1. 为什什么学习Python?
Life is short, You need Python
2. 通过什什么途径学习的Python?
pass
3. Python和Java、PHP、C、C#、C++等其他语⾔言的对比?
pass
4. 简述解释型和编译型编程语言?
将由高级语言编写的程序文件转换为可执行文件(二进制的)有两种方式,编译和解释,编译是在程序运行前,已经将程序全部转换成二进制码,而解释是在程序执行的时候,边翻译边执行。
5. Python解释器器种类以及特点?
CPython
当 从Python官方网站下载并安装好Python2.7后,就直接获得了一个官方版本的解释器:Cpython,这个解释器是用C语言开发的,所以叫 CPython,在命名行下运行python,就是启动CPython解释器,CPython是使用最广的Python解释器。
IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的,好比很多国产浏览器虽然外观不同,但内核其实是调用了IE。
PyPy
PyPy是另一个Python解释器,它的目标是执行速度,PyPy采用JIT技术,对Python代码进行动态编译,所以可以显著提高Python代码的执行速度。
Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
在Python的解释器中,使用广泛的是CPython,对于Python的编译,除了可以采用以上解释器进行编译外,技术高超的开发者还可以按照自己的需求自行编写Python解释器来执行Python代码,十分的方便!
6. 位和字节的关系?
1字节=8位(二进制)7. b、B、KB、MB、GB 的关系?
1B(byte字节)=8b(比特位) 1KB=1024B 1MB=1024KB 1GB=1024MB8. 请至少列举5个 PEP8 规范(越多越好)。
9. 通过代码实现如下转换:

二进制转换成十进制:v = “0b1111011” >>print(int(v,2)) 十进制转换成二进制:v = 18 >> print(bin(int(v))) 八进制转换成十进制:v = “011” >> print(int(v,8)) 十进制转换成八进制:v = 30 >> print(oct(v)) 十六进制转换成十进制:v = “0x12” >>print(int(v,16)) 十进制转换成十六进制:v = 87 >>print(hex(v))
10.请编写一个函数实现将IP地址转换成一个整数。
如 10.3.9.12 转换规则为:
10 00001010
3 00000011
9 00001001
12 00001100
再将以上二进制拼接起来计算十进制结果:00001010 00000011 00001001 00001100 = ?
def ip_to_int(s):
L = '0b'+''.join([bin(int(i)) for i in s.split('.')]).replace('0b','')
print(int(L,2))
if __name__ == '__main__':
s = "10.3.9.12"
ip_to_int(s)11. python递归的最大层数?
12. 求结果:
v1 = 1 or 3 >>1 v2 = 1 and 3 >>3 v3 = 0 and 2 and 1 >>0 v4 = 0 and 2 or 1 >>1 v5 = 0 and 2 or 1 or 4 >>1 v6 = 0 or False and 1 >> False
13. ascii、unicode、utf-8、gbk 区别?
最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
14. 字节码和机器器码的区别?
机器码(machine code),学名机器语言指令,有时也被称为原生码(Native Code),是电脑的CPU可直接解读的数据。通常意义上来理解的话,机器码就是计算机可以直接执行,并且执行速度最快的代码。用机器语言编写程序,编程人员要首先熟记所用计算机的全部指令代码和代码的涵义。手编程序时,程序员得自己处理每条指令和每一数据的存储分配和输入输出,还得记住编程过程中每步所使用的工作单元处在何种状态。这是一件十分繁琐的工作,编写程序花费的时间往往是实际运行时间的几十倍或几百倍。而且,编出的程序全是些0和1的指令代码,直观性差,还容易出错。现在,除了计算机生产厂家的专业人员外,绝大多数的程序员已经不再去学习机器语言了。
总结:机器码是电脑CPU直接读取运行的机器指令,运行速度最快,但是非常晦涩难懂,也比较难编写,一般从业人员接触不到。
字节码(Bytecode)是一种包含执行程序、由一序列 op 代码/数据对 组成的二进制文件。字节码是一种中间码,它比机器码更抽象,需要直译器转译后才能成为机器码的中间代码。通常情况下它是已经经过编译,但与特定机器码无关。字节码通常不像源码一样可以让人阅读,而是编码后的数值常量、引用、指令等构成的序列。字节码主要为了实现特定软件运行和软件环境、与硬件环境无关。字节码的实现方式是通过编译器和虚拟机器。编译器将源码编译成字节码,特定平台上的虚拟机器将字节码转译为可以直接执行的指令。字节码的典型应用为Java bytecode。字节码在运行时通过JVM(JAVA虚拟机)做一次转换生成机器指令,因此能够更好的跨平台运行。总结:字节码是一种中间状态(中间码)的二进制代码(文件)。需要直译器转译后才能成为机器码。
15. 三元运算规则以及应用场景?
