点0 00000003 10 20 20 20 节点1 0000000c 20 10 20 20 节点2 00000030 20 20 10 20 节点3 000000c0 20 20 20 10 表5.4:Opteron节点的sysfs信息
此信息将其余所有内容联系在一起;现在,我们对机器的架构有了完整的了解。我们已经知道该机器具有四个处理器。从node *目录中cpumap文件中的 值中设置的位可以看出,每个处理器都构成自己的节点。这些目录中的距离文件包含一组值,每个节点一个,代表各个节点上的内存访问成本。在此示例中,所有本地内存访问的成本均为10,对任何其他节点的所有远程访问的成本均为20。{顺便说一句,这是不正确的。ACPI信息显然是错误的,因为尽管所使用的处理器具有三个相关的HyperTransport链接,但至少一个处理器必须连接到南桥。因此,至少一对节点必须具有更大的距离。}这意味着,即使处理器被组织为二维超立方体(请参见图5.1),未直接连接的处理器之间的访问也不是那么昂贵。成本的相对值应该可用作访问时间实际差异的估计。所有这些信息的准确性是另一个问题。
5.4远程访问成本
距离是相关的。AMD在[amdccnuma]中记录了四插槽计算机的NUMA成本。对于写操作,数字如图5.3所示。
图5.3:具有多个节点的读/写性能
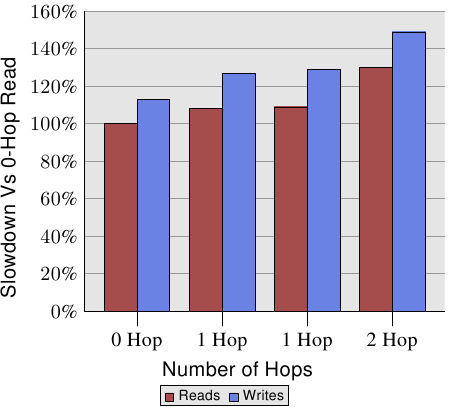
写比读慢,这不足为奇。有趣的部分是1跳和2跳情况的成本。实际上,这两种1跳案例的费用略有不同。有关详细信息,请参见[amdccnuma]。我们需要从该图表记住的事实是,两跳读取和写入的速度分别比0跳读取慢30%和49%。2跳写比0跳写慢32%,比1跳写慢17%。处理器和内存节点的相对位置可能会有很大的不同。AMD的下一代处理器将具有每个处理器四个相干的HyperTransport链接。在这种情况下,四插槽机器的直径将为一。对于八个插槽,由于具有八个节点的超立方体的直径为三,因此同样的问题也会报复。
所有这些信息都是可用的,但是使用起来很麻烦。在6.5节中,我们将看到一个有助于更轻松地访问和使用此信息的界面。
系统提供的最后一条信息是流程本身的状态。可以确定内存映射文件,写时复制(COW)页面和匿名内存如何在系统中的节点上分布。{写时复制是一种在OS实现中经常使用的方法,当一个内存页首先有一个用户,然后必须复制以允许独立用户时。在许多情况下,根本不需要复制,或者根本不需要复制,在这种情况下,仅当任何一个用户修改了内存时才复制。操作系统拦截写操作,复制内存页,然后允许写指令继续进行。}每个进程都有一个文件/ proc / PID / numa_maps,其中PID 是进程的ID,如图5.2所示。
00400000默认文件= / bin / cat映射= 3 N3 = 3 00504000默认文件= / bin / cat anon = 1脏= 1映射= 2 N3 = 2 00506000默认堆anon = 3脏= 3活动= 0 N3 = 3 38a9000000默认文件= / lib64 / ld-2.4.so映射= 22 mapmax = 47 N1 = 22 38a9119000默认文件= / lib64 / ld-2.4.so anon = 1脏= 1 N3 = 1 38a911a000默认文件= / lib64 / ld-2.4.so anon = 1脏= 1 N3 = 1 38a9200000默认文件= / lib64 / libc-2.4.so映射= 53 mapmax = 52 N1 = 51 N2 = 2 38a933f000默认文件= / lib64 / libc-2.4.so 38a943f000默认文件= / lib64 / libc-2.4.so anon = 1脏= 1映射= 3 mapmax = 32 N1 = 2 N3 = 1 38a9443000默认文件= / lib64 / libc-2.4.so anon = 1脏= 1 N3 = 1 38a9444000默认anon = 4脏= 4活动= 0 N3 = 4 2b2bbcdce000默认anon = 1脏= 1 N3 = 1 2b2bbcde4000默认anon = 2脏= 2 N3 = 2 2b2bbcde6000默认文件= / usr / lib / locale / locale-archive映射= 11 mapmax = 8 N0 = 11 7fffedcc7000默认堆栈anon = 2脏= 2 N3 = 2图5.2:/ proc / PID / numa_maps的内容
文件中的重要信息是N0到N3的值,它们表示为节点0到3上的内存区域分配的页数。可以很好地猜测该程序是在节点3的核心上执行的。本身和脏页分配在该节点上。只读映射(例如ld-2.4.so和 libc-2.4.so的第一个映射)以及共享文件的locale-archive被分配在其他节点上。
如图5.3所示,对于1跳和2跳读取,跨节点的读取性能分别下降了9%和30%。为了执行,需要进行此类读取,如果丢失了L2高速缓存,则每个高速缓存行都会产生这些额外的费用。如果内存远离处理器,则针对大型工作负载(超出缓存大小)测得的所有成本都必须增加9%/ 30%。
图5.4:在远程存储器上操作
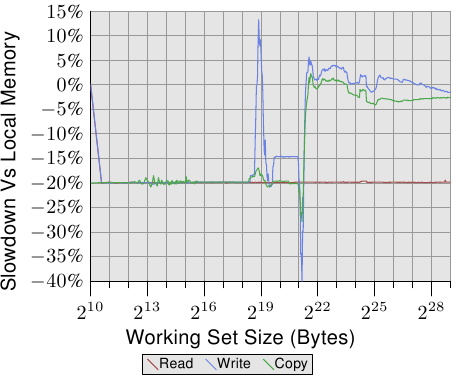
要查看现实世界中的影响,我们可以像第3.5.1节中所述测量带宽,但是这次将内存放在距离一跳的远程节点上。与使用本地内存的数据相比,该测试的结果如图5.4所示。数字在两个方向上都有一些大的尖峰,这是测量多线程代码的问题导致的,可以忽略。此图中的重要信息是读取操作始终慢20%。这比图5.3中的9%慢得多,后者很可能不是不间断的读/写操作的数字,并且可能是指较旧的处理器版本。只有AMD知道。
对于适合缓存的工作集大小,写入和复制操作的性能也会降低20%。对于超过缓存大小的工作集,写入性能不会比本地节点上的操作明显降低。互连的速度足够快以跟上内存的速度。主要因素是等待主内存所花费的时间。
内存第5部分:程序员可以做什么6程序员可以做什么
在前面几节中的描述之后,很明显,程序员有很多很多机会积极或消极地影响程序的性能。这仅适用于与内存相关的操作。我们将从最底层的物理RAM访问和L1高速缓存开始,直至影响操作系统的功能(包括影响内存处理的操作系统功能),从头开始涵盖所有机会。
6.1绕过缓存
当产生数据并且不再(立即)再次使用数据时,内存存储操作首先读取完整的缓存行,然后修改缓存的数据这一事实对性能有害。此操作将数据从高速缓存中推出,这可能需要再次使用,以支持即将不再使用的数据。这对于大型数据结构(例如矩阵)尤其如此,这些数据结构先被填充然后在以后使用。在填充矩阵的最后一个元素之前,绝对大小会将第一个元素逐出,使写入的缓存无效。
对于这种情况和类似情况,处理器为非临时写操作提供支持 。在这种情况下,非时间意味着数据将不会很快被重用,因此没有理由对其进行缓存。这些非临时写操作不会先读取高速缓存行,然后再对其进行修改。而是将新内容直接写入内存。
这听起来可能很昂贵,但不一定如此。处理器将尝试使用写合并(请参阅第3.3.3节)填充整个缓存行。如果此操作成功,则根本不需要内存读取操作。对于x86和x86-64体系结构,gcc提供了许多内在函数:
#include <emmintrin.h> void _mm_stream_si32(int * p,int a); void _mm_stream_si128(int * p,__m128i a); 无效_mm_stream_pd(double * p,__m128d a); #include <xmmintrin.h> 无效_mm_stream_pi(__ m64 * p,__m64 a); void _mm_stream_ps(float * p,__m128 a); #include <ammintrin.h> 无效_mm_stream_sd(double * p,__m128d a); void _mm_stream_ss(float * p,__m128 a);
如果这些指令一次处理大量数据,它们的使用效率最高。数据从内存中加载,经过一个或多个步骤进行处理,然后写回到内存中。数据“流”通过处理器,因此是内部函数的名称。
内存地址必须分别对齐8或16个字节。在使用多媒体扩展名的代码中,可以用这些非临时版本替换普通的_mm_store_ *内部函数。在9.1节中的矩阵乘法代码中,我们不这样做,因为写入的值会在很短的时间内被重用。这是使用流指令无用的示例。有关此代码的更多信息,请参见第6.2.1节。
处理器的写合并缓冲区只能将对缓存行的部分写请求保持这么长时间。通常有必要发出所有一条一条一条地修改一条高速缓存行的所有指令,以使写入合并实际上可以进行。如何执行此操作的示例如下:
#include <emmintrin.h> 无效的setbytes(char * p,int c) { __m128i i = _mm_set_epi8(c,c,c,c, c,c,c,c, c,c,c,c, c,c,c,c); _mm_stream_si128((__ m128i *)&p [0],i); _mm_stream_si128((__ m128i *)&p [16],i); _mm_stream_si128((__ m128i *)&p [32],i); _mm_stream_si128((__ m128i *)&p [48],i); }
假设指针p正确对齐,则对该函数的调用会将所寻址的缓存行的所有字节设置为c。写合并逻辑将看到生成的四个movntdq 指令,并且仅在执行完最后一条指令后才向内存发出写命令。总而言之,此代码序列不仅避免了在写入之前读取缓存行,而且还避免了用很快可能不需要的数据污染缓存。在某些情况下,这可以带来巨大的好处。使用此技术的日常代码的一个示例是C运行时中的 memset函数,对于大型块,应使用类似于上面的代码序列。
一些体系结构提供专门的解决方案。PowerPC体系结构定义了dcbz指令,该指令可用于清除整个缓存行。该指令实际上并未绕过高速缓存,因为已为结果分配了高速缓存行,但是没有从内存中读取任何数据。它比非临时存储指令有更多限制,因为高速缓存行只能设置为全零,并且会污染高速缓存(如果数据是非临时的),但是不需要写合并逻辑来实现。结果。
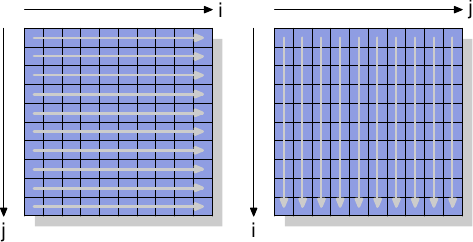
为了查看非时间指令的实际效果,我们将看一个新的测试,该测试用于测量以二维数组组织的矩阵的写入。编译器将矩阵布置在内存中,以便最左边的(第一个)索引寻址具有所有元素顺序排列在内存中的行。右(第二)索引处理一行中的元素。测试程序以两种方式遍历矩阵:首先通过增加内部循环中的列数,然后通过增加内部循环中的行索引。这意味着我们得到了如图6.1所示的行为。
图6.1:矩阵访问模式
我们测量初始化3000×3000矩阵所需的时间。要查看内存的行为,我们使用不使用缓存的存储指令。在IA-32处理器上,“非时间提示”用于此目的。为了进行比较,我们还测量了普通商店的运营情况。结果见表6.1。
内环增量 行 柱 正常 0.048秒 0.127秒 非临时性 0.048秒 0.160秒 表6.1:时序矩阵初始化
对于确实使用高速缓存的普通写入,我们看到了预期的结果:如果顺序使用内存,则将获得更好的结果,与几乎随机访问相比,整个操作为0.048s,转换为大约750MB / s这需要0.127s(约280MB / s)。矩阵足够大,以至于缓存实际上是无效的。
我们在此主要感兴趣的部分是绕过缓存的写入。令人惊讶的是,这里的顺序访问与使用缓存的情况下一样快。出现这种现象的原因是处理器正在执行如上所述的写合并。此外,放宽了非临时写入的内存排序规则:程序需要显式插入内存屏障(x86和x86-64处理器的防护指令)。这意味着处理器拥有更大的自由写回数据,从而尽可能地使用可用带宽。
在内部循环中按列访问时,情况有所不同。结果比缓存访问的情况要慢得多(0.16s,约225MB / s)。在这里我们可以看到不可能进行写合并,并且每个存储单元都必须单独寻址。这就需要不断地在RAM芯片中选择具有所有相关延迟的新行。结果比缓存的运行结果差25%。
在读取方面,直到最近,除了使用非临时访问(NTA)预取指令的弱提示之外,处理器都缺乏支持。没有等同于读取的写合并,这对于不可缓存的内存(例如内存映射的I / O)尤其不利。英特尔通过SSE4.1扩展引入了NTA负载。它们使用少量的流式负载缓冲区来实现。每个缓冲区包含一个缓存行。第一个movntdqa给定缓存行的指令会将一条缓存行加载到缓冲区中,可能会替换另一条缓存行。后续的16字节对齐访问同一高速缓存行将以很小的成本从加载缓冲区进行服务。除非有其他原因,否则高速缓存行将不会加载到高速缓存中,从而可以加载大量内存而不会污染高速缓存。编译器为此指令提供了一个内在函数:
#include <smmintrin.h> __m128i _mm_stream_load_si128(__m128i * p);
此内在函数应多次使用,并以16字节块的地址作为参数传递,直到读取每个高速缓存行。只有这样才能启动下一个缓存行。由于有一些流读取缓冲区,因此有可能一次从两个内存位置读取数据。
我们应该从该实验中删除的是,现代CPU可以很好地优化未缓存的写访问和(最近)读访问,只要它们是顺序的即可。处理仅使用一次的大型数据结构时,此知识会非常有用。其次,缓存可以帮助掩盖部分但不是全部的随机存储器访问成本。由于实现了RAM访问,本示例中的随机访问速度降低了70%。在实现更改之前,应尽可能避免随机访问。
在有关预取的部分中,我们将再次查看非时间标志。
6.2缓存访问
程序员在缓存方面可以做出的最重要的改进是那些会影响1级缓存的改进。在包含其他级别之前,我们将首先讨论它。显然,对1级缓存的所有优化也会影响其他缓存。所有内存访问的主题都是相同的:提高局部性(空间和时间)并对齐代码和数据。
6.2.1优化1级数据缓存访问
在3.3节中,我们已经看到有效使用L1d缓存可以提高性能的程度。在本节中,我们将显示哪些代码更改可以帮助提高性能。在上一节的基础上,我们首先专注于顺序访问内存的优化。如第3.3节中的数字所示,当顺序访问存储器时,处理器会自动预取数据。
使用的示例代码是矩阵乘法。我们使用两个1000×1000 双 元素的正方形矩阵。对于那些忘记了数学的人,给定两个矩阵A和B的元素a ij和b ij且0≤i,j <N,则乘积为
![[式]](https://img2020.cnblogs.com/blog/572188/202011/572188-20201117200111445-1653478378.png)
简单的C实现可以如下所示:
对于(i = 0; i <N; ++ i) 对于(j = 0; j <N; ++ j) 对于(k = 0; k <N; ++ k) res [i] [j] + = mul1 [i] [k] * mul2 [k] [j];
两个输入矩阵是mul1和mul2。假定结果矩阵res初始化为全零。这是一个很好且简单的实现。但是很明显,我们确实具有图6.1中解释的问题。当 mul1被顺序访问时,内部循环使mul2的行数前进。这意味着mul1的处理方式类似于图6.1中的左矩阵,而mul2的处理方式类似于右侧矩阵。不好
有一种可能的补救措施,可以轻松尝试。由于矩阵中的每个元素都会被多次访问,因此在使用第二矩阵mul2之前,有必要重新排列(用数学术语来说是“转置”) 。
![[式]](https://img2020.cnblogs.com/blog/572188/202011/572188-20201117200111455-1018475356.png)
转置后(传统上用上标“ T”表示),我们现在依次遍历两个矩阵。就C代码而言,现在看起来像这样:
双tmp [N] [N]; 对于(i = 0; i <N; ++ i) 对于(j = 0; j <N; ++ j) tmp [i] [j] = mul2 [j] [i]; 对于(i = 0; i <N; ++ i) 对于(j = 0; j <N; ++ j) 对于(k = 0; k <N; ++ k) res [i] [j] + = mul1 [i] [k] * tmp [j] [k];
我们创建一个临时变量来包含转置矩阵。这需要占用更多的内存,但是希望可以收回此成本,因为每列1000次非顺序访问的成本更高(至少在现代硬件上如此)。是时候进行一些性能测试了。时钟速度为2666MHz的Intel Core 2的结果为(以时钟周期为单位):
原版的 转置 周期数 16,765,297,870 3,922,373,010 相对的 100% 23.4%
通过矩阵的简单转换,我们可以实现76.6%的加速!复制操作已完成。1000次非顺序访问确实很痛苦。
下一个问题是这是否是我们能做的最好的事情。无论如何,我们当然需要一种不需要其他副本的替代方法。我们并不总是拥有执行复制的能力:矩阵可能太大,或者可用内存太小。
寻找替代实施方案应首先仔细检查所涉及的数学和原始实施方案所执行的操作。简单的数学知识使我们可以看到,只要每个加数恰好出现一次,对结果矩阵的每个元素进行加法的顺序就无关紧要。{我们在这里忽略算术效应,这可能会改变上溢,下溢或舍入的发生。}这种理解使我们能够寻找对原始代码的内循环中执行的添加进行重新排序的解决方案。
现在让我们检查一下原始代码执行中的实际问题。mul2元素的访问顺序为:(0,0),(1,0),...,(N-1,0),(0,1),(1,1),...。元素(0,0)和(0,1)位于同一高速缓存行中,但是,当内部循环完成一轮时,此高速缓存行早已被逐出。对于此示例,对于三个矩阵中的每个矩阵,内部循环的每一轮都需要1000个缓存行(对于Core 2处理器,需要64个字节)。这加起来比可用的L1d的32k要多得多。
但是,如果在执行内部循环时我们一起处理中间循环的两次迭代该怎么办?在这种情况下,我们使用高速缓存行中的两个double值,这些值保证在L1d中。我们将L1d错过率降低了一半。这当然是一种改进,但是,根据缓存行的大小,它可能仍然不如我们所能得到的好。Core 2处理器的L1d缓存行大小为64字节。实际值可以使用查询
sysconf(_SC_LEVEL1_DCACHE_LINESIZE)
在运行时或从命令行使用getconf实用程序,以便可以为特定的缓存行大小编译程序。随着 的sizeof(双)为8,这意味着,充分利用高速缓存行,我们应该展开环路中间的8倍。继续这种思想,同样要有效地使用res矩阵,即同时写入8个结果,我们也应该将外部循环展开8次。我们在这里假定大小为64的高速缓存行,但是该代码在具有32字节高速缓存行的系统上也能很好地工作,因为两条高速缓存行也都被100%使用。通常,最好使用getconf 实用程序在编译时对高速缓存行大小进行硬编码,如下所示:
gcc -DCLS = $(getconf LEVEL1_DCACHE_LINESIZE)...
如果二进制文件是通用的,则应使用最大的缓存行大小。对于非常小的L1ds,这可能意味着并非所有数据都适合高速缓存,但是此类处理器无论如何都不适合高性能程序。我们得到的代码如下所示:
#定义SM(CLS / sizeof(双精度)) 对于(i = 0; i <N; i + = SM) 对于(j = 0; j <N; j + = SM) 对于(k = 0; k <N; k + = SM) 对于(i2 = 0,rres =&res [i] [j], rmul1 =&mul1 [i] [k]; i2 <SM; ++ i2,rres + = N,rmul1 + = N) 对于(k2 = 0,rmul2 =&mul2 [k] [j]; k2 <SM; ++ k2,rmul2 + = N) 对于(j2 = 0; j2 <SM; ++ j2) rres [j2] + = rmul1 [k2] * rmul2 [j2];
这看起来很吓人。在某种程度上,这是但仅因为它包含了一些技巧。最明显的变化是我们现在有六个嵌套循环。外循环以SM的间隔进行迭代(缓存行大小除以sizeof(double))。这将乘法分为几个较小的问题,可以用更多的缓存局部性来处理。内部循环遍历外部循环的缺失索引。再有三个循环。这里唯一棘手的部分是k2和j2循环的顺序不同。这样做是因为在实际计算中,只有一个表达式取决于k2,而两个表达式取决于j2。
剩下的复杂性是由于gcc在优化数组索引方面不是很聪明。引入额外的变量rres,rmul1和 rmul2可以通过将公共表达式尽可能远地从内部循环中拉出来优化代码。C和C ++语言的默认别名规则不能帮助编译器做出这些决定(除非使用了限制,所有指针访问都是潜在的别名来源)。这就是为什么Fortran仍然是数字编程的首选语言:它使编写快速代码更加容易。{理论上,限制在1999年修订版中引入C语言的关键字应该可以解决该问题。但是,编译器尚未赶上。原因主要是存在太多不正确的代码,它们会误导编译器并导致其生成不正确的目标代码。}
表6.2列出了所有这些工作的回报方式。
原版的 转置 子矩阵 向量化 周期数 16,765,297,870 3,922,373,010 2,895,041,480 1,588,711,750 相对的 100% 23.4% 17.3% 9.47% 表6.2:矩阵乘法时序
通过避免复制,我们又获得了6.1%的性能。另外,我们不需要任何其他内存。只要结果矩阵也适合内存,输入矩阵就可以任意大。这是我们现已实现的一般解决方案的要求。
表6.2中还有一列未解释。如今,大多数现代处理器都对矢量化提供了特殊支持。这些特殊的指令通常被称为多媒体扩展名,它们允许同时处理2、4、8或更多值。这些通常是SIMD(单指令,多数据)操作,其他操作则对其进行了扩充,以获取正确格式的数据。英特尔处理器提供的SSE2指令可以处理两个 加倍一次操作中的值。指令参考手册列出了可访问这些SSE2指令的内在功能。如果使用了这些内在函数,则该程序将运行另外7.3%(相对于原始函数)的速度更快。结果是一个程序以原始代码的10%的时间运行。换算成人们可以识别的数字,我们从318 MFLOPS升至3.35 GFLOPS。由于这里我们只对内存效应感兴趣,因此程序代码被推送到9.1节中。
应该注意的是,在代码的最新版本中,mul2仍然存在一些缓存问题;预取仍然无法进行。但是,如果不对矩阵进行转置,这是无法解决的。也许高速缓存预取单元会变得更聪明以识别模式,那么就不需要进行其他更改。不过,在具有单线程代码的2.66 GHz处理器上的3.19 GFLOPS不错。
在矩阵乘法示例中,我们优化的是使用加载的缓存行。总是使用高速缓存行的所有字节。我们只是确保在撤消缓存行之前就已使用它们。这当然是特例。
具有填充一个或多个高速缓存行的数据结构更为常见,其中程序一次只使用几个成员。在图3.11中,我们已经看到如果只使用几个成员,则大型结构的效果。
图6.2:分布在多个缓存行中
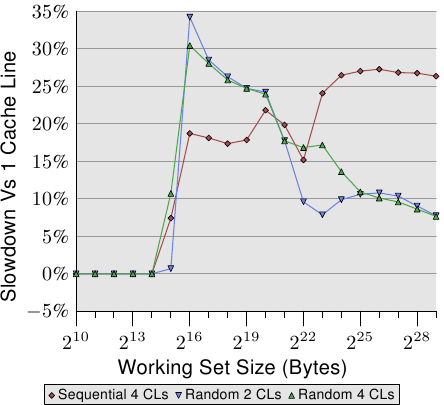
图6.2显示了使用目前众所周知的程序执行的另一组基准测试的结果。这次添加了相同列表元素的两个值。在一种情况下,两个元素都位于同一缓存行中;在另一种情况下,一个元素位于列表元素的第一行缓存中,第二个元素位于最后一个缓存行中。该图显示了我们正在经历的放慢脚步。
毫不奇怪,如果工作集适合L1d,则在所有情况下都不会产生负面影响。一旦L1d不再足够,将在处理中使用两条高速缓存行而不是一条,来支付罚款。红线显示列表在内存中的顺序排列时的数据。我们看到了通常的两个步骤模式:L2高速缓存足够时大约17%的损失,而必须使用主存储器时大约27%的损失。
在随机存储器访问的情况下,相对数据看起来有些不同。适用于L2的工作集的速度降低了25%至35%。除此之外,它下降到大约10%。这不是因为惩罚变小,而是因为实际内存访问的开销成比例地增加。数据还表明,在某些情况下,元素之间的距离确实很重要。随机4 CL曲线显示出更高的惩罚,因为使用了第一和第四缓存行。
与缓存行相比,查看数据结构布局的一种简单方法是使用pahole程序(请参阅[dwarves])。该程序检查以二进制形式定义的数据结构。采取一个包含此定义的程序:
struct foo { 诠释 长填充[7]; int b; };
pahole在64位计算机上编译,其输出包含(除其他外)图6.3中所示的信息。
struct foo { 诠释 / * 0 4 * / / * XXX 4个字节的空洞,请尝试打包* / 长整数填充[7];/ * 8 56 * / / * ---缓存行1边界(64字节)--- * / int b; / * 64 4 * / }; / *大小:72,高速缓存行:2 * / / *总和成员:64,孔:1,总和孔:4 * / / *填充:4 * / / *最后一个缓存行:8个字节* /图6.3:Pahole Run的输出
这个输出告诉我们很多。首先,它表明数据结构使用了多个缓存行。该工具假定当前使用的处理器的缓存行大小,但是可以使用命令行参数覆盖此值。特别是在结构的大小刚好超过高速缓存行的限制并且分配了许多此类对象的情况下,寻找一种压缩该结构的方法是有意义的。也许某些元素可以具有较小的类型,或者某些字段实际上是可以使用单个位表示的标志。
在该示例的情况下,压缩很容易,并且程序提示了压缩。输出显示在第一个元素之后有四个字节的空洞。该孔是由结构和填充元素的对齐要求引起的。显而易见,元素b的大小为4个字节(在行的末尾由4表示),完全适合间隙。在这种情况下,结果是间隙不再存在,并且数据结构适合一条高速缓存行。Pahole工具本身可以执行此优化。如果-重新组织使用参数并在命令行末尾添加结构名称,该工具的输出是优化的结构和缓存行的使用。除了移动元素以填充间隙外,该工具还可以优化位场并将填充和孔合并。有关更多详细信息,请参见[矮人]。
当然,理想的情况是有一个足够大的孔供尾随元件使用。为了使此优化有用,需要将对象本身与高速缓存行对齐。我们稍作讨论。
通过pahole输出,还可以更轻松地确定是否必须重新排序元素,以便将一起使用的那些元素也存储在一起。使用pahole工具,可以轻松地确定哪些元素在同一高速缓存行中,以及何时必须重新组合元素才能实现此目的。这不是一个自动过程,但是该工具可以提供很多帮助。
各个结构元素的位置及其使用方式也很重要。正如我们在3.5.2节中所看到的那样,在高速缓存行中带有关键单词的代码的性能更差。这意味着程序员应始终遵循以下两个规则:
始终将最有可能成为关键字的结构元素移到结构开头。
当访问数据结构时,访问顺序不受情况的限制,请按在结构中定义元素的顺序访问元素。
对于小型结构,这意味着程序员应按可能访问元素的顺序排列元素。必须以灵活的方式处理此问题,以允许同时应用其他优化,例如填充孔。对于更大的数据结构,每个缓存行大小的块都应按照规则进行排列。
但是,如果对象本身未对齐,则不值得花费时间进行重新排序。对象的对齐方式由数据类型的对齐要求决定。每个基本类型都有其自己的对齐要求。对于结构化类型,其任何元素的最大对齐要求决定了结构的对齐方式。这几乎总是小于高速缓存行的大小。这意味着即使将结构的成员对齐以适合同一高速缓存行,分配的对象也可能没有与高速缓存行大小匹配的对齐方式。有两种方法可以确保对象具有设计结构布局时使用的对齐方式:
- 可以为对象分配明确的对齐要求。对于动态分配,对malloc的调用只会分配对齐方式与最苛刻的标准类型(通常为long double)相匹配的对象。不过,可以使用posix_memalign来请求更高的对齐方式。
#include <stdlib.h> int posix_memalign(void ** memptr, size_t对齐, size_t大小);
该函数在memptr指向的指针变量中存储指向新分配的内存的指针。内存块的 大小为字节大小,并在align- byte边界上对齐。
对于由编译器分配的对象(在.data,.bss等中以及在堆栈上),可以使用变量属性:
struct strtype变量 __attribute((aligned(64)));
在这种情况下,无论strtype 结构的对齐要求如何,变量都在64字节边界对齐。这适用于全局变量以及自动变量。
但是,此方法不适用于数组。除非每个数组元素的大小是对齐值的倍数,否则只有数组的第一个元素会对齐。这也意味着必须对每个变量进行适当的注释。posix_memalign的使用 也不是完全免费的,因为对齐要求通常会导致碎片和/或更高的内存消耗。
- 可以使用type属性来更改类型的对齐要求:
struct strtype { ...成员... } __attribute((aligned(64)));
这将导致编译器以适当的对齐方式分配所有对象,包括数组。但是,程序员必须注意为动态分配的对象请求适当的对齐方式。在此 必须再次使用posix_memalign。使用gcc提供的alignof运算符很容易,并将值作为第二个参数传递给posix_memalign。
本节前面提到的多媒体扩展几乎总是要求对齐内存访问。即,对于16字节内存访问,地址应为16字节对齐。x86和x86-64处理器具有内存操作的特殊变体,可以处理未对齐的访问,但速度较慢。对于大多数要求对所有内存访问进行完全对齐的RISC体系结构,这种硬对齐要求并不是什么新鲜事。即使架构支持不对齐的访问,这有时也比使用适当的对齐要慢,特别是如果不对齐导致装入或存储使用两条缓存行而不是一条缓存行。
图6.4:未对齐访问的开销
图6.4显示了未对齐的内存访问的影响。现在测量的众所周知的测试是在访问内存(顺序或随机)时增加数据元素,一次是使用对齐的列表元素,一次是使用故意错位的元素。该图显示了由于未对齐访问而导致程序减速的情况。对于顺序访问的情况,其影响要比对随机情况的影响更为显着,因为在后一种情况下,未对齐访问的成本部分被通常较高的内存访问成本所掩盖。在顺序情况下,对于确实适合L2高速缓存的工作集大小,减速速度约为300%。这可以通过降低L1缓存的有效性来解释。现在,某些增量操作会涉及两条缓存行,并且现在开始处理列表元素通常需要读取两条缓存行。L1和L2之间的连接太拥塞了。
对于非常大的工作集大小,未对齐访问的影响仍然是20%到30%-考虑到这些大小的对齐访问时间很长,这是很大的。该图应表明必须认真对待对齐。即使架构支持未对齐的访问,也不能将其视为“它们与对齐的访问一样好”。
但是,这些对齐要求会有一些影响。如果自动变量具有对齐要求,则编译器必须确保在所有情况下都满足该要求。这不是小菜一碟,因为编译器无法控制调用站点及其处理堆栈的方式。此问题可以通过两种方式处理:
- 生成的代码主动对齐堆栈,并在必要时插入间隙。这需要代码检查对齐方式,创建对齐方式,然后撤消对齐方式。
- 要求所有调用方的堆栈对齐。
所有常用的应用程序二进制接口(ABI)都遵循第二条路线。如果调用者违反规则并且需要在被调用者中进行对齐,则程序可能会失败。但是,保持对齐完整并非免费的。
函数中使用的堆栈框架的大小不一定是对齐的倍数。这意味着,如果从此堆栈帧中调用其他功能,则需要填充。最大的区别是,在大多数情况下,编译器都知道堆栈帧的大小,因此,它知道如何调整堆栈指针以确保与从该堆栈帧调用的任何函数对齐。实际上,大多数编译器只会将堆栈帧的大小四舍五入并用它来完成。
