一、事情起因
我看的老男孩76期ELK课程的day106缺了第12集,这一集讲的是安装Filebeat呈现Nginx日志的过程,于是快乐没有了。
因为课程缺失,我看了很多关于Filebeat的博文,但由于版本差异,配置文件也有些许差异;同时还有架构上的不同,导致各式各样的安装方式;为了少走弯路同时更加深入的了解ELK的部署以及运行,我花了两天时间看完了千锋教育的一套讲解ELK的课程,链接在这里。
课程讲解还是很不错的,各有各的侧重点,在学习的过程中还能学到老师们处理故障的思路以及经验是很难得的。
我较为习惯先看视频再看博客进行学习,这样方便理解,同时也能避免遇到一些不必要的坑。
这篇博文会很长,因为我屁话过多,实属抱歉,答应我一定要看到最后!
二、组件介绍
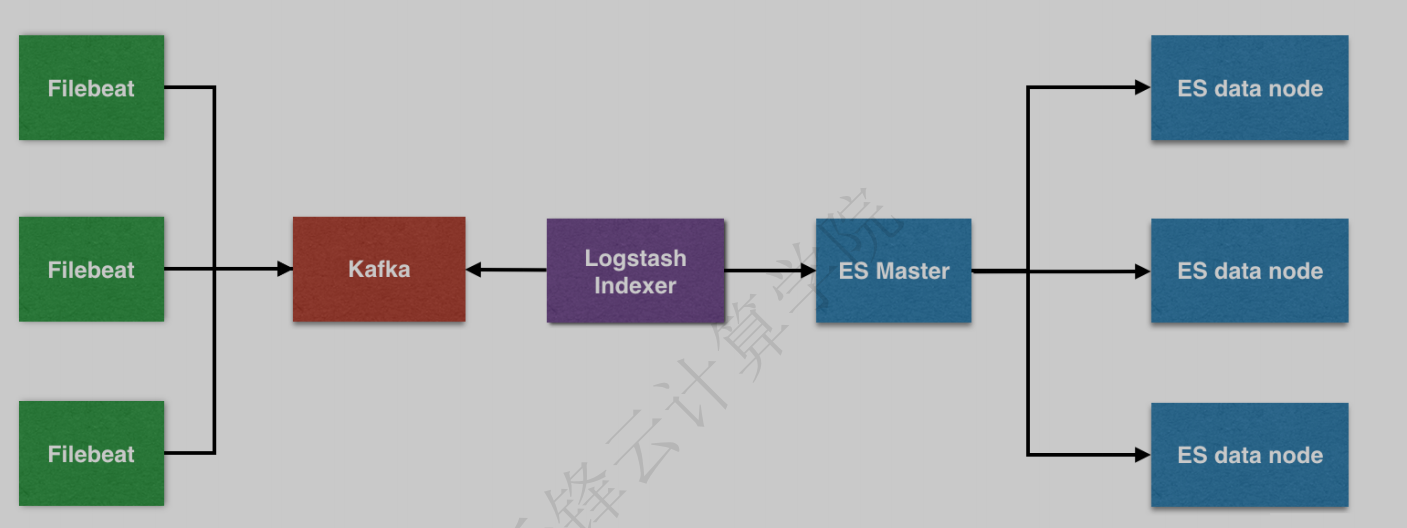
这里我按收集日志,处理日志,存储日志,展示日志的顺序介绍组件,便于理解。
1、Filebeat
用来收集日志的,因为原来收集日志的工具Logstash是java开发的,占用资源过多,影响性能。
Filebeat收集到的日志会发给数据缓冲队列Kafka。
2、Kafka
数据缓冲队列。
处理各种消息队列的传递,提供数据缓冲的功能。
相当于打疫苗要排队,不能一拥而上。如果打疫苗的人太多了,就要增加疫苗接种点来接收打疫苗的人,Kafka就相当于疫苗接种点,日志量相当于打疫苗的人。
经过Kafka的数据会发给Logstash进行过滤。
3、Logstash
过滤日志,解析日志转为方便阅读的格式
经过Logstash的日志会存储在es搜索引擎中。
4、Elasticsearch
基于java开发的搜索引擎来着,可提供搜集、分析、存储数据三⼤功能。
5、Kibana
将日志使用web页面展示出来的工具。
总之,一套完整的ELK系统是通过filebeat收集日志,发往消息队列Kafka,再到Logstash过滤,存储在es,展示在kibana。
filebeat-->Kafka-->Logstash-->es-->kibana
三、环境介绍
1、环境介绍
| 主机名 | IP | 安装软件 | 内存配置 |
|---|---|---|---|
| es01 | 10.154.0.110 | es/zookeeper/kafka/kibana | 6G |
| es02 | 10.154.0.111 | es/zookeeper/kafka/logstash | 4G |
| es03 | 10.154.0.112 | es/ zookeeper/kafka/filebeat/nginx | 4G |
filebeat,有一台,收集nginx日志
kafka是集群,有三台,用于消息队列,需要安装依赖zookeeper
Logstash,有一台,用于过滤日志
es是集群,有三台,用于存储日志,其中110是master
kibana,有一台,用于展示日志
因为电脑性能有限,所有工具委屈一下挤一挤。
在实际生产环境中filebeat是安装在所有要收集日志的服务器上的。
kafka至少三台组成集群,数量由是否能消耗处理日志量为准,如果日志数据堆积,则需要增加kafka数量。
Logstash过滤日志一台即可。
es集群至少两台。
kibana展示一台即可。
2、版本说明
jdk: 1.8
Kafka: 2.11-1
Elasticsearch: 7.9.3
Logstash: 7.9.3
Kibana: 7.9.3
Filebeat: 7.9.3
除了kafka其他工具版本需要一致,因为我之前用的rpm包安装的,里面自带jdk,这次我使用二进制安装,需要提前安装jdk。
3、安装包下载
官网下载可能会很慢,我把所需要的软包上传到腾讯云上了,方便下载。
4、安装前的准备
#修改三台机器的主机名
$ hostnamectl set-hostname es01
$ hostnamectl set-hostname es02
$ hostnamectl set-hostname es03
#修改Hosts文件,三台都做
$ echo -e '10.154.0.110 es01\n10.154.0.111 es02\n10.154.0.112 es03'>> /etc/hosts
#检查
$ ping es01
$ ping es02
$ ping es03
#关闭防火墙跟selinux
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
getenforce
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
echo -e表示开启转义字符,\n就不会原样输出而是变成换行
四、搭建ES集群
1、安装JDK
因为ES是java编写的,运行需要jdk,三台都要做。
可以使用xshell里的工具-->发送键输入到所有会话
1)将上传的jdk传给其他机器
scp -rp ~/soft/jdk-8u211-linux-x64.tar.gz es02:~/soft/
scp -rp ~/soft/jdk-8u211-linux-x64.tar.gz es03:~/soft/
2)解压
tar zxvf jdk-8u211-linux-x64.tar.gz -C /usr/local/
mv /usr/local/jdk1.8.0_211 /usr/local/java
3)添加环境变量,单独设置环境变量脚本方便管理
echo '
JAVA_HOME=/usr/local/java
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
' >>/etc/profile.d/java.sh
source /etc/profile.d/java.sh
$ java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
2、安装ES
三台都要做
1)创建es账号,因为es需要非root用户来启动。
需要注意的是最好三台创建同样的uid跟gid的es用户,因为以后涉及到使用snapshot备份就很好做。
groupadd -g 1001 ela
useradd -u 1000 -g ela -s /bin/bash -M ela
echo "123456" | passwd --stdin ela #密码要尽量复杂,我这是测试环境
如果uid或gid已经被使用了,可查看
/etc/passwd跟/etc/group文件,找一个没有用的uid跟gid
2)解压
tar zxvf elasticsearch-7.9.3-linux-x86_64.tar.gz -C /usr/local/
3)创建必要目录,改权限
mkdir -p /data/elasticsearch/data
mkdir -p /data/elasticsearch/logs
