【前言】部署服务器用到了nginx,相比较于apache并发能力更强,优点也比其多得多。虽然我的项目可能用不到这么多性能,还是部署一个流行的服务器吧!
此篇博文主要学习nginx(ingine x)的反向代理、负载均衡原理,并介绍一下分布式下sesssion保持。(分布式和集群的区别?下面有)
一、正向代理和反向代理
1、正向代理的概念
正向代理,也就是传说中的代理,他的工作原理就像一个跳板,简单的说,我是一个用户,我访问不了某网站,但是我能访问一个代理服务器。这个代理服务器呢,他能访问那个我不能访问的网站于是我先连上代理服务器,告诉他我需要那个无法访问网站的内容,代理服务器去取回来,然后返回给我。从网站的角度,只在代理服务器来取内容的时候有一次记录,有时候并不知道是用户的请求,也隐藏了用户的资料,这取决于代理告不告诉网站。
结论就是 正向代理 是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理。
2、反向代理的概念
继续举例:
例用户访问 http://ooxx.me/readme,但ooxx.me上并不存在readme页面,他是偷偷从另外一台服务器上取回来,然后作为自己的内容吐给用户,但用户并不知情。这很正常,用户一般都很笨。这里所提到的 ooxx.me 这个域名对应的服务器就设置了反向代理功能。
结论就是 反向代理正好相反,对于客户端而言它就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向反向代理 的命名空间(name-space)中的内容发送普通请求,接着反向代理将判断向何处(原始服务器)转交请求,并将获得的内容返回给客户端,就像这些内容 原本就是它自己的一样。
3、两者区别
从用途上来讲:
正向代理的典型用途是为在防火墙内的局域网客户端提供访问Internet的途径;正向代理还可以使用缓冲特性减少网络使用率。
反向代理的典型用途是将 防火墙后面的服务器提供给Internet用户访问;反向代理还可以为后端的多台服务器提供负载平衡,或为后端较慢的服务器提供缓冲服务。
另外,反向代理还可以启用高级URL策略和管理技术,从而使处于不同web服务器系统的web页面同时存在于同一个URL空间下。
从安全性来讲:
正向代理允许客户端通过它访问任意网站并且隐藏客户端自身,因此你必须采取安全措施以确保仅为经过授权的客户端提供服务;
反向代理对外都是透明的,访问者并不知道自己访问的是一个代理。
二、nginx的反向代理负载均衡
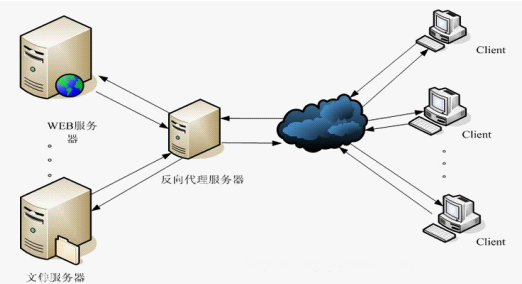
Nginx服务器就是反向代理服务器,只做请求的转发,后台有多个http服务器提供服务,nginx的功能就是把请求转发给后面的服务器,并把结果返回给客户端。实现在同一个域名之下,有多台服务器,并实现服务器负载均衡。
1、什么是负载均衡?
负载均衡,英文名称为Load Balance,其意思就是算力分摊到多个操作单元上进行执行,例如Web服务器、FTP服务器、企业关键应用服务器和其它关键任务服务器等,从而共同完成工作任务。
负载均衡建立在现有网络结构之上,它提供了一种廉价有效透明的方法扩展网络设备和服务器的带宽、增加吞吐量、加强网络数据处理能力、提高网络的灵活性和可用性。负载均衡,核心就是网络流量分发,分很多维度。从网络层看,基本是四层(TCP,UDP),和七层(HTTP,HTTPS等),基本就是解析到对应的网络层,然后根据不同特征分发。比如四层的,基本就是根据连接信息(TCP)或者本身的特征(源IP,目标IP)等做。七层的,就可以用域名(HTTP头里的Host),URL,Cookie,Header这些来做。
2、负载均衡的分类
(1)从实现上看,基本可以分软负载均衡和反向代理:
- 软负载均衡不会过中间代理,网络rt,性能会较好,但是一般不好做精细的流量控制,有的方案还有延时问题。实现有DNS实现,iptables实现的方案。
- 反向代理,故名思意就是通过代理来做吗,有中间件。由于流量都会过LB,因此可以做到比较精细的流量分发(比如各种权重,七层的各种转发规则)。坏处就是代理本身可能成为瓶颈,以及过了一层代理造成网络延时的增加。而代理本身也会有一定成本,因此实现成本较高。
- DNS负载均衡可以根据地域就近分配服务器,但比较简单使用简单轮询方式。有时候可搭配反向代理服务器在集群中使用,因为在客户端和反向代理服务器之间,可以对多个反向代理服务器进行负载均衡。
- 一个小结
(2)从实现方式看,有软件负载均衡和硬件负载均衡:
- 软件负载均衡的具体软件实现有Nginx,Haproxy,LVS,以及比较古老的Apache等,上面两种但是软件负载均衡。现在比较新的做法是用dpdk这种内核bypass方案做的负载均衡,由于绕过了linux内核比较复杂的网络协议栈(人家本身就不是做负载均衡的。。。),因此性能会有明显的提升(轻松跑满万兆网卡)。
- 硬件负载均衡有大名鼎鼎的F5之类,这种不差钱的企业会采用。但是现在互联网公司用的越来越少。现在硬件使用较多的是使用支持OSPF协议的交换机(基本都支持了),通过ECMP做的负载均衡集群。这个查查云计算厂商的负载均衡文档,大部分都是用这个作为分发集群的。性能非常好(随便几十G器),稳定性也很高。就是贵,搭建麻烦(需要机房支持),所以不是一般用户搞的起的。不过这个也可以用软件路由器(比如quagga这种)自己搭建一套软件的OSPF集群,不过稳定性和性能相比硬件的要大打折扣。