如果使用可变长度数组(VLA)或alloca,则无法使用这种简单的对齐方式。在这种情况下,仅在运行时才知道堆栈帧的总大小。在这种情况下,可能需要主动对齐控制,从而使生成的代码(稍微)变慢。
在某些架构上,只有多媒体扩展才需要严格的对齐。这些架构上的堆栈对于常规数据类型始终保持最小对齐,对于32位和64位架构,通常分别为4或8字节对齐。在这些系统上,执行对齐会产生不必要的成本。这意味着,在这种情况下,如果我们知道它从来都不依赖于此,我们可能希望摆脱严格的对齐要求。不执行多媒体操作的尾部功能(不调用其他功能的功能)不需要对齐。仅调用不需要对齐的函数的函数也不执行。如果可以识别出足够大的功能集,则程序可能希望放宽对齐要求。对于x86二进制文件,gcc支持宽松的堆栈对齐要求:
-mpreferred-stack-boundary = 2
如果此选项的值为N,则堆栈对齐要求将设置为2 N个字节。因此,如果使用值2,则堆栈对齐要求将从默认值(16字节)减少到仅4字节。在大多数情况下,这意味着不需要额外的对齐操作,因为正常的堆栈压入和弹出操作始终在四字节边界上进行。此特定于机器的选项可以帮助减小代码大小并提高执行速度。但是它不能应用于许多其他体系结构。即使对于x86-64,它也通常不适用,因为x86-64 ABI要求在SSE寄存器中传递浮点参数,并且SSE指令需要完整的16字节对齐。但是,只要可以使用该选件,它就会产生显着的不同。
结构元素的有效放置和对齐并不是影响高速缓存效率的数据结构的唯一方面。如果使用结构数组,则整个结构定义都会影响性能。记住图3.11中的结果:在这种情况下,数组元素中的未使用数据量不断增加。结果是预取的效率越来越低,而针对大数据集的程序的效率也越来越低。
对于大型工作集,尽可能使用可用的缓存非常重要。为此,可能需要重新排列数据结构。尽管程序员可以更轻松地将概念上属于同一类别的所有数据放到同一数据结构中,但这可能不是实现最佳性能的最佳方法。假设我们的数据结构如下:
结构顺序{ 双重价格; 布尔付款; const char * buyer [5]; 长buyer_id; };
进一步假设这些记录存储在一个很大的阵列中,并且频繁运行的工作加起来了所有未付票据的预期付款。在这种情况下,用于存储 买方和buyer_id字段被不必要地加载到高速缓存。从图3.11中的数据来看,该程序的性能可能比其性能差5倍。
最好将订单数据结构一分为二,将前两个字段存储在一个结构中,将其他字段存储在其他位置。这种变化肯定会增加程序的复杂性,但是性能的提高可能证明了这一成本的合理性。
最后,让我们考虑另一个缓存使用优化,该优化同时也适用于其他缓存,主要体现在L1d访问中。如图3.8所示,增加的缓存关联性有利于正常操作。高速缓存越大,通常关联性越高。L1d高速缓存太大,无法完全关联,但不足以与L2高速缓存具有相同的关联性。如果工作集中的许多对象都属于同一缓存集,则可能会出现问题。如果由于过度使用集合而导致逐出,即使许多缓存未使用,程序也可能会遇到延迟。这些高速缓存未命中有时称为 冲突未命中。由于L1d寻址使用虚拟地址,因此程序员实际上可以控制这些地址。如果一起使用的变量也一起存储,则将它们归入同一集合的可能性降到最低。图6.5显示了问题解决的速度。
图6.5:缓存关联性影响
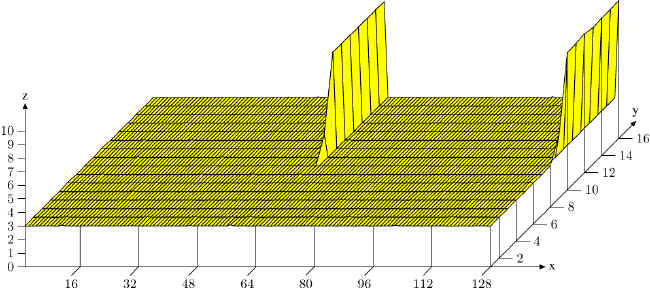
在图中,现在熟悉的Follow {该测试是在32位计算机上执行的,因此NPAD = 15表示每个列表元素一个64字节的缓存行。}在NPAD = 15的情况下,测试是通过特殊设置进行的。X轴是两个列表元素之间的距离,以空列表元素为单位。换句话说,距离2意味着下一个元素的地址是前一个元素之后的128个字节。所有元素都以相同的距离布置在虚拟地址空间中。Y轴显示列表的总长度。仅使用1到16个元素,这意味着工作集的总大小为64到1024字节。z轴显示遍历每个列表元素所需的平均循环数。
图中显示的结果不足为奇。如果使用的元素很少,则所有数据都适合L1d,每个列表元素的访问时间仅为3个周期。对于列表元素的几乎所有排列都是如此:虚拟地址很好地映射到了L1d插槽,几乎没有冲突。有两个(在此图中)情况不同的特殊距离值。如果该距离是4096字节的倍数(即64个元素的距离)并且列表的长度大于8,则每个列表元素的平均循环数将急剧增加。在这些情况下,所有条目都在同一集合中,并且一旦列表长度大于关联性,就会从L1d刷新条目,并在下一轮必须从L2重新读取。这导致每个列表元素大约花费10个周期。
通过此图,我们可以确定所使用的处理器具有L1d高速缓存,其关联性为8,总大小为32kB。这意味着该测试可以在必要时用于确定这些值。对于L2高速缓存,可以测量相同的效果,但是在这里,由于使用物理地址对L2高速缓存进行索引并且它更大,因此更为复杂。
对于程序员来说,这意味着关联性值得关注。在现实世界中,经常在以2的幂表示的边界上放置数据经常会发生,但这正是这种情况,很容易导致上述影响并降低性能。未对齐的访问可能会增加冲突遗漏的可能性,因为每次访问可能都需要一条额外的缓存行。
图6.6:AMD上L1d的银行地址

如果执行此优化,则也可以进行其他相关的优化。至少AMD的处理器将L1d实施为几个单独的存储库。L1d可以在每个周期接收两个数据字,但前提是两个字都存储在不同的存储区中或具有相同索引的存储区中。存储区地址被编码在虚拟地址的低位,如图6.6所示。如果一起使用的变量也一起存储,则它们位于不同库或具有相同索引的同一库的可能性很高。
6.2.2优化1级指令缓存访问
为良好的L1i使用准备代码需要与良好的L1d使用类似的技术。问题是,尽管如此,程序员通常不会直接影响使用L1i的方式,除非他/她在汇编器中编写代码。如果使用编译器,则程序员可以通过指导编译器创建更好的代码布局来间接确定L1i的使用。
代码的优点是跳转之间是线性的。在这些期间,处理器可以有效地预取内存。跳跃打乱了这张漂亮的照片,因为
- 跳转目标可能不是静态确定的;
- 即使它是静态的,如果丢失所有缓存,内存提取也可能需要很长时间。
这些问题会在执行过程中造成停顿,并可能严重影响性能。这就是为什么当今的处理器在分支预测(BP)上进行大量投资的原因。高度专业化的BP单元试图确定尽可能远的跳转目标,以便处理器可以启动将新位置的指令加载到缓存中。它们使用静态和动态规则,并且越来越擅长确定执行模式。
对于指令高速缓存而言,尽快将数据移入高速缓存更为重要。如第3.1节所述,在执行指令之前必须先对其进行解码,并且为了加快执行速度(在x86和x86-64上非常重要),指令实际上是以解码形式而不是从读取的字节/字形式缓存的记忆。
为了获得最佳的L1i使用率,程序员应该至少注意以下几方面的代码生成:
- 尽可能减少代码占用量。这必须与诸如循环展开和内联之类的优化相平衡。
- 代码执行应该是线性的,没有气泡。{气泡以图形方式描述了处理器管道中执行中的漏洞,这些漏洞在执行必须等待资源时出现。有关更多详细信息,请读者阅读有关处理器设计的文献。}
- 在合理的情况下对齐代码。
现在,我们将研究一些可用于根据这些方面帮助优化程序的编译器技术。
编译器具有启用优化级别的选项。特定的优化也可以单独启用。在高优化级别启用的许多优化(对于gcc为-O2和-O3)都涉及循环优化和函数内联。通常,这些是很好的优化。如果以这些方式优化的代码占了程序总执行时间的很大一部分,则可以提高整体性能。特别地,函数内联允许编译器一次优化更大的代码块,从而能够生成机器代码,从而更好地利用处理器的流水线体系结构。代码和数据的处理(通过消除无效代码或传播值范围,
较大的代码大小意味着对L1i(以及L2和更高级别)高速缓存的压力更高。这会导致性能降低。较小的代码可以更快。幸运的是,gcc有一个优化选项可以指定此选项。如果使用-Os,则编译器将优化代码大小。已知会增加代码大小的优化被禁用。使用此选项通常会产生令人惊讶的结果。特别是如果编译器不能真正利用循环展开和内联的优势,那么此选项将是一个大赢家。
内联也可以单独控制。编译器具有指导内联的启发式方法和限制。这些限制可以由程序员控制。-finline-limit选项指定必须考虑多大的函数才能进行内联。如果在多个位置调用一个函数,则在所有位置内联该函数会导致代码大小激增。但是还有更多。假设函数inlcand在两个函数f1和f2中被调用。函数f1和f2 本身被依次调用。
带内联 没有内联 表6.3:内联VS不
表6.3显示了在没有内联和两个函数都内联的情况下生成的代码的外观。如果在f1和f2中都内联函数 inlcand,则生成的代码的总大小为:
尺寸f1 +尺寸f2 + 2×尺寸inlcand
如果没有内联发生,则总大小将减小inlcand大小。如果紧接着又调用f1和f2,则需要多少L1i和L2高速缓存。加:如果未内联inlcand,则代码可能仍在L1i中,并且无需再次解码。另外:分支预测单元可能已经对代码进行了预测,因此可以更好地预测跳转。如果编译器默认的内联函数大小上限不是最适合该程序的值,则应降低该值。
但是,在某些情况下,内联总是有意义的。如果一个函数仅被调用一次,则最好内联。这为编译器提供了执行更多优化的机会(例如值范围传播,这可能会大大改善代码)。选择限制可能会阻止该内联。在这种情况下,gcc有一个选项可以指定始终内联函数。添加always_inline函数属性将指示编译器完全按照名称的建议进行操作。
在相同的上下文中,如果尽管函数足够小也不能内联,则可以使用noinline函数属性。即使经常从不同地方调用小功能,使用此属性也很有意义。如果可以重复使用L1i内容并且减少了总体占用空间,那么这通常可以弥补额外函数调用的额外费用。如今,分支预测单位非常好。如果内联可以导致更积极的优化,则情况将有所不同。这是必须根据具体情况决定的。
该always_inline属性效果很好,如果一直使用内嵌代码。但是,如果不是这种情况怎么办?如果仅偶尔调用内联函数怎么办:
无效fct(void){ ...代码块A ... 如果(条件) inlfct() ...代码块C ... }
通常为这种代码序列生成的代码与源的结构匹配。这意味着首先是代码块A,然后是条件跳转,如果条件为假,则条件跳转将向前跳转。接下来是为内联的inlfct生成的代码,最后是代码块C。这看起来很合理,但是有问题。
如果条件经常为假,则执行不是线性的。中间有很多未使用的代码,这不仅会由于预取而污染L1i,还会导致分支预测问题。如果分支预测错误,则条件表达式的效率可能非常低。
这是一个普遍的问题,并不特定于内联函数。每当使用条件执行时,条件执行就会出现偏差(即,该表达式比另一个结果更容易导致一个结果),则可能会出现错误的静态分支预测,从而在管道中产生泡沫。这可以通过告诉编译器将执行频率较低的代码移出主代码路径来防止。在这种情况下,为if语句生成的条件分支将跳到顺序之外的位置,如下图所示。

上部代表简单的代码布局。如果区域B(例如由上面的内联函数inlfct生成的)由于条件I跳过而通常不执行,则处理器的预取将拉入包含很少使用的块B的缓存行。使用块重新排序可以更改,其结果可以在图的下部看到。经常执行的代码在内存中是线性的,而很少执行的代码被移动到不会损害预取和L1i效率的位置。
gcc提供了两种方法来实现此目的。首先,编译器可以在重新编译代码时考虑分析输出,并根据配置文件对代码块进行布局。我们将在第7节中看到它的工作方式。第二种方法是通过显式分支预测。gcc识别__builtin_expect:
long __builtin_expect(long EXP,long C);
这种结构告诉编译器,表达EXP最有可能将具有值Ç。返回值为EXP。 __builtin_expect旨在用于条件表达式中。在几乎所有情况下,都将在布尔表达式的上下文中使用它,在这种情况下,定义两个帮助程序宏将更加方便:
#定义不太可能的(expr)__ builtin_expect(!!(expr),0) #定义可能性(expr)__builtin_expect(!!(expr),1)
然后可以将这些宏用作
如果(可能(a> 1))
如果程序员利用这些宏,然后使用 -freorder-blocks优化选项,则gcc将对块进行重新排序,如上图所示。-O2启用了此选项,而-Os禁用了此选项。还有另一种对块进行重新排序的选项(-freorder-blocks-and-partition),但是它的用途有限,因为它不适用于异常处理。
至少在某些处理器上,小循环还有另一个很大的优势。英特尔酷睿2前端具有一项特殊功能,称为环路流检测器(LSD)。如果一个循环中的指令不超过18条(都不是对子程序的调用),则最多只需要4次解码器读取16个字节,最多具有4条分支指令,并且执行比循环多64次。有时被锁定在指令队列中,因此当再次使用循环时可以更快地使用。例如,这适用于通过外部循环多次输入的小的内部循环。即使没有这样的专用硬件,紧凑循环也具有优势。
内联不是关于L1i优化的唯一方面。另一个方面是对齐,就像数据一样。有明显的区别:代码是一个主要是线性的Blob,不能随意放置在地址空间中,并且在编译器生成代码时,它不能直接受到程序员的影响。但是,程序员可以控制某些方面。
对齐每条指令没有任何意义。目的是使指令流是顺序的。因此,仅在战略性位置才有意义。要决定在何处添加路线,必须了解其优点。在高速缓存行的开头有一条指令{对于某些处理器,高速缓存行不是指令的原子块。英特尔酷睿2前端向解码器发出16个字节的块。它们已适当对齐,因此没有已发布的块可以跨越缓存行边界。在高速缓存行的开头对齐仍然具有优势,因为它可以优化预取的积极效果。}表示高速缓存行的预取已最大化。对于指令,这也意味着解码器更有效。显而易见,如果执行了高速缓存行末尾的指令,则处理器必须准备好读取新的高速缓存行并解码指令。有些事情可能出错(例如高速缓存行未命中),这意味着平均而言,高速缓存行末尾的指令执行效率不如开始时有效。
将其与后续推论相结合,即如果将控制权仅仅转移到有问题的指令上,则问题将最为严重(因此预取是无效的),我们得出了最后的结论,其中代码的对齐最有用:
- 在功能开始时;
- 在仅通过跳跃达到的基本块的开始处;
- 在某种程度上,在循环的开始。
在前两种情况下,对齐花费很少。执行在新位置进行,如果我们选择它在高速缓存行的开头,则会优化预取和解码。{对于指令解码处理器,x86和x86-64通常使用比高速缓存行更小的单元,即16个字节。}编译器通过插入一系列无操作指令来填补对齐代码所产生的空白,从而完成对齐。此“死代码”占用的空间很小,但通常不会影响性能。
第三种情况略有不同:对齐每个循环的开始可能会导致性能问题。问题是循环的开始通常会顺序地跟随其他代码。如果情况不是很幸运,则前一条指令与对齐的循环开始之间将存在间隙。与前两种情况不同,这种差距不能完全消除。执行上一条指令后,必须执行循环中的第一条指令。这意味着,按照前一条指令,必须有许多无操作指令来填补空白,或者必须无条件地跳转到循环的开始。两种可能性都不是免费的。特别是如果循环本身不经常执行,则通过对齐循环,无操作或跳转可能节省的成本不止一次。
程序员可以通过三种方式影响代码的对齐。显然,如果代码是用汇编器编写的,则函数及其中的所有指令都可以显式对齐。汇编程序为所有体系结构提供.align伪操作。对于高级语言,必须告知编译器对齐要求。与数据类型和变量不同,这在源代码中是不可能的。而是使用编译器选项:
-falign-functions = N
此选项指示编译器将所有函数与下一个大于N的2的幂的边界对齐。这意味着将创建最多N个字节的间隙。对于较小的函数,使用较大的N值是浪费的。同样,对于很少执行的代码。后者在包含流行和不太流行的接口的库中经常发生。通过明智地选择选项值,可以避免对齐,从而加快速度或节省内存。通过使用一个作为N的值或使用-fno-align-functions选项关闭所有对齐。
上面第二种情况的对齐方式(先后顺序未到达的基本块的对齐方式)可以使用其他选项进行控制:
-falign-jumps = N
所有其他详细信息都是等效的,关于内存浪费的相同警告也适用。
第三种情况也有自己的选择:
-falign-loops = N
同样,同样的细节和警告也适用。除此以外,如前所述,对齐要花费运行时间,因为如果顺序到达对齐的地址,则必须执行无操作或跳转指令。
gcc知道了另一个控制对齐的选项,此处仅出于完整性目的而提及。 -falign-labels对齐代码中的每个单个标签(基本上是每个基本块的开头)。除了少数例外情况,这会减慢代码的速度,因此不应使用。
6.2.3优化2级和更高级别的缓存访问
关于使用1级缓存进行优化的所有说明也适用于2级及更高级别的缓存访问。最后一级缓存还有两个其他方面:
- 高速缓存未命中总是非常昂贵的。虽然L1命中(希望)频繁命中L2和更高的缓存,从而限制了惩罚,但最后一级缓存显然没有后退。
- L2高速缓存和更高级别的高速缓存通常由多个内核和/或超线程共享。因此,每个执行单元可用的有效缓存大小通常小于总缓存大小。
为避免高速缓存未命中的高成本,工作集大小应与高速缓存大小匹配。如果仅需要一次数据,则显然没有必要,因为无论如何缓存将无效。我们谈论的是不止一次需要数据集的工作负载。在这种情况下,使用太大而无法放入高速缓存的工作集将产生大量的高速缓存未命中,即使成功执行了预取操作,也会使程序变慢。
即使数据集太大,程序也必须执行其工作。以最小化缓存未命中的方式完成这项工作是程序员的工作。对于最后一级的高速缓存,这与L1高速缓存一样,可以通过较小的工作量来实现。这与表6.2的优化矩阵乘法非常相似。但是,一个区别是,对于最后一级的高速缓存,要处理的数据块可能更大。如果还需要L1优化,则代码变得更加复杂。想象一下矩阵乘法,其中数据集(两个输入矩阵和输出矩阵)不一起容纳在最后一级缓存中。在这种情况下,同时优化L1和最后一级缓存访问可能是合适的。
L1缓存行大小通常在许多代处理器中都是恒定的。即使不是,差异也会很小。假设更大的尺寸没什么大问题。在具有较小高速缓存大小的处理器上,将使用两个或多个高速缓存行,而不是一个。无论如何,对高速缓存行大小进行硬编码并为此优化代码是合理的。
对于高级缓存,如果程序是通用的,则不是这种情况。这些缓存的大小可以相差很大。八分之一或更多的因子并不少见。无法将更大的缓存大小作为默认值,因为这将意味着代码在所有具有最大缓存的机器上均无法正常运行。相反的选择也很糟糕:假设最小的缓存意味着丢弃87%或更多的缓存。这不好; 从图3.14中可以看到,使用大型缓存会对程序的速度产生巨大影响。
这意味着代码必须动态调整自身以适应缓存行大小。这是针对该程序的优化。我们在这里只能说程序员应该正确计算程序的需求。不仅需要数据集本身,更高级的高速缓存还用于其他目的。例如,所有已执行的指令均从缓存中加载。如果使用库函数,则此缓存使用量可能总计很大。这些库函数可能还需要自己的数据,这进一步减少了可用内存。
一旦有了内存需求的公式,就可以将其与缓存大小进行比较。如前所述,缓存可能与其他多个内核共享。目前{肯定会有一个更好的方法!}在没有硬编码知识的情况下获取正确信息的唯一方法是通过/ sys 文件系统。在表5.2中,我们看到了内核发布的有关硬件的内容。程序必须找到目录:
/ sys / devices / system / cpu / cpu * / cache
用于最后一级缓存。可以通过该目录中级别文件中的最高数值来识别。确定目录后,程序应读取该目录中大小文件的内容,并将 数值除以文件shared_cpu_map中位掩码中设置的位数。
以这种方式计算的值是安全的下限。有时程序对其他线程或进程的行为了解更多。如果这些线程是在共享高速缓存的核心或超线程上调度的,并且已知高速缓存使用情况并未耗尽其在总高速缓存大小中所占的比例,则计算出的限制可能太低而无法达到最佳。是否应使用比公平份额更多的钱确实取决于情况。程序员必须做出选择,或者必须允许用户做出决定。
6.2.4优化TLB使用率
TLB使用情况有两种优化。第一个优化是减少程序必须使用的页面数。这自动导致更少的TLB丢失。第二个优化是通过减少必须分配的更高级别目录表的数量来使TLB查找更便宜。较少的表意味着较少的内存使用,这可能导致目录查找的高速缓存命中率更高。
第一个优化与页面错误的最小化紧密相关。我们将在7.5节中详细介绍该主题。尽管页面错误通常是一次性的代价,但考虑到TLB缓存通常很小并且经常刷新,TLB丢失是永久的代价。页面错误比TLB丢失的代价高出几个数量级,但是,如果程序运行时间足够长,并且该程序的某些部分执行得足够频繁,则TLB丢失甚至会超过页面错误的成本。因此,重要的是不仅要从页面错误的角度来考虑页面优化,而且还要从TLB未命中的角度来考虑页面优化。区别在于,虽然页面错误优化仅需要对代码和数据进行页面范围的分组,但是TLB优化需要在任何时间点使用尽可能少的TLB条目。
第二个TLB优化甚至更难控制。必须使用的页面目录的数量取决于在进程的虚拟地址空间中使用的地址范围的分布。地址空间中变化很大的位置意味着更多的目录。复杂的是地址空间布局随机化(ASLR)会导致这些情况。堆栈,DSO,堆以及可能的可执行文件的加载地址在运行时被随机分配,以防止机器的攻击者猜测功能或变量的地址。
为了获得最佳性能,ASLR当然应该被关闭。但是,额外目录的成本足够低,因此,除了极少数极端情况之外,几乎无需执行此步骤。内核可以随时执行的一种可能的优化是确保单个映射不会跨越两个目录之间的地址空间边界。这将以最小的方式限制ASLR,但不足以大大削弱它。
程序员直接受此影响的唯一方法是显式请求地址空间区域。将mmap 与MAP_FIXED结合使用时会发生这种情况。这样分配新的地址空间区域非常危险,而且几乎从未做过。但是有可能,并且,如果使用了它,程序员应该知道最后一级页面目录的边界,并适当地选择所请求的地址。
6.3预取
预取的目的是隐藏内存访问的延迟。当今处理器的命令管道和无序(OOO)执行功能可以隐藏一些延迟,但充其量仅适用于访问高速缓存的访问。为了覆盖主内存访问的延迟,命令队列必须非常长。一些没有OOO的处理器试图通过增加内核数来进行补偿,但这是一个不好的交易,除非使用中的所有代码都并行化。
预取可以进一步帮助隐藏延迟。处理器自行执行预取,由某些事件触发(硬件预取)或由程序明确请求(软件预取)。
6.3.1硬件预取
硬件预取的触发器通常是按特定模式的两个或多个高速缓存未命中的序列。这些高速缓存未命中可能是后续的或先前的高速缓存行。在旧的实现中,仅识别到相邻缓存行的缓存未命中。使用现代硬件,也可以识别跨步,这意味着跳过固定数量的高速缓存行被视为一种模式并得到了适当处理。
如果每个高速缓存未命中都会触发硬件预取,这将对性能造成不利影响。随机存储器访问(例如对全局变量的访问)非常普遍,并且由此产生的预取将大部分浪费FSB带宽。这就是为什么要启动预取,至少需要两个高速缓存未命中的原因。如今,所有处理器都期望内存访问流不止一个。处理器尝试将每个高速缓存未命中自动分配给此类流,如果达到阈值,则开始硬件预取。当今的CPU可以跟踪八到十六个单独的流,以获取更高级别的缓存。
负责模式识别的单元与相应的缓存关联。L1d和L1i缓存可以有一个预取单元。L2高速缓存和更高版本可能有一个预取单元。L2和更高的预取单元使用同一缓存与所有其他核心和超线程共享。因此,可以迅速减少八到十六个独立流的数量。
预取有一个很大的缺点:它不能跨越页面边界。当人们意识到CPU支持需求分页时,原因应该显而易见。如果允许预取器跨越页面边界,则访问可能会触发OS事件以使页面可用。这本身可能是不好的,尤其是对于性能而言。更糟糕的是,预取程序不了解程序或OS本身的语义。因此,它可能会预取在现实生活中永远不会被请求的页面。这意味着预取器将以可识别的模式经过处理器访问过的存储区域的末端。这不仅可能,而且很有可能。如果处理器作为预取的副作用,
因此,重要的是要认识到,无论预取器在预测模式方面有多好,程序都会在页面边界遇到高速缓存未命中的情况,除非它明确地预取或从新页面读取。这是优化数据布局的另一个原因,如第6.2节所述,可通过将无关数据拒之门外来最大程度地减少缓存污染。
由于页面限制,处理器没有非常复杂的逻辑来识别预取模式。在仍然占主导地位的4k页面大小中,只有这么多才有意义。多年来,可以识别跨步的地址范围已经增加,但是超出当今经常使用的512字节窗口可能没有多大意义。当前,预取单元无法识别非线性访问模式。这样的模式很可能是真正随机的,或者至少是足够不重复的,以至于试图识别它们是没有意义的。
如果意外触发了硬件预取,则只能执行很多操作。一种可能性是尝试检测此问题并稍微更改数据和/或代码布局。这可能很难证明。可能会有一些特殊的本地化解决方案,例如使用 ud2指令{或非指令。这是推荐的未定义操作码。在x86和x86-64处理器上。该指令本身不能执行,可在间接跳转指令之后使用。它被用作向指令提取器发送的信号,表明处理器不应浪费精力解码后续的存储器,因为执行将在其他位置继续进行。但是,这是一个非常特殊的情况。在大多数情况下,必须忍受这一问题。
可以完全或部分禁用整个处理器的硬件预取。在Intel处理器上,为此使用了模型专用寄存器(MSR)(IA32_MISC_ENABLE,许多处理器上的位9;位19仅禁用相邻的高速缓存行预取)。在大多数情况下,由于这是特权操作,因此必须在内核中发生。如果性能分析表明在系统上运行的重要应用程序由于硬件预取而遭受带宽耗尽和缓存过早驱逐,则可以使用此MSR。
6.3.2软件预取
硬件预取的优点是不必调整程序。正如刚刚描述的那样,缺点是访问模式必须是琐碎的,并且预取不能跨越页面边界发生。由于这些原因,我们现在有了更多的可能性,软件预取了其中最重要的可能性。软件预取确实需要通过插入特殊指令来修改源代码。一些编译器支持编译指示或多或少地自动插入预取指令。在x86和x86-64上,通常使用Intel的编译器内部函数约定来插入这些特殊指令:
#include <xmmintrin.h> 枚举_mm_hint { _MM_HINT_T0 = 3, _MM_HINT_T1 = 2 _MM_HINT_T2 = 1 _MM_HINT_NTA = 0 }; 无效_mm_prefetch(无效* p, 枚举_mm_hint h);
程序可以在程序中的任何指针上使用_mm_prefetch内在函数。大多数处理器(某些x86和x86-64处理器)都忽略了无效指针导致的错误,这些错误使程序员的工作变得更加轻松。但是,如果传递的指针引用了有效内存,则将指示预取单元将数据加载到缓存中,并在必要时驱逐其他数据。绝对应该避免不必要的预取,因为这可能会降低高速缓存的效率,并且会占用内存带宽(如果驱逐出的高速缓存行很脏,则可能占用两个高速缓存行)。
_mm_prefetch内部函数 要使用的不同提示是实现定义的。这意味着每个处理器版本可以(略)不同地实现它们。通常可以说是_MM_HINT_T0将数据读取到高速缓存的所有级别以用于包含性高速缓存,并读取到最低级别的高速缓存以用于排他性高速缓存。如果数据项位于更高级别的缓存中,则将其加载到L1d中。所述_MM_HINT_T1提示拉动数据到L2和不进L1D。如果有L3高速缓存,则_MM_HINT_T2 提示可以对此执行类似的操作。但是,这些是详细信息,很少指定,并且需要针对使用中的实际处理器进行验证。通常,如果要立即使用_MM_HINT_T0使用数据是正确的事情。当然,这需要L1d高速缓存大小足够大以容纳所有预取的数据。如果立即使用的工作集的大小太大,则将所有内容预取到L1d中是一个坏主意,应使用其他两个提示。
第四个提示,_MM_HINT_NTA特殊之处在于,它允许告诉处理器特别对待预取的缓存行。NTA代表非时间对齐,我们已经在6.1节中进行了解释。该程序告诉处理器,应尽量避免污染此数据,因为该数据仅使用了很短的时间。因此,处理器在加载时可以避免将数据读取到较低级的高速缓存中以实现包含性高速缓存。从L1d清除数据时,无需将数据推入L2或更高版本,而是可以直接将其写入内存。如果给出此提示,处理器设计者可能还会采用其他技巧。程序员必须小心使用此提示:如果立即工作集的大小太大,并迫使逐出装有NTA提示的缓存行,
图6.7:平均预取(NPAD = 31)
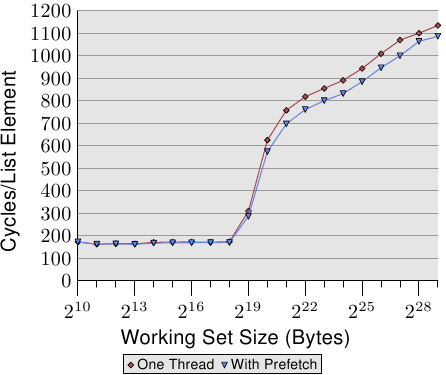
图6.7显示了使用现在熟悉的指针追踪框架进行测试的结果。该列表是随机的。与先前测试的不同之处在于,该程序实际上在每个列表节点上花费一些时间(大约160个周期)。正如我们从图3.15中的数据中学到的那样,只要工作集大小大于上一级缓存,程序的性能就会严重受损。
现在,我们可以尝试通过在计算之前发出预取请求来改善这种情况。也就是说,在循环的每一轮中,我们都会预取一个新元素。必须仔细选择列表中的预取节点和当前正在处理的节点之间的距离。假设每个节点都经过160个周期处理,并且我们必须预取两条高速缓存行(NPAD = 31),那么五个列表元素之间的距离就足够了。
图6.7中的结果表明预取确实有帮助。只要工作集的大小不超过最后一级缓存的大小(计算机的512kB = 2 19 B of L2),数字都是相同的。预取指令不会增加可衡量的额外负担。一旦超过L2大小,预取将节省50到60个周期,最多可节省8%。使用预取不能掩盖所有的惩罚,但确实有帮助。
AMD在Opteron系列的10h系列中实现了另一条指令:prefetchw。到目前为止,该指令在英特尔方面没有等效功能,并且无法通过内部函数使用。该PREFETCHW指令预取缓存线到L1就像其他预取指令。区别在于缓存行立即进入“ M”状态。如果以后没有写入缓存行,这将是一个不利条件。如果有一个或多个写入,则将加快写入速度,因为这些写入不必更改高速缓存状态(在预取高速缓存行时已发生的状态)。
预取比我们在这里获得的8%的优势更大。但是众所周知,正确的做法很难,特别是如果相同的二进制代码在各种机器上都能很好地运行的话。CPU提供的性能计数器可以帮助程序员分析预取。可以计数和采样的事件包括硬件预取,软件预取,有用的软件预取,各个级别的高速缓存未命中等等。在第7.1节中,我们将介绍许多此类事件。所有这些计数器都是特定于机器的。
在分析程序时,应首先查看缓存未命中。当找到大量的高速缓存未命中源时,应尝试为有问题的内存访问添加预取指令。这应该一次在一个地方完成。每次修改的结果都应通过观察性能计数器来测量有用的预取指令来进行检查。如果这些计数器没有增加,则预取可能是错误的,则没有足够的时间从内存中加载,或者预取将仍然需要的缓存从内存中逐出。
今天的gcc能够在一种情况下自动发出预取指令。如果循环遍历数组,则可以使用以下选项:
-fprefetch-loop-arrays
编译器将确定预取是否有意义,如果可以,预取应该走多远。对于较小的数组,这可能是一个缺点,如果在编译时不知道数组的大小,则结果可能会更糟。gcc手册警告说,收益的高低很大程度上取决于代码的形式,并且在某些情况下,代码的运行速度实际上可能会更慢。程序员必须谨慎使用此选项。
6.3.3特殊类型的预取:推测
处理器的OOO执行功能可以在指令彼此不冲突的情况下移动指令。例如(以这次的IA-64为例):
st8 [r4] = 12 加r5 = r6,r7 ;; st8 [r18] = r5
该代码序列将12存储在寄存器r4指定的地址处 ,将寄存器r6和r7的内容相加并将其存储在寄存器r5中。最后,将和存储在寄存器r18指定的地址处。这里的要点是,由于不存在数据依赖性,因此可以在第一个st8指令之前(或同时)执行add指令。但是,如果必须加载加数之一怎么办?