chown -R ela.ela /data/elasticsearch/
chown -R ela.ela /usr/local/elasticsearch-7.9.3
4)备份配置文件
cd /usr/local/elasticsearch-7.9.3/config
cp elasticsearch.yml elasticsearch.yml.bak
#其实es配置文件抛开注释跟空行就啥也没有了,但是保险起见还是备份一下
cat config/elasticsearch.yml.bak | grep -v '#' | grep -v '^#'
5)修改es01的配置文件,注意这是es01的配置文件,es02跟es03的配置文件在后面
echo '
cluster.name: tz_elk
node.name: es01 #其他两台需要改这里
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: false #为什么要禁用内存锁定后续会说明
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.154.0.111","10.154.0.112"] #其他两台需要改这里
cluster.initial_master_nodes: ["10.154.0.110"] #指定master
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping_timeout: 150s
discovery.zen.fd.ping_retries: 10
client.transport.ping_timeout: 60s
http.cors.enabled: true
http.cors.allow-origin: "*"
' >>/usr/local/elasticsearch-7.9.3/config/elasticsearch.yml
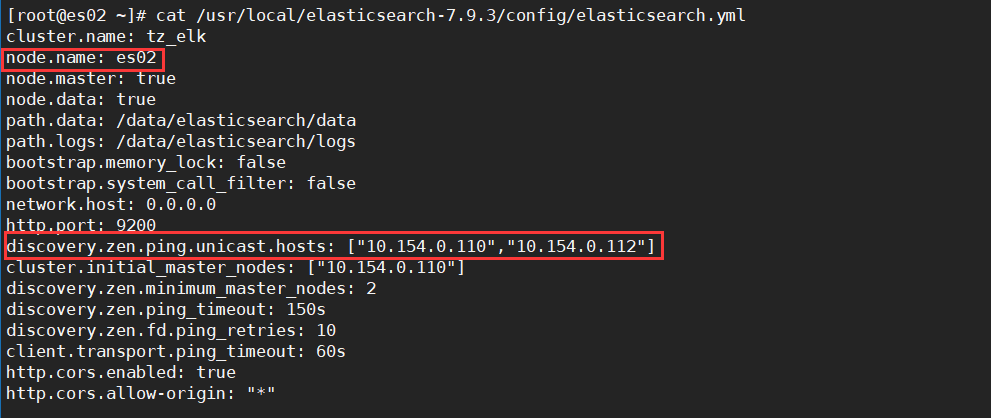
es02的配置文件如下
es03的配置文件如下
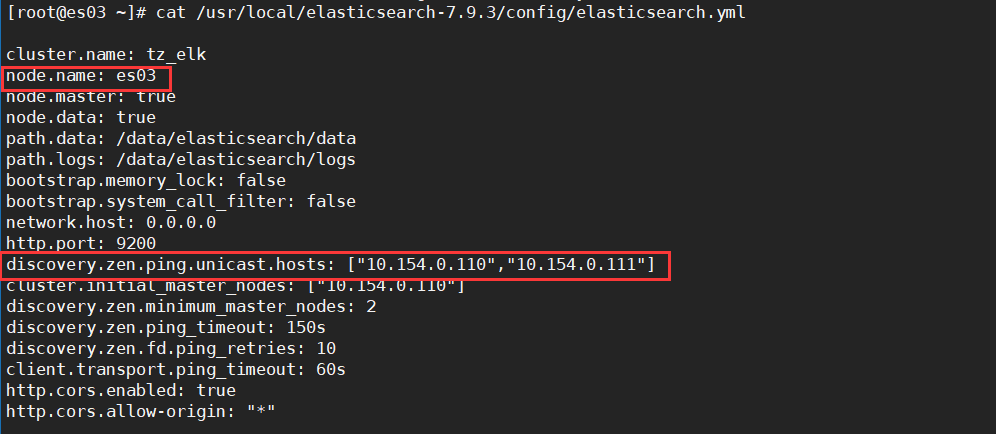
配置文件含义
cluster.name #集群名称,同一个集群内所有节点的集群名称必须一样。
node.name #节点名称,各节点配置不同。
node.master #表示该节点是否能成为主节点。
node.data #表示该节点是否能成为数据节点。数据节点包含并管理索引的⼀部分。
path.data #数据存储⽬录。
path.logs #⽇志存储⽬录。
bootstrap.memory_lock #内存锁定,是否禁⽤交换。
bootstrap.system_call_filter #系统调⽤过滤器。
network.host #绑定节点IP,配成0.0.0.0表示绑定所有接口的IP地址。
http.port #访问端⼝,默认9200。
discovery.zen.ping.unicast.hosts #能够被发现的es节点的IP地址。
discovery.zen.minimum_master_nodes #集群中可⼯作的具有Master节点资格的最⼩数量,官⽅的推荐值是(N/2)+1,其中N是具有master资格的节点的数量,例如我这有3台机器可以成为master,那么(3/2)+1=2,具有Master节点资格的最⼩数量就为2。
discovery.zen.ping_timeout #节点在发现过程中的等待时间。
discovery.zen.fd.ping_retries #节点发现失败的重试次数。
http.cors.enabled #是否允许跨源REST请求,⽤于允许head插件访问ES。
http.cors.allow-origin #允许的源地址。
6)设置JVM堆⼤⼩
sed -i 's/-Xms1g/-Xms2g/' /usr/local/elasticsearch-7.9.3/config/jvm.options
sed -i 's/-Xmx1g/-Xmx2g/' /usr/local/elasticsearch-7.9.3/config/jvm.options
注意
1.确保堆内存最⼩值(Xms)与最⼤值(Xmx)的⼤⼩应相同,防⽌程序在运⾏时改变堆内存⼤⼩。
2.如果系统内存⾜够⼤,将堆内存最⼤和最⼩值设置为31G,因为有⼀个32G性能瓶颈问题。
3.堆内存⼤⼩不要超过系统内存的50%
3、优化ES
1)增加最⼤⽂件打开数、最大进程数,修改完后退出会话重新连接才能生效。
vim /etc/security/limits.conf
* soft nofile 65536 #增加最⼤⽂件打开数
* hard nofile 131072 #增加最⼤⽂件打开数
* soft nproc 65536 #增加最大进程数
* hard nproc 65536 #增加最⼤进程数
#验证
ulimit -n
2)增加最大内存映射数以及禁用swap提高性能
echo "vm.max_map_count=262144" >> /etc/sysctl.conf
echo "vm.swappiness=0" >> /etc/sysctl.conf
sysctl -p #重新加载配置文件使其即时生效
3)防止内存未锁定报错(一定要看)
内存未锁定报错根本原因在于,ES使用普通用户启动进程,而普通用户无法进行锁定内存操作。
使用rpm或者yum安装的解决方案实质上是修改/etc/systemd/system/elasticsearch.service.d/override.conf 的配置文件,但是我是用的源码安装,网上的方法都用过了,还是会报内存未锁定报错,这里只能将配置文件中的bootstrap.memory_lock改为false了。
参考资料:
ES内存未锁定报错解决方案1
ES内存未锁定报错解决方案2
4、启动ES
1)启动es
#使用ela用户启动es
su - ela -c "cd /usr/local/elasticsearch-7.9.3/ && nohup bin/elasticsearch &"
#关闭es
fuser -k -n tcp 9200
注意使用nohup命令后台启动es,会在当前目录下生成nohup.out文件,里面记录了输出信息,即es启动信息。
如果出现找不到java报错,请删除/etc/profile里的java的环境变量,然后source一下
2)验证
#查看启动日志
tailf /usr/local/elasticsearch-7.9.3/nohup.out
#查看es进程
ps -ef | grep elastic
fuser -n tcp 9200
#查看es端口
ss -lntup| grep 9200
ss -lntup| grep 9300
五、部署Kibana
1、安装kibana
只在110机器上做。
1)解压