if X:
A = Y
else:
A = Z
# 用于简单的if-else判断,基本语法:条件为真的返回值 if 条件 else 条件为假的返回值
A = Y if X else Z16. 列举 Python2和Python3的区别?
17. 用一行代码实现数值交换:
a = 1 b = 2
a, b = b, a # 附加 '''采用第三方变量''' c = a a = b b = c '''使用两个变量''' a = a+b #取两个数的和 b = a-b #然后a-b等于a然后赋值给b a = a-b #然后a-b等于b然后赋值给a,完成值的交换
18.Python3和Python2中 int 和 long的区别
python2
int(符号整数):通常被称为是整数或整数,没有小数点的正或负整数。
long(长整数):或渴望,无限大小的整数,这样写整数和一个大写或小写的L。
python3
去除了long类型,现在只有一种整型——int,但它的行为就像2.X版本的long
19.xrange和range的区别
xrange 用法与 range 完全相同,所不同的是生成的不是一个list对象,而是一个生成器。
20.文件操作时:xreadlines和readlines的区别?
file.readlines()是把文件的全部内容读到内存,并解析成一个list,当文件的体积很大的时候,需要占用很多内存,使用该方法是一种不明智的做法。
file.xreadlines()则直接返回一个iter(file)迭代器
21.列举布尔值为False的常见值
0以及长度为0的内置对象(空列表,空字符,空字典等等)22..字符串、列表、元组、字典每个常用的5个方法
23.lambda表达式格式以及应用场景?
24.pass的作用
pass语句什么也不做,一般作为占位符或者创建占位程序,pass语句不会执行任何操作保证格式完整 保证语义完整
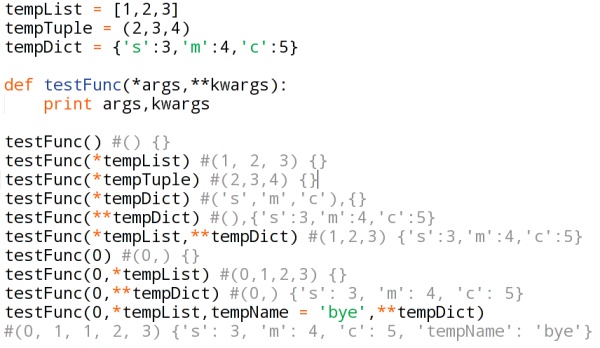
25.*arg和**kwarg作用
如果我们不确定往一个函数中传入多少参数,或者我们希望以元组(tuple)或者列表(list)的形式传参数的时候,我们可以使用*args(单星号)。如果我们不知道往函数中传递多少个关键词参数或者想传入字典的值作为关键词参数的时候我们可以使用**kwargs(双星号),args、kwargs两个标识符是约定俗成的用法。
另一种答法:当函数的参数前面有一个星号*号的时候表示这是一个可变的位置参数,两个星号**表示这个是一个可变的关键词参数。星号*把序列或者集合解包(unpack)成位置参数,两个星号**把字典解包成关键词参数。
26.is和==的区别
is 是⽐较两个引⽤是否指向了同⼀个对象(引⽤⽐较)。
== 是⽐较两个对象的值是否相等
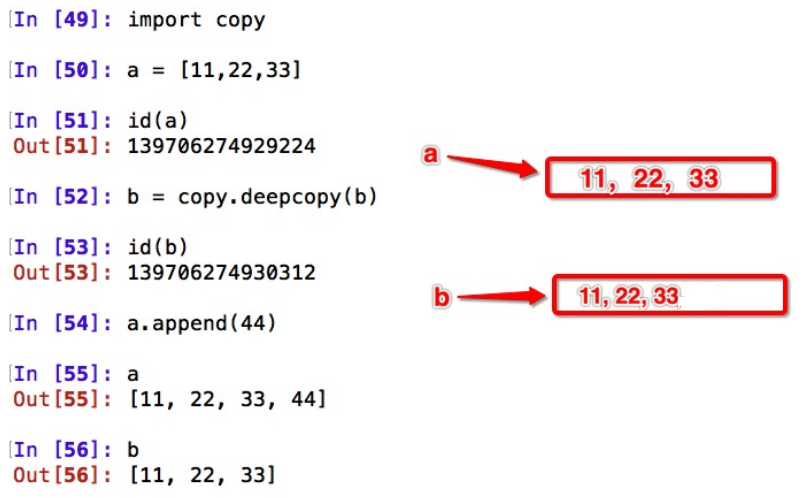
27.简述Python的深浅拷贝以及应用场景
# 1. copy.copy 浅拷贝 只拷贝父对象,不会拷贝对象的内部的子对象。
# 2. copy.deepcopy 深拷贝 拷贝对象及其子对象
import copy
a = [1, 2, 3, 4, ['a', 'b']] #原始对象
b = a #赋值,传对象的引用
c = copy.copy(a) #对象拷贝,浅拷贝