st8 [r4] = 12 ld8 r6 = [r8] ;; 加r5 = r6,r7 ;; st8 [r18] = r5
额外的ld8指令从寄存器r8指定的地址加载值。此装入指令与以下添加 指令之间存在明显的数据相关性(这是;;的原因,在指令之后,感谢提出要求)。这里的关键是,新的ld8指令(与add指令不同)不能移到第一个st8的前面。处理器无法在指令解码期间足够快地确定存储和加载是否冲突,即r4和r8是否可能具有相同的值。如果它们确实具有相同的值,则st8指令将确定装入r6的值。更糟糕的是,如果负载错过了缓存,则ld8也可能带来很大的延迟。IA-64体系结构在这种情况下支持推测性负载:
ld8.a r6 = [r8] ;; [...其他说明...] st8 [r4] = 12 ld8.c.clr r6 = [r8] ;; 加r5 = r6,r7 ;; st8 [r18] = r5
新的ld8.a和ld8.c.clr指令属于一起,并替换了先前代码序列中的ld8指令。所述ld8.a指令是推测性负载。该值不能直接使用,但是处理器可以开始工作。到达ld8.c.clr指令时,该内容可能已经装入(如果在间隙中有足够数量的指令)。该指令的参数必须与ld8.a指令的参数匹配。如果前面的 st8指令未覆盖该值(即r4和 r8相同),则无需执行任何操作。投机负载完成其工作,并且负载的延迟被隐藏。如果存储和加载确实发生冲突,则ld8.c.clr会从内存中重新加载该值,然后我们将得出普通ld8指令的语义。
投机负载尚未广泛使用。但是如示例所示,这是隐藏延迟的非常简单而有效的方法。预取基本上是等效的,对于寄存器较少的处理器,推测性负载可能没有多大意义。推测性加载具有(有时很大)的优点,可以将值直接加载到寄存器中,而不是加载到可能再次被驱逐(例如,在调度线程时)的高速缓存行中。如果有推测,则应使用。
6.3.4辅助线程
当人们尝试使用软件预取时,经常会遇到代码复杂性的问题。如果代码必须遍历数据结构(在我们的示例中为列表),则必须在同一循环中实现两个独立的迭代:正常的迭代完成工作,第二个迭代(展望未来)以使用预取。这很容易变得很复杂,以至于可能出现错误。
此外,有必要确定展望未来。太少了,内存将无法及时加载。距离太远,刚加载的数据可能已被再次逐出。另一个问题是,虽然预取指令不会阻塞并等待加载内存,但它们会花费一些时间。该指令必须进行解码,如果解码器太忙(例如,由于编写/生成的代码好),可能会引起注意。最后,循环的代码大小增加了。这降低了L1i效率。如果人们试图通过连续发出多个预取请求来避免部分成本(如果第二个加载不取决于第一个加载的结果),则会遇到未完成的预取请求数量问题。
另一种方法是完全分开执行正常操作和预取。使用两个普通线程可能会发生这种情况。显然,必须对线程进行调度,以使预取线程填充两个线程访问的缓存。有两种特殊的解决方案值得一提:
- 在同一内核上使用超线程(请参见图3.22)。在这种情况下,预取可以进入L2(甚至L1d)。
- 使用比SMT线程更多的“哑”线程,只能执行预取和其他简单操作。这是处理器制造商可能会探索的选择。
使用超线程特别有趣。如图3.22所示,如果超线程执行独立代码,则共享缓存是一个问题。相反,如果将一个线程用作预提取帮助程序线程,那么这不是问题。相反,这是期望的效果,因为最低级别的高速缓存已预加载。此外,由于预取线程主要是空闲的或正在等待内存,因此如果另一个超线程不必访问主内存本身,则不会对正常操作产生太多干扰。后者正是预取帮助线程所阻止的。
唯一棘手的部分是确保帮助程序线程没有运行得太远。它一定不能完全污染高速缓存,以便再次逐出最旧的预取值。在Linux上,可以使用futex系统调用[futexes]轻松完成同步,或者使用POSIX线程同步原语以更高的成本进行同步。
图6.8:带有辅助线程的平均值,NPAD = 31
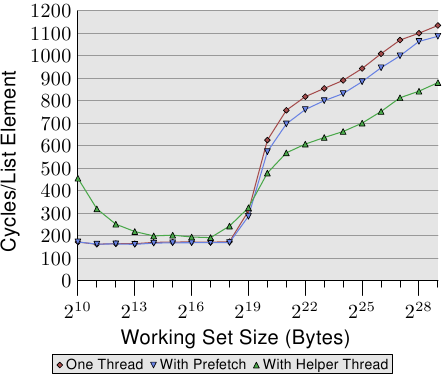
这种方法的好处如图6.8所示。这与图6.7相同,只是添加了其他结果。新测试将创建一个附加的帮助程序线程,该线程在前面运行大约100个列表条目,并读取(不仅预取)每个列表元素的所有缓存行。在这种情况下,每个列表元素有两条高速缓存行(在具有64字节高速缓存行大小的32位计算机上,NPAD = 31)。
这两个线程被调度在同一内核的两个超线程上。测试机只有一个核心,但是如果有多个核心,结果应该大致相同。我们将在6.4.3节中介绍的亲和力函数用于将线程绑定到适当的超线程。
为了确定操作系统知道哪个(或更多)两个处理器是超线程,可以使用libNUMA中的NUMA_cpu_level_mask接口(请参见第12节)。
#include <libNUMA.h> ssize_t NUMA_cpu_level_mask(size_t destsize, cpu_set_t *目的地, size_t srcsize, const cpu_set_t * src, unsigned int级别);
该接口可用于确定通过缓存和内存连接的CPU的层次结构。这里感兴趣的是与超线程相对应的1级。要在两个超线程上调度两个线程,可以使用libNUMA函数(为简洁起见,删除了错误处理):
cpu_set_t self; NUMA_cpu_self_current_mask(sizeof(self), &自); cpu_set_t hts; NUMA_cpu_level_mask(sizeof(hts),&hts, sizeof(self),&self,1); CPU_XOR(&hts,&hts,&self);
执行此代码后,我们有两个CPU位集。 self可以用来设置当前线程的亲和力,而以hts为单位的掩码 可以用来设置辅助线程的亲和力。理想情况下,这应该在创建线程之前发生。在6.4.3节中,我们将介绍用于设置亲和力的接口。如果没有可用的超线程,则 NUMA_cpu_level_mask函数将返回1。这可以用作避免此优化的标志。
该基准测试的结果可能令人惊讶(也许没有)。如果工作集适合L2,则辅助线程的开销会将性能降低10%到60%(再次忽略最小的工作集大小,噪音太大)。这应该是可以预期的,因为如果所有数据都已经在L2缓存中,则预取帮助线程仅使用系统资源,而无助于执行。
但是,一旦L2大小用尽,图片就会改变。预取帮助线程有助于将运行时间减少约25%。我们仍然看到上升的曲线,仅仅是因为预取不能足够快地处理。但是,由主线程执行的算术运算和辅助线程的内存加载运算确实可以互补。资源冲突很小,这导致了这种协同效应。
该测试的结果应可转移到许多其他情况。在这种情况下,超线程(通常由于缓存污染而通常不可用)会发光,应加以利用。该SYS文件系统允许一个程序来找到线程的兄弟姐妹(见thread_siblings表5.3列)。一旦获得了这些信息,程序就只需定义线程的亲和力,然后以两种模式运行循环:正常操作和预取。预取的内存量应取决于共享缓存的大小。在此示例中,L2的大小是相关的,程序可以使用
sysconf(_SC_LEVEL2_CACHE_SIZE)
是否必须限制辅助线程的进度取决于程序。通常,最好确保存在一些同步,因为否则安排详细信息可能会导致严重的性能下降。
6.3.5直接缓存访问
在现代操作系统中,缓存未命中的一种来源是对传入数据流量的处理。诸如网络接口卡(NIC)和磁盘控制器之类的现代硬件能够在不涉及CPU的情况下将接收或读取的数据直接写入内存。这对于今天我们拥有的设备的性能至关重要,但这也会引起问题。假定来自网络的传入数据包:操作系统必须通过查看数据包的标头来决定如何处理它。NIC将数据包放入内存中,然后将到达通知给处理器。处理器没有预取数据的机会,因为它不知道数据何时到达,甚至不知道确切的存储位置。结果是读取标头时出现高速缓存未命中。
英特尔已在其芯片组和CPU中增加了技术来缓解此问题[directcacheaccess]。这个想法是填充CPU的缓存,该缓存将被通知有关传入数据包的数据包数据。数据包的有效负载在这里并不重要,通常,这些数据将由内核或用户级别的更高级别的功能处理。数据包头用于决定必须处理数据包的方式,因此立即需要此数据。
网络I / O硬件已经具有DMA来写入数据包。这意味着它与可能集成在北桥中的内存控制器直接通信。内存控制器的另一面是通过FSB与处理器的接口(假定内存控制器未集成到CPU本身)。
直接缓存访问(DCA)背后的思想是扩展NIC和内存控制器之间的协议。在图6.9中,第一个图显示了在具有北桥和南桥的常规计算机中DMA传输的开始。
DMA启动 执行DMA和DCA 图6.9:直接缓存访问
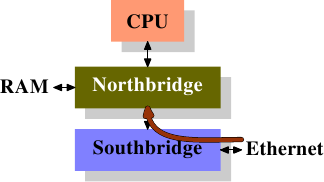
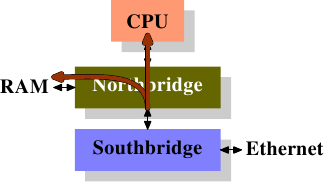
NIC连接到南桥(或为南桥的一部分)。它启动DMA访问,但提供有关应该发送到处理器缓存中的数据包头的新信息。
传统的做法是,在第二步中,只需完成与存储器的连接即可完成DMA传输。对于设置了DCA标志的DMA传输,北桥还使用特殊的新DCA标志在FSB上发送数据。处理器始终监听FSB,并且如果识别出DCA标志,它将尝试将定向到处理器的数据加载到最低缓存中。实际上,DCA标志只是一个提示。处理器可以自由地忽略它。DMA传输完成后,将向处理器发出信号。
操作系统在处理数据包时,首先必须确定它是哪种数据包。如果未忽略DCA提示,则操作系统必须执行的负载才能确定最有可能到达缓存的数据包。将每个数据包节省的数百个周期与每秒可处理的数万个数据包相乘,所节省的费用总计非常多,尤其是在延迟方面。
如果没有I / O硬件(在这种情况下为NIC),芯片组和CPU的集成,那么这种优化是不可能的。因此,如果需要此技术,必须确保明智地选择平台。
内存第6部分:程序员可以做的更多事情6.4多线程优化
当涉及多线程时,缓存的三个不同方面很重要:
- 并发
- 原子性
- 带宽
这些方面也适用于多进程情况,但是由于多个进程(大多数)是独立的,因此对其进行优化并不是那么容易。可能的多进程优化是多线程方案可用的子集。因此,我们将在这里专门处理后者。
在这种情况下,并发是指进程一次运行多个线程时所经历的内存效应。线程的一个特性是它们都共享相同的地址空间,因此都可以访问相同的内存。在理想情况下,线程使用的内存区域是不同的,在这种情况下,这些线程仅轻轻耦合(例如,常见的输入和/或输出)。如果多个线程使用相同的数据,则需要协调;这是原子性发挥作用的时候。最后,取决于机器架构,处理器可用的可用内存和处理器间总线带宽受到限制。在以下各节中,我们将分别处理这三个方面,尽管它们是紧密相连的。
6.4.1并发优化
最初,在本节中,我们将讨论实际上需要矛盾优化的两个独立问题。多线程应用程序在其某些线程中使用公共数据。常规的高速缓存优化要求将数据保持在一起,以使应用程序的占用空间较小,从而在任何时候最大化适合高速缓存的内存量。
但是,这种方法存在一个问题:如果多个线程写入一个内存位置,则高速缓存行必须在每个相应内核的L1d中处于“ E”(独占)状态。这意味着发送了许多RFO请求,在最坏的情况下,每次写访问都会发送一个。因此,正常的写入将突然变得非常昂贵。如果使用相同的内存位置,则需要同步(可能通过使用原子操作,这将在下一部分中进行处理)。但是,当所有线程都使用不同的内存位置并且应该是独立的时,该问题也很明显。
图6.10:并发高速缓存行访问开销
图6.10显示了这种“错误共享”的结果。测试程序(在9.3节中显示)创建了许多线程,这些线程除了增加内存位置(5亿次)外什么也不做。测量的时间是从程序启动到等待最后一个线程之后程序结束为止的时间。线程固定到各个处理器。该机器具有四个P4处理器。蓝色值表示运行,其中分配给每个线程的内存分配在单独的缓存行中。红色部分是当线程的位置仅移至一条缓存行时发生的代价。
蓝色测量值(使用单独的高速缓存行时)与预期的结果一致。该程序可扩展至许多线程而不会受到任何影响。每个处理器将其缓存行保留在其自己的L1d中,并且由于不需要读取太多代码或数据(实际上,它们全部都已缓存),因此不会出现带宽问题。测得的轻微增加实际上是系统噪声,并且可能还有一些预取效果(线程使用顺序的缓存行)。
通过将每个线程使用一条高速缓存行与一条单独的高速缓存行所需要的时间相除得出的测量开销分别为390%,734%和1,147%。这些数量乍一看可能令人惊讶,但在考虑所需的缓存交互时,它应该很明显。高速缓存线刚写完高速缓存线后,便从一个处理器的高速缓存中拉出。除了在任何给定时刻具有高速缓存行的处理器之外,所有处理器都被延迟并且无法执行任何操作。每个额外的处理器只会导致更多的延迟。
从这些度量很明显,必须在程序中避免这种情况。考虑到巨大的代价,这个问题在很多情况下是显而易见的(分析至少会显示代码位置),但是现代硬件存在一个陷阱。图6.11显示了在单处理器四核计算机(Intel Core 2 QX 6700)上运行代码时的等效测量结果。即使使用该处理器的两个单独的L2,测试用例也不会显示任何可伸缩性问题。多次使用同一条缓存行时会产生一些开销,但是不会随核心数量的增加而增加。{当使用全部四个核心时,我无法解释这个较低的数字,但是它是可复制的。}如果使用了多个处理器,我们当然会看到类似于图6.10的结果。尽管越来越多地使用多核处理器,但是许多机器仍将继续使用多个处理器,因此,正确处理此方案很重要,这可能意味着要在实际的SMP机器上测试代码。
图6.11:开销,四核
这个问题有一个非常简单的“解决方案”:将每个变量放在自己的缓存行中。这就是与前面提到的优化冲突发生的地方,特别是应用程序的占用空间将大大增加。这是不可接受的。因此,有必要提出一个更智能的解决方案。
所需要的是识别哪些变量一次仅由一个线程使用,哪些变量仅由一个线程使用,以及那些有时被争用的变量。针对每种情况的不同解决方案都是可能且有用的。区分变量的最基本标准是:是否曾经写过变量以及变量发生的频率。
从不写入的变量和仅初始化一次的变量基本上是常量。由于仅写操作需要RFO请求,因此可以在缓存中共享常量(“ S”状态)。因此,不必特别对待这些变量。将它们分组在一起很好。如果程序员使用const正确标记了变量,则工具链会将变量从普通变量移到.rodata(只读数据)或 .data.rel.ro(重定位后只读)部分。由它们的名称标识的是包含ELF文件中的代码和数据的原子单位。}不需要其他特殊操作。如果由于某种原因无法使用const正确标记变量,程序员可以通过将其分配到特殊部分来影响其位置。
当链接器构造最终二进制文件时,它首先在所有输入文件中附加具有相同名称的部分;然后,按照链接描述文件确定的顺序排列这些部分。这意味着,通过将基本上是恒定的但未标记为此类的所有变量移到特殊部分,程序员可以将所有这些变量组合在一起。它们之间不会经常写入变量。通过在该部分中适当对齐第一个变量,可以保证不会发生错误共享。假设这个小例子:
int foo = 1; 诠释栏__attribute __((section(“。data.ro”))))= 2; int baz = 3; int xyzzy __attribute __((section(“。data.ro”))))= 4;
如果已编译,此输入文件将定义四个变量。有趣的部分是变量foo和baz以及bar和 xyzzy分别分组在一起。如果没有属性定义,编译器将在源代码中名为.data的部分中按顺序定义所有四个变量。{ ISO C标准不对此提供保证,但gcc的工作原理是这样。}使用代码原样,将变量bar和xyzzy放在名为.data.ro的部分中。段名.data.ro或多或少是任意的。.data的前缀。 保证GNU链接器将把该节和其他数据节放在一起。
可以应用相同的技术来分离出变量,这些变量大多数是读取的,但偶尔是写入的。只需选择其他部分名称即可。在某些情况下,例如Linux内核,这种分离似乎很有意义。
如果某个变量仅由一个线程使用,则可以使用另一种方法来指定该变量。在这种情况下,使用线程局部变量是可能且有用的(请参见[mytls])。gcc中的C和C ++语言允许使用__thread关键字将变量定义为每个线程。
int foo = 1; __thread int bar = 2; int baz = 3; __thread int xyzzy = 4;
变量bar和xyzzy没有在普通数据段中分配;相反,每个线程都有其自己的单独区域,这些变量存储在该区域中。变量可以具有静态初始化器。所有其他线程局部变量都可以被所有其他线程寻址,但是,除非某个线程将指向该线程局部变量的指针传递给那些其他线程,否则其他线程将无法找到该变量。由于变量是线程局部的,所以错误共享不是问题,除非程序人为地造成了问题。该解决方案易于设置(编译器和链接器完成所有工作),但是却要付出代价。创建线程时,它必须花费一些时间来设置线程局部变量,这需要时间和内存。此外,
使用线程本地存储(TLS)的一个缺点是,如果将变量的使用转移到另一个线程,则旧线程中变量的当前值不可用于新线程。每个线程的变量副本都是不同的。通常这根本不是问题,如果是这样,则需要协调到新线程的切换,此时可以复制当前值。
第二个更大的问题是可能浪费资源。如果任何时候只有一个线程使用该变量,则所有线程都必须为内存付出代价。如果线程不使用任何TLS变量,则TLS内存区域的延迟分配可避免出现此问题(应用程序本身中的TLS除外)。如果线程在DSO中仅使用一个TLS变量,则该对象中所有其他TLS变量的内存也将被分配。如果大规模使用TLS变量,则可能会加起来。
通常,可以提供的最佳建议是
- 至少将只读(初始化后)和读写变量分开。也许将这种分离扩展到第三类,主要是读取变量。
- 将可一起使用的读写变量分组为一个结构。使用结构是确保所有这些变量的内存位置紧密对齐的唯一方法,所有gcc版本均会一致地翻译该位置。
- 将通常由不同线程写入的读写变量移到其自己的缓存行中。这可能意味着在末尾添加填充以填充缓存行的其余部分。如果与步骤2结合使用,这通常并不是真正的浪费。扩展上面的示例,我们可能最终得到如下代码(假设 bar和xyzzy打算一起使用):
int foo = 1; int baz = 3; 结构{ struct al1 { 整数条 int xyzzy; }; 字符填充[CLSIZE-sizeof(struct al1)]; } rwstruct __attribute __((aligned(CLSIZE)))= {{.bar = 2,.xyzzy = 4}};
需要一些代码更改(对bar的引用必须用rwstruct.bar替换,对于xyzzy也是一样),仅此而已。其余的全部由编译器和链接器完成。{此代码必须使用-fms-extensions }在命令行上进行编译。}
- 如果一个变量被多个线程使用,但是每次使用都是独立的,请将变量移至TLS。
6.4.2原子度优化
如果多个线程同时修改同一内存位置,则处理器不保证任何特定结果。此决定是为了避免在所有案例中有99.999%不必要的费用。例如,如果内存位置处于“ S”状态并且两个线程必须同时增加其值,则执行管道不必在读取旧值之前等待高速缓存行在“ E”状态下可用从缓存中执行添加。取而代之的是,它读取当前缓存中的值,并且一旦缓存行在状态“ E”下可用,就将新值写回。如果两个线程中的两个高速缓存读取同时发生,则结果与预期不符;一加将丢失。
为了确保不会发生这种情况,处理器提供了原子操作。例如,这些原子操作将不会读取旧值,直到很明显可以以将添加到内存位置的方式显示为原子的方式执行加法。除了等待其他内核和处理器之外,某些处理器甚至还向主板上的其他设备发出针对特定地址的原子操作的信号。所有这些使原子操作变慢。
处理器供应商决定提供不同的原子操作集。早期的RISC处理器,与用于“R”线 ř得出,提供非常少的原子操作,有时仅一个原子位集和测试。{ HP Parisc仍然不提供更多… }另一方面,我们拥有提供大量原子操作的x86和x86-64。通常可用的原子操作可以分为四类:
- 位测试
- 这些操作自动设置或清除一个位,并返回指示该位是否已被设置的状态。
- 加载锁定/存储条件(LL / SC)
- {有些人使用“链接”而不是“锁定”,这都是一样的。}
这些操作成对工作,其中使用特殊加载指令来启动事务,并且只有在此期间未修改位置的情况下,最终存储才会成功。存储操作指示成功或失败,因此程序可以在必要时重复其工作。
- 比较和交换(CAS)
- 这是三元运算,仅当当前值与第三参数值相同时,才将作为参数提供的值写入地址(第二参数);
- 原子算术
- 这些操作仅在x86和x86-64上可用,它们可以在内存位置执行算术和逻辑运算。这些处理器支持这些操作的非原子版本,但RISC体系结构则不支持。因此,难怪它们的可用性受到限制。
架构支持LL / SC或CAS指令,而不同时支持两者。两种方法基本上是等效的。它们可以同样好地实现原子算术运算,但如今,CAS似乎是首选方法。可以使用它间接实现所有其他操作。例如,原子加法:
内部曲线 int newval; 做{ curval = var; newval =曲线+加数; } while(CAS(&var,curval,newval));;
CAS调用 的结果指示操作是否成功。如果返回失败(非零值),则再次运行循环,执行加法,然后再次尝试CAS调用。重复此操作直到成功。关于代码的值得注意的是,必须在两个单独的指令中计算存储位置的地址。{ x86和x86-64上的CAS操作码可以避免在第二次及以后的迭代中加载值,但是,在此平台上,我们可以使用一个简单的加法操作码以一种更简单的方式编写原子加法。对于LL / SC,代码看起来几乎相同。
内部曲线 int newval; 做{ 曲线= LL(var); newval =曲线+加数; } while(SC(var,newval));
在这里,我们必须使用特殊的加载指令(LL),并且我们不必将存储位置的当前值传递给SC, 因为处理器知道与此同时存储位置是否已被修改。
最大的区别是x86和x86-64,其中我们具有原子操作,因此在这里选择合适的原子操作以达到最佳结果非常重要。图6.12显示了实现原子增量操作的三种不同方式。
1.添加和读取结果
2.添加并返回旧值
3.原子替换为新值
图6.12:循环中的原子增量
这三个代码在x86和x86-64上产生的代码不同,而在其他体系结构上的代码可能相同。有巨大的性能差异。下表显示了四个并发线程以一百万为增量的执行时间。该代码使用gcc的内置原语(__sync_ *)。
1.交换添加 2.添加提取 3. CAS 0.23秒 0.21秒 0.73秒
前两个数字相似;我们看到返回旧值要快一些。重要信息是突出显示的字段,即使用CAS时的成本。毫不奇怪,它要贵得多。造成这种情况的原因有很多:1.有两个内存操作,2. CAS操作本身更加复杂,甚至需要条件操作,并且3.如果两个并发访问导致整个操作必须循环执行CAS调用失败。
现在读者可能会问一个问题:为什么有人会使用利用CAS的复杂且较长的代码?答案是:复杂性通常是隐藏的。如前所述,CAS目前是所有有趣架构中的统一原子操作。因此,有些人认为用CAS定义所有原子操作就足够了。这使程序更简单。但正如数字所示,结果可能是最佳的。CAS解决方案的内存处理开销巨大。下面说明仅执行两个线程,每个线程在其自己的内核上。
线程#1 线程#2 var缓存状态 v =无功 Proc 1上的“ E” n = v + 1 v =无功 进程1 + 2上的“ S” CAS(无功) n = v + 1 Proc 1上的“ E” CAS(无功) Proc 2上的“ E”
我们看到,在这短时间内的执行期间,高速缓存行状态至少发生了3次变化。其中两个更改是RFO。此外,第二个CAS将失败,因此线程必须重复整个操作。在该操作过程中,可能会再次发生相同的情况。
相反,当使用原子算术运算时,处理器可以保持负载并存储在一起执行加法(或其他任何运算)所需的运算。它可以确保在发出原子操作之前,阻止同时发出的缓存行请求。因此,示例中的每个循环迭代最多只产生一个RFO缓存请求,而没有其他结果。
所有这些意味着,至关重要的一点是,在可以利用原子算术和逻辑运算的水平上定义机器抽象。CAS不应该被普遍用作统一机制。
对于大多数处理器而言,原子操作本身始终是原子的。只能通过为不需要原子性的情况提供完全独立的代码路径来避免它们。这意味着需要更多的代码,条件的代码,并进一步跳转以适当地指导执行。
对于x86和x86-64,情况有所不同:可以以原子方式和非原子方式使用相同的指令。为了使它们原子化,使用了该指令的特殊前缀:lock 前缀。如果在给定情况下不需要原子性要求,这为原子操作打开了大门,避免了高昂的成本。例如,库中的通用代码(如果需要,必须始终是线程安全的)可以从中受益。编写代码时不需要任何信息,可以在运行时做出决定。诀窍是跳过锁定前缀。此技巧适用于x86和x86-64处理器允许使用lock前缀的所有指令。
cmpl $ 0,多个线程 je 1f 锁 1:添加$ 1,some_var
如果此汇编代码看起来很晦涩,请放心,这很简单。第一条指令检查变量是否为零。在这种情况下,非零表示正在运行多个线程。如果该值为零,则第二条指令跳转到标签1。否则,将执行下一条指令。这是棘手的部分。如果je指令没有跳转, 则使用锁定前缀执行add指令。否则,将在没有锁定前缀的情况下执行它。
添加像条件跳转这样的相对昂贵的操作(在分支预测失败的情况下很昂贵)似乎适得其反。确实可以这样:如果大多数时间都在运行多个线程,则性能会进一步降低,尤其是在分支预测不正确的情况下。但是,如果在许多情况下仅使用一个线程,则代码会明显更快。在两种情况下使用if-then-else构造的替代方法都会引入额外的无条件跳转,这可能会更慢。考虑到原子操作的成本约为200个周期,因此使用技巧(或if-then-else块)的交叉点非常低。这绝对是要牢记的技术。不幸的是,这意味着无法使用gcc的__sync_ *原语。
6.4.3带宽注意事项
当使用多个线程,并且它们不会通过在不同内核上使用相同的缓存行而导致缓存争用时,仍然存在潜在的问题。每个处理器具有最大的内存带宽,该带宽由该处理器上的所有内核和超线程共享。取决于机器架构(例如,图2.1中的架构),多个处理器可能共享同一条总线到内存或北桥。
处理器内核本身以这样的频率运行:即使在完美的条件下,全速甚至在完美的条件下,与内存的连接也无法满足所有负载和存储请求。现在,将可用带宽进一步除以共享到北桥的连接的内核,超线程和处理器的数量,突然之间的并行性成为一个大问题。理论上非常有效的程序可能会受到内存带宽的限制。
在图3.32中,我们已经看到提高处理器的FSB速度会很有帮助。这就是为什么随着处理器上内核数量的增加,我们还将看到FSB速度提高的原因。但是,如果程序使用较大的工作集并进行了充分优化,这将永远是不够的。程序员必须准备好识别由于带宽有限而引起的问题。
现代处理器的性能测量计数器允许观察FSB争用。在Core 2处理器上,NUS_BNR_DRV 事件计算内核由于总线未准备好而必须等待的周期数。这表明总线使用率很高,并且从主存储器加载或存储到主存储器的时间比平时更长。Core 2处理器支持更多事件,这些事件可以计算特定的总线动作,例如RFO或常规FSB利用率。在研究开发过程中应用程序可伸缩性的可能性时,后者可能会派上用场。如果总线利用率已经接近1.0,那么可伸缩性机会就很小。
如果识别出带宽问题,则可以执行几项操作。它们有时是矛盾的,因此可能需要进行一些实验。一种解决方案是购买速度更快的计算机(如果有的话)。获得更高的FSB速度,更快的RAM模块以及处理器本地内存可能会有所帮助。不过,这可能会花费很多。如果仅在一台(或几台机器)上需要所讨论的程序,那么硬件的一次性费用可能比重新编写程序要少。但是,一般而言,最好在该程序上工作。
在优化程序本身以避免高速缓存未命中之后,要获得更好的带宽利用率,剩下的唯一选择就是将线程更好地放置在可用内核上。默认情况下,内核中的调度程序将根据其自己的策略将线程分配给处理器。尽可能避免将线程从一个内核移动到另一个内核。但是,调度程序实际上并不了解有关工作负载的任何信息。它可以从缓存未命中等收集信息,但这在许多情况下并没有太大帮助。
图6.13:低效率的调度

导致大量FSB使用的一种情况是,两个线程在不同的处理器(或不共享缓存的内核)上调度,并且使用相同的数据集。图6.13显示了这种情况。内核1和3访问相同的数据(访问指示符和存储区用相同的颜色表示)。同样,核心2和核心4访问相同的数据。但是线程安排在不同的处理器上。这意味着每个数据集必须从内存中读取两次。这种情况可以更好地处理。
图6.14:有效的调度
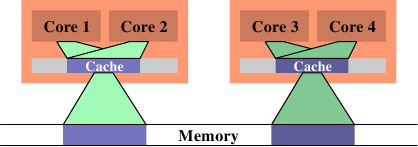
在图6.14中,我们可以看到理想的外观。现在,由于核心1和2以及核心3和4处理同一数据,因此正在使用的总缓存大小减小了。数据集只需从内存中读取一次。
这是一个简单的示例,但从广义上讲,它适用于许多情况。如前所述,内核中的调度程序无法深入了解数据的使用,因此程序员必须确保高效地进行调度。没有太多内核接口可用于传达此要求。实际上,只有一个:定义线程亲和力。