tar zvxf kibana-7.9.3-linux-x86_64.tar.gz -C /usr/local/
2)改名,备份配置文件,改权限,修改配置文件
mv /usr/local/kibana-7.9.3-linux-x86_64/ /usr/local/kibana-7.9.3
cp /usr/local/kibana-7.9.3/config/kibana.yml /usr/local/kibana-7.9.3/config/kibana.yml.bak
chown -R ela.ela /usr/local/kibana-7.9.3/
echo '
server.port: 5601
server.host: "10.154.0.110"
elasticsearch.hosts: ["http://10.154.0.110:9200"]
kibana.index: ".kibana"
'>/usr/local/kibana-7.9.3/config/kibana.yml
配置文件含义
server.port kibana #服务端⼝,默认5601
server.host kibana #主机IP地址,默认localhost
elasticsearch.url #⽤来做查询的ES节点的URL,默认http://localhost:9200
kibana.index #kibana在Elasticsearch中的存储的索引文件,默认.kibana
官方资料:其他配置项介绍
2、启动Kibana
#启动kibana
su - ela -c "cd /usr/local/kibana-7.9.3/ && nohup ./bin/kibana &"
#查看kibana端口
ss -lntup| grep 5601
#查看kibana进程号
fuser -n tcp 5601
#关闭kibana
fuser -k -n tcp 5601
3、配置nginx反向代理
前面介绍了给es跟es-head以及kibana添加密码认证,传送门在这里,这里介绍使用nginx反向代理添加密码认证,以防止任何人都能访问es跟es-head以及kibana。
1)配置yum源
rpm -ivh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
2)安装Nginx
httpd-tools用于生成nginx认证访问的用户密码文件
yum install -y nginx httpd-tools
3)修改Nginx配置文件
这里的反向代理配置为访问http://10.154.0.110就跳转访问http://10.154.0.110:5601,即kibana
使用谷歌es-head插件连接http://10.154.0.110:81就能连接上es
vim /etc/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
worker_rlimit_nofile 65535;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 65535;
use epoll;
}
http {
include mime.types;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
server_names_hash_bucket_size 128;
autoindex on;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 120;
types_hash_max_size 4096;
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
gzip on;
gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_http_version 1.0;
gzip_comp_level 2;
gzip_types text/plain application/x-javascript text/css application/xml;
gzip_vary on;
include /etc/nginx/mime.types;
default_type application/octet-stream;
include /etc/nginx/conf.d/*.conf;
server {
listen *:80;
access_log off;
location / {
auth_basic "Kibana";
auth_basic_user_file /etc/nginx/passwd.db;
proxy_pass http://10.154.0.110:5601;
proxy_set_header Host $host:5601;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Via "nginx";
}
location /status {
stub_status on;
access_log /var/log/nginx/kibana_status.log;
auth_basic "NginxStatus";
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
server {
listen *:81;
access_log off;
location / {
auth_basic "head";
auth_basic_user_file /etc/nginx/passwd.db;
proxy_pass http://10.154.0.110:9200;
proxy_set_header Host $host:9200;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Via "nginx";
}
}
}
介绍一个好用的nginx配置文件格式美化,点我美化
4)配置授权用户名密码
#请牢记配置的用户名密码
htpasswd -cm /etc/nginx/passwd.db tzelk
5)因为我将Nginx反向代理部署到了es01上,为了防止谷歌es-head插件通过9200端口访问各个节点的es,需要开启所有节点的防火墙,只允许节点之间的服务互相访问。
需要放通的服务端口有
- es端口:9200,9300
- zk端口:2181,3888,2888
- kafka端口:9092
#篇幅所限只给出es01节点的防火墙配置
firewall-cmd --add-service=http --permanent
firewall-cmd --add-port=80/tcp --permanent
firewall-cmd --add-port=81/tcp --permanent