d = copy.deepcopy(a) #对象拷贝,深拷贝
a.append(5) #修改对象a
a[4].append('c') #修改对象a中的['a', 'b']数组对象
print 'a = ', a
print 'b = ', b
print 'c = ', c
print 'd = ', d
# 输出结果:
a = [1, 2, 3, 4, ['a', 'b', 'c'], 5]
b = [1, 2, 3, 4, ['a', 'b', 'c'], 5]
c = [1, 2, 3, 4, ['a', 'b', 'c']]
d = [1, 2, 3, 4, ['a', 'b']] 浅拷⻉是对于⼀个对象的顶层拷⻉:拷⻉了引⽤,并没有拷⻉内容

深拷⻉是对于⼀个对象所有层次的拷⻉(递归)
28.Python垃圾回收机制
29.Python的可变类型和不可变类型
30.求结果:
v = dict.fromkeys(['k1','k2'],[])
v[‘k1’].append(666)
print(v)
>>{'k1': [666], 'k2': [666]}
v[‘k1’] = 777
print(v) >> {'k1': 777, 'k2': [666]}31. 求结果:
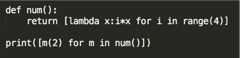
Python的延迟绑定其实就是只有当运行嵌套函数的时候,才会引用外部变量i,不运行的时候,并不是会去找i的值,这个就是第一个函数,为什么输出的结果是[6,6,6,6]的原因。
32. 列举常见的内置函数?
33. filter、map、reduce的作用?
34. 一行代码实现9*9乘法表
#正序
for i in range(1,10): for j in range(1,i+1): print("%s*%s=%s" % (j,i,i*j),end=" ") print()
#倒序 for i in range(9,0,-1): for j in range(i,0,-1): print("%s*%s=%s" % (j,i,i*j),end=" ") print()
#一行代码
print(" ".join(" ".join(["%s*%s=%s" % (y, x, x*y) for y in range(1, x + 1)]) for x in range(1, 10)))
35. 如何安装第三方模块?以及用过哪些第三方模块?
pip安装:pip install 模块名称(使用豆瓣源 pip install -ihttp://pypi.douban.com/simple/模块名称
源码安装:1.下载代码 2.解压 3.进入目录4.执行 python setup.py install
36. 至少列举8个常用模块都有那些?
37.re的match和search区别
38.什么是正则的贪婪匹配
39.求结果:
a. [ i % 2 for i in range(10) ] b. ( i % 2 for i in range(10) )
a为列表[0, 1, 0, 1, 0, 1, 0, 1, 0, 1] ,b为列表生成器
40.求结果:
a. 1 or 2 b. 1 and 2 c. 1 < (2==2) d. 1 < 2 == 2
1 2 False True
41.def func(a,b=[]) 这种写法有什么坑?