线程相似性是指将一个线程分配给一个或多个内核。然后,调度程序将在决定运行线程的位置时(仅)在这些内核之间进行选择。即使其他内核处于空闲状态,也不会考虑它们。这听起来像是一种劣势,但这是人们必须付出的代价。如果太多的线程专门在一组内核上运行,则其余内核可能大部分都是空闲的,除了更改亲和力外,其他任何事情都无法做。默认情况下,线程可以在任何内核上运行。
有许多接口可以查询和更改线程的相似性:
#定义_GNU_SOURCE #include <sched.h> int sched_setaffinity(pid_t pid,size_t size,const cpu_set_t * cpuset); int sched_getaffinity(pid_t pid,size_t size,cpu_set_t * cpuset);
这两个接口旨在用于单线程代码。的PID参数指定哪个进程的亲和力应当改变或确定。调用方显然需要适当的特权才能执行此操作。第二个和第三个参数指定内核的位掩码。第一个功能要求填充位掩码,以便可以设置亲和力。第二个用所选线程的调度信息填充位掩码。接口在<sched.h>中声明。
该标头中还定义了cpu_set_t类型,以及一些用于操作和使用此类型对象的宏。
#定义_GNU_SOURCE #include <sched.h> #定义CPU_SETSIZE #定义CPU_SET(cpu,cpusetp) #定义CPU_CLR(cpu,cpusetp) #定义CPU_ZERO(cpusetp) #定义CPU_ISSET(CPU,CPUSETP) #定义CPU_COUNT(cpusetp)
CPU_SETSIZE指定在数据结构中可以表示多少个CPU。其他三个宏操作 cpu_set_t对象。要初始化一个对象, 应使用CPU_ZERO;其他两个宏应用于选择或取消选择单个内核。CPU_ISSET测试特定处理器是否属于集合。 CPU_COUNT返回集合中所选的内核数。该cpu_set_ttype为CPU数量上限提供合理的默认值。随着时间的流逝,它肯定会变得太小。届时将调整类型。这意味着程序必须始终牢记大小。上面的便捷宏根据cpu_set_t的定义隐式处理大小。如果需要更多动态尺寸处理,则应使用扩展的宏集:
#定义_GNU_SOURCE #include <sched.h> #定义CPU_SET_S(cpu,setsize,cpusetp) #定义CPU_CLR_S(cpu,setsize,cpusetp) #定义CPU_ZERO_S(setsize,cpusetp) #定义CPU_ISSET_S(cpu,setsize,cpusetp) #定义CPU_COUNT_S(setsize,cpusetp)
这些接口带有一个带有大小的附加参数。为了能够分配动态大小的CPU集,提供了三个宏:
#定义_GNU_SOURCE #include <sched.h> #定义CPU_ALLOC_SIZE(计数) #定义CPU_ALLOC(计数) #定义CPU_FREE(cpuset)
所述CPU_ALLOC_SIZE宏返回其具有将要分配给一个字节数cpu_set_t结构,其可以处理 数量的CPU。要分配这样的块,可以使用CPU_ALLOC宏。以这种方式分配的内存应使用CPU_FREE释放 。这些函数可能会在后台使用malloc和 free,但这不一定必须保持这种方式。
最后,定义了对CPU集对象的许多操作:
#定义_GNU_SOURCE #include <sched.h> #定义CPU_EQUAL(cpuset1,cpuset2) #定义CPU_AND(目标集,cpuset1,cpuset2) #定义CPU_OR(目标集,cpuset1,cpuset2) #定义CPU_XOR(目标集,cpuset1,cpuset2) #定义CPU_EQUAL_S(setsize,cpuset1,cpuset2) #定义CPU_AND_S(setsize,destset,cpuset1,cpuset2) #定义CPU_OR_S(setsize,destset,cpuset1,cpuset2) #定义CPU_XOR_S(setsize,destset,cpuset1,cpuset2)
这两个包含四个宏的集合可以检查两个集合是否相等,并对集合执行逻辑AND,OR和XOR操作。使用某些libNUMA函数时,这些操作非常方便(请参见第12节)。
进程可以使用sched_getcpu接口确定当前在哪个处理器上运行:
#定义_GNU_SOURCE #include <sched.h> int sched_getcpu(void);
结果是CPU在CPU集中的索引。由于调度的性质,该数字不能总是100%正确。从返回结果到线程返回用户级之间,线程可能已移至其他CPU。程序始终必须考虑这种不准确的可能性。无论如何,更重要的是,允许线程在其上运行的一组CPU。可以使用sched_getaffinity检索此集合。该集合由子线程和进程继承。线程不能依赖集合在整个生命周期内保持稳定。亲和力遮罩可从外部设置(请参见pid以上原型中的参数);Linux还支持CPU热插拔,这意味着CPU可以从系统中消失,因此也可以从相似性CPU集中消失。
在多线程程序中,各个线程正式没有POSIX定义的进程ID,因此,不能使用上述两个函数。相反,<pthread.h>声明了四个不同的接口:
#定义_GNU_SOURCE #include <pthread.h> int pthread_setaffinity_np(pthread_t th,size_t size, const cpu_set_t * cpuset); int pthread_getaffinity_np(pthread_t th,size_t size,cpu_set_t * cpuset); int pthread_attr_setaffinity_np(pthread_attr_t * at, size_t size,const cpu_set_t * cpuset); int pthread_attr_getaffinity_np(pthread_attr_t * at,size_t大小, cpu_set_t * cpuset);
前两个接口基本上与我们已经看到的两个接口相同,除了它们在第一个参数中使用线程句柄而不是进程ID。这允许处理进程中的各个线程。这也意味着这些接口不能在其他进程中使用,它们严格供进程内使用。第三和第四接口使用线程属性。这些属性在创建新线程时使用。通过设置该属性,可以从头开始在一组特定的CPU上调度线程。尽早选择目标处理器(而不是在线程已经启动之后)在许多不同级别上都有优势,包括(尤其是)内存分配(请参见6.5节中的NUMA)。
说到NUMA,相似性接口在NUMA编程中也起着重要作用。我们将很快回到这种情况。
到目前为止,我们已经讨论了两个线程的工作集重叠从而使两个线程位于同一内核上的情况。反之亦然。如果两个线程在单独的数据集上工作,那么将它们安排在同一内核上可能会成为问题。两个线程都争夺同一个缓存,从而减少了彼此对缓存的有效使用。其次,两个数据集都必须加载到同一缓存中。实际上,这增加了必须加载的数据量,因此,可用带宽减少了一半。
在这种情况下,解决方案是设置线程的相似性,以使它们无法在同一内核上调度。这与之前的情况相反,因此在进行任何更改之前了解一个试图优化的情况非常重要。
实际上,优化缓存共享以优化带宽是NUMA编程的一个方面,下一部分将对此进行介绍。只需要将“内存”的概念扩展到缓存。一旦缓存级别增加,这将变得越来越重要。因此,NUMA支持库中提供了多核调度解决方案。有关在不对系统详细信息进行硬编码或深入了解/ sys 文件系统深度的情况下确定亲和力掩码的方法,请参见第12节中的代码示例。
6.5 NUMA编程
到目前为止,关于NUMA编程的所有内容都适用于缓存优化。差异仅始于该水平以下。当访问地址空间的不同部分时,NUMA会引入不同的成本。通过统一的内存访问,我们可以进行优化以最大程度地减少页面错误(请参见7.5节),仅此而已。创建的所有页面均相等。
NUMA对此进行了更改。访问成本可能取决于所访问的页面。不同的访问成本也增加了优化内存页面局部性的重要性。对于大多数SMP机器来说,NUMA是不可避免的,因为带CSI的Intel(用于x86,x86-64和IA-64)和AMD(用于Opteron)都使用NUMA。随着每个处理器内核数量的增加,我们很可能会看到正在使用的SMP系统急剧减少(至少在外部数据中心和对CPU使用率有很高要求的人们的办公室)。大多数家用计算机只需一个处理器就可以了,因此不会出现NUMA问题。但这a)并不意味着程序员可以忽略NUMA,b)并不意味着没有相关问题。
如果想到NUMA的概括,就会很快意识到这一概念也扩展到了处理器缓存。使用相同缓存的内核上的两个线程将比不共享缓存的内核上的线程协作更快。这不是捏造的情况:
- 早期的双核处理器没有L2共享。
- 例如,英特尔的Core 2 QX 6700和QX 6800四核芯片具有两个单独的L2缓存。
- 如前所述,随着芯片上更多内核的出现以及统一缓存的愿望,我们将拥有更多级别的缓存。
缓存形成自己的层次结构,线程在核心上的放置对于共享(或不共享)缓存很重要。这与NUMA面临的问题并没有太大不同,因此可以将这两个概念统一起来。因此,即使只对非SMP机器感兴趣的人也应该阅读本节。
在5.3节中,我们看到Linux内核提供了许多信息,这些信息在NUMA编程中是有用的(并且是必需的)。但是,收集此信息并不容易。为此,Linux上当前可用的NUMA库完全不足。作者目前正在构建一个更合适的版本。
现有的NUMA库libnuma是numactl软件包的一部分,无法提供对系统体系结构信息的访问。它只是可用系统调用的包装,以及一些常用操作的便捷接口。今天在Linux上可用的系统调用为:
- mbind
- 选择将指定的内存页面绑定到节点。
- set_mempolicy
- 设置默认的内存绑定策略。
- get_mempolicy
- 获取默认的内存绑定策略。
- migrate_pages
- 将给定节点集上的进程的所有页面迁移到另一组节点上。
- move_pages
- 将所选页面移动到给定节点或请求有关页面的节点信息。
这些接口在libnuma库随附的<numaif.h>中声明。在开始更多细节之前,我们必须了解内存策略的概念。
6.5.1内存策略
定义内存策略的思想是,允许现有代码在NUMA环境中正常运行而无需进行重大修改。该策略由子进程继承,这使得可以使用numactl工具。除其他外,该工具可以用于以给定策略启动程序。
Linux内核支持以下策略:
- MPOL_BIND
- 仅从给定的节点集分配内存。如果这不可能,则分配失败。
- MPOL_PREFERRED
- 存储器优选地从给定的节点集合分配。如果失败,则考虑其他节点的内存。
- MPOL_INTERLEAVE
- 内存从指定节点平均分配。对于基于VMA的策略,可以通过虚拟内存区域中的偏移量来选择节点;对于基于任务的策略,可以通过自由运行计数器来选择节点。
- MPOL_DEFAULT
- 根据区域的默认值选择分配。
此列表似乎是递归定义策略。这是正确的一半。实际上,内存策略形成了一个层次结构(见图6.15)。
图6.15:内存策略层次结构

如果某个地址被VMA策略覆盖,则使用该策略。一种特殊的策略用于共享内存段。如果没有针对特定地址的策略,则使用任务的策略。如果也不存在,则使用系统的默认策略。
系统默认设置是在请求内存的线程本地分配内存。默认情况下不提供任何任务和VMA策略。对于具有多个线程的进程,本地节点是“宿主”节点,是第一个运行该进程的节点。上面提到的系统调用可用于选择不同的策略。
6.5.2指定策略
该set_mempolicy调用可以用来设置当前线程(内核发言任务)任务的政策。仅当前线程受到影响,而不是整个过程受到影响。
#include <numaif.h> 长set_mempolicy(int模式, 无符号长* nodemask, 无符号长maxnode);
该模式参数必须是一个MPOL_ *在前一节中介绍的常量。所述nodemask参数指定的存储器节点使用和maxnode是在节点(即,位)的数目nodemask。如果MPOL_DEFAULT使用nodemask参数被忽略。如果一个空指针作为传递 nodemask为MPOL_PREFERRED本地节点被选择。否则,MPOL_PREFERRED使用最低的节点号,并在nodemask中设置相应的位。
设置策略对已分配的内存没有任何影响。页面不会自动迁移;仅将来的分配会受到影响。注意内存分配和地址空间保留之间的区别:使用mmap建立的地址空间区域通常不会自动分配。在存储器区域上的第一次读或写操作将分配适当的页面。如果策略在访问同一地址空间区域的不同页面之间更改,或者该策略允许从不同节点分配内存,则看似统一的地址空间区域可能分散在许多内存节点上。
6.5.3交换和策略
如果物理内存用完,则系统必须丢弃干净页面并保存脏页面以进行交换。Linux swap实现在写入要交换的页面时会丢弃节点信息。这意味着当页面被重用并在所使用的节点中分页时,将从头开始选择。线程的策略可能会导致选择一个与正在执行的处理器接近的节点,但是该节点可能与以前使用的节点不同。
这种变化的关联意味着节点关联不能被程序存储为页面的属性。关联会随着时间而变化。对于与其他进程共享的页面,这也可能发生,因为某个进程需要它(请参阅下面的mbind讨论 )。如果一个节点空间不足而其他节点仍具有可用空间,则内核本身可以迁移页面。
因此,用户级代码了解的任何节点关联都只能在很短的时间内成立。它比绝对信息更多是提示。每当需要准确的知识时, 都应使用get_mempolicy接口(请参见6.5.5节)。
6.5.4 VMA策略
要为地址范围设置VMA策略,必须使用其他接口:
#include <numaif.h> 长mbind(void * start,unsigned long len, 整数模式 无符号长* nodemask, 无符号长maxnode, 未签名的标志);
此接口针对地址范围[ start,start + len)注册新的VMA策略。由于内存处理在页面上进行,因此起始地址必须与页面对齐。该 LEN值向上舍入到下一个页面大小。
该模式参数指定再次,政策; 这些值必须从6.5.1节的列表中选择。与 set_mempolicy一样,nodemask参数仅用于某些策略。其处理方式相同。
mbind接口 的语义取决于flags参数的值 。默认情况下,如果标志为零,则系统调用将为地址范围设置VMA策略。现有映射不受影响。如果这还不够,那么当前有三个标志可以修改此行为。可以单独或一起选择它们:
- MPOL_MF_STRICT
- 如果并非所有页面都在nodemask指定的节点上,则 对mbind的调用将失败。如果此标志与MPOL_MF_MOVE和/或MPOL_MF_MOVEALL一起使用 ,则如果无法移动任何页面,则调用将失败。
- MPOL_MF_MOVE
- 内核将尝试在不在nodemask指定的集合中的节点上分配的地址范围内移动任何页面。默认情况下,仅移动当前进程的页表专用的页面。
- MPOL_MF_MOVEALL
- 像MPOL_MF_MOVE一样,内核将尝试移动所有页面,而不仅仅是仅由当前进程的页面表使用的那些页面。这具有系统范围的含义,因为它也会影响其他进程(可能不是同一用户所有)的内存访问。因此,MPOL_MF_MOVEALL是特权操作(需要CAP_NICE功能)。
请注意,仅在2.6.16 Linux内核中添加了对MPOL_MF_MOVE和MPOL_MF_MOVEALL的支持。
当必须在实际分配任何页面之前指定新保留的地址范围的策略时,不带任何标志的mbind 调用最有用。
无效* p = mmap(NULL,len,PROT_READ | PROT_WRITE,MAP_ANON,-1,0); 如果(p!= MAP_FAILED) mbind(p,len,mode,nodemask,maxnode,0);
此代码序列保留len字节的地址空间范围,并指定应使用引用节点掩码中的存储节点的策略模式。除非MAP_POPULATE标志与使用MMAP,无记忆将已经被时间分配 mbind通话,因此,新政策适用于该地址空间区域的所有页面。
所述MPOL_MF_STRICT单独标志可被用来确定在地址范围内的任何页面是否描述由开始和 LEN参数mbind上比由指定的其它节点分配nodemask。没有分配的页面被更改。如果在指定节点上分配了所有页面,则地址空间区域的VMA策略将根据mode进行更改。
有时需要重新平衡内存,在这种情况下,可能有必要将在一个节点上分配的页面移动到另一节点。调用mbind与MPOL_MF_MOVE集使以达到最佳的努力。仅考虑由进程的页面表树唯一引用的页面。可以有多个用户以线程或其他进程的形式共享页面表树的该部分。不可能影响碰巧映射相同数据的其他过程。这些页面不共享页面表条目。
如果将MPOL_MF_STRICT和MPOL_MF_MOVE都传递给 mbind,则内核将尝试移动未在指定节点上分配的所有页面。如果这不可能,则呼叫将失败。这样的调用对于确定是否有一个节点(或一组节点)可以容纳所有页面可能很有用。可以连续尝试几种组合,直到找到合适的节点为止。
除非运行当前进程是计算机的主要目的,否则很难证明 使用MPOL_MF_MOVEALL是合理的。原因是即使出现在多个页面表中的页面也被移动了。这很容易以负面方式影响其他进程。因此,应谨慎使用此操作。
6.5.5查询节点信息
该get_mempolicy接口可用于查询各种有关NUMA的给定地址的状态的事实。
#include <numaif.h> long get_mempolicy(int * policy, const unsigned long * nmask, 无符号长maxnode, * addr,int标志);
如果在没有在标志中设置标志的情况下调用get_mempolicy,则有关地址addr的策略的信息将存储在policy所指向的字中 以及nmask所指向的节点的位掩码中 。如果addr落入为其指定了VMA策略的地址空间区域,则返回有关该策略的信息。否则,将返回有关任务策略或必要时系统默认策略的信息。
如果MPOL_F_NODE标志被设置的标志,和管理政策地址是MPOL_INTERLEAVE,存储在由指着字的价值的政策是在其下一次分配将要发生的节点的索引。此信息可能会用于设置将在新分配的内存上工作的线程的亲和力。这可能是实现接近的一种成本较低的方法,尤其是在尚未创建线程的情况下。
该MPOL_F_ADDR标志可用于检索另一个完全不同的数据项。如果使用此标志,则策略指向的字中存储的值是已在其中分配了包含addr的页面的内存的存储节点的索引。该信息可用于做出有关可能的页面迁移的决定,决定哪个线程可以最有效地在内存位置上工作以及更多其他事情。
与线程的内存分配相比,线程正在使用的CPU(因此还有内存节点)的易失性要大得多。内存页面在没有明确请求的情况下仅在极端情况下移动。由于重新平衡了CPU负载,因此可以将一个线程分配给另一个CPU。因此,有关当前CPU和节点的信息可能很短。调度程序将尝试将线程保持在同一CPU上,甚至可能保持在同一内核上,以最大程度地减少由于冷缓存而导致的性能损失。这意味着查看当前的CPU和节点信息很有用。一个人只能避免假设关联不会改变。
libNUMA提供了两个接口来查询给定虚拟地址空间范围的节点信息:
#include <libNUMA.h> int NUMA_mem_get_node_idx(void * addr); int NUMA_mem_get_node_mask(void * addr, size_t大小, size_t __destsize, memnode_set_t * dest);
NUMA_mem_get_node_mask根据控制策略,为所有已分配(或将分配)[ addr,addr + size)范围内的页面的存储节点的位设置目标。 NUMA_mem_get_node仅查看地址addr,并返回在其上(或将在其上)分配该地址的内存节点的索引。这些接口比get_mempolicy更易于使用,可能应该首选。
可以使用sched_getcpu查询线程当前使用的CPU (请参见6.4.3节)。使用此信息,程序可以使用libNUMA中的NUMA_cpu_to_memnode接口来确定CPU本地的内存节点:
#include <libNUMA.h> int NUMA_cpu_to_memnode(size_t cpusetsize, const cpu_set_t * cpuset, size_t memnodesize, memnode_set_t * memnodeset);
对该函数的调用将设置(在第四个参数所指向的存储节点集中)与第二个参数所指向的集中的任何CPU本地的所有存储节点相对应的所有位。就像CPU信息本身一样,该信息仅在计算机的配置发生更改(例如,卸下并添加CPU)之后才是正确的。
memnode_set_t对象中 的位可用于对诸如get_mempolicy之类的低级函数的调用。在libNUMA中使用其他功能更为方便。反向映射可通过以下方式获得:
#include <libNUMA.h> int NUMA_memnode_to_cpu(size_t memnodesize, const memnode_set_t * memnodeset, size_t cpusetsize, cpu_set_t * cpuset);
结果cpuset中设置的位是在memnodeset中设置了相应位的任何内存节点本地的CPU的位 。对于这两个接口,程序员都必须意识到该信息会随着时间而改变(尤其是在CPU热插拔的情况下)。在许多情况下,输入位集中会设置一个位,但是,例如,将通过调用sched_getaffinity检索到的整个CPU传递给 NUMA_cpu_to_memnode来确定线程有哪些内存节点也很有意义。可以直接访问。
6.5.6 CPU和节点集
如果源不可用,则通过更改代码以使用到目前为止介绍的接口来调整SMP和NUMA环境的代码可能会非常昂贵(或不可能)。另外,系统管理员可能希望对用户和/或进程可以使用的资源施加限制。对于这些情况,Linux内核支持所谓的CPU集。该名称有点误导,因为还包括内存节点。它们也与cpu_set_t数据类型无关。
目前,CPU集的接口是一个特殊的文件系统。通常未安装(至少到目前为止)。可以通过以下方式更改
挂载-t cpuset无/ dev / cpuset
当然,挂载点/ dev / cpuset必须存在。该目录的内容是对默认(根)CPU集的描述。它最初包括所有CPU和所有内存节点。该 目录中的cpus文件显示CPU集中的CPU,mems 文件显示内存节点,任务文件显示进程。
要创建一个新的CPU集,只需在层次结构中的某个位置创建一个新目录。新的CPU集将继承父级的所有设置。然后,可以通过将新值写入新目录中的cpus和 mems伪文件中来更改用于新CPU集的CPU和内存节点。
如果进程属于CPU集,则将CPU和内存节点的设置用作关联性和内存策略位掩码的掩码。这意味着程序无法在亲和力掩码中选择不在cpus文件中的任何CPU作为该进程正在使用的CPU集(即,在任务文件中列出的CPU )。类似地,对于内存策略和mems文件的节点掩码。
除非屏蔽后位屏蔽为空,否则程序将不会遇到任何错误,因此CPU集是控制程序执行的几乎不可见的方法。这种方法在具有大量CPU和/或内存节点的大型计算机上特别有效。将进程移至新的CPU集中就像将进程ID写入相应CPU的任务文件中一样简单。
CPU集的目录包含许多其他文件,这些文件可用于指定详细信息,例如在内存压力下的行为以及对CPU和内存节点的独占访问。有兴趣的读者可以参考内核源代码树中的Documentation / cpusets.txt文件。
6.5.7明确的NUMA优化
如果所有节点上的所有线程都需要访问相同的内存区域,则所有本地内存和关联性规则都将无济于事。当然,可以简单地将线程数限制为直接连接到存储节点的处理器可支持的数量。但是,这没有利用SMP NUMA机器,因此不是真正的选择。
如果所讨论的数据是只读的,则有一个简单的解决方案:复制。每个节点都可以获得自己的数据副本,因此不需要节点间访问。执行此操作的代码如下所示:
无效* local_data(void){ 静态void * data [NNODES]; int节点= NUMA_memnode_self_current_idx(); 如果(节点== -1) / *无法获得节点,请选择一个。* / 节点= 0; 如果(数据[节点] == NULL) 数据[节点] = allocate_data(); 返回数据[节点]; } void worker(void){ 无效*数据= local_data(); 为(...) 使用数据计算 }
在此代码中,函数工作者通过调用local_data获取指向数据本地副本的指针来进行准备。然后,它继续使用该指针的循环。该 local_data功能保持围绕数据的已分配副本的列表。每个系统都有有限数量的内存节点,因此带有指向每个节点内存副本的指针的数组的大小受到限制。该 NUMA_memnode_system_count从libNUMA函数返回这个数字。如果尚未知道由NUMA_memnode_self_current_idx调用确定的当前节点的指针, 则会分配新副本。
重要的是要认识到,如果在调用sched_getcpu系统后将线程调度到连接到不同内存节点的另一个CPU上,则不会发生任何可怕的事情。这仅意味着使用另一个存储节点上的工作程序访问存储器中的data变量进行访问。这会减慢程序速度,直到重新计算数据为止 ,仅此而已。内核将始终避免不必要地重新平衡每个CPU的运行队列。如果发生这种转移,通常是有充分的理由的,并且在不久的将来不会再次发生。
当所讨论的存储区可写时,事情会变得更加复杂。在这种情况下,简单的复制将不起作用。根据实际情况,可能有许多可能的解决方案。
例如,如果可写存储区用于累加结果,则有可能首先为每个存储结果的存储节点创建一个单独的区域。然后,完成这项工作后,将所有每个节点的内存区域组合在一起以获得总结果。即使工作从未真正停止,该技术也可以工作,但是需要中间结果。此方法的要求是结果的累积是无状态的,即,它不依赖于先前收集的结果。
但是,直接访问可写存储区域将总是更好。如果对内存区域的访问次数很大,则最好强制内核将相关的内存页面迁移到本地节点。如果访问次数确实很高,并且不同节点上的写入操作不是同时发生的,则可能会有所帮助。但是请注意,内核无法执行奇迹:页面迁移是复制操作,因此它并不便宜。该费用必须摊销。
6.5.8利用所有带宽
图5.4中的数字表明,当缓存无效时,访问远程内存并不比访问本地内存慢。这意味着程序可以通过不必将数据再次读入连接到另一个处理器的存储器中的数据来节省本地存储器的带宽。与DRAM模块的连接带宽和互连的带宽大部分是独立的,因此并行使用可以提高整体性能。
这是否真的可能取决于许多因素。确实必须确保缓存无效,因为否则可以测量与远程访问有关的速度下降。另一个大问题是远程节点是否对自己的内存带宽有任何需求。在采用这种方法之前,必须详细检查这种可能性。从理论上讲,使用处理器可用的所有带宽可以产生积极的影响。一个家庭10h Opteron处理器可以直接连接到最多四个其他处理器。如果系统的其余部分继续运行,那么利用所有这些额外的带宽,也许再加上适当的预取(尤其是prefetchw),可能会导致改进。
内存第7部分:内存性能工具7种内存性能工具
各种各样的工具可用来帮助程序员了解程序的缓存和内存使用。现代处理器具有可以使用的性能监视硬件。有些事件很难精确测量,因此也有进行模拟的空间。当涉及到更高级别的功能时,有一些特殊的工具可以监视流程的执行。我们将介绍大多数Linux系统上可用的一组常用工具。
7.1内存操作分析
分析内存操作需要硬件的协作。可以仅在软件中收集一些信息,但这要么是粗粒度的,要么仅仅是模拟。模拟示例将在第7.2节和第7.5节中显示。在这里,我们将专注于可测量的记忆效果。
oprofile 提供了对Linux上的性能监视硬件的访问 。 Oprofile提供了连续分析功能,如[continuous]中所述。它使用易于使用的界面在整个系统范围内进行统计分析。Oprofile绝不是使用处理器性能评估功能的唯一方式;Linux开发人员正在研究 pfmon ,在某个时候它可能已经足够广泛地部署,以保证在此也有描述。
oprofile提供的界面既简单又最小,即使使用了可选的GUI,也相当底层。用户必须在处理器可以记录的事件中进行选择。处理器的体系结构手册描述了事件,但是通常,它需要有关处理器本身的大量知识才能解释数据。另一个问题是所收集数据的解释。性能测量计数器是绝对值,可以任意增长。给定计数器的价格有多高?