firewall-cmd --add-port=22/tcp --permanent
#放通es02节点访问es01的相关服务端口
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.154.0.111" port protocol="tcp" port="2181" accept"
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.154.0.111" port protocol="tcp" port="3888" accept"
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.154.0.111" port protocol="tcp" port="2888" accept"
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.154.0.111" port protocol="tcp" port="9092" accept"
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.154.0.111" port protocol="tcp" port="9200" accept"
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.154.0.111" port protocol="tcp" port="9300" accept"
#放通es03节点访问es01的相关服务端口
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.154.0.112" port protocol="tcp" port="2181" accept"
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.154.0.112" port protocol="tcp" port="3888" accept"
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.154.0.112" port protocol="tcp" port="2888" accept"
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.154.0.112" port protocol="tcp" port="9092" accept"
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.154.0.112" port protocol="tcp" port="9200" accept"
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.154.0.112" port protocol="tcp" port="9300" accept"
firewall-cmd --reload
firewall-cmd --list-all
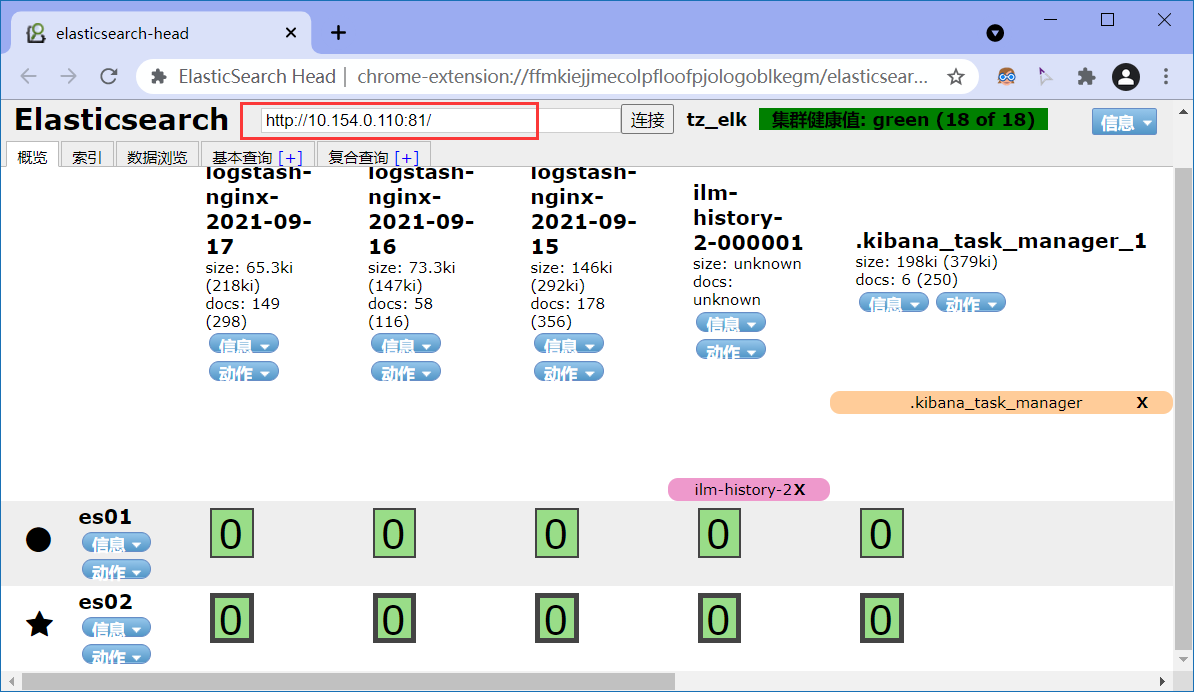
6)验证
访问http://10.154.0.110就能跳转到nginx认证页面,输入用户密码之后能访问到kibana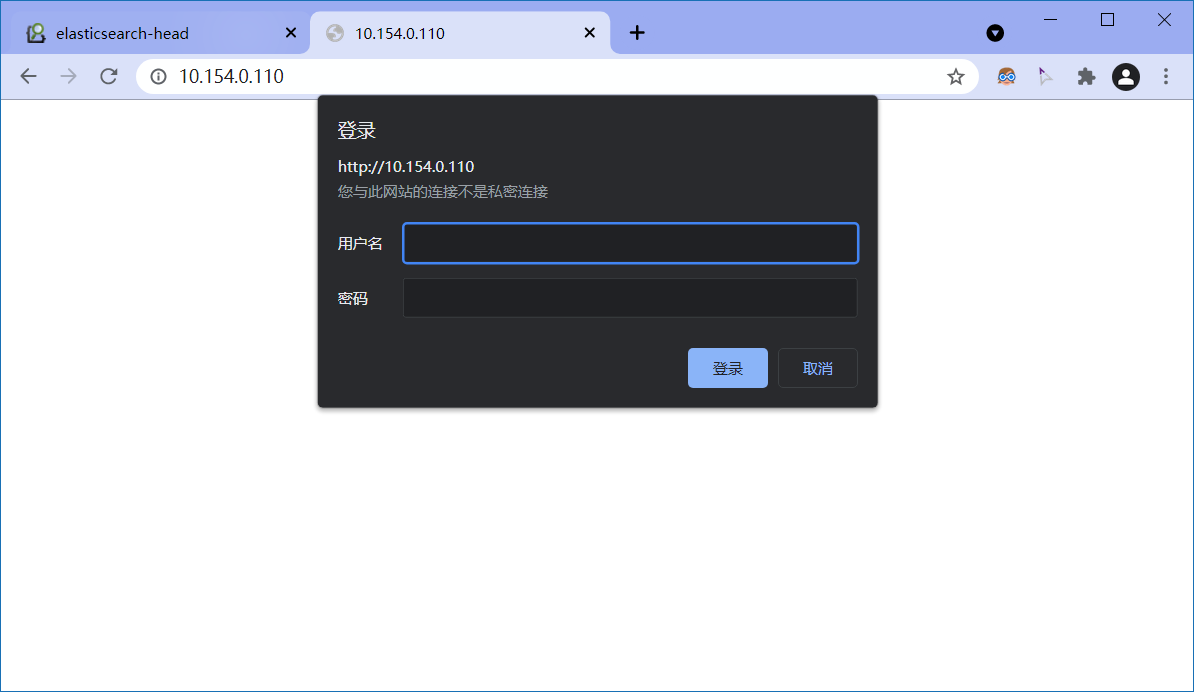
使用谷歌es-head插件访问http://10.154.0.110:81,输入用户密码之后就能访问到es
这样做有个缺点,如果es01的es服务挂了,那么就不能通过es-head访问es了,这时可以做负载均衡,让他跳转访问es02的es,负载均衡可以看我写的nginx文章,这里就不屁话了。
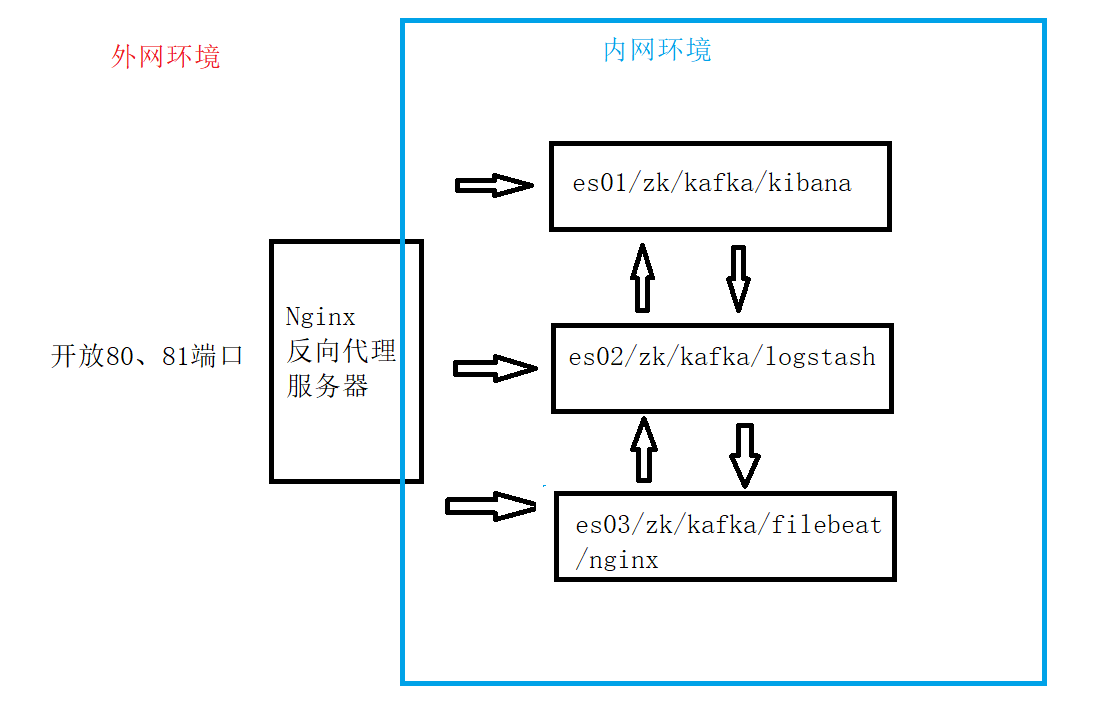
最好可以改为如下架构,这样就省去开启es节点的防火墙的功夫了,只需要开启Nginx的防火墙放通80,81端口即可。
六、搭建Kafka集群
1、安装JDK
Kafka依赖Zookeeper(以下都简称ZK)跟jdk。
前面讲过如何安装JDK了,这里就不多说了。
2、安装ZK
因为Kafka依赖ZK,所以Kafka官⽹提供的tar包中,已经包含了ZK,不用我们再去下载了。
注意不要下载成了
kafka_2.13-2.8.0.tgz,src表示源码包,下载后需要编译,kafka_2.13-2.8.0.tgz为二进制安装包,解压即用。
因为搭建的Kafka集群,所以三台机器上都要做。
1)解压
tar xzvf kafka_2.13-2.8.0.tgz -C /usr/local
2)配置ZK
#注释掉配置文件,然后追加配置,这一步我没做,我是直接备份的配置文件
sed -i 's/^[^#]/#&/' /usr/local/kafka_2.13-2.8.0/config/zookeeper.properties
#备份配置文件
cd /usr/local/kafka_2.13-2.8.0/config
cp zookeeper.properties zookeeper.properties.bak
echo '
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=10.154.0.110:2888:3888
server.2=10.154.0.111:2888:3888
server.3=10.154.0.112:2888:3888
'>>/usr/local/kafka_2.13-2.8.0/config/zookeeper.properties
配置项含义
dataDir #ZK数据存放⽬录。
dataLogDir #ZK⽇志存放⽬录。
clientPort #客户端连接ZK服务的端⼝。
tickTime #ZK服务器之间或客户端与服务器之间维持⼼跳的时间间隔。
initLimit #允许follower(相对于Leaderer⾔的“客户端”)连接并同步到Leader的初始化连接时间,以tickTime为单位。当初始化连接时间超过该值,则表示连接失败。
syncLimit #Leader与Follower之间发送消息时,请求和应答时间⻓度。如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
server.1=10.154.0.110:2888:3888 #2888是follower与leader交换信息的端⼝,3888是当leader挂了时⽤来执⾏选举时服务器相互通信的端⼝。
3)创建目录
mkdir -p /opt/data/zookeeper/{data,logs}
4)创建myid文件
#在es01上
echo 1 > /opt/data/zookeeper/data/myid