每个云服务都会提供负载均衡服务(负载均衡服务_流量分发服务-网易云),拿来直接用就好啦,省时又省力,可以将更多精力放在核心业务上面。
3、反向代理nginx负载均衡举例说明
nginx作为负载均衡服务器,用户请求先到达nginx,再由nginx根据负载配置将请求转发至tomcat服务器。
nginx负载均衡服务器:192.168.3.43
tomcat1服务器:192.168.3.43:8080
tomcat2服务器:192.168.3.43:8081
4、nginx配置
upstream tomcatserver1 {
server 192.168.3.43:8080 weight=2;
server 192.168.3.43:8082 weight=1; #多加了此台服务器,并增加了负载的权重。性能高的服务器做的事情多
}
upstream tomcatserver2 {
server 192.168.3.43:8082;
}
#第一台服务器
server {
listen 80;
server_name 8080.zcinfo.com;
location / {
proxy_pass http://tomcatserver1;
index index.html index.htm;
}
}
#第二台服务器
server {
listen 80;
server_name 8082.zcinfo.com;
location / {
proxy_pass http://tomcatserver2;
index index.html index.htm;
}
}
这样的情况下,就反向代理成功了。会出现两个端口下的页面轮询。那么负载均衡体现在哪里呢?
5、负载均衡的策略
上面的weight大小就是一种负载均衡的策略,weight=2的会连续出现两次,1的出现一次。总的来说,nginx提供五种负载均衡的策略。
(1)轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
upstream backserver {
server 192.168.0.14;
server 192.168.0.15;
}
(2)指定权重
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。 默认为1
upstream backserver {
server 192.168.0.14 weight=3;
server 192.168.0.15 weight=10;
}
(3)IP绑定 ip_hash
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。因为对于集群问题不好解决session问题。
upstream backserver {
ip_hash;
server 192.168.0.14:88;
server 192.168.0.15:80;
}
(4)fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
upstream backserver {
server server1;
server server2;
fair;
}
(5)url_hash(第三方)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
upstream backserver {
server squid1:3128;
server squid2:3128;
hash $request_uri;
hash_method crc32;
}
6 、在需要使用负载均衡的server中增加 :
proxy_pass http://backserver/;
upstream backserver{
ip_hash;
server 127.0.0.1:9090 down; #(down 表示单前的server暂时不参与负载)
server 127.0.0.1:8080 weight=2; # (weight 默认为1.weight越大,负载的权重就越大)
server 127.0.0.1:6060;
server 127.0.0.1:7070 backup; # (其它所有的非backup机器down或者忙的时候,请求backup机器)
}
max_fails :允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream 模块定义的错误
fail_timeout:max_fails次失败后,暂停的时间
三、分布式下session保持
负载均衡的应用背景下是多台服务器,那么对于多台服务器这样进行session保持呢?
我有一篇文章已经介绍了session,此处不再赘述。下面介绍一下session的管理,例如在java服务器下,例如tomcat服务器sessionid会以jsessionid的名称存在cookie中,以cookie的形式和服务器通信。
1、session怎么保存的?