此问题的部分答案是避免查看绝对值,而是将多个计数器相互关联。处理器可以监视多个事件。然后可以检查所收集的绝对值的比率。这给出了不错的可比结果。除数通常是处理时间,时钟周期数或指令数的量度。作为程序性能的初步尝试,仅将这两个数字相互关联是很有用的。
图7.1:每条指令的周期(随机)
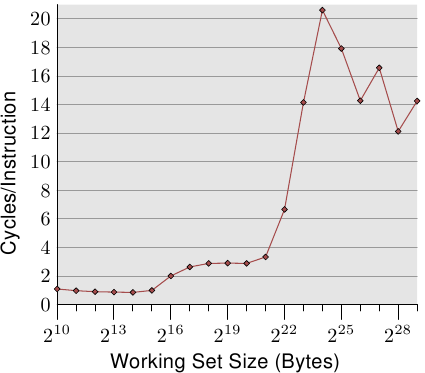
图7.1显示了针对各种工作集大小的简单随机“跟随”测试用例的每条指令周期(CPI)。为大多数英特尔处理器收集该信息的事件的名称为 CPU_CLK_UNHALTED和INST_RETIRED。顾名思义,前者计算CPU的时钟周期,后者计算指令数。我们看到的图片类似于我们使用的每个列表元素测量的周期。对于小尺寸的工作台,该比率为1.0甚至更低。这些测量是在Intel Core 2处理器上进行的,该处理器是多标量的,可以一次处理多个指令。对于不受内存带宽限制的程序,该比率可以显着低于1.0,但是在这种情况下,1.0非常好。
一旦L1d的大小不再足以容纳工作集,CPI就会跳到3.0以下。请注意,CPI比率是对所有指令(不只是存储器指令)的访问L2的平均惩罚。使用列表元素数据的周期,可以算出每个列表元素需要多少条指令。如果甚至L2缓存不足,CPI比率也会跳到20以上。这是预期的结果。
但是性能测量计数器应该可以提供更多有关处理器中发生的情况的信息。为此,我们需要考虑处理器的实现。在本文档中,我们关注缓存处理的详细信息,因此我们必须查看与缓存有关的事件。这些事件,它们的名称及其计数是特定于处理器的。无论使用哪种简单的用户界面,oprofile都是当前很难使用的地方:用户必须自己确定性能计数器的详细信息。在第10节中,我们将看到有关某些处理器的详细信息。
对于Core 2处理器,要查找的事件是L1D_REPL, DTLB_MISSES和L2_LINES_IN。后者可以测量所有丢失和由指令引起的丢失,而不是硬件预取。随机“跟随”测试的结果如图7.2所示。
图7.2:测得的高速缓存未命中(跟随随机)
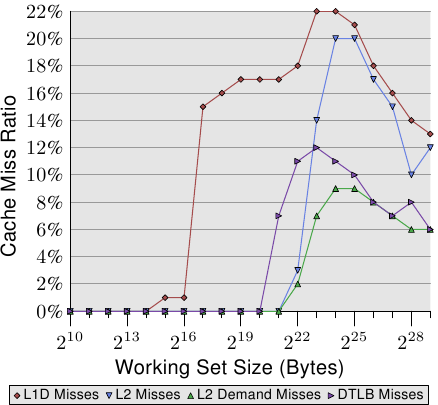
所有比率均使用退休指令数(INST_RETIRED)计算。这意味着还对未触及存储器的指令进行了计数,这又意味着触及存储器且遭受高速缓存未命中的指令的数量甚至比图中所示的还要高。
L1d丢失比其他所有错误都高,因为对于Intel处理器,L2d丢失意味着由于使用包含性缓存而导致L1d丢失。处理器具有32k的L1d,因此,正如我们所预期的,L1d速率在工作集大小附近从零上升(列表数据结构旁边还有高速缓存的其他用途,这意味着16k和32k标记)。有趣的是,对于不超过64k的工作集,硬件预取可以将未命中率保持在1%。之后,L1d率猛增。
L2丢失率保持为零,直到L2耗尽为止。由于L2的其他用途而导致的一些遗漏对数字的影响不大。一旦超过L2的大小(2 21字节),未命中率就会上升。重要的是要注意,L2需求未命中率不为零。这表明硬件预取器不会稍后加载指令所需要的所有高速缓存行。这是预料之中的,访问的随机性阻止了完美的预取。将其与图7.3中顺序读取的数据进行比较。
图7.3:测得的高速缓存未命中(顺序)
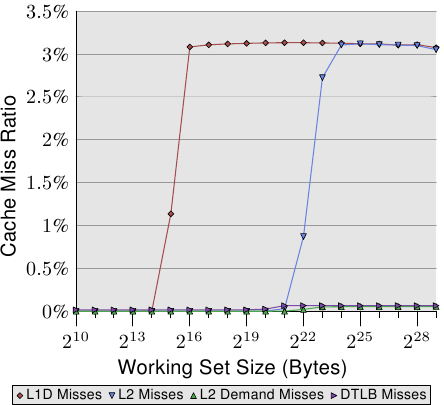
在此图中,我们可以看到L2需求缺失率基本上为零(请注意,此图的比例与图7.2不同)。对于顺序访问的情况,硬件预取器可以完美地工作:几乎所有的L2缓存未命中都是由预取器引起的。L1d和L2丢失率相同的事实表明,所有L1d高速缓存未命中都由L2高速缓存处理,没有进一步的延迟。这是所有程序的理想情况,但是,这几乎是不可能的。
两张图中的第四行是DTLB丢失率(Intel对代码和数据有单独的TLB,DTLB是数据TLB)。对于随机访问的情况,DTLB丢失率很高,并且会导致延迟。有趣的是,L2未命中之前就设置了DTLB处罚。对于顺序访问的情况,DTLB成本基本上为零。
回到6.2.1节的矩阵乘法示例和9.1节的示例代码,我们可以使用另外三个计数器。该SSE_PRE_MISS,SSE_PRE_EXEC和 LOAD_HIT_PRE计数器可以用来查看软件预取的效果如何。如果运行第9.1节中的代码,我们将得到以下结果:
描述 比 有用的NTA预取 2.84% 晚期NTA预取 2.65%
有用的NTA(非时间对齐)预取比率低表示已为已加载的高速缓存行执行了许多预取指令,因此不需要任何工作。这意味着处理器浪费时间来解码预取指令并查找缓存。但是,不能过于苛刻地判断代码。在很大程度上取决于所使用的处理器的缓存大小。硬件预取器也起作用。
较低的NTA预取后期比率会产生误导。该比率意味着所有预取指令的2.65%发出得太晚了。需要数据的指令在数据可以预取到高速缓存之前执行。必须记住,只有2.84%+ 2.65%= 5.5%的预取指令有用。在有用的NTA预取指令中,有48%没有及时完成。因此,可以进一步优化代码:
- 不需要大多数预取指令。
- 可以调整预取指令的使用以更好地匹配硬件。
留给读者练习是确定可用硬件的最佳解决方案。确切的硬件规格起着重要作用。在Core 2处理器上,SSE算术运算的等待时间为1个周期。较旧的版本具有2个周期的延迟,这意味着硬件预取器和预取指令有更多的时间来引入数据。
要确定可能需要(或不需要)预取的位置,可以使用opannotate程序。它列出了程序的源代码或汇编代码,并显示了识别事件的指令。请注意,模糊性有两个来源:
- Oprofile执行随机分析。仅记录每个第N个事件(其中N是具有强制最小值的每个事件阈值),以避免过多降低系统的运行速度。可能有几行会导致100个事件,但它们可能不会显示在报告中。
- 并非所有事件都被准确记录。例如,记录特定事件时的指令计数器可能不正确。处理器是多标量的,因此很难给出100%正确的答案。不过,某些处理器上的一些事件是准确的。
带注释的清单对确定预取信息不仅仅有用。每个事件都用指令指针记录。因此,还可以在程序中查明其他热点。作为许多INST_RETIRED事件源的位置 经常执行,应该进行调整。报告许多高速缓存未命中的位置可能需要预取指令,以避免高速缓存未命中。
页面错误是一种无需硬件支持即可测量的事件。操作系统负责解决页面错误,在这些情况下,它也将其计算在内。它区分两种页面错误:
- 小页面错误
- 这些是迄今为止尚未使用的匿名(即,没有文件支持的)页面,写时复制页面以及其他内容已经在内存中的其他页面的页面错误。
- 主要页面错误
- 解决它们需要访问磁盘以检索文件支持(或换出)的数据。
显然,主要页面错误要比次要页面错误贵得多。但是后者也不便宜。无论哪种情况,都必须进入内核,必须找到一个新页面,必须用适当的数据清除或填充该页面,并且必须相应地修改页面表树。最后一步需要与读取或修改页表树的其他任务同步,这可能会导致进一步的延迟。
检索有关页面错误计数信息的最简单方法是使用时间工具。注意:使用真实的工具,而不是内置的shell。输出如图7.4所示。{反斜杠会阻止使用内置命令。}
$ time ls / etc [...] 0.00user 0.00系统0:00.02经过17%CPU(0avgtext + 0avgdata 0maxresident)k 0inputs + 0outputs(1major + 335minor)页面错误0swap图7.4:时间实用程序的输出
有趣的部分是最后一行。时间工具报告一个主要页面错误和335个次要页面错误。确切数字有所不同;特别是,立即重复运行可能会表明现在根本没有重大页面错误。如果程序执行相同的操作,而环境没有任何变化,则总页面错误计数将保持稳定。
关于页面错误的一个特别敏感的阶段是程序启动。使用的每一页都会产生页面错误;可见的效果(尤其是对于GUI应用程序)是使用的页面越多,程序开始工作所需的时间就越长。在7.5节中,我们将看到一种专门测量此效果的工具。
在后台,时间工具使用了rusage功能。该 wait4系统调用在填充结构rusage对象时,对孩子的父母等待终止; 这正是时间工具所需要的。但是,进程也可以请求有关其自身资源使用情况(即名称 rusage的来源)或其终止子级的资源使用情况的信息。
#include <sys / resource.h> int getrusage(__ rusage_who_t who,struct rusage * usage)
该谁参数指定处理信息的请求。当前, 已定义RUSAGE_SELF和RUSAGE_CHILDREN。每个子进程终止时,将累积子进程的资源使用情况。它是一个总值,而不是单个子进程的使用量。存在允许请求特定于线程的信息的建议,因此在不久的将来我们可能会看到RUSAGE_THREAD。该rusage结构被定义为包含各种指标,包括执行时间的,用于发送IPC消息和存储器的数量,和页面错误的数量。后面的信息在ru_minflt和ru_majflt中可用 结构的成员。
试图确定其程序由于页面错误而在哪里失去性能的程序员可以定期请求信息,然后将返回的值与以前的结果进行比较。
如果请求者具有必要的特权,则从外部也可以看到该信息。伪文件/ proc / <PID> / stat(其中 <PID>是我们感兴趣的进程的进程ID)在第十至第十四字段中包含页面错误编号。它们分别是进程及其子级累积的次要和主要页面错误的对。
7.2模拟CPU缓存
尽管对缓存如何工作的技术描述相对容易理解,但要查看实际程序相对于缓存的行为却并不容易。程序员并不直接关心地址的值,无论它们是绝对值还是相对值。地址部分由链接器决定,部分在运行时由动态链接器和内核确定。预期生成的汇编代码可以与所有可能的地址一起使用,并且在源语言中,甚至没有暗示绝对地址值的提示。因此,很难理解程序如何利用内存。{当编程接近于硬件时,这可能会有所不同,但这与普通编程无关,在任何情况下,仅适用于特殊地址,例如内存映射设备。}
CPU级的分析工具(例如oprofile)(如7.1节所述)可以帮助您了解缓存的使用。结果数据与实际硬件相对应,如果不需要细粒度的收集,则可以相对快速地收集数据。一旦需要更多细粒度的数据,oprofile就不再可用。该线程将不得不被频繁中断。此外,要查看程序在不同处理器上的存储行为,实际上必须拥有这样的机器并在它们上执行程序。有时(通常)是不可能的。图3.8中的数据就是一个例子。要使用oprofile收集此类数据,必须拥有24台不同的机器,其中许多机器不存在。
该图中的数据是使用缓存模拟器收集的。该程序cachecachend使用valgrind框架,该框架最初是为检查程序中与内存处理相关的问题而开发的。valgrind框架模拟程序的执行,并且在执行此操作时,它允许各种扩展(例如cachegrind)挂接到执行框架中。cachegrind工具使用它来拦截所有对内存地址的使用。然后,它以给定的大小,缓存行大小和关联性来模拟L1i,L1d和L2缓存的操作。
要使用该工具,必须使用valgrind作为包装运行程序:
valgrind --tool = cachegrind命令arg
以这种最简单的形式,使用参数arg执行程序命令,同时使用与其运行的处理器相对应的大小和关联性来模拟三个高速缓存。程序运行时,输出的一部分被打印为标准错误。它由缓存总使用量的统计信息组成,如图7.5所示。
== 19645 ==我参考:152,653,497 == 19645 == I1失误:25,833 == 19645 == L2i未击中:2,475 == 19645 == I1失败率:0.01% == 19645 == L2i丢失率:0.00% == 19645 == == 19645 == D refs:56,857,129(35,838,721 rd + 21,018,408 wr) == 19645 == D1失误:14,187(12,451 rd + 1,736 wr) == 19645 == L2d未中:7,701(6,325 rd + 1,376 wr) == 19645 == D1失误率:0.0%(0.0%+ 0.0%) == 19645 == L2d丢失率:0.0%(0.0%+ 0.0%) == 19645 == == 19645 == L2裁判:40,020(38,284 rd + 1,736 wr) == 19645 == L2失误:10,176(8,800 rd + 1,376 wr) == 19645 == L2失误率:0.0%(0.0%+ 0.0%)图7.5:Cachegrind摘要输出
给出了指令和内存引用的总数,以及它们为L1i / L1d和L2高速缓存生成的未命中次数,未命中率等。该工具甚至能够将L2访问分为指令和数据访问,并且所有数据缓存的使用均分为读写访问权限。
当更改模拟缓存的详细信息并比较结果时,这将变得更加有趣。通过使用的-I1, -D1和-L2参数,cachegrind可以指示无视处理器的高速缓存布局和使用该命令行上指定。例如:
valgrind --tool = cachegrind --L2 = 8388608,8,64命令arg
将模拟具有8路设置关联性和64字节高速缓存行大小的8MB L2高速缓存。请注意,“- L2”选项出现在命令行中要模拟的程序名称之前。
这不是所有cachegrind都能做到的。在进程退出之前,cachegrind会写出一个名为cachegrind.out.XXXXX的文件,其中 XXXXX是进程的PID。该文件包含每个功能和源文件中有关高速缓存使用的摘要信息和详细信息。可以使用cg_annotate程序查看数据。
该程序产生的输出包含在进程终止时打印的缓存使用摘要,以及该程序每个功能中缓存行使用的详细摘要。生成此按功能的数据要求cg_annotate能够将地址与功能进行匹配。这意味着调试信息应该可用以获得最佳结果。失败的话,ELF符号表可能会有所帮助,但是由于内部符号未在动态符号表中列出,因此结果不完整。图7.6显示了与图7.5相同的程序运行的部分输出。
-------------------------------------------------- ------------------------------ Ir I1mr I2mr Dr D1mr D2mr Dw D1mw D2mw文件:功能 -------------------------------------------------- ------------------------------ 53,684,905 9 8 9,589,531 13 3 5,820,373 14 0 ???:_ IO_file_xsputn @@ GLIBC_2.2.5 36,925,729 6,267 114 11,205,241 74 18 7,123,370 22 0 ???:vfprintf 11,845,373 22 2 3,126,914 46 22 1,563,457 0 0 ???:__ find_specmb 6,004,482 40 10 697,872 1,744 484 0 0 0 ???:strlen 5,008,448 3 2 1,450,093 370 118 0 0 0 ???:strcmp 3,316,589 24 4 757,523 0 0 540,952 0 0 ???:_ IO_padn 2,825,541 3 3 290,222 5 1 216,403 0 0 ???:_ itoa_word 2,628,466 9 6 730,059 0 0 358,215 0 0 ???:_ IO_file_overflow @@ GLIBC_2.2.5 2,504,211 4 4 762,151 2 0 598,833 3 0 ???:_ IO_do_write @@ GLIBC_2.2.5 2,296,142 32 7 616,490 88 0 321,848 0 0 dwarf_child.c:__ libdw_find_attr 2,184,153 2,876 20 503,805 67 0 435,562 0 0 ???:__ dcigettext 2,014,243 3 3 435,512 1 1 272,195 4 0 ???:_ IO_file_write @@ GLIBC_2.2.5 1,988,697 2,804 4 656,112 380 0 47,847 1 1 ???:getenv 1,973,463 27 6 597,768 15 0 420,805 0 0 dwarf_getattrs.c:dwarf_getattrs
图7.6:cg_annotate输出
Ir,Dr和Dw列显示了总的缓存使用量,而不是缓存未命中,这在以下两列中显示。此数据可用于识别产生最多缓存未命中的代码。首先,人们可能会专注于L2缓存未命中,然后继续优化L1i / L1d缓存未命中。
cg_annotate可以更详细地提供数据。如果给出了源文件的名称,它也会用与该行相对应的高速缓存命中和未命中次数来注释(因此为程序名)源文件的每一行。该信息使程序员可以深入到高速缓存未命中问题所在的确切行。程序界面有点原始:在撰写本文时,cachegrind数据文件和源文件必须位于同一目录中。
在这一点上,应该再次指出:cachegrind是一个模拟器,它不使用来自处理器的测量。处理器中的实际缓存实现可能完全不同。cachegrind模拟最近最少使用(LRU)驱逐,这对于具有较大关联性的高速缓存而言可能太昂贵了。此外,该模拟未考虑上下文切换和系统调用,这两者都可能破坏L2的大部分,并且必须刷新L1i和L1d。这导致高速缓存未中的总数低于实际情况。尽管如此,cachegrind是一个很好的工具,可以了解程序的内存使用及其内存问题。
7.3测量内存使用率
知道程序分配了多少内存以及分配可能在哪里进行是优化其内存使用的第一步。幸运的是,有一些易于使用的程序,它们甚至不需要重新编译或专门修改程序。
对于第一个称为massif的工具,不剥离编译器可以自动生成的调试信息就足够了。它概述了一段时间内累积的内存使用情况。图7.7显示了生成的输出示例。
图7.7:Massif输出
与cachegrind(第7.2节)一样,massif是使用valgrind基础结构的工具。开始使用
valgrind --tool = massif命令arg
其中命令arg是要观察的程序及其参数,将模拟该程序并识别对内存分配函数的所有调用。记录呼叫站点以及时间戳值。新的分配大小将添加到整个程序总数和特定呼叫站点的总数中。这同样适用于释放内存的功能,其中显然从适当的总和中减去释放块的大小。然后,可以使用此信息来创建一个图表,显示程序在整个生命周期内的内存使用情况,并根据请求分配的位置划分每个时间值。在该过程终止之前,massif创建两个文件:massif.XXXXX.txt和 massif.XXXXX.ps,其中两种情况下的XXXXX均为流程的PID。该.TXT文件是内存使用的所有调用点和汇总.PS是什么可以在图7.7中可以看出。
Massif还可以记录程序的堆栈使用情况,这对于确定应用程序的总内存占用量很有用。但这并不总是可能的。在某些情况下(某些线程堆栈或使用signaltstack时 ),valgrind运行时无法了解堆栈的限制。在这些情况下,将这些堆栈的大小加到总计中也没有多大意义。在其他几种情况下,这毫无意义。如果程序受此影响,则应该使用附加选项-stacks = no来启动massif。注意,这是valgrind的一个选项,因此必须在所观察程序的名称之前。
某些程序围绕系统的分配功能提供自己的内存分配功能或包装器功能。在第一种情况下,通常会错过分配;在第二种情况下,已记录的呼叫站点会隐藏信息,因为只有包装功能中的呼叫地址被记录。因此,可以将其他功能添加到分配功能列表中。所述 -alloc-FN =的xmalloc参数将指定的函数 的xmalloc也是分配功能,这通常是在GNU程序的情况。记录对xmalloc的调用,但不记录从xmalloc内部进行的分配调用。
第二种工具称为记忆。它是GNU C库的一部分。它是地块的简化版本(但存在于地块之前很长时间)。它仅记录堆的总内存使用情况(如果给定了-m选项,则包括对mmap的可能调用等),以及可选的堆栈。结果可以显示为总内存使用量随时间变化的图表,或者线性显示为对分配函数的调用。这些图形是由memusage脚本分别创建的,与valgrind一样,该脚本必须用于启动应用程序:
记忆命令arg
该-p IMGFILE选项必须用于指定图形应在文件中生成IMGFILE,这将是一个PNG文件。收集数据的代码在实际程序本身中运行,而不是像valgrind这样的模拟。这意味着游乐比地块快得多,并且在地块无用的情况下可用。除了总的内存消耗外,该代码还记录了分配大小,并且在程序终止时,它还显示了所用分配大小的直方图。此信息被写入标准错误。
有时不可能(或不可行)调用应该直接观察的程序。一个示例是gcc的编译器阶段,该阶段由gcc驱动程序启动。在这种情况下,必须使用-n NAME参数将应注意的程序名称提供给memusage脚本。如果观察到的程序启动其他程序,此参数也很有用。如果未指定程序名称,则将对所有启动的程序进行概要分析。
地块和记忆这两个程序都有其他选项。程序员发现自己需要更多的功能时,应首先查阅手册或帮助消息,以确保尚未实现其他功能。
既然我们知道如何捕获有关内存分配的数据,那么有必要讨论如何在内存和缓存使用的上下文中解释此数据。有效动态内存分配的主要方面是线性分配和所用部分的紧凑性。这可以提高预取的效率并减少缓存丢失。
必须读取任意数量的数据以供以后处理的程序可以通过创建一个列表来实现此目的,其中每个列表元素都包含一个新的数据项。这种分配方法的开销可能很小(单链接列表一个指针),但是使用数据时的缓存效果会大大降低性能。
一个问题是,例如,不能保证顺序分配的存储器在存储器中顺序布置。有许多可能的原因:
- 实际上,由内存分配器管理的大内存块中的内存块实际上是从后往前返回的;
- 一个内存块耗尽,并且在地址空间的不同部分开始一个新的内存块;
- 分配请求是针对不同大小的,它们是由不同的内存池提供的;
- 多线程程序各个线程中分配的交织。
如果必须先分配数据以便以后处理,则链表方法显然不是一个好主意。不能保证(甚至不可能)列表中的连续元素在内存中连续布置。为确保连续分配,不得以小块分配该内存。必须使用另一层内存处理。程序员可以轻松实现它。一种替代方法是使用GNU C库中提供的obstack实现。该分配器向系统的分配器请求大块内存,然后将任意大块或小块内存移出。除非大内存块已用尽,否则这些分配始终是顺序的,这取决于请求的分配大小,这很少见。堆栈不能完全替代内存分配器,它们释放物体的能力有限。有关详细信息,请参见GNU C库手册。
因此,如何从图表中识别出建议使用堆栈(或类似技术)的情况?如果不咨询来源,就无法确定可能的更改候选者,但是图形可以为搜索提供入口点。如果从同一位置进行许多分配,这可能意味着批量分配可能会有所帮助。在图7.7中,我们可以在地址0x4c0e7d5的分配中看到这种可能的候选对象。从运行的大约800毫秒到运行的1800毫秒,这是唯一增长的区域(顶部,绿色区域除外)。此外,斜率并不陡峭,这意味着我们有大量相对较小的分配。实际上,这确实是使用堆栈或类似技术的候选人。
这些图可能显示的另一个问题是分配总数高时。如果图形不是随时间线性地绘制,而是随调用次数线性地绘制(带有memusage的默认值),则特别容易看到。在这种情况下,图中的缓坡意味着很多小的分配。memusage不会说分配发生在哪里,但是与massif的输出进行比较可以说明这一点,否则程序员可能会立即意识到这一点。应该合并许多小分配以实现线性内存使用。
但是,后一种情况还有另一个同样重要的方面:许多分配也意味着更高的管理数据开销。就其本身而言,这可能不是问题。红色区域“ heap-admin”在地块图中表示此开销,并且非常小。但是,根据malloc的实现,此管理数据与数据块一起分配在同一内存中。对于GNU C库中的当前malloc实现,情况就是这样:每个分配的块至少都有一个2字头(32位平台为8个字节,64位平台为16个字节)。此外,由于管理内存的方式,块大小通常会比所需大小大一些(将块大小四舍五入为特定倍数)。
这一切都意味着程序使用的内存与仅分配器出于管理目的使用的内存散布。我们可能会看到以下内容:

每个块代表一个存储字,在这个小的存储区中,我们有四个分配的块。由于块头和填充造成的开销为50%。由于头文件的放置,这自动意味着处理器的有效预取率也将降低多达50%。如果对这些块进行了顺序处理(以充分利用预取的优势),则处理器将把所有标头和填充字读入高速缓存中,即使它们永远不会被应用程序本身读取或写入。仅运行时使用标题字,并且运行时仅在释放该块时起作用。
现在,有人可能会争辩说应该更改实现以将管理数据放到其他地方。在某些实现中确实可以做到这一点,这可能是一个好主意。但是,有许多方面需要牢记,安全并不是其中最重要的方面。无论将来是否会发生变化,填充问题都将永远消失(忽略标题时,示例中的数据占16%)。只有程序员直接控制分配,才能避免这种情况。当对齐要求发挥作用时,可能仍然会有漏洞,但这也是程序员控制下的事情。
7.4改进分支预测
在6.2.2节中,提到了两种通过分支预测和块重新排序来提高L1i使用率的方法:通过__builtin_expect进行的静态预测和配置文件引导的优化(PGO)。正确的分支预测会影响性能,但是在这里我们对内存使用率的改进很感兴趣。
采用__builtin_expect(或更好的可能和 不可能宏)很简单。这些定义放在中央头文件中,编译器负责其余的工作。有一个小问题,虽然:它很容易足以让一个程序员使用 可能时真的不太可能是意味着,反之亦然。即使有人使用oprofile之类的工具来测量不正确的分支预测并且L1i遗漏,这些问题也很难发现。
不过,有一种简单的方法。9.2节中的代码显示了可能和不太可能的宏的替代定义,这些宏在运行时会主动测量静态预测是否正确。然后,程序员或测试人员可以检查结果并进行调整。这些度量实际上并没有考虑程序的性能,它们只是测试程序员的静态假设。在上面引用的部分中,可以找到更多详细信息以及代码。
如今,PGO在gcc中非常容易使用。但是,这是一个三步过程,必须满足某些要求。首先,必须使用附加的-fprofile-generate选项编译所有源文件 。必须将此选项传递给所有编译器运行和链接程序的命令。可以混合使用和不使用此选项编译的目标文件,但是PGO对于未启用此选项的对象不会有任何好处。
编译器会生成一个正常运行的二进制文件,但它会变得更大,更慢,因为它会记录(并发出)有关是否采用分支的所有信息。编译器还会为每个输入文件发出一个扩展名为.gcno的文件。该文件包含与代码中的分支有关的信息。必须保留以备后用。
一旦程序二进制文件可用,就应使用它来运行一组代表性的工作负载。无论使用什么工作负载,最终二进制文件都将被优化以很好地完成此任务。该程序可以连续运行,通常是必需的;所有运行将贡献到相同的输出文件。在程序终止之前,将在程序运行期间收集的数据写出为扩展名为.gcda的文件。这些文件在包含源文件的目录中创建。可以从任何目录执行该程序,并且可以复制二进制文件,但是带有源的目录必须是可写的。同样,为每个输入源文件创建一个输出文件。如果程序多次运行,则.gcda很重要可以在源目录中找到上一次运行的文件,因为否则运行数据不能累积在一个文件中。
运行了一组有代表性的测试后,就该重新编译该应用程序了。编译器必须能够在包含源文件的同一目录中找到 .gcda文件。无法移动文件,因为编译器无法找到它们,并且文件的嵌入式校验和不再匹配。对于重新编译,将-fprofile-generate参数替换为 -fprofile-use。至关重要的是,源代码不得以任何会更改生成代码的方式进行更改。这意味着:可以更改空白并编辑注释,但是添加更多分支或基本块会使收集的数据无效,并且编译将失败。
这是程序员要做的所有事情。这是一个相当简单的过程。正确的最重要的事情是选择代表性的测试来执行测量。如果测试工作负载与程序的实际使用方式不匹配,则所执行的优化实际上弊大于利。因此,将PGO用于库通常很困难。图书馆可用于许多(有时相差很大)场景中。除非用例确实相似,否则通常最好只使用__builtin_expect进行静态分支预测。
.gcno和.gcda文件中的 几句话。这些是二进制文件,不能立即用于检查。但是,也可以使用gcov工具(也是gcc软件包的一部分)检查它们。该工具主要用于覆盖率分析(因此得名),但是使用的文件格式与PGO相同。gcov工具会为每个带有已执行代码的源文件生成扩展名为.gcov的输出文件(可能包括系统头文件)。这些文件是源清单,根据提供给gcov的参数进行注释,并带有分支计数器,概率等。
7.5页面错误优化
在按需分页的操作系统(如Linux)上, mmap调用只会修改页表。它确保对于文件支持的页面,可以找到基础数据,对于匿名内存,可以确保在访问时提供以零初始化的页面。mmap调用时未分配实际内存。{如果您想说“错!” 稍等片刻,以后会有异常的资格。}