#在es02上
echo 2 > /opt/data/zookeeper/data/myid
#在es03上
echo 3 > /opt/data/zookeeper/data/myid
注意:每台kafka机器ID都不能一样
3、安装Kafka
1)前面说过,Kafka包里已经包含了ZK跟Kafka,所以这直接编辑配置文件
#注释掉配置文件,然后追加配置,这一步我没做,我是直接备份的配置文件
sed -i 's/^[^#]/#&/' /usr/local/kafka_2.13-2.8.0/config/server.properties
#备份配置文件
cd /usr/local/kafka_2.13-2.8.0/config/
cp server.properties server.properties.bak
#修改配置文件
echo '
broker.id=1 #每台不一样需要改,跟myid一致
listeners=PLAINTEXT://10.154.0.110:9092 #本地监听地址需要改
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=10.154.0.110:2181,10.154.0.111:2181,10.154.0.112:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
4lw.commands.whitelist=*
' >>/usr/local/kafka_2.13-2.8.0/config/server.properties
配置项含义
broker.id #每个server需要单独配置broker id,如果不配置系统会⾃动配置。需要和第4步配置的myid⼀致
listeners #本地监听地址
num.network.threads #接收和发送⽹络信息的线程数。
num.io.threads #服务器⽤于处理请求的线程数,其中可能包括磁盘I/O。
socket.send.buffer.bytes #套接字服务器使⽤的发送缓冲区(SO_SNDBUF)
socket.receive.buffer.bytes #套接字服务器使⽤的接收缓冲区(SO_RCVBUF)
socket.request.max.bytes #套接字服务器将接受的请求的最⼤⼤⼩(防⽌OOM)
log.dirs #⽇志⽂件⽬录。
num.partitions #分片数量。
num.recovery.threads.per.data.dir #在启动时恢复⽇志、关闭时刷盘⽇志每个数据⽬录的线程的数量,默认1。
offsets.topic.replication.factor #偏移量话题的复制因⼦(设置更⾼保证可⽤),为了保证有效的复制,偏移话题的复制因⼦是可配置的,在偏移话题的第⼀次请求的时候可⽤的broker的数量⾄少为复制因⼦的⼤⼩,否则要么话题创建失败,要么复制因⼦取可⽤broker的数量和配置复制因⼦的最⼩值。
log.retention.hours #⽇志⽂件删除之前保留的时间(单位⼩时),默认168
log.segment.bytes #单个⽇志⽂件的⼤⼩,默认1073741824
log.retention.check.interval.ms #检查⽇志段以查看是否可以根据保留策略删除它们的时间间隔。
zookeeper.connect #ZK主机地址,如果zookeeper是集群则以逗号隔开。
zookeeper.connection.timeout.ms #连接到Zookeeper的超时时间。
2)创建log目录
mkdir -p /opt/data/kafka/logs
4、启动ZK
1)启动ZK
#启动ZK
cd /usr/local/kafka_2.13-2.8.0/
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
#关闭ZK
cd /usr/local/kafka_2.13-2.8.0/
nohup bin/zookeeper-server-stop.sh &
2)验证ZK
#安装nc,通过nc验证
yum -y install nc
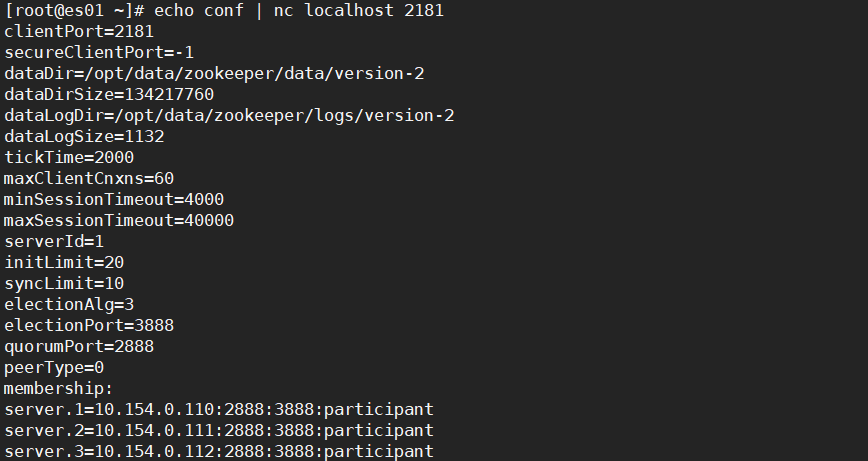
#查看ZK配置
echo conf | nc localhost 2181
#查看ZK状态
echo stat | nc localhost 2181
#查看端口
lsof -i:2181
lsof -i:3888
lsof -i:2888
效果如下
报错解决
#报错如下
$ echo conf | nc localhost 2181
conf is not executed because it is not in the whitelist.
#解决方案
echo '4lw.commands.whitelist=*' >>/usr/local/kafka_2.13-2.8.0/config/zookeeper.properties
#重启ZK,先关闭ZK,稍等一会,再重启ZK
cd /usr/local/kafka_2.13-2.8.0/
bin/zookeeper-server-stop.sh
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
5、启动Kafka
1)在三个节点执行,启动Kafka
#启动Kafka
cd /usr/local/kafka_2.13-2.8.0/
nohup bin/kafka-server-start.sh config/server.properties &
#关闭Kafka
cd /usr/local/kafka_2.13-2.8.0/
nohup bin/kafka-server-stop.sh &
2)验证
方法一
查看端口号,默认端口为9092
ss -lntup| grep 9092
方法二
在es01上创建一个名为testtopic的topic,topic相当于一个会话流。
cd /usr/local/kafka_2.13-2.8.0/
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic
效果如下

在es02机器上查询es01上的topic
cd /usr/local/kafka_2.13-2.8.0/
bin/kafka-topics.sh --zookeeper 10.154.0.110:2181 --list
效果如下

模拟消息⽣产者和消费者,es01作为消息生产者生成消息并发送给消费者es02
#在es01上执行
cd /usr/local/kafka_2.13-2.8.0/
bin/kafka-console-producer.sh --broker-list 10.154.0.110:9092 --topic testtopic
>Hello World!