42.如何实现 “1,2,3” 变成 [‘1’,’2’,’3’] ?
“1,2,3”.split(',')43.如何实现[‘1’,’2’,’3’]变成[1,2,3] ?
[int(i) for i in “1,2,3”.split(',')]44.比较: a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的区别?
>>> b = [(1),(2),(3) ] >>> print(type(b[1])) <class 'int'> >>> b = [(1,),(2,),(3,) ] >>> print(type(b[1])) <class 'tuple'> >>> b = [1,2,3] >>> print(type(b[1])) <class 'int'>
45.如何用一行代码生成[1,4,9,16,25,36,49,64,81,100] ?
[pow(i,2) for i in range(1,11)]
46.一行代码实现删除列表中重复的值 ?
def distFunc1():
a=[1,2,4,2,4,5,6,5,7,8,9,0]
b={}
b=b.fromkeys(a)
print b
#print b.keys()
a=list(b.keys())
print a
def distFunc2():
a=[1,2,4,2,4,5,7,10,5,5,7,8,9,0,3]
a=list(set(a)) # set是非重复的,无序集合。可以用list来的排队对set进行排序,list()转换为列表,a.sort来排序
print a
def distFunc3():
#可以先把list重新排序,然后从list的最后开始扫描,代码如下:
List=[1,2,4,2,4,5,7,10,5,5,7,8,9,0,3]
if List:
List.sort()
#print List
last = List[-1]
#print last
for i in range(len(List)-2, -1, -1):
if last==List[i]:
del List[i]
else: last=List[i]47.如何在函数中设置一个全局变量
48.logging模块的作用?以及应用场景?
49.请用代码简答实现stack
# coding:utf-8
class Stack(object):
def __init__(self):
self.__list = []
def push(self, item):
"""添加一个新元素到栈顶"""
self.__list.append(item)
def pop(self):
"""弹出栈顶元素"""
return self.__list.pop()
def peek(self):
"""返回栈顶元素"""
if self.__list:
return self.__list[-1]
else:
return None
def is_empty(self):
"""判断栈是否为空"""
return self.__list == []
def size(self):
"""返回栈元素个数"""
return len(self.__list)
if __name__ == '__main__':
s = Stack()
s.push(0)
s.push(1)
s.push(2)
print(s.pop())50.常用字符串格式化哪几种?
>>> print("我叫%s,今年%d岁了" % ("小李", 20))
我叫小李,今年20岁了
1、正常使用
>>> print("我叫{},今年{}岁了".format("小李", 20))
我叫小李,今年20岁了
2、还可以通过在括号里填写数字,修改格式化的顺序
>>> print("我叫{1},今年{0}岁了".format("小李", 20))
我叫20,今年小李岁了
3、通过key取变量
>>> print("我叫{name},今年{age}岁了".format(name="小李", age=20))
我叫小李,今年20岁了51.简述 生成器、迭代器、可迭代对象 以及应用场景?
52.用Python实现一个二分查找的函数。
# coding:utf-8
# 二分查找又称折半查找,优点是比较次数少,查找速度快,平均性能好;其缺点是要求待查表为有序表,
# 且插入删除困难。因此,折半查找方法适用于不经常变动而查找频繁的有序列表。首先,假设表中元素是按升序排列,
# 将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成
# 前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。
# 重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
# 最优时间复杂度:O(1)
# 最坏时间复杂度:O(logn)
def binary_search(alist, item):
first = 0
last = len(alist)-1
while first<=last:
midpoint = (first + last)//2
if alist[midpoint] == item:
return True
elif item < alist[midpoint]:
last = midpoint-1
else:
first = midpoint+1
return False
testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42,]
print(binary_search(testlist, 3))
print(binary_search(testlist, 13))
def binary_search(alist, item):
if len(alist) == 0:
return False
else:
midpoint = len(alist)//2
if alist[midpoint]==item:
return True
else:
if item<alist[midpoint]:
return binary_search(alist[:midpoint],item)
else:
return binary_search(alist[midpoint+1:],item)
testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42,]
print(binary_search(testlist, 3))
print(binary_search(testlist, 13))53.谈谈你对闭包的理解?