当通过读取或写入数据或通过执行代码首次访问存储页面时,发生分配部分。响应于随之而来的页面错误,内核控制并使用页面表树确定必须在页面上显示的数据。解决页面错误的方法并不便宜,但是对于进程使用的每一个页面,它都会发生。
为了最大程度地减少页面错误的成本,必须减少已使用页面的总数。优化代码的大小将对此有所帮助。为了降低特定代码路径(例如,启动代码)的成本,还可以重新排列代码,以便在该代码路径中将触摸页面的数量最小化。但是,确定正确的顺序并不容易。
作者基于valgrind工具集编写了一个工具,用于在页面错误发生时对其进行测量。不是页面错误的数量,而是它们发生的原因。该 页面调工具发出关于页面错误的顺序和时间信息。输出写入名为pagein。<PID>的文件,如图7.8所示。
0 0x3000000000 C 0 0x3000000B50:(在/lib64/ld-2.5.so中) 1 0x 7FF000000 D 3320 0x3000000B53:(在/lib64/ld-2.5.so中) 2 0x3000001000 C 58270 0x3000001080:_dl_start(在/lib64/ld-2.5.so中) 3 0x3000219000 D 128020 0x30000010AE:_dl_start(在/lib64/ld-2.5.so中) 4 0x300021A000 D 132170 0x30000010B5:_dl_start(在/lib64/ld-2.5.so中) 5 0x3000008000 C 10489930 0x3000008B20:_dl_setup_hash(在/lib64/ld-2.5.so中) 6 0x3000012000 C 13880830 0x3000012CC0:_dl_sysdep_start(在/lib64/ld-2.5.so中) 7 0x3000013000 C 18091130 0x3000013440:brk(在/lib64/ld-2.5.so中) 8 0x3000014000 C 19123850 0x3000014020:strlen(在/lib64/ld-2.5.so中) 9 0x3000002000 C 23772480 0x3000002450:dl_main(在/lib64/ld-2.5.so中)图7.8:pagein工具的输出
第二列指定被分页的页面的地址。第三列指出是代码页还是数据页,分别包含“ C”或“ D”。第四列指定自第一页错误以来经过的循环数。该行的其余部分是valgrind尝试查找导致页面错误的地址的名称。地址值本身是正确的,但是如果没有可用的调试信息,则名称并不总是准确的。
在图7.8的示例中,执行从地址0x3000000B50开始,这迫使地址0x3000000000的页面被分页。此后不久,此后的页面也被引入。该页面上调用的函数是_dl_start。初始代码访问页面0x7FF000000上的变量。这在第一页错误之后仅发生3,320个周期,并且很可能是程序的第二条指令(仅在第一条指令之后的三个字节)。如果人们看了一下程序,就会注意到这种内存访问有些特殊之处。有问题的指令是一个电话指令,它不会显式加载或存储数据。不过,它确实将返回地址存储在堆栈中,而这恰恰是在这里发生的情况。这不是进程的正式堆栈,但是,它是valgrind的应用程序内部堆栈。这意味着在解释pagein的结果时,请务必牢记valgrind会引入一些工件。
Pagein的输出可用于确定哪些代码序列在程序代码中理想情况下应该相邻。快速浏览 /lib64/ld-2.5.so代码,您会发现第一条指令立即调用了函数_dl_start,并且这两个位置位于不同的页面上。重新布置代码以将代码序列移动到同一页面上可以避免(或至少延迟)页面错误。到目前为止,确定最佳代码布局应是繁琐的过程。由于设计上没有记录页面的第二次使用,因此需要反复试验才能看到更改的效果。使用调用图分析,可以猜测可能的调用顺序;这可能有助于加快对函数和变量进行排序的过程。
在非常粗糙的级别上,可以通过查看组成可执行文件或DSO的目标文件来查看调用序列。从一个或多个入口点(即函数名称)开始,可以计算依赖关系链。无需付出太多努力,这在目标文件级别就可以很好地工作。在每一轮中,确定哪些目标文件包含所需的函数和变量。必须明确指定种子集。然后确定那些目标文件中所有未定义的引用,并将它们添加到所需符号集中。重复直到设定稳定。
该过程的第二步是确定订单。必须将各种目标文件组合在一起以填充尽可能少的页面。另外,没有功能可以跨越页面边界。所有这些的一个复杂之处在于,为了最好地排列目标文件,必须知道链接器以后将要执行的操作。此处的重要事实是,链接器会将对象文件以它们在输入文件(例如,归档文件)和命令行中出现的顺序放入可执行文件或DSO中。这给程序员足够的控制权。
对于那些愿意花更多时间的人,使用-finstrument-functions选项[oooreorder]进行调用时,通过__cyg_profile_func_enter和 __cyg_profile_func_exit钩子gcc插入进行了自动调用跟踪,已经成功进行了重新排序的尝试。有关这些__cyg_ *的更多信息,请参见gcc手册。 接口。通过创建程序执行的跟踪,程序员可以更准确地确定调用链。仅通过重新排序功能,[oooreorder]中的结果就是启动成本降低了5%。主要的好处是减少了页面错误的数量,但是TLB缓存也发挥了作用-变得越来越重要,因为在虚拟化环境中,TLB丢失的代价大大增加。
通过将pagein工具的分析与调用顺序信息结合起来,应该可以优化程序的某些阶段(例如启动),以最大程度地减少页面错误的数量。
Linux内核提供了两种其他机制来避免页面错误。第一个是mmap的标志,它指示内核不仅修改页面表,而且实际上对映射区域中的所有页面进行预故障处理。这是通过简单地将MAP_POPULATE标志添加 到mmap 调用的第四个参数来实现的。这将导致mmap调用的成本大大增加,但是,如果立即使用该调用映射的所有页面,则好处可能很大。该程序将不具有多个页面错误,而这些页面错误由于同步需求等导致的开销而非常昂贵,因此该程序将具有一个更昂贵的mmap呼叫。但是,在呼叫后不久(或从未)使用大量映射页面的情况下,使用此标志有缺点。映射的未使用页面显然浪费时间和内存。立即进行故障处理且仅在以后大量使用的页面也会阻塞系统。内存在使用前已分配,这可能会导致内存不足。另一方面,在最坏的情况下,页面只是简单地重新用于新的目的(因为它尚未被修改),它虽然不那么昂贵,但仍然与分配一起增加了一些成本。
MAP_POPULATE 的粒度太粗糙了。还有第二个可能的问题:这是优化。确实映射所有页面并不重要。如果系统太忙而无法执行操作,则可以删除预故障。一旦真正使用了页面,程序就会出现页面错误,但这并不比人为地造成资源短缺更糟糕。另一种方法是将 POSIX_MADV_WILLNEED建议与posix_madvise一起使用 功能。这向操作系统提示,在不久的将来,该程序将需要调用中描述的页面。内核可以随意忽略建议,但也可以对页面进行故障修复。这样做的好处是粒度更细。可以预先对任何映射的地址空间区域中的单个页面或页面范围进行故障处理。对于包含很多在运行时未使用的数据的内存映射文件,这比使用MAP_POPULATE具有巨大的优势 。
除了这些主动方法以最大程度地减少页面错误数之外,还可以采用一种更被动的方法,该方法在硬件设计人员中很流行。DSO占用地址空间中的相邻页面,每个页面用于代码和数据。页面大小越小,容纳DSO所需的页面越多。反过来,这也意味着更多的页面错误。重要的是,相反的情况也是如此。对于较大的页面大小,减少了映射(或匿名内存)所需的页面数;随之而来的是页面错误的数量。
大多数体系结构都支持4k的页面大小。在IA-64和PPC64上,页面大小为64k也很流行。这意味着分配内存的最小单位为64k。该值必须在编译内核时指定,并且不能动态更改(至少当前不能更改)。多页面大小体系结构的ABI旨在允许运行具有任一页面大小的应用程序。运行时将进行必要的调整,并且正确编写的程序不会注意到任何事情。页面尺寸越大,表示部分使用页面的浪费就越大,但是在某些情况下,这是可以的。
大多数体系结构还支持1MB或更大的超大页面大小。这样的页面在某些情况下也很有用,但是以如此大的单位分配所有内存是没有意义的。物理RAM的浪费只会太大。但是很大的页面有其优点:如果使用海量数据集,则在x86-64上将它们存储在2MB页面中(每大页面)将比使用相同数量的4k页面的内存减少511个页面错误。这可以带来很大的不同。解决方案是有选择地请求内存分配,该内存分配仅针对请求的地址范围使用巨大的内存页,而对于同一进程中的所有其他映射,则使用正常的页面大小。
不过,巨大的页面尺寸要付出代价。由于用于大页面的物理内存必须是连续的,因此一段时间后,由于内存碎片,可能无法分配此类页面。防止这种情况。人们正在努力进行内存碎片整理和避免碎片整理,但这非常复杂。对于较大的页面(例如2MB),总是很难获得必要的512个连续页面,除非一次:系统启动时。这就是为什么当前的大页面解决方案需要使用特殊文件系统 ugettlbfs的原因。该伪文件系统是应系统管理员的要求分配的,方法是写一些应保留给它们的大页面数
/ proc / sys / vm / nr_hugepages
应当保留的大页面数。如果找不到足够的连续内存,此操作可能会失败。如果使用虚拟化,情况将变得特别有趣。使用VMM模型进行虚拟化的系统无法直接访问物理内存,因此无法单独分配 hugetlbfs。它必须依赖VMM,并且不能保证支持此功能。对于KVM模型,运行KVM模块的Linux内核可以执行hugetlbfs分配,并可能将由此分配的页面的子集传递到来宾域之一。
以后,当程序需要大页面时,有多种可能性:
- 程序可以使用带有SHM_HUGETLB标志的System V共享内存 。
- 该hugetlbfs的文件系统实际上可以安装,然后程序可以创建一个文件下的安装点和使用 的mmap映射一个或多个页面的匿名内存。
在第一种情况下,无需安装hugetlbfs。请求一个或多个大页面的代码如下所示:
key_t k = ftok(“ / some / key / file”,42); int id = shmget(k,LENGTH,SHM_HUGETLB | IPC_CREAT | SHM_R | SHM_W); void * a = shmat(id,NULL,0);
该代码序列的关键部分是使用 SHM_HUGETLB标志和选择LENGTH的正确值,该值 必须是系统巨大页面大小的倍数。不同的体系结构具有不同的价值。使用System V共享内存接口存在一个令人讨厌的问题,即取决于关键参数来区分(或共享)映射。该 ftok接口可以很容易产生冲突,这是什么原因,如果可能的话,最好是使用其他机制。
如果挂载ugeltlbfs文件系统的要求不是问题,则最好使用它而不是System V共享内存。使用特殊文件系统的唯一真正问题是内核必须支持它,并且还没有标准化的挂载点。一旦挂载了文件系统(例如/ dev / hugetlb),程序就可以轻松使用它:
int fd = open(“ / dev / hugetlb / file1”,O_RDWR | O_CREAT,0700); 无效* a = mmap(NULL,LENGTH,PROT_READ | PROT_WRITE,fd,0);
通过在打开的调用中使用相同的文件名,多个进程可以共享相同的大页面并进行协作。也可以使页面可执行,在这种情况下,还必须在mmap调用中设置PROT_EXEC标志。就像在System V共享内存示例中一样,LENGTH的值必须是系统巨大页面大小的倍数。
防御性编写的程序(如所有程序一样)可以使用以下函数在运行时确定安装点:
字符* hugetlbfs_mntpoint(void){ char *结果= NULL; FILE * FP = setmntent(_PATH_MOUNTED,“ r”); 如果(fp!= NULL){ 结构* m; 而((m = getmntent(fp))!= NULL) 如果(strcmp(m-> mnt_fsname,“ hugetlbfs”)== 0){ 结果= strdup(m-> mnt_dir); 打破; } endmntent(fp); } 返回结果; }
关于这两种情况的更多信息,可以在作为内核源代码树的一部分的hugetlbpage.txt文件中找到。该文件还描述了IA-64所需的特殊处理。
图7.9:跟随大页面,NPAD = 0
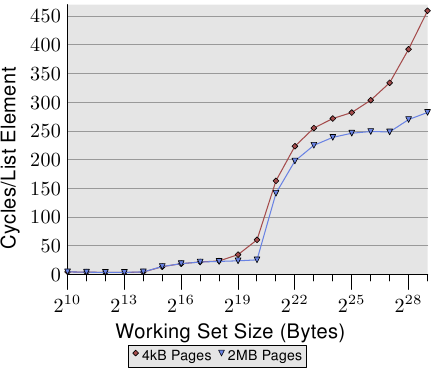
为了说明大页面的优势,图7.9显示了针对NPAD = 0进行随机Follow测试的结果。这与图3.15中所示的数据相同,但是这次,我们也使用分配在大页面中的内存来测量数据。可以看出,性能优势是巨大的。对于2个20字节,使用大页面的测试速度提高了57%。这是因为该大小仍完全适合单个2MB页面,因此不会发生DTLB遗漏的事实。
此后,奖金最初较小,但随着工作装置尺寸的增加而再次增加。对于512MB工作集大小,大页面测试速度提高了38%。大页面测试的曲线在大约250个周期处处于平稳状态。除了2个27字节的工作集之外,数字再次显着增加。达到平稳状态的原因是2MB页的64个TLB条目覆盖2 27个字节。
如这些数字所示,使用大型工作台尺寸的大部分成本来自TLB缺失。使用本节中描述的接口可以节省大量时间。图中的数字很可能是上限,但即使是实际程序也显示出明显的加速。由于数据库使用大量数据,因此它们是当今使用大量页面的程序之一。
当前无法使用大页面来映射文件支持的数据。有实现这种功能的兴趣,但是到目前为止提出的建议都涉及显式使用大页面,并且它们依赖于 hugetlbfs文件系统。这是不可接受的:这种情况下的大页面使用必须是透明的。内核可以轻松确定哪些映射较大,并自动使用较大的页面。一个大问题是内核并不总是知道使用模式。如果内存可以映射为大页面,则以后需要4k页粒度(例如,因为使用mprotect更改了部分内存范围的保护,)会浪费很多宝贵的资源,尤其是线性物理内存。因此,成功实施这种方法肯定还需要更多时间。
记忆第8部分:未来技术8即将推出的技术
在前面有关多处理器处理的各节中,我们已经看到,如果按比例增加CPU或内核的数量,则必须预料到明显的性能问题。但是,这种扩展正是未来所期望的。处理器将拥有越来越多的内核,并且程序必须越来越并行以利用CPU潜力的增加,因为单核性能不会像以前那样迅速地提高。
8.1原子操作问题
传统上,同步访问共享数据结构的方式有两种:
- 通过互斥,通常通过使用系统运行时的功能来实现这一目标;
- 通过使用无锁数据结构。
无锁数据结构的问题在于,处理器必须提供可以原子地执行整个操作的原语。这种支持是有限的。在大多数体系结构上,支持仅限于原子读取和写入单词。有两种基本的实现方法(请参见第6.4.2节):
- 使用原子比较和交换(CAS)操作;
- 使用加载锁定/存储条件(LL / SC)对。
可以很容易地看出如何使用LL / SC指令实现CAS操作。这使CAS操作成为大多数原子操作和无锁数据结构的构建块。
一些处理器,尤其是x86和x86-64体系结构,提供了更为详尽的原子操作集。其中许多是针对特定目的的CAS操作的优化。例如,可以使用CAS和LL / SC操作以原子方式将值添加到内存位置,但是对x86 / x86-64处理器上原子增量的本机支持更快。对于程序员而言,重要的是要了解这些操作以及使它们在编程时可用的内在函数,但这并不是什么新鲜事物。
这两种体系结构的非凡扩展是它们具有双字CAS(DCAS)操作。这对于某些应用程序(但不是全部)很重要(请参阅[dcas])。作为如何使用DCAS的示例,让我们尝试编写基于阵列的无锁堆栈/ LIFO数据结构。在图8.1中可以看到使用gcc内在函数的第一次尝试。
struct elem { data_t d; struct elem * c; }; struct elem * top; 无效推(struct elem * n){ n-> c =顶部; 顶部= n; } struct elem * pop(void){ struct elem * res = top; 如果(res!= NULL) 顶部= res-> c; 返回资源; }图8.1:不是线程安全的LIFO
此代码显然不是线程安全的。不同线程中的并发访问将修改全局变量top,而无需考虑其他线程的修改。元素可能丢失或被删除,元素可以神奇地重新出现。可以使用互斥,但在这里我们将尝试仅使用原子操作。
解决此问题的首次尝试是在安装或删除列表元素时使用CAS操作。生成的代码如图8.2所示。
#定义CAS __sync_bool_compare_and_swap struct elem { data_t d; struct elem * c; }; struct elem * top; 无效推(struct elem * n){ 做 n-> c =顶部; while(!CAS(&top,n-> c,n)); } struct elem * pop(void){ struct elem * res; 而((res = top)!= NULL) 如果(CAS(&top,res,res-> c)) 打破; 返回资源; }图8.2:使用CAS的LIFO
乍看之下,这似乎是一个可行的解决方案。 顶部绝不会被修改,除非它这是在LIFO的顶部的操作开始时的元素相匹配。但是我们必须考虑所有级别的并发性。可能是在最坏的时刻安排了另一个在数据结构上工作的线程。这里的一种情况就是所谓的ABA问题。请考虑一下,如果在弹出的CAS操作之前安排了第二个线程并执行以下操作,将会发生什么情况:
- l = pop()
- 推(newelem)
- 推(l)
此操作的最终结果是,LIFO的前一个顶部元素返回顶部,但第二个元素不同。返回第一个线程,因为top元素未更改,所以CAS操作将成功。但是,值res-> c不合适。它是原始LIFO的第二个元素的指针,而不是newelem的指针。结果是这个新元素丢失了。
在[lockfree]文献中,您找到了使用某些处理器上的功能来解决此问题的建议。具体地说,这与x86和x86-64处理器执行DCAS操作的能力有关。这在图8.3的代码的第三种形式中使用。
#定义CAS __sync_bool_compare_and_swap struct elem { data_t d; struct elem * c; }; struct lifo { struct elem * top; size_t gen; } l; 无效推(struct elem * n){ struct lifo旧,新; 做{ 旧= l; new.top = n-> c = old.top; new.gen = old.gen +1; } while(!CAS(&l,old,new)); } struct elem * pop(void){ struct lifo旧,新; 做{ 旧= l; 如果(old.top == NULL)返回NULL; new.top = old.top-> c; new.gen = old.gen +1; } while(!CAS(&l,old,new)); 返回old.top; }图8.3:使用双字CAS的LIFO
与其他两个示例不同,这是(当前)伪代码,因为gcc不会破坏CAS内部函数中结构的使用。无论如何,该示例应该足以理解该方法。将生成计数器添加到指向LIFO顶部的指针。由于在每次操作push或pop时都会对其进行更改,因此上述ABA问题不再是问题。到第一个线程通过实际交换顶部 指针恢复工作时,生成计数器已经增加了三倍。CAS操作将失败,并且在循环的下一轮中,将确定LIFO的正确的第一和第二元素,并且LIFO不会损坏。Voilà。
这真的是解决方案吗?[lockfree]的作者肯定听起来像这样,值得称赞的是,有可能为LIFO构造数据结构,这将允许使用上面的代码。但是,总的来说,这种方法与前一种方法一样注定要失败。只是在另一个地方,我们仍然存在并发问题。让我们假设一个线程执行pop 并且在测试old.top == NULL之后被中断。现在,第二个线程使用pop并获得了LIFO先前第一个元素的所有权。它可以执行任何操作,包括更改所有值,或者在动态分配元素的情况下,释放内存。
现在,第一个线程恢复。在旧变量仍然充满了后进先出法的前顶部。更具体地说,顶部 成员指向第二个线程弹出的元素。在 new.top = old.top-> c中第一个线程取消引用元素中的指针。但是此指针引用的元素可能已释放。地址空间的该部分可能无法访问,并且进程可能崩溃。通用数据类型实现不允许这样做。解决此问题的方法非常昂贵:绝不能释放内存,或者至少必须在释放之前验证没有线程再引用该内存。考虑到无锁数据结构应该更快,更并发,这些额外的要求完全破坏了任何优势。在支持它的语言中,通过垃圾回收处理内存可以解决问题,但这要付出代价。
对于更复杂的数据结构,情况通常更糟。上面引用的同一篇论文还描述了FIFO实现(在后续论文中进行了改进)。但是这段代码有同样的问题。由于在现有硬件(x86,x86-64)上的CAS操作仅限于修改在内存中连续的两个字,因此在其他常见情况下它们根本没有帮助。例如,不可能在双向链接列表中的任何位置自动添加或删除元素。{作为旁注,IA-64的开发人员 未包含此功能。它们允许比较两个单词,但只能替换一个单词。}
问题是通常涉及多个内存地址,并且只有这些地址的值没有同时更改时,整个操作才能成功。这是数据库处理中的一个众所周知的概念,而这正是解决这一难题的最有希望的建议之一。
8.2交易记忆
Herlihy和Moss在其开创性的1993年论文[transactmem]中提出要在硬件中实现用于内存操作的事务,因为仅靠软件不能有效地解决问题。当时的数字设备公司(Digital Equipment Corporation)已经在其高端硬件(具有几十个处理器)上应对可扩展性问题。原理与数据库事务相同:事务的结果立即变为可见,或者事务中止并且所有值保持不变。
这就是内存发挥作用的地方,也是上一节为什么费心开发使用原子运算的算法的原因。在许多情况下,尤其是对于无锁数据结构,事务性内存是原子操作的替代和扩展。将事务处理系统集成到处理器中听起来很复杂,但是实际上,大多数处理器在某种程度上已经具有类似的功能。
由某些处理器实现的LL / SC操作形成事务。SC指令根据是否触摸了内存位置来中止或提交事务。事务性内存是此概念的扩展。现在,代替简单的一对指令,多个指令参与了交易。要了解它是如何工作的,值得首先了解如何实现LL / SC指令。{这并不意味着它实际上是这样实现的。}
8.2.1加载锁定/存储条件实现
如果发出LL指令,则将存储单元的值加载到寄存器中。作为该操作的一部分,将该值加载到L1d中。如果未修改此值,则以后SC指令才能成功。处理器如何检测到这一点?回顾图3.18中对MESI协议的描述,答案将显而易见。如果另一个处理器更改了内存位置的值,则必须撤消第一个处理器的L1d中的值的副本。当在第一个处理器上执行SC指令时,它将发现它必须再次将该值加载到L1d中。这是处理器必须已经检测到的东西。
关于上下文切换(可能在同一处理器上进行修改)以及在另一个处理器上进行写操作后意外重载高速缓存行,还有一些其他细节需要解决。这是策略(上下文切换上的缓存刷新)和额外的标志或LL / SC指令的单独缓存行无法解决的所有问题。通常,LL / SC实现几乎是免费提供的,例如MESI这样的缓存一致性协议的实现。
8.2.2事务性内存操作
为了使事务性存储大体上有用,不得使用第一条存储指令来完成事务。相反,实现应允许一定数量的加载和存储操作。这意味着我们需要单独的提交和中止指令。稍后,我们将需要再执行一条指令,该指令可以检查事务的当前状态以及它是否已经中止。
要实现三种不同的内存操作:
- 读取内存
- 读取稍后写入的内存
- 写记忆
当查看MESI协议时,应该清楚这种特殊的第二种读取操作如何有用。正常读取可以通过处于“ E”和“ S”状态的高速缓存行来满足。第二种读取操作需要状态为“ E”的高速缓存行。从下面的讨论中可以确切地了解为什么需要第二种类型的内存读取,但是对于更完整的描述,有兴趣的读者可以从[transactmem]开始参考有关事务性内存的文献。
另外,我们需要事务处理,它主要由数据库事务处理中已经熟悉的提交和中止操作组成。但是,还有另一种操作,从理论上讲是可选的,但是使用事务性存储器编写健壮的程序是必需的。该指令使线程可以测试事务是否仍在进行中并可以(也许)稍后进行提交,或者事务是否已经失败并且在任何情况下都将中止。
我们将讨论这些操作实际上如何与CPU缓存交互以及它们如何与总线操作匹配。但是在我们这样做之前,我们先看一些使用事务性内存的实际代码。希望这会使本节的其余部分更容易理解。
8.2.3使用事务性内存的示例代码
对于该示例,我们将重新访问正在运行的示例,并显示使用事务性内存的LIFO实现。
struct elem { data_t d; struct elem * c; }; struct elem * top; 无效推(struct elem * n){ 而(1){ n-> c = LTX(top); ST(&top,n); 如果(COMMIT()) 返回; ...延迟... } } struct elem * pop(void){ 而(1){ struct elem * res = LTX(top); 如果(VALIDATE()){ 如果(res!= NULL) ST(&top,res-> c); 如果(COMMIT()) 返回资源; } ...延迟... } }图8.4:LIFO使用事务性内存
该代码看起来与非线程安全代码非常相似,这是一个额外的好处,因为它使使用事务性内存编写代码更加容易。该代码的新部分是LTX,ST, COMMIT和VALIDATE操作。这四个操作是请求访问事务性存储器的方式。实际上还有另外一个操作LT,这里不使用。 LT请求非独占读取访问,LTX请求独占读取访问,ST是存储在事务内存中的存储区。该VALIDATEoperation是检查事务是否仍在进行中的操作。如果此事务仍然正常,则返回true。如果该事务已被标记为正在中止,则它将实际上被中止,并且下一条事务存储指令将开始一个新的事务。因此,如果事务仍在进行,则代码使用新的if块。
该COMMIT操作完成交易; 如果事务成功完成,则操作返回true。这意味着程序的这一部分已经完成,线程可以继续前进。如果该操作返回错误值,这通常意味着必须重复整个代码序列。这就是外部while 循环在这里执行的操作。这并不是绝对必要的,但是在某些情况下,放弃工作是正确的选择。
关于LT,LTX和ST 操作的有趣之处在于,它们可以失败而不会以任何直接方式发出信号通知此失败。程序请求此信息的方式是通过VALIDATE或COMMIT操作。对于加载操作,这可能意味着实际加载到寄存器中的值可能是伪造的。这就是为什么在上面的示例中必须使用 VALIDATE的原因在取消引用指针之前。在下一节中,我们将了解为什么这是实现的明智选择。可能是,一旦事务内存实际可用,处理器将实现不同的功能。不过,[transactmem]的结果表明了我们在此处描述的内容。
该推送功能可以概括为这样的:交易是通过读取指针链表的头开始。读取请求排他所有权,因为在该函数的后面,写入了该变量。如果另一个线程已经启动了事务,则加载将失败,并将仍然存在的事务标记为已中止;在这种情况下,实际加载的值可能是垃圾。不论其状态如何,该值都存储在下一个新列表成员的字段。很好,因为该成员尚未使用,并且只能由一个线程访问。然后将指向列表开头的指针分配给新元素的指针。如果事务仍然正常,则此写入可以成功。这是正常情况,只有在线程使用提供的push和 pop函数以外的其他代码访问此指针时,它才会失败。 如果交易在ST时已经中止被执行,什么也不做。最后,线程尝试提交事务。如果成功,那么工作就完成了;其他线程现在可以开始其事务。如果交易失败,则必须从头开始重复。但是,在此之前,最好插入一个延迟。如果不这样做,线程可能会在繁忙的循环中运行(浪费能量,导致CPU过热)。
该弹出功能稍微复杂一些。它还从读取包含列表开头的变量开始,请求排他所有权。然后,代码立即检查LTX操作是否 成功。如果不是这样,则本轮除了延迟下一轮外没有其他动作。如果成功读取了顶部指针,则表示其状态为良好;我们现在可以取消引用指针。记住,这正是使用原子操作的代码的问题。有了事务性内存,这种情况就可以毫无问题地处理了。以下ST仅当LIFO不为空时才执行操作,就像原始的线程不安全代码一样。最后,交易被提交。如果成功,函数将旧指针返回到头部;否则,我们将延迟并重试。该代码的一个棘手的部分是要记住,如果VALIDATE操作已经失败,它将中止该事务。下一个事务存储操作将启动一个新事务,因此,我们必须跳过该函数中的其余代码。
当硬件中可用事务存储实现时,将看到延迟代码如何工作。如果做得不好,系统性能可能会受到很大影响。