#在es02上执行
cd /usr/local/kafka_2.13-2.8.0/
bin/kafka-console-consumer.sh --bootstrap-server 10.154.0.111:9092 --topic testtopic --from-beginning
在es01输入消息,效果如下

在es02上接收到消息,效果如下

七、部署Logstash
Logstash作为日志过滤工具,搭建在es02上。
1、安装JDK
Logstash也依赖JDK,安装方法看前面。
2、安装Logstash
1)解压
tar xzvf logstash-7.9.3.tar.gz -C /usr/local/
2)配置
#就不需要注释了吧,很容易看明白
mkdir -p /usr/local/logstash-7.9.3/etc/conf.d
vim /usr/local/logstash-7.9.3/etc/conf.d/input.conf
input {
kafka {
type => "nginx_kafka"
codec => "json"
topics => "nginx"
decorate_events => true
bootstrap_servers => "10.154.0.110:9092,10.154.0.111:9092,10.154.0.112:9092"
}
}
vim /usr/local/logstash-7.9.3/etc/conf.d/output.conf
output {
if [type] == "nginx_kafka" {
elasticsearch {
hosts => ["10.154.0.110","10.154.0.111","10.154.0.112"]
index => 'logstash-nginx-%{+YYYY-MM-dd}'
}
}
}
3、启动Logstash
1)启动Logstash
#启动
cd /usr/local/logstash-7.9.3/
nohup bin/logstash -f etc/conf.d/ --config.reload.automatic &
#关闭
kill -9 `ps -aux|grep logstash|awk '{print$2}'|awk 'NR==1'`
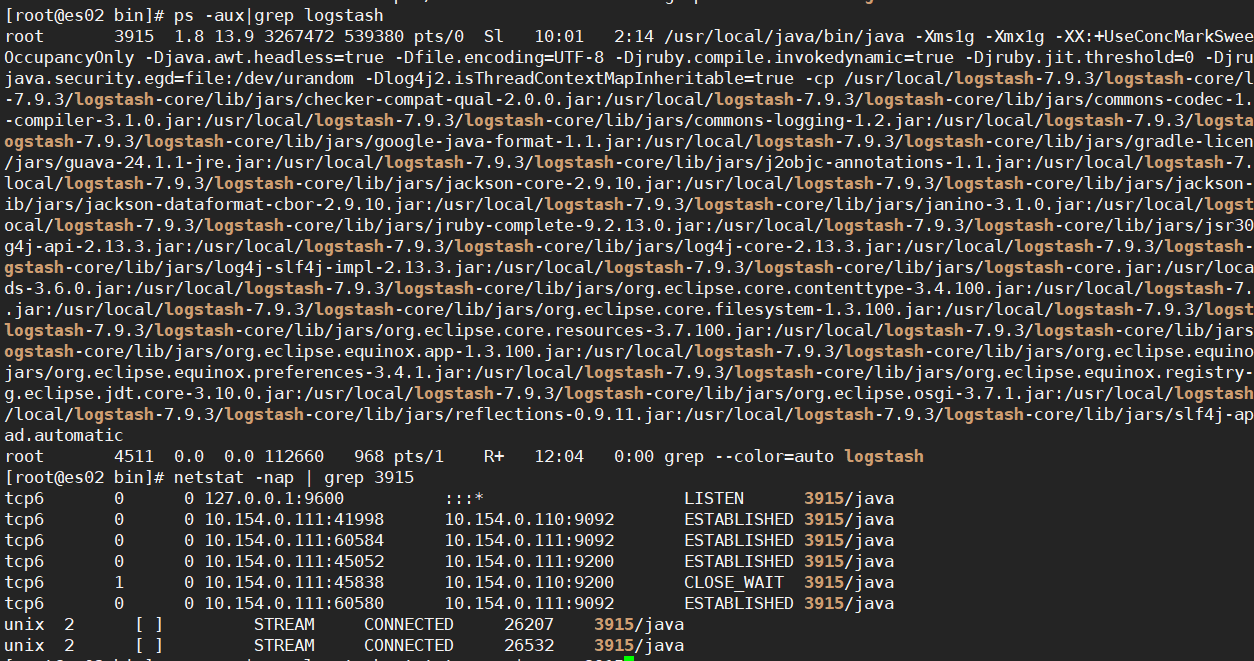
关于停止Logstash
从以下命令可看出Logstash使用的是随机端口连接kafka跟es的,所以不能通过端口来Kill掉Logstash
ps -aux|grep logstash
netstat -nap | grep 3915
2)验证
方式一
ps -aux|grep logstash
方式二
因为我们刚刚创建了个名为nginx的topics,现在有了nginx,表示Logstash启动成功。
cd /usr/local/kafka_2.13-2.8.0/bin
./kafka-topics.sh --zookeeper 10.154.0.111:2181 --list
效果如下

八、部署Filebeat
根据环境介绍,Filebeat将部署在es03上收集Nginx日志。
1、安装Filebeat
1)解压,改名
tar xzvf filebeat-7.9.3-linux-x86_64.tar.gz -C /usr/local/
cd /usr/local
mv filebeat-7.9.3-linux-x86_64 filebeat-7.9.3
2)备份配置文件,修改配置
cd /usr/local/filebeat-7.9.3/
cp filebeat.yml filebeat.yml.bak
vim /usr/local/filebeat-7.9.3/filebeat.yml
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/access.log
- /var/log/nginx/error.log
json.keys_under_root: true
json.add_error_key: true
json.message_key: log
output.kafka:
hosts: ["10.154.0.110:9092","10.154.0.111:9092","10.154.0.112:9092"]
topic: 'nginx'
配置说明
json.keys_under_root: true #keys_under_root可以让字段位于根节点,默认为false
json.overwrite_keys: true #对于同名的key,覆盖原有key值
json.message_key: message #message_key是⽤来合并多⾏json⽇志使⽤的,如果配置该项还需要配置multiline的设置,后⾯会讲
json.add_error_key: true #将解析错误的消息记录储存在error.message字段中
2、安装Nginx
#安装yum源
rpm -ivh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
#安装nginx
yum -y install nginx
#启动nginx
systemctl start nginx
#访问nginx让其产生日志
curl http://10.154.0.112
3、启动Filebeat
#启动
cd /usr/local/filebeat-7.9.3/
nohup ./filebeat -e -c filebeat.yml &
#关闭
kill -9 `ps -aux|grep filebeat|awk '{print$2}'|awk 'NR==1'`
这时访问es-head就会出现logstash-nginx-2021-09-16索引,表示es已经成功接收到了filebeat收集的nginx日志。
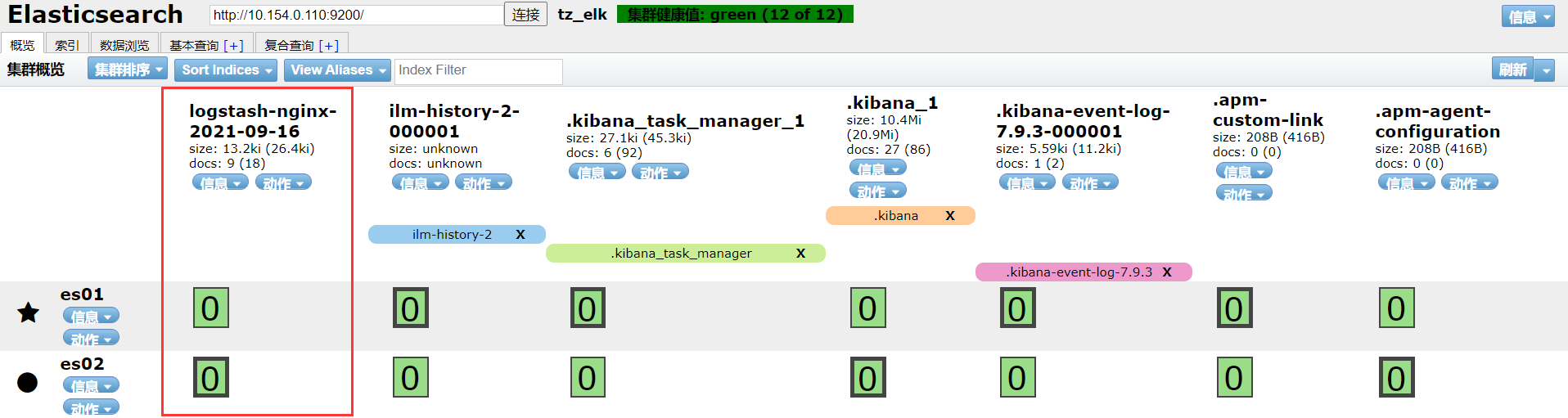
4、使用kibana查看日志
通过上述的配置,es已经成功的接收到了filebeat采集的日志,那么怎么通过kibana进行查看呢?