54.os和sys模块的作用?
os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口;sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python的运行时环境。
55.如何生成一个随机数?
56.如何使用python删除一个文件?
57.谈谈你对面向对象的理解?
面向对象编程,即OOP,是一种编程范式,满足面向对象编程的语言,一般会提供类、封装、继承等语法和概念来辅助我们进行面向对象编程。
58.Python面向对象中的继承有什么特点?
59. 面向对象深度优先和广度优先是什么?
Python的类如果继承了多个类,那么其寻找方法的方式有两种,分别是:深度优先和广度优先
60.面向对象中super的作用?
61.是否使用过functools中的函数?其作用是什么?
functools,用于高阶函数:指那些作用于函数或者返回其它函数的函数,通常只要是可以被当做函数调用的对象就是这个模块的目标。
62.列举面向对象中带爽下划线的特殊方法,如:__new__、__init__
63.如何判断是函数还是方法?
64.静态方法和类方法区别?
65.列举面向对象中的特殊成员以及应用场景
见62
66.1、2、3、4、5 能组成多少个互不相同且无重复的三位数
n = 0
for i in range(1,6):
for j in range(1,6):
for k in range(1,6):
if( i != k ) and (i != j) and (j != k):
n += 1
print("能组成%d个互不相同且无重复数字的三位数:"%n)67. 什么是反射?以及应用场景?
反射就是通过字符串的形式,导入模块;通过字符串的形式,去模块寻找指定函数,并执行。利用字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员,一种基于字符串的事件驱动!
68.metaclass作用?以及应用场景?
69.用尽量多的方法实现单例模式
70.装饰器的写法以及应用场景
71.异常处理写法以及如何主动跑出异常
72.什么是面向对象的mro
MRO(Method Resolution Order):方法解析顺序
73.isinstance作用以及应用场景
74.写代码并实现:
Given an array of integers, return indices of the two numbers such that they add up to a specific target.You may assume that each input wouldhave exactly one solution, and you may not use the same element twice.
Example:
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1]
class Solution(object):
def twoSum(self, nums, target):
""" :type nums: List[int]
:type target: int
:rtype: List[int]
"""
if len(nums) <= 1:
return False
buff_dict = {}
for i in range(len(nums)):
if nums[i] in buff_dict:
return [buff_dict[nums[i]], i]
else:
buff_dict[target - nums[i]] = i75.json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
76.json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办?
import json
dict = {'aa': '你好啊', 'bb': '你还'}
print dict
print '-----------------------'
##加上ensure_ascii=False后data返回的就是中文而不是unicode
data = json.dumps(dict, ensure_ascii=False)
'''
方法二:
print json.dumps(dict,ensure_ascii=False).decode('utf8').encode('gb2312')
'''
print data
####
python3中没有这种问题,所以最简单的方法是引入future模块
from __future__ import unicode_literals
print json.dumps(dict,ensure_ascii=False)
=>{"aa": "你好啊"}77.什么是断言
78.有用过with statement吗?它的好处是什么
79.使用代码实现查看列举目录下的所有文件。
#方法1:使用os.listdir
import os
for filename in os.listdir(r'c:windows'):
print filename
#方法2:使用glob模块,可以设置文件过滤
import glob
for filename in glob.glob(r'c:windows*.exe'):
print filename
#方法3:通过os.path.walk递归遍历,可以访问子文件夹
import os.path
def processDirectory ( args, dirname, filenames ):
print 'Directory',dirname
for filename in filenames:
print ' File',filename
os.path.walk(r'c:windows', processDirectory, None )
#方法4:非递归
import os
for dirpath, dirnames, filenames in os.walk('c:\winnt'):
print 'Directory', dirpath
for filename in filenames:
print ' File', filename
# 另外,判断文件与目录是否存在
import os
os.path.isfile('test.txt') #如果不存在就返回False
os.path.exists(directory) #如果目录不存在就返回False80.简述 yield和yield from关键字。
81.打印目录
# import os # def Test1(rootDir): # list_dirs =os.walk(rootDir) # for root, dirs, files inlist_dirs: # for d indirs: # print(os.path.join(root, d)) # for f infiles: # print(os.path.join(root, f)) # # # Test1(r'path_name') # print('###################')