8.2.4事务性存储器的总线协议
既然我们已经了解了事务存储背后的基本原理,我们就可以深入研究实现的细节。请注意,这 不是基于实际的硬件。它基于事务性存储器的原始设计和有关缓存一致性协议的知识。省略了一些细节,但仍然应该有可能深入了解性能特征。
事务性内存实际上并未实现为单独的内存;考虑到需要在线程地址空间中任何位置上进行事务,这毫无意义。相反,它是在第一个缓存级别实现的。从理论上讲,该实现可以在正常的L1d中进行,但是,正如[transactmem]所指出的,这不是一个好主意。我们将更可能看到与L1d并行实现的事务缓存。所有访问将以与使用L1d相同的方式使用更高级别的缓存。事务缓存可能比L1d小得多。如果它是完全关联的,则其大小由事务可包含的操作数确定。实施可能会限制体系结构和/或特定处理器版本。可以轻松想象一个具有16个甚至更少元素的事务缓存。在上面的示例中,我们只需要一个内存位置;具有较大事务工作集的算法变得非常复杂。我们可能会看到处理器在任何时候都支持多个活动事务。然后,高速缓存中的元素数量相乘,但是它仍然足够小,可以完全关联。
事务缓存和L1d是互斥的。这意味着,一条高速缓存行最多位于其中一个高速缓存中,而从不在两个高速缓存中。事务高速缓存中的每个插槽在任何时候都处于四个MESI协议状态之一。除此之外,插槽还具有事务状态。状态如下(根据[transactmem]命名):
- 空
- 高速缓存插槽中没有数据。MESI状态始终为“ I”。
- 正常
- 缓存插槽中包含已提交的数据。数据也可能存在于L1d中。MESI状态可以是“ M”,“ E”和“ S”。允许使用“ M”状态这一事实意味着事务提交 不会强制将数据写入主内存(除非将内存区域声明为未缓存或直写)。这可以极大地帮助提高性能。
- XABORT
- 高速缓存插槽中包含在中止时被丢弃的数据。这显然与XCOMMIT相反。在事务期间创建的所有数据都保存在事务缓存中,在提交之前没有任何内容写入主内存。这限制了最大事务大小,但是这意味着,除了事务缓存之外,其他任何内存都不必知道单个内存位置的XCOMMIT / XABORT对偶性。MESI可能的状态为“ M”,“ E”和“ S”。
- XCOMMIT
- 高速缓存插槽中包含在提交时丢弃的数据。这是处理器可以实现的可能的优化。如果使用事务操作更改了内存位置,则不能仅删除旧内容:如果事务失败,则需要恢复旧内容。MESI状态与XABORT相同。关于XABORT的一个区别是,如果事务缓存已满,则可以将任何处于“ M”状态的XCOMMIT条目写回到内存,然后对于所有状态都将其丢弃。
当启动LT操作时,处理器会在高速缓存中分配两个插槽。通过首先为操作的地址(即高速缓存命中)寻找NORMAL插槽来选择受害者。如果找到这样的条目,则找到第二个插槽,复制值,将一个条目标记为XABORT,将另一个标记为XCOMMIT。
如果该地址尚未缓存,则找到EMPTY缓存槽。如果找不到,则寻找NORMAL插槽。如果MESI状态为“ M”,则必须将旧内容刷新到内存中。如果任何一个NORMAL插槽都不可用,则可能会损害XCOMMIT条目。不过,这很可能是实现细节。事务的最大大小由事务高速缓存的大小确定,并且由于事务中每个操作所需的插槽数是固定的,因此在不必退出XCOMMIT条目之前可以限制事务数。
如果在事务高速缓存中找不到该地址,则会在总线上发出T_READ请求。这就像普通的READ总线请求一样,但是它表明这是用于事务性缓存的。就像普通的READ请求一样,所有其他处理器中的缓存都首先有机会做出响应。如果没有,则从主存储器读取该值。MESI协议确定新缓存行的状态是“ E”还是“ S”。当另一个处理器或内核上的活动事务当前正在使用高速缓存行时,T_READ和READ之间的区别就会发挥作用。在这种情况下,T_READ操作显然失败,不传输任何数据。生成T_READ总线请求的事务被标记为失败,并且操作中使用的值(通常是简单的寄存器加载)未定义。回顾示例,我们可以看到,如果正确使用事务性内存操作,则此行为不会引起问题。在使用加载到事务中的值之前,必须使用验证。在几乎没有情况下,这是一个额外的负担。正如我们在尝试使用原子操作创建FIFO实现中所看到的那样,我们添加的检查是使无锁代码正常工作的一项缺失功能。
所述LTX操作几乎是相同的LT。一个区别是总线操作是T_RFO而不是T_READ。与正常的RFO总线请求一样,T_RFO请求高速缓存行的排他所有权。结果高速缓存行的状态为“ E”。像T_READ总线请求一样,T_RFO也会失败,在这种情况下,使用的值也是未定义的。如果高速缓存行已经在本地事务高速缓存中,处于“ M”或“ E”状态,则无需执行任何操作。如果本地事务缓存中的状态为“ S”,则总线请求必须退出以使所有其他副本无效。
在ST操作类似于LTX。该值首先在本地事务高速缓存中专用。然后, ST操作将值的副本复制到缓存中的第二个插槽中,并将该条目标记为XCOMMIT。最后,另一个插槽被标记为XABORT,并将新值写入其中。如果事务已被中止,或者由于隐式LTX 失败而被新中止,则不会写入任何内容。
VALIDATE或COMMIT 都没有自动操作会隐式创建总线操作。这是事务性内存比原子操作具有的巨大优势。使用原子操作,可以通过将更改的值写回到主存储器来实现并发。如果您到目前为止已经阅读了本文档,则应该知道它的价格是多少。使用事务性内存时,不会强制访问主内存。如果高速缓存没有EMPTY插槽,则必须清除当前内容,对于处于“ M”状态的插槽,必须将内容写入主内存。这与常规缓存没有什么不同,并且回写无需特殊的原子性保证即可执行。如果缓存大小足够,则内容可以生存很长时间。如果一次又一次在同一内存位置执行事务,
对于中止的事务, 所有VALIDATE和COMMIT操作都将标记为XABORT的缓存插槽标记为空,并将XCOMMIT插槽标记为NORMAL。同样,当COMMIT 成功完成事务时,XCOMMIT插槽标记为空,而XABORT插槽标记为NORMAL。这些是对事务缓存的非常快速的操作。没有显式通知要处理的其他处理器。这些处理器只需要继续尝试。有效地做到这一点是另一回事。在上面的示例代码中,我们只是 在适当的位置放置了... delay...。我们可能会看到实际的处理器支持以有用的方式进行延迟。
总而言之,事务性存储器操作仅在启动新事务并将事务高速缓存中尚未存在的新高速缓存行添加到仍成功的事务中时才引起总线操作。中止的事务中的操作不会导致总线操作。由于有多个线程试图使用同一内存,因此不会有缓存行乒乓。
8.2.5其他考虑
在6.4.2节中,我们已经讨论了在某些情况下如何使用x86和x86-64上可用的锁前缀来避免对原子操作进行编码。但是,当有多个线程在使用不争夺同一内存的线程时,建议的技巧就不够了。在这种情况下,不必要使用原子操作。有了事务性内存,这个问题就消失了。仅当在不同CPU上同时或连续使用内存时,才会发出昂贵的RFO总线请求。仅在需要它们时才如此。做得更好几乎是不可能的。
细心的读者可能会对延迟感到好奇。预期的最坏情况是什么?如果对具有活动事务的线程进行了调度,或者接收到信号并可能终止了该线程,或者决定使用siglongjmp跳转到外部作用域,该怎么办?答案是:事务将中止。每当线程进行系统调用或接收信号(即发生环级更改)时,就有可能中止事务。在执行系统调用或处理信号时,中止事务也可能是操作系统的职责之一。我们将不得不等到实现可用后才能看到实际完成的工作。
事务存储的最后一个方面应该在这里讨论,这是人们甚至在今天仍要考虑的问题。事务缓存与其他缓存一样,在缓存行上运行。由于事务缓存是专用缓存,因此使用相同的缓存行进行事务和非事务操作将是一个问题。因此,重要的是
- 将非事务性数据移出缓存行
- 具有用于单独事务中的数据的单独缓存行
第一点不是新问题,同样的努力将为今天的原子操作带来回报。第二个问题更大,因为如今由于相关的高成本,对象几乎从未与高速缓存行对齐。如果所使用的数据以及使用原子操作修改过的单词位于同一高速缓存行中,则需要少一个高速缓存行。这不适用于互斥(互斥对象应始终具有其自己的缓存行),但是可以肯定的是,原子操作会与其他数据一起出现。对于事务性内存,将高速缓存行用于两个目的将很可能致命。每次对数据的常规访问{来自所涉及的缓存行。访问任意其他高速缓存行不会影响事务。}将从事务缓存中删除缓存行,从而中止该事务。将来,数据对象的缓存对齐不仅是性能问题,而且是准确性问题。
事务性内存实现可能会使用更精确的计费方式,因此,可能不会正常访问作为事务一部分的高速缓存行上的数据。但是,这需要付出更多的努力,因为那时MESI协议信息已不再足够。
8.3增加延迟
关于存储器技术的未来发展的一件事几乎可以肯定:延迟将继续增加。在第2.2.4节中,我们已经讨论了即将到来的DDR3内存技术将比当前的DDR2技术具有更高的延迟。如果应该部署FB-DRAM,则FB-DRAM的潜在延迟也可能更高,尤其是当FB-DRAM模块以菊花链方式连接时。传递请求和结果不是免费的。
延迟的第二个来源是NUMA的使用增加。如果AMD的Opterons具有多个处理器,则它们是NUMA计算机。通过其自己的内存控制器将一些本地内存附加到CPU,但是在SMP主板上,其余的内存必须通过Hypertransport总线进行访问。英特尔的CSI技术将使用几乎相同的技术。由于每个处理器的带宽限制以及保持(例如)多个10Gb / s以太网端口繁忙的要求,即使每个插槽的内核数量增加,多插槽主板也不会消失。
延迟的第三个来源是协处理器。我们认为,在1990年代初不再需要用于商品处理器的数学协处理器之后,我们就摆脱了它们,但是它们正在卷土重来。英特尔的Geneseo和AMD的Torrenza是该平台的扩展,允许第三方硬件开发人员将其产品集成到主板中。即,协处理器将不必坐在PCIe卡上,而是位于更靠近CPU的位置。这给了他们更多的带宽。
IBM在Cell CPU上走了一条不同的路线(尽管仍然可以进行像Intel和AMD这样的扩展)。除PowerPC内核外,单元CPU还包含8个协同处理单元(SPU),它们是主要用于浮点计算的专用处理器。
协处理器和SPU的共同点是,它们最有可能比实际处理器具有更慢的内存逻辑。部分原因是由于必要的简化:所有缓存处理,预取等都很复杂,尤其是在需要缓存一致性的情况下。高性能程序将越来越依赖于协处理器,因为性能差异可能很大。单元CPU的理论峰值性能为210 GFLOPS,而高端CPU的理论峰值性能为50-60 GFLOPS。当前使用的图形处理单元(GPU,图形卡上的处理器)的数量甚至更高(超过500 GFLOPS),并且可以不费吹灰之力将它们集成到Geneseo / Torrenza系统中。
所有这些发展的结果是,程序员必须得出结论,预取将变得越来越重要。对于协处理器而言,这绝对是至关重要的。对于CPU(尤其是具有越来越多的内核)的CPU,有必要始终保持FSB繁忙,而不是分批堆积请求。这就要求CPU通过有效使用预取指令来尽可能深入地了解将来的流量。
8.4向量运算
当今主流处理器中的多媒体扩展仅以有限的方式实现矢量操作。向量指令的特点是可以一起执行大量的操作。与标量运算相比,这可以说是关于多媒体指令的,但是与矢量计算机(如Cray-1)或矢量单元(如IBM 3090)所做的工作相去甚远。
为了补偿为一条指令执行的有限数量的操作(大多数机器上为四个 浮点或两个 双精度运算),必须更频繁地执行周围的循环。9.1节中的示例清楚地说明了这一点,每个高速缓存行都需要SM迭代。
使用更宽的向量寄存器和操作,可以减少循环迭代的次数。这不仅可以改善指令解码等。在这里,我们对记忆效应更感兴趣。通过单个指令加载或存储更多数据,处理器可以更好地了解应用程序的内存使用情况,而不必尝试将各个指令的行为信息汇总在一起。此外,提供不影响高速缓存的加载或存储指令变得更加有用。在x86 CPU中使用16字节宽的SSE寄存器加载时,使用未缓存的加载是个坏主意,因为以后对同一缓存行的访问必须再次从内存中加载数据(如果发生缓存丢失)。另一方面,如果 向量寄存器足够宽,可以容纳一个或多个缓存行,未缓存的负载或存储不会产生负面影响。对不适合高速缓存的数据集执行操作变得更加实际。
具有大的向量寄存器并不一定意味着指令的等待时间会增加。向量指令不必等待读取或存储所有数据。如果矢量单元可以识别代码流,则可以从已经读取的数据开始。这意味着,例如,如果要加载向量寄存器,然后将所有向量元素乘以标量,则一旦向量的第一部分已加载,CPU便可以开始乘法操作。这仅仅是向量单位的复杂性问题。这表明,从理论上讲,向量寄存器可以真正地变宽,并且考虑到这一点,现在可以潜在地设计程序。在实践中,由于处理器用于多进程和多线程OS中,因此矢量寄存器的大小受到限制。因此,上下文切换时间非常重要,其中包括存储和加载寄存器值。
对于较宽的向量寄存器,存在一个问题,即操作的输入和输出数据无法顺序地放置在内存中。这可能是因为矩阵是稀疏的,矩阵是由列而不是行访问的,以及许多其他因素。在这种情况下,矢量单元提供了以非顺序模式访问内存的方法。可以对单个向量加载或存储进行参数设置,并指示其从地址空间中许多不同位置加载数据。使用今天的多媒体说明,这是完全不可能的。必须将这些值一一显式地加载,然后将其精心组合到一个向量寄存器中。
过去的向量单位具有不同的模式,以允许使用最有用的访问模式:
- 使用striding,程序可以指定两个相邻向量元素之间的间隙有多大。所有元素之间的间隙必须相同,但是,例如,这很容易允许用一条指令而不是每行一条指令将矩阵的列读入向量寄存器。
- 使用间接,可以创建任意访问模式。加载或存储指令将接收一个指向数组的指针,该数组包含必须加载的实存储器位置的地址或偏移量。
目前尚不清楚在未来版本的主流处理器中我们是否会看到真正的矢量运算的复兴。也许这项工作将降级到协处理器。无论如何,如果我们可以访问矢量操作,那么正确组织执行此类操作的代码就显得尤为重要。该代码应该是自包含的并且是可替换的,并且接口应该足够通用以有效地应用矢量运算。例如,接口应该允许添加整个矩阵,而不是对行,列甚至元素组进行操作。构建块越大,使用向量运算的机会就越大。
在[vectorops]中,作者强烈呼吁恢复向量操作。他们指出了许多优势,并试图揭穿各种神话。但是,它们绘制的图像过于简单。如上所述,大寄存器集意味着高上下文切换时间,在通用OS中必须避免。当涉及到上下文切换密集型操作时,请查看IA-64处理器的问题。如果涉及到中断,向量操作的执行时间也很长。如果引发中断,则处理器必须停止其当前工作并开始处理中断。之后,它必须恢复执行中断的代码。在工作中中断指令通常是一个很大的问题。这不是不可能,但是很复杂。对于长时间运行的指令,这必须发生,或者指令必须以可重新启动的方式执行,因为否则中断响应时间会太长。后者是不可接受的。
就内存访问的对齐而言,向量单元也是宽容的,它决定了所开发的算法。当今的某些处理器(尤其是RISC处理器)需要严格的对齐方式,因此扩展到全矢量操作并不容易。向量操作存在很大的潜在优势,尤其是在支持跨步和间接调用时,因此我们希望将来能够看到此功能。
记忆第9部分:附录和书目9个示例和基准程序
9.1矩阵乘法
这是第6.2.1节中矩阵乘法的完整基准程序。有关所使用的内在函数的详细信息,请参阅《英特尔参考手册》。
#include <stdlib.h> #include <stdio.h> #include <emmintrin.h> #定义N 1000 double res [N] [N] __attribute__((aligned(64))); double mul1 [N] [N] __attribute__((aligned(64))); double mul2 [N] [N] __attribute__((aligned(64)))); #定义SM(CLS / sizeof(双精度))整型 主(无效) { // ...初始化mul1和mul2
int i,i2,j,j2,k,k2; 双重限制 双* restrict rmul1; 双* restrict rmul2; 对于(i = 0; i <N; i + = SM) 对于(j = 0; j <N; j + = SM) 对于(k = 0; k <N; k + = SM) 对于(i2 = 0,rres =&res [i] [j],rmul1 =&mul1 [i] [k]; i2 <SM; ++ i2,rres + = N,rmul1 + = N) { _mm_prefetch(&rmul1 [8],_MM_HINT_NTA); 对于(k2 = 0,rmul2 =&mul2 [k] [j]; k2 <SM; ++ k2,rmul2 + = N) { __m128d m1d = _mm_load_sd(&rmul1 [k2]); m1d = _mm_unpacklo_pd(m1d,m1d); 对于(j2 = 0; j2 <SM; j2 + = 2) { __m128d m2 = _mm_load_pd(&rmul2 [j2]); __m128d r2 = _mm_load_pd(&rres [j2]); _mm_store_pd(&rres [j2], _mm_add_pd(_mm_mul_pd(m2,m1d),r2)); } } }
// ...使用res矩阵
返回0; }
循环的结构与第6.2.1节中的最终版本几乎相同。一个重大变化是,加载rmul1 [k2]值已从内部循环中退出,因为我们必须创建一个两个元素都具有相同值的向量。这就是_mm_unpacklo_pd()内部函数所做的。
唯一值得一提的是,我们显式地对齐了三个数组,以便实际上可以在同一缓存行中找到我们期望的值。
9.2调试分支预测
如果按照建议 使用了6.2.2节中可能和不太可能的定义,则很容易{至少使用GNU工具链。使用调试模式来检查这些假设是否真的正确。宏的定义可以替换为:
#ifndef DEBUGPRED #定义不太可能的(expr)__ builtin_expect(!!(expr),0) #定义可能性(expr)__builtin_expect(!!(expr),1) #其他 asm(“ .section Forecast_data,” aw “; .previous n” “ .section预报_line,” a “;。上一个 n” “ .section Forecast_file,” a “; .previous”); #ifdef __x86_64__ #定义debugpred __(e,E) ({long int _e = !!(e); asm volatile(“ .pushsection Forecast_data n” “ ..predictcnt%=:.quad 0; .quad 0 n” “ .section Forecast_line; .quad%c1 n” “ .section Forecast_file; .quad%c2; .popsection n” “ addq $ 1,.. predictcnt%=(,%0,8)” ::“ r”(_e == E),“ i”(__LINE__),“ i”(__FILE__)); __builtin_expect(_e,E); }) #elif定义__i386__ #定义debugpred __(e,E) ({long int _e = !!(e); asm volatile(“ .pushsection Forecast_data n” “ ..predictcnt%=:.long 0; .long 0 n” “ .section Forecast_line; .long%c1 n” “ .section预报文件; .long%c2; .popsection n” “包括..predictcnt%=(,%0,4)” ::“ r”(_e == E),“ i”(__LINE__),“ i”(__FILE__)); __builtin_expect(_e,E); }) #其他 #错误“ debugpred__定义缺失” # 万一 #定义不太可能的(expt)debugpred__((expr),0) #定义可能的(expr)debugpred__((expr),1) #万一
创建ELF文件时,这些宏使用GNU汇编器和链接器提供的许多功能。DEBUGPRED案例中的第一个asm语句 定义了另外三个部分;它主要为汇编器提供有关如何创建节的信息。所有部分都可以在运行时使用, predict_data部分是可写的。所有节名称都是有效的C标识符,这一点很重要。原因很快就会清楚。
可能和不太可能的宏 的新定义是指特定于计算机的debugpred__宏。该宏具有以下任务:
- 在predict_data节中分配两个词以包含正确和不正确预测的计数。这两个字段通过使用%=获得唯一的名称;前导点确保符号不会污染符号表。
- 在predict_line部分中分配一个单词,以包含可能或不太可能使用宏的行号。
- 在predict_file节中分配一个字,以包含一个指向可能或不太可能 使用宏的文件名的指针。
- 根据表达式e的实际值,递增为此宏创建的“正确”或“错误”计数器。我们此处不使用原子操作,因为它们的运行速度非常慢,而且在不太可能发生的碰撞情况下绝对精度也不是那么重要。如果需要,很容易进行更改。
的.pushsection和.popsection伪操作在汇编手册中有描述。有兴趣的读者可以在手册的帮助下尝试一些定义,并尝试一些错误。
这些宏自动透明地负责收集有关正确和不正确的分支预测的信息。缺少的是获得结果的方法。最简单的方法是为对象定义一个析构函数,并在那里打印出结果。这可以通过定义如下的函数来实现:
extern long int __start_predict_data; extern long int __stop_predict_data; extern long int __start_predict_line; extern const char * __ start_predict_file;静态空隙 __attribute__((析构函数)) 预印本(void) { long int * s =&__ start_predict_data; long int * e =&__ stop_predict_data; long int * sl =&__ start_predict_line; const char ** sf =&__ start_predict_file; 而(s <e){ printf(“%s:%ld:不正确=%ld,正确=%ld%s n”,* sf,* sl,s [0],s [1], s [0]> s [1]?“ <====警告”:“”); ++ sl; ++ sf; s + = 2; } }
段名称是有效的C标识符的事实在这里发挥了作用;如果需要,GNU链接器使用它自动为该部分定义两个符号。所述 __start_ XYZ符号对应于部分的开始XYZ和__stop_ XYZ是以下部分中的第一字节的位置XYZ。这些符号使得可以在运行时遍历节内容。请注意,由于节的内容可以来自链接器在链接时使用的所有文件,因此编译器和汇编器没有足够的信息来确定节的大小。只有使用这些神奇的链接器生成的符号,才可以遍历部分内容。
但是,该代码并不只迭代一个部分。涉及三个部分。因为我们知道,对于添加到predict_data部分中的每两个单词,我们将一个单词添加到predict_line和predict_file部分中的每一个,所以 我们不必检查这两个部分的边界。我们只是随身携带指针,并一致地增加它们。
该代码为出现在代码中的每个预测打印出一行。它突出显示了预测不正确的那些用途。当然,可以更改此设置,并且可以将调试模式限制为仅标记那些预测比正确预测更多的条目。这些是变革的候选人。有一些细节使问题复杂化;例如,如果分支预测发生在用于多个地方的宏内,则在做出最终判断之前必须将所有宏使用一起考虑。
最后两个评论:该调试操作所需的数据不小,并且在DSO的情况下非常昂贵( 必须重新定位预测文件部分)。因此,不应在生产二进制文件中启用调试模式。最后,每个可执行文件和DSO都会创建自己的输出,在分析数据时必须牢记这一点。
9.3测量缓存行共享开销
本节包含测试程序,用于测量在同一高速缓存行上使用变量与在单独的高速缓存行上使用变量的开销。
#include <error.h> #include <pthread.h> #include <stdlib.h> #define N(atomic?10000000:500000000) 静态int原子; 静态无符号nthreads; 静态无符号显示; 静态长**读取; 静态pthread_barrier_t b; 静态虚空* tf(无效* arg) { 长* p = arg; 如果(原子) 对于(int n = 0; n <N; ++ n) __sync_add_and_fetch(p,1); 其他 对于(int n = 0; n <N; ++ n) { * p + = 1; asm volatile(“”::“ m”(* p)); } 返回NULL; } 整型 main(int argc,char * argv []) { 如果(argc <2) 显示= 0; 其他 disp = atol(argv [1]); 如果(argc <3) nthreads = 2; 其他 nthreads = atol(argv [2])?:1; 如果(argc <4) 原子= 1; 其他 原子= atol(argv [3]); pthread_barrier_init(&b,NULL,nthreads); 无效* p; posix_memalign(&p,64,(nthreads * disp?:1)* sizeof(long)); 长* mem = p; pthread_t th [nthreads]; pthread_attr_t a; pthread_attr_init(&a); cpu_set_t c; for(无符号i = 1; i <nthreads; ++ i) { CPU_ZERO(&c); CPU_SET(i,&c); pthread_attr_setaffinity_np(&a,sizeof(c),&c); mem [i * disp] = 0; pthread_create(&th [i],&a,tf和&mem [i * disp]); } CPU_ZERO(&c); CPU_SET(0,&c); pthread_setaffinity_np(pthread_self(),sizeof(c),&c); mem [0] = 0; tf(&mem [0]); 如果((disp == 0 && mem [0]!= nthreads * N) || (显示!= 0 && mem [0]!= N)) 错误(1,0,“ mem [0]错误:%ld而不是%d”, mem [0],disp == 0?nthreads * N:N); for(无符号i = 1; i <nthreads; ++ i) { pthread_join(th [i],NULL); if(disp!= 0 && mem [i * disp]!= N) 错误(1,0,“ mem [%u]错误:%ld代替%d”,i,mem [i * disp],N); } 返回0; }
这里提供的代码主要是为了说明如何编写一个程序,该程序可测量诸如高速缓存行开销之类的效果。有趣的部分是tf中循环的主体。编译器已知的 __sync_add_and_fetch内部函数会生成原子添加指令。在第二个循环中,我们必须“消费”增量的结果(通过内联asm 语句)。该ASM不会引入任何实际的代码; 相反,它防止编译器将增量操作移出循环。
第二个有趣的部分是程序将线程固定到特定的处理器上。该代码假定处理器编号为0到3,如果计算机具有四个或更多逻辑处理器,通常就是这种情况。该代码本可以使用libNUMA中的接口来确定可用处理器的数量,但是该测试程序应该可以广泛使用,而不会引入这种依赖性。以一种或另一种方式修复很容易。
10个OProfile技巧
以下内容不代表如何使用oprofile。有关于该主题的完整文档。相反,它旨在为如何看待自己的程序以发现可能的故障点提供一些更高层次的提示。但是在此之前,我们至少必须至少介绍一下。
10.1 Oprofile基础
Oprofile分两个阶段工作:收集和分析。收集是由内核执行的;由于测量使用CPU的性能计数器,因此无法在用户级别完成此操作。这些计数器要求访问MSR,而MSR又需要特权。
每个现代处理器都提供自己的一组性能计数器。在某些体系结构上,所有处理器实现都提供计数器的一个子集,而其他版本则各不相同。这使得很难就使用oprofile提供一般建议。计数器还没有更高级别的抽象来隐藏这些详细信息。
处理器版本还控制一次可以跟踪多少个事件以及以哪种组合进行跟踪。这给图片增加了更多的复杂性。