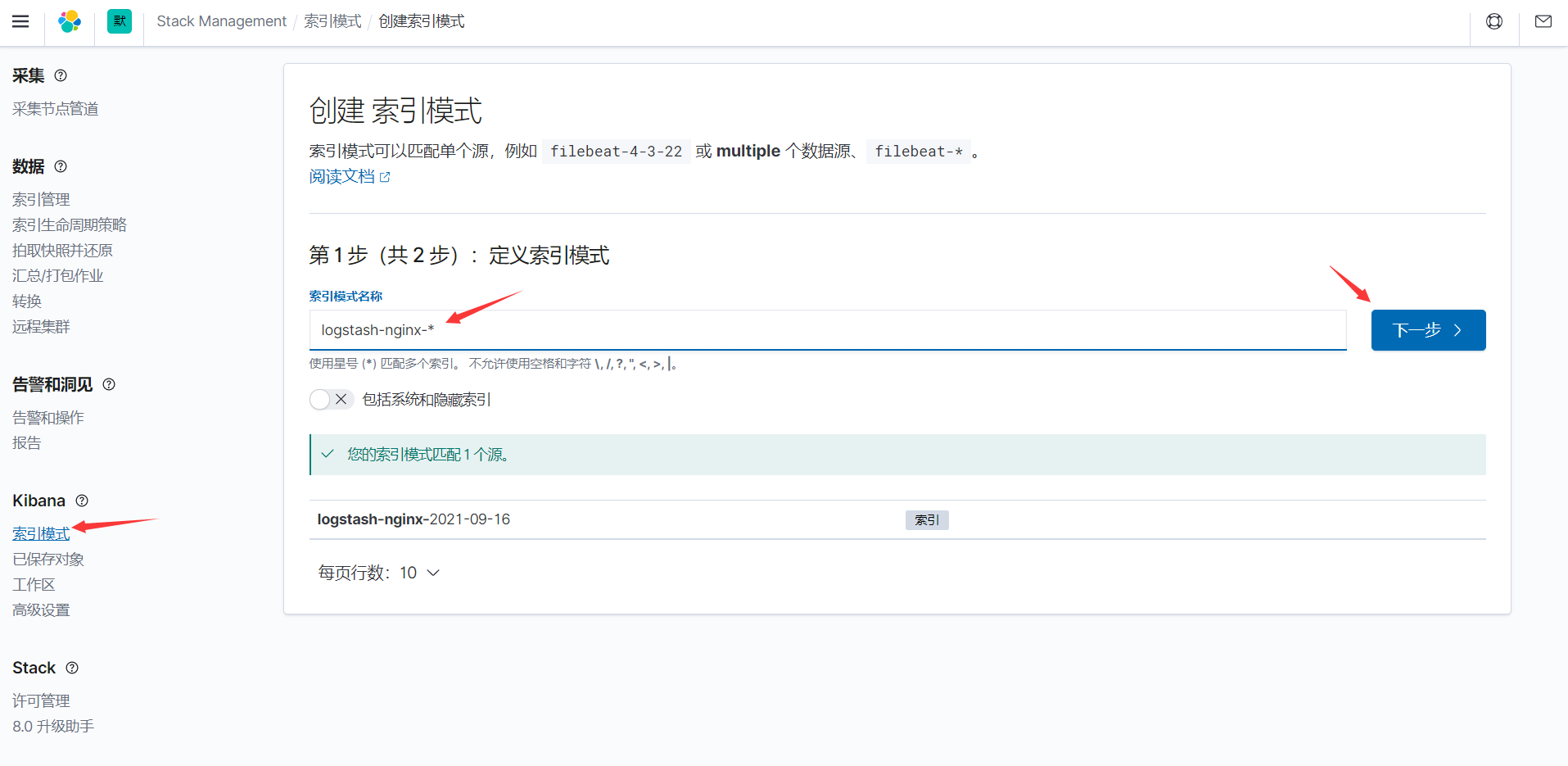
kibana主页-->安全性设置-->索引模式
在这里我们创建一个索引模式为logstash-nginx-*
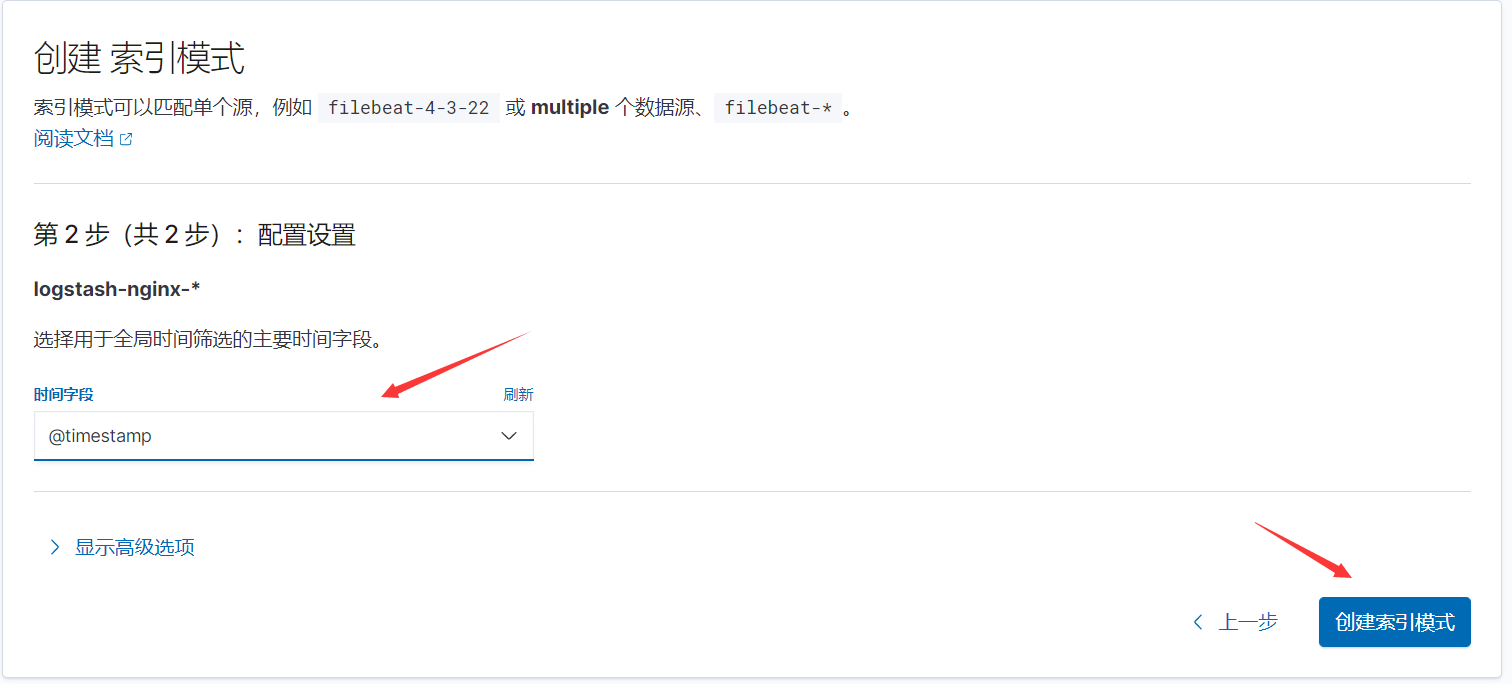
选择@timestamp,以时间作为筛选条件
kibana主页-->Discover
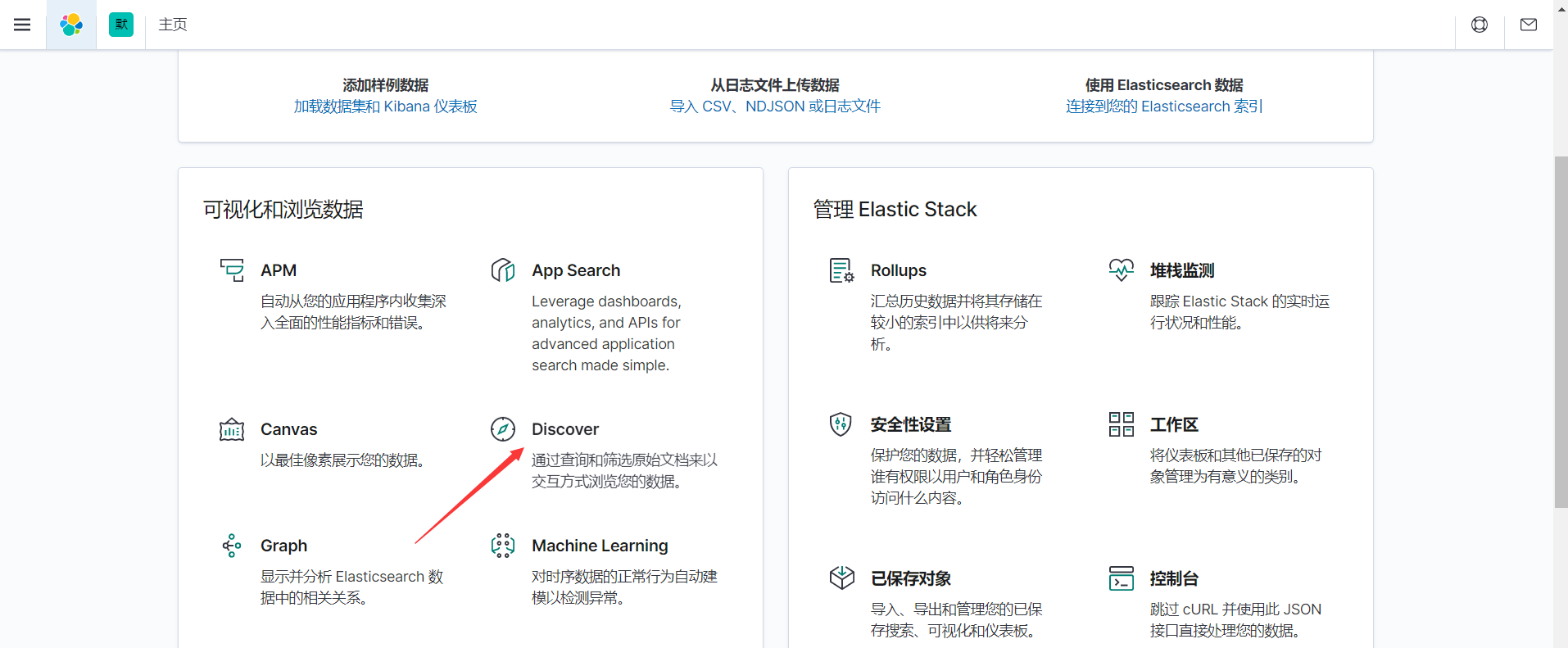
通过更改时间范围,就能看到日志了。