不同的服务器、不同的语言框架都有不同的实现。比如java的服务器,有的是用文件方式来存储的;有的是用内存cache的方式来存储的;有的语言的服务器将数据做加密,然后设置成cookie,存到了客户端(浏览器)。那这些实现方式都有哪些优缺点呢?我们逐个来分析。
文件方式:这种方式,将文件作为一个map,当新增一个数据的时候,就在文件中增加类似这样的一条数据:
angOwberup =>
data={"user":{"id":1,"nickname":"老王"}};
expiry="2016-10-0100:00:00"
(当然,具体实现的时候有可能是用的二进制方式,而不是字符串)
这种方式的好处,就是能够存储大量的用户session,使得这个session有效期可以比较长(比如:三个月用户不用登录)。不过这个方式也有对应的问题,就是文件操作比较麻烦。比如,有一个用户的session过期了,需要删掉这条记录,那这个文件就需要挪动或重写。cache方式:有好多web端的逻辑服务器都采用这种方式。这种方式好处非常明显,就是实现起来非常简单。将所有数据放入到内存cache中。如果有失效,直接内存删除就可以了。不过带来的问题也很明显,当服务器重启以后,所有session都丢失了。或者当有大量用户登录(也有可能是遭受攻击),就会很快让cache被充满,然后大量session被LRU算法淘汰,造成session的大量失效,使得用户需要反复登录等操作。
- cookie方式:这种方式是最偷懒的方式,也是我上面提的爬虫遇到的。就是服务器任何数据都不存,把你们所有的客户端当做我的存储器,我就需要做一个加密和解密操作。当然这种方式最大的好处就是实现极其简单(还有其他的好处,稍后再说),不过问题也是很明显的,就是客户端要记录大量信息,同时还要保证加密信息的安全。如果session里要存放大数据,这种方式就不是很适合了。
除了上述说到的优缺点以外,第一和第二,He两种方式还有另外一个问题,就是当我有不止一台服务器的时候,不同服务器间的session数据共享就成问题了。比如,最初我只有一台服务器1,他的session里记录了user-1和user-2的数据。这个时候,我需要增加一台服务器2。当nginx把用户的请求转发到服务器2的时候,他就傻眼了:用户带了一个jsession_id=angOwberup这个的cookie过来,而在他的session管理器里却找不到这样一个session数据。那该怎么办?!
因此,就出现了我们文章一开始提到的问题:在分布式系统里,用户session如何才能实现同步?
2、分布式的session同步
(PS:分布式和集群的区别在于分布式解决的是压力集中问题,每个单元任务都不一样;集群是解决大项目臃肿问题,是同一个项目分散在不同单元上。所以此处用分布式比较合适)
有了上面的情况,我们就必须要去考虑,如何在多个服务器之间实现session同步这个操作。常见的做法有以下几种,我们逐个来看看:
- 程间通信传递session数据,这是最容易想到的一个方法。我们在不同的server服务里开一个socket,然后用socket来将相互拥有的session数据进行传递。我记得多年以前tomcat就是采用这样的方式来做的(已经很久没用过tomcat了,不知道现在是否还在这样使用)。这种方式的好处很明显,就是原理简单明了;坏处也很明显,就是同步合并过程复杂,还容易造成同步延迟。比如,某个用户在server-1登录了,server-1存储了这个用户的session,当正准备将数据同步给server-2的时候,由于用户访问实在是太快(飞一般的速度),server-2还没收到server-1传来的session数据,用户访问就已经来了。这个时候,server-2就不能识别这个用户,造成用户需要再次登录。而且,当有成千上万台服务器的时候,session同步就是一个噩梦:每一个服务器都要将自己拥有的session广播给其他所有机器,而且还要随时进行,不能停歇……这些机器估计都是累死的)
- cookie存储方式。我们在上面讲到了一个很偷懒的方式,就是把session数据做加密,然后存储到cookie中。用户请求到了,就直接从cookie读取,然后做解密。这种方式真是把分布式思想发挥到了一个相当的高度。他把用户也当做分布式的一员,你要访问数据,那你就自己携带着他,每次到服务器的时候,我们的服务器就只负责解密。对于session里只存放小数据,并且加密做的比较好(防止碰撞做暴力破解)的系统来讲,这是一个比较好的选择。他实现超级简单,而且不用考虑数据的同步。不过如果要往session里存放大数据的情况就不是太好处理。或者安全性要求很高的系统,也不是太好的一个方式(数据有被破解的风险)。
- cache集群或者数据库做session管理。我们也可以采用另外一种架构来解决session同步问题,那就是引入统一session接入点。我们session放入到cache集群(一个容易宕掉)或者数据库中,每次请求的时候,都从他们中来获取。这样,所有的机器都能获取到最新的session数据。这种方案也是很多中大型网站采用的解决方案。他实现起来相对简单(利用cache集群或者主从数据库自身的管理来实现多机的互备),而且效率很高,安全性也不错。(NFS)
- 还有一种方式是从上面这种方式延展出来的,就是提供session服务。这个服务负责管理session,其他服务器每次从这个服务处获取session数据,从而达到数据的共享。
- redis、memcache同步session。二者可以把web服务器中的内存组合起来,成为一个"内存池",不管是哪个服务器产生的sessoin都可以放到这个"内存池"中,其他的都可以使用。不同之处在于redis会有固化操作。参考:https://www.cnblogs.com/lingshao/p/5580287.html