如果用户知道有关性能计数器的必要详细信息,则可以使用opcontrol程序来选择应该计数的事件。对于每个事件,必须指定“溢出数量”(在CPU中断以记录事件之前必须发生的事件数),是否应为用户级别和/或内核计算该事件,最后指定一个“单元掩码”(它选择性能计数器的子功能)。
要计算x86和x86-64处理器上的CPU周期,必须发出以下命令:
opcontrol --event CPU_CLK_UNHALTED:30000:0:1:1
数字30000是超限数字。选择合理的值对于系统和收集到的数据的行为很重要。要求接收有关事件的每一次发生的数据是一个坏主意。对于许多事件,这将使机器陷入停顿,因为它所做的只是处理事件超限的数据收集。这就是为什么oprofile强制使用最小值。每种事件的最小值都不同,因为不同的事件在正常代码中触发的可能性不同。
选择一个很高的数字会降低配置文件的分辨率。在每次溢出时,oprofile都会记录此时执行的指令的地址。对于x86和PowerPC,它在某些情况下也可以记录回溯。{在某些时候希望所有架构都可以使用Backtrace支持。}在较粗的分辨率下,热点可能无法获得具有代表性的点击数;这全都与概率有关,这就是为什么oprofile被称为概率分析器的原因。越低的数量越低,对系统的影响就越大,但分辨率越高。
如果要分析特定程序,并且系统不用于生产,则使用尽可能低的超限值通常是最有用的。可以使用以下命令查询每个事件的确切值
opcontrol --list-events
如果配置文件程序与另一个进程进行交互,并且速度下降导致交互问题,则可能会出现问题。如果某个流程具有某些实时要求,而这些要求经常被中断,则也可能导致麻烦。在这种情况下,必须找到中间立场。如果要对整个系统进行长时间的概要分析,也是如此。较低的超支数字将意味着大幅放缓。无论如何,oprofile像其他任何配置文件机制一样,都会带来不确定性和不准确性。
分析必须从opcontrol --start开始,并且可以由opcontrol --stop停止。当oprofile处于活动状态时,它将收集数据;此数据首先在内核中收集,然后分批发送到用户级守护程序,在此将其解码并写入文件系统。使用opcontrol --dump,可以请求将内核中缓冲的所有信息释放给用户级别。
收集的数据可以包含来自不同性能计数器的事件。除非用户选择在单独的oprofile运行之间擦除存储的数据,否则所有数字将保持并行。可以在不同情况下累积来自同一事件的数据。如果在不同的性能分析运行期间遇到事件,那么如果用户选择了该编号,则会添加数字。
数据收集过程的用户级部分对数据进行多路分解。每个文件的数据分别存储。甚至可以区分单个可执行文件使用的DSO,甚至单个线程的数据也可以区分。这样产生的数据可以使用oparchive归档 。该命令生成的文件可以传输到另一台计算机上,并且可以在此进行分析。
使用opreport程序,可以从分析结果生成报告。使用opannotate可以查看各种事件发生的位置:哪条指令,如果有数据,则在哪条源代码行。这样可以轻松找到热点。对CPU周期进行计数将指出花费最多的时间(包括高速缓存未命中),而对已退休的指令进行计数则可以找到大多数已执行指令的位置-两者之间有很大的差异。
通常,单打一个地址就没有任何意义。统计分析的副作用是,仅执行几次甚至仅执行一次的指令可能会被命中。在这种情况下,有必要通过重复来验证结果。
10.2看起来像什么
一个oprofile会话看起来像这样简单:
$ opcontrol -i cachebench $ opcontrol -e INST_RETIRED:6000:0:0:1-开始 $ ./cachebench ... $ opcontrol -h
请注意,这些命令(包括实际程序)以root用户身份运行。仅出于简单起见,此处以root用户身份运行程序;该程序可以由任何用户执行,oprofile会选择该程序。下一步是分析数据。通过opreport,我们看到:
CPU:Core 2,速度1596 MHz(估计) 计数的INST_RETIRED.ANY_P事件(已退休的指令数),单位掩码为 0x00(无单位掩码)计数6000 INST_RETIRED:6000 | 样品| %| ------------------ 116452 100.000缓存工作台
这意味着我们收集了很多事件;现在可以使用opannotate更详细地查看数据。我们可以看到在程序中记录了最多事件的位置。该部分opannotate --source 输出如下:
:静态无效 :inc(结构l * l,无符号n) :{ :while(n--> 0)/ *总计:13980 11.7926 * / :{ 5 0.0042:++ l-> pad [0] .l; 13974 11.7875:l = l-> n; 1 8.4e-04:asm volatile(“” ::“ r”(l)); :} :}
这是测试的内部功能,其中花费了大量时间。我们看到样本分布在循环的所有三行上。这样做的主要原因是,相对于所记录的指令指针,采样并不总是100%准确。CPU乱序执行指令;重构确切的执行顺序以产生正确的指令指针是困难的。最新的CPU版本尝试在少数事件中执行此操作,但通常不值得(或者根本不可能)这样做。在大多数情况下,这并不重要。即使有一组正常分布的样本,程序员也应该能够确定正在发生的事情。
10.3开始分析
当开始分析一段代码时,当然可以开始查看程序中花费最多时间的地方。该代码当然应该尽可能地优化。但是接下来会发生什么呢?该程序在哪里花费不必要的时间?这个问题很难回答。
在这种情况下的问题之一是绝对值不能说明真实情况。程序中的一个循环可能需要大部分时间,这很好。但是,有很多可能的原因导致CPU利用率很高。但是更常见的是,CPU使用率在整个程序中分布更均匀。在这种情况下,绝对值指向许多位置,这是没有用的。
在许多情况下,查看两个事件的比率是有帮助的。例如,如果无法衡量函数执行的频率,则函数中错误预测的分支数可能毫无意义。是的,绝对值与程序的性能有关。每次调用的错误预测比率对于函数的代码质量而言更有意义。英特尔针对x86和x86-64 [intelopt]的优化手册描述了应研究的比率(引用的文档中的Core 2事件附录B.7)。与内存处理相关的一些比率如下。
| 指令获取停顿 | CYCLES_L1I_MEM_STALLED / CPU_CLK_UNHALTED.CORE | 指令解码器由于高速缓存或ITLB丢失而等待新数据的周期比率。 |
| ITLB未命中率 | ITLB_MISS_RETIRED / INST_RETIRED.ANY | 每条指令ITLB都未命中。如果此比率很高,则代码会散布在太多页面上。 |
| L1I未命中率 | L1I_MISSES / INST_RETIRED.ANY | 每条指令L1i未命中。执行流程无法预测或代码太大。在前一种情况下,避免间接跳转可能会有所帮助。在后一种情况下,块重新排序或避免内联可能会有所帮助。 |
| L2指令失误率 | L2_IFETCH.SELF.I_STATE / INST_RETIRED.ANY | L2缺少每条指令的程序代码。任何大于零的值都表示代码局部性问题,甚至比L1i丢失更严重。 |
| 负载率 | L1D_CACHE_LD.MESI / CPU_CLK_UNHALTED.CORE | 每个周期读取操作。Core 2内核可以为一个加载操作提供服务。高比率意味着执行受内存读取约束。 |
| 商店订单块 | STORE_BLOCK.ORDER / CPU_CLK_UNHALTED.CORE | 比率(如果该商店被错过高速缓存的先前商店阻止)。 |
| L1d速率阻塞负载 | LOAD_BLOCK.L1D / CPU_CLK_UNHALTED.CORE | 由于缺乏资源而阻止了来自L1d的负载。通常,这意味着太多并发的L1d访问。 |
| L1D失误率 | L1D_REPL / INST_RETIRED.ANY | 每个指令的L1d次未命中。高速率意味着预取无效,并且L2的使用频率很高。 |
| L2数据丢失率 | L2_LINES_IN.SELF.ANY / INST_RETIRED.ANY | L2丢失了每条指令的数据。如果该值明显大于零,则硬件和软件预取无效。处理器需要更多(或更早的)软件预取帮助。 |
| L2需求缺失率 | L2_LINES_IN.SELF.DEMAND / INST_RETIRED.ANY | L2的每条指令都未使用数据,而硬件预取器根本没有使用。这意味着预取甚至还没有开始。 |
| 有用的NTA预取率 | SSE_PRE_MISS.NTA / SSS_PRE_EXEC.NTA | 有用的非时间预取相对于所有非时间预取的总数的比率。较低的值表示高速缓存中已经有许多值。也可以为其他预取类型计算该比率。 |
| NTA晚期预取速率 | LOAD_HIT_PRE / SSS_PRE_EXEC.NTA | 具有正在进行的预取的数据的负载请求相对于所有非时间性预取的总数的比率。较高的值表示软件预取指令发布得太晚。也可以为其他预取类型计算该比率。 |
对于所有这些比率,应在指示要测量两个事件的情况下运行该程序。这保证了两个计数是可比较的。除法之前,必须确保考虑了可能不同的超限值。最简单的方法是通过将每个事件计数器乘以溢出值来确保这一点。
这些比率对于整个程序,可执行文件/ DSO级别甚至功能级别都有意义。对程序的了解越深,值中包含的错误就越多。
要理解这些比率,需要的是基线值。这并不像看起来那样容易。不同类型的代码具有不同的特性,并且一个程序中不好的比率值在另一程序中可能是正常的。
11种记忆类型
尽管对于高效编程而言,这不是必需的知识,但描述可用内存类型的更多技术细节可能会很有用。具体来说,我们对“已注册”与“未注册”以及ECC与非ECC DRAM类型的区别感兴趣。
当描述在DRAM模块上具有一个附加组件:缓冲区的DRAM类型时,术语“已注册”和“已缓冲”同义使用。所有DDR内存类型均可采用已注册和未注册形式。对于未注册的模块,内存控制器直接连接到模块上的所有芯片。图11.1显示了设置。
图11.1:未注册的DRAM模块
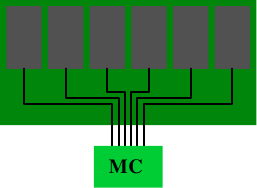
在电气上这是非常苛刻的。内存控制器必须能够处理所有内存芯片的容量(超过图中所示的六个)。如果内存控制器(MC)有限制,或者要使用许多内存模块,则此设置不理想。
图11.2:已注册的DRAM模块

缓冲(或已注册)内存会改变这种情况:它们不是直接将DRAM模块上的RAM芯片连接到内存,而是连接到缓冲区,然后又连接到内存控制器。这大大降低了电连接的复杂性。存储控制器驱动DRAM模块的能力将增加一个与保存的连接数相对应的系数。
具有这些优点的问题是:为什么不对所有DRAM模块进行缓冲?有几个原因。显然,缓冲模块要复杂一些,因此也更昂贵。成本并不是唯一的因素。缓冲器稍微延迟了来自RAM芯片的信号;延迟必须足够高,以确保缓冲来自RAM芯片的所有信号。结果是DRAM模块的等待时间增加。在此值得一提的最后一个因素是,额外的电气组件会增加能源成本。由于缓冲器必须以总线的频率运行,因此该组件的能耗可能会很大。
由于使用了DDR2和DDR3模块的其他因素,通常每个库中不能有两个以上的DRAM模块。内存控制器的引脚数限制了存储体的数量(在商用硬件中为2个)。大多数内存控制器能够驱动四个DRAM模块,因此,未注册的模块就足够了。在内存要求高的服务器环境中,情况可能有所不同。
某些服务器环境的另一个方面是它们不能容忍错误。由于RAM单元中电容器保持的微小电荷,可能会产生错误。人们经常开玩笑说宇宙辐射,但这确实是有可能的。连同alpha衰减和其他自然现象,它们会导致RAM单元的内容从0变为1或反之亦然的错误。使用的内存越多,发生此事件的可能性就越高。
如果此类错误不可接受,则可以使用ECC(错误校正代码)DRAM。纠错码使硬件能够识别不正确的单元格内容,并在某些情况下纠正错误。过去,奇偶校验仅检查可识别的错误,并且在检测到错误时必须停止计算机。相反,使用ECC可以自动纠正少量错误位。但是,如果错误数量过多,则无法正确执行内存访问,并且机器仍会停止。但是,对于正常工作的DRAM模块而言,这种情况不太可能发生,因为同一模块上必须发生多个错误。
当我们谈到ECC内存时,我们实际上并不完全正确。执行错误检查的不是内存;而是内存。相反,它是内存控制器。DRAM模块仅提供更多存储空间,并将其他非数据位与实际数据一起传输。通常,ECC存储器为每8个数据位存储一个额外的位。为什么要使用8位,将在后面解释。
在将数据写入内存地址后,内存控制器会在将数据和ECC发送到内存总线之前,为新内容动态计算ECC。读取时,接收到的数据加上ECC,存储控制器将为数据计算ECC,并将其与从DRAM模块发送的ECC进行比较。如果ECC匹配,一切都很好。如果它们不匹配,则内存控制器将尝试纠正错误。如果无法进行此更正,则会记录错误,并可能使机器停止运行。
美国证券交易委员会 SEC / DED 数据位W ECC位E 高架 ECC位E 高架 4 3 75.0% 4 100.0% 8 4 50.0% 5 62.5% 16 5 31.3% 6 37.5% 32 6 18.8% 7 21.9% 64 7 10.9% 8 12.5% 表11.1:ECC与数据位的关系
使用了几种纠错技术,但对于DRAM ECC,通常使用汉明码。汉明码最初用于编码四个数据位,并具有识别和校正一个翻转位的能力(SEC,单错误校正)。该机制可以轻松扩展到更多数据位。数据位数W和错误代码E的位数之间的关系由等式描述
E =⌈log 2(W + E + 1)⌉
迭代求解该方程式将得出表11.1第二栏中所示的值。再加上一个附加位,我们可以使用一个简单的奇偶校验位来识别两个翻转的位。这就是所谓的SEC / DED,单错误校正/双错误检测。有了这个额外的位,我们得出了表11.1第四栏中的值。W = 64的开销足够低,数字(64,8)是8的倍数,因此这是ECC的自然选择。在大多数模块上,每个RAM芯片产生8位,因此,任何其他组合都会导致效率较低的解决方案。
7 6 5 4 3 2 1个 ECC字 d d d P d P P P 1平价 d — d — d — P P 2平价 d d — — d P — P 4平价 d d d P — — — 图11.3:汉明生成矩阵构造
使用W = 4和E = 3的代码可以很容易地演示汉明码的计算。我们计算编码字中关键位置的奇偶校验位。图11.3给出了原理。在与两个的幂相对应的位位置,添加奇偶校验位。第一奇偶校验位P 1的奇偶校验和包含每第二个比特。第二奇偶校验位P 2的奇偶校验和包含数据位1、3和4(此处编码为3、6和7)。类似地,计算P 4。
奇偶校验位的计算可以使用矩阵乘法来更好地描述。我们构造一个矩阵G = [I | A],其中I是单位矩阵,A是可以从图11.3中确定的奇偶校验生成矩阵。
A的列由用于计算P 1,P 2和P 4的位构成。如果现在将每个输入数据项表示为4维向量d,则可以计算r =d⋅G并获得7维向量r。这是在ECC DDR情况下存储的数据。
为了解码数据,我们构造了一个新的矩阵H = [A T | I],其中A T是根据G的计算而转置的奇偶校验生成矩阵。这意味着:
H⋅r的结果显示所存储的数据是否有缺陷。如果不是这种情况,则乘积为3维向量(0 0 0)T。否则,乘积的值在解释为数字的二进制表示形式时,会用翻转的位指示列号。
例如,假设d =(1 0 0 1)。这导致
r =(1 0 0 1 0 0 1)
使用与H相乘的测试结果为
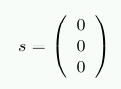
现在,假设我们存储的数据已损坏,并从内存r'=(1 0 1 1 0 0 1)读回 。在这种情况下,我们得到
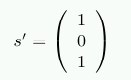
向量不是空向量,当解释为数字时,s'的值为5。这是我们在r'中翻转的位的数量(从1开始计数)。内存控制器可以纠正该位,并且程序不会注意到有问题。
处理DED部分的多余位只是稍微复杂一点。通过更多的努力,可以创建可以纠正两个或更多翻转位的代码。决定是否需要的是概率和风险。一些内存制造商说,每750小时256MB RAM中会发生错误。通过使内存量加倍,时间减少了75%。如果有足够的内存,那么在短时间内出现错误的可能性可能会很大,因此ECC RAM成为必需。时间甚至可能太短,以至于SEC / DED的实施还不够。
服务器主板无需实现更多的纠错功能,而是可以在给定的时间内自动读取所有内存。这意味着,无论处理器是否实际请求了内存,内存控制器都会读取数据,如果ECC检查失败,则将校正后的数据写回到内存中。只要在读取所有内存并将其写回所需的时间范围内发生少于两个内存错误的可能性是可以接受的,SEC / DED纠错就是一个完美的解决方案。
与已注册的DRAM一样,必须提出一个问题:为什么ECC DRAM并非规范?该问题的答案与关于注册RAM的等效问题相同:额外的RAM芯片增加了成本,而奇偶校验计算则增加了延迟。未注册的非ECC内存可以显着提高速度。由于已注册和ECC DRAM问题的相似性,通常只能找到已注册的ECC DRAM而未找到未注册的非ECC DRAM。
还有另一种克服内存错误的方法。一些制造商提供了通常被错误地称为“内存RAID”的数据,其中数据冗余地分布在多个DRAM模块或至少RAM芯片上。具有此功能的主板可以使用未注册的DRAM模块,但是内存总线上增加的流量可能会抵消ECC和非ECC DRAM模块的访问时间差异。
12 libNUMA简介
尽管许多信息程序员需要最佳地调度线程,适当地分配内存等可用的信息,但是要获取这些信息很麻烦。长期来看,现有的NUMA支持库(libnuma,位于RHEL / Fedora系统上的numactl软件包中)无法提供足够的功能。
作为回应,作者提出了一个新的库,其中提供了NUMA所需的所有功能。由于内存和缓存层次结构处理的重叠,该库对于具有多线程和多核处理器的非NUMA系统(几乎每台当前可用的计算机)也很有用。
紧迫需要此新库的功能以遵循本文档中给出的建议。这是在此提到它的唯一原因。该库(在撰写本文时)尚未完成,未审阅,未完善且未(广泛)分发。将来可能会发生重大变化。当前可从 http://people.redhat.com/drepper/libNUMA.tar.bz2获得。
该库的接口在很大程度上取决于/ sys文件系统导出的信息。如果未安装此文件系统,许多功能将简单地失败或提供不正确的信息。要记住是否在chroot监狱中执行了进程,这一点尤其重要。
该库的接口头当前包含以下定义:
typedef memnode_set_t;#定义MEMNODE_ZERO_S(setsize,memnodesetp) #定义MEMNODE_SET_S(节点,setsize,memnodesetp) #定义MEMNODE_CLR_S(节点,setsize,memnodesetp) #定义MEMNODE_ISSET_S(节点,setsize,memnodesetp) #定义MEMNODE_COUNT_S(setsize,memnodesetp)
#定义MEMNODE_EQUAL_S(setsize,memnodesetp1,memnodesetp2)
#定义MEMNODE_AND_S(setsize,destset,srcset1,srcset2) #定义MEMNODE_OR_S(setsize,destset,srcset1,srcset2) #定义MEMNODE_XOR_S(setsize,destset,srcset1,srcset2)
#定义MEMNODE_ALLOC_SIZE(计数) #定义MEMNODE_ALLOC(计数) #定义MEMNODE_FREE(memnodeset)
int NUMA_cpu_system_count(void); int NUMA_cpu_system_mask(size_t destsize,cpu_set_t * dest);
int NUMA_cpu_self_count(void); int NUMA_cpu_self_mask(size_t destsize,cpu_set_t * dest);
int NUMA_cpu_self_current_idx(void); int NUMA_cpu_self_current_mask(size_t destsize,cpu_set_t * dest);
ssize_t NUMA_cpu_level_mask(size_t destsize,cpu_set_t * dest, size_t srcsize,const cpu_set_t * src, unsigned int级别);
int NUMA_memnode_system_count(void); int NUMA_memnode_system_mask(size_t destsize,memnode_set_t * dest);
int NUMA_memnode_self_mask(size_t destsize,memnode_set_t * dest);
int NUMA_memnode_self_current_idx(void); int NUMA_memnode_self_current_mask(size_t destsize,memnode_set_t * dest);
int NUMA_cpu_to_memnode(size_t cpusetsize,const cpu_set_t * cpuset, size_t __memnodesize,memnode_set_t * memnodeset); int NUMA_memnode_to_cpu(size_t memnodesize,const memnode_set_t * memnodeset, size_t cpusetsize,cpu_set_t * cpuset);
int NUMA_mem_get_node_idx(void * addr); int NUMA_mem_get_node_mask(void * addr,size_t size, size_t destsize,memnode_set_t * dest);
该MEMNODE_ *宏在形式和功能相似的CPU_ *在第6.4.3节介绍的宏。宏没有非_S变体,它们都需要一个size参数。所述memnode_set_t类型是相当于 cpu_set_t,但这次对于存储器节点。请注意,存储节点的数量与CPU的数量无关,反之亦然。每个内存节点可能有多个CPU,甚至根本没有CPU。因此,动态分配的内存节点位集的大小不应由CPU的数量确定。
相反,应使用NUMA_memnode_system_count接口。它返回当前已注册的节点数。随着时间的流逝,这个数字可能会增加或减少。但是,它通常会保持不变,因此对于确定存储节点位的大小是一个不错的选择。分配再次类似于CPU_ 宏,使用MEMNODE_ALLOC_SIZE,MEMNODE_ALLOC 和MEMNODE_FREE进行分配。
作为与CPU_ *宏的最后并行,该库还提供了宏,用于比较内存节点位集是否相等并执行逻辑操作。
该NUMA_cpu_ *函数来处理CPU集提供的功能。在某种程度上,这些接口仅以新名称提供现有功能。 NUMA_cpu_system_count返回系统中的CPU数量,NUMA_CPU_system_mask变体返回设置了适当位的位掩码,否则该功能将不可用。
NUMA_cpu_self_count和NUMA_cpu_self_mask返回有关当前允许当前线程在其上运行的CPU的信息。 NUMA_cpu_self_current_idx返回当前使用的CPU的索引。由于内核可以做出调度决定,因此返回时该信息可能已经过时。始终必须假定它不准确。该NUMA_cpu_self_current_mask 返回相同的信息,并设置在该位设定的相应位。
已经引入了NUMA_memnode_system_count。 NUMA_memnode_system_mask是等效的函数,用于填充位集。 NUMA_memnode_self_mask根据直接连接到线程当前可以在其上运行的任何CPU的内存节点填充位集。
NUMA_memnode_self_current_idx和 NUMA_memnode_self_current_mask 返回更多专业信息 。返回的信息是连接到线程当前正在运行的处理器的内存节点。就像NUMA_cpu_self_current_ * 函数一样,当该函数返回时,此信息可能已经过时。它只能用作提示。
该NUMA_cpu_to_memnode函数可用于一组CPU的映射到所述一组直连存储器节点。如果在CPU集中仅设置了一位,则可以确定每个CPU属于哪个存储节点。当前,Linux中不支持属于多个内存节点的单个CPU。从理论上讲,这可能会在未来发生变化。要向另一个方向映射, 可以使用NUMA_memnode_to_cpu函数。
如果已经分配了内存,则知道分配内存的位置有时会很有用。这是程序员可以确定的NUMA_mem_get_node_idx和 NUMA_mem_get_node_mask。前一个函数返回在其上分配了与参数指定的地址相对应的页面的内存节点的索引,如果该页面尚未分配,则将根据当前安装的策略进行分配。第二个功能可以在整个地址范围内执行工作;它以位集的形式返回信息。该函数的返回值是所使用的不同存储节点的数量。
在本节的其余部分,我们将看到一些有关这些接口用例的示例。在所有情况下,我们都将跳过错误处理以及CPU和/或内存节点数量分别对于cpu_set_t和memnode_set_t类型而言过大的情况。增强代码的健壮性留给读者练习。
12.1确定给定CPU的线程同级
为了调度助手线程或受益于在给定CPU的线程上进行调度的其他线程,可以使用类似于以下的代码序列。
cpu_set_t cur; CPU_ZERO(&cur); CPU_SET(cpunr,&cur); cpu_set_t hyperths; NUMA_cpu_level_mask(sizeof(hyperths),&hyperths,sizeof(cur),&cur,1); CPU_CLR(cpunr,&hyperths);
该代码首先为cpunr指定的CPU生成一个位集 。然后,将此位集 与第五个参数一起传递给NUMA_cpu_level_mask,该第五个参数指定我们正在寻找超线程。结果以hyperths位集中返回。剩下要做的就是清除与原始CPU对应的位。
12.2确定给定CPU的核心同级
如果不应在两个超线程上调度两个线程,而是可以从缓存共享中受益,则我们需要确定处理器的其他内核。以下代码序列可以解决问题。
cpu_set_t cur; CPU_ZERO(&cur); CPU_SET(cpunr,&cur); cpu_set_t hyperths; int nhts = NUMA_cpu_level_mask(sizeof(hyperths),&hyperths,sizeof(cur),&cur,1); cpu_set_t核心; int ncs = NUMA_cpu_level_mask(sizeof(coreths),&coreths,sizeof(cur),&cur,2); CPU_XOR(&coreths,&coreths,&hyperths); ncs-= nhts;
该代码的第一部分与确定超线程的代码相同。这不是巧合,因为我们必须将给定CPU的超线程与其他内核区分开。这是在第二部分中实现的,该部分 再次调用NUMA_cpu_level_mask,但是这次的级别为2。剩下要做的就是从结果中删除给定CPU的所有超线程。变量nhts和ncs用于跟踪各个位集中设置的位数。
生成的掩码可用于安排另一个线程。如果不需要显式调度其他线程,则有关使用内核的决定可以留给操作系统。否则,可以反复运行以下代码:
而(ncs> 0){ size_t idx = 0; 同时(!CPU_ISSET(idx,&ncs)) ++ idx; CPU_ZERO(&cur); CPU_SET(idx,&cur); nhts = NUMA_cpu_level_mask(sizeof(hyperths),&hyperths,sizeof(cur),&cur,1); CPU_XOR(&coreths,&coreths,hyperths); ncs-= nhts;...安排CPU IDX上的线程... }
循环在每次迭代中从剩余的已使用内核中选择一个CPU编号。然后,它为此CPU计算所有超线程。然后从可用内核的位集中减去结果位集(使用CPU_XOR)。如果XOR操作没有删除任何内容,则确实是错误的。该NCS变量更新,我们已经准备好为下一轮,但不是调度决策才制成。最后,根据程序要求,可以使用idx, cur或hyperths中的任何一个来调度线程。通常,最好让操作系统尽可能地自由,因此要使用 虚拟机 设置此位,以便OS可以选择最佳的超线程。