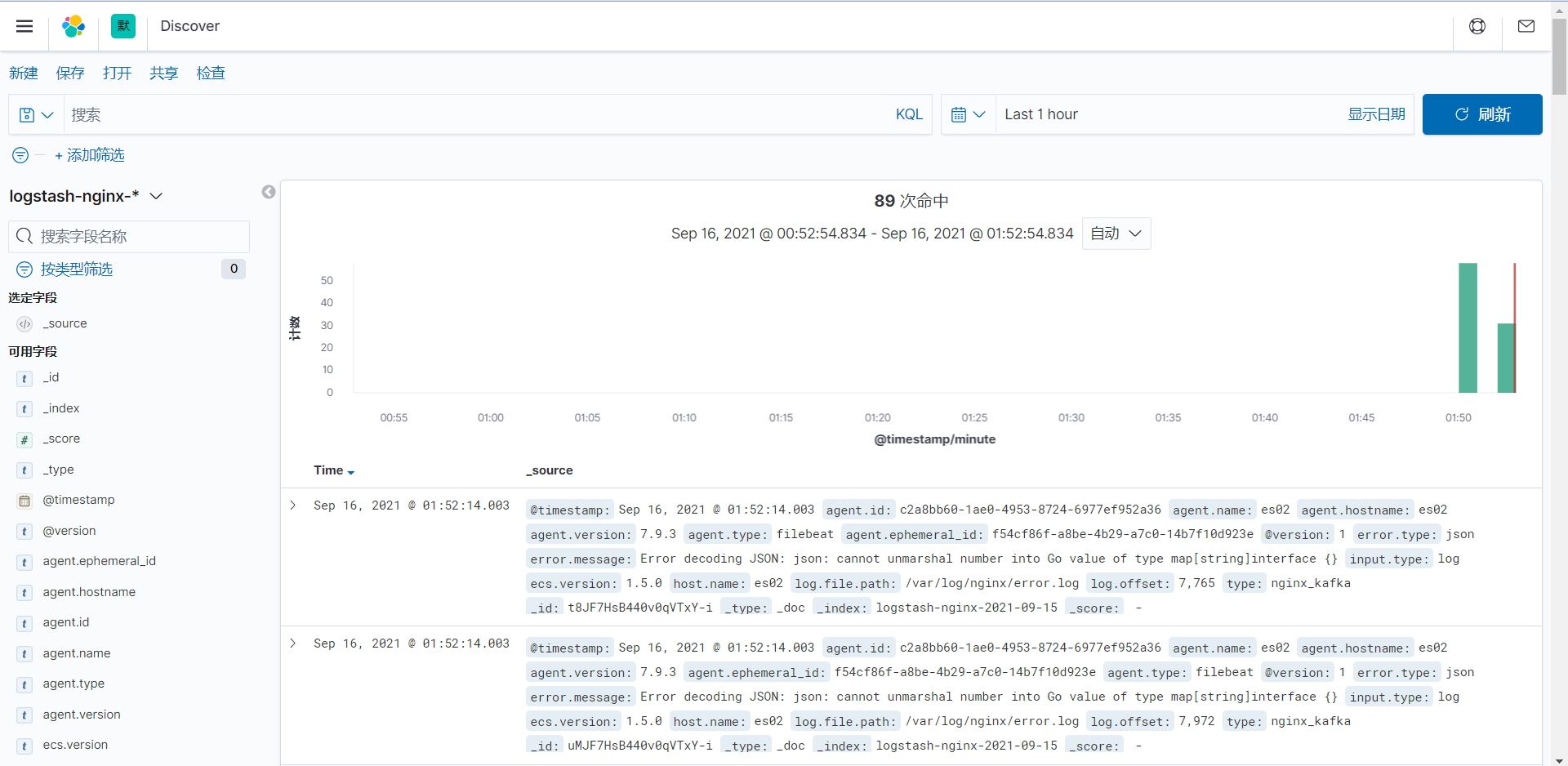
如果查不到日志的话,同步一下所有机器时间即可。
#在es01,es02,es03上执行
ntpdate cn.pool.ntp.org
九、写在最后
至此,搭建EFK一整套系统已经完成,看视频花了两天,做实验写博客花了三天时间,这里除了老师讲的,还写了一些我自己的做法,算是小小的补充吧。
有幸白嫖到千峰教育老师讲的课程,十分高兴,讲解的也很细致,在此十分感谢。
最近白嫖了不少老师的课程,在此对各位老师表示诚挚的感谢,学习的内容均有标明出处。
参考资料
千锋教育ELK