1.历史渊源
深度学习(deep learning)和神经网络(netural networks)这几年随着“阿尔法狗”以及ImageNet挑战赛的兴起而被炒得火热,然鹅这俩大兄弟已经不是生面孔了,而可以算是“老家伙了”。早在1943年,McCulloch and Pitts就设计了一个简单的神经元模型。之所以叫做神经元模型,是因为它的工作原理是模仿人类的大脑神经元。人类大脑中约有1000亿个神经元,互相之间的连接突触可达100万亿个。神经元有两种形态——兴奋或者抑制,兴奋就会把电信号传递给下一个神经元。通过数以亿计的神经元互相作用,最终使我们人类拥有了高级智慧。而神经元模型工作原理很简单,它也有两种状态——兴奋(标1)跟抑制(标0)。而之所以近几年深度学习跟神经网络开始广泛进入人们的视野是因为深度学习需要强大的计算能力跟足够的数据的支撑,以前由于技术跟数据的限制,所以没能发扬光大,所以科技是第一生产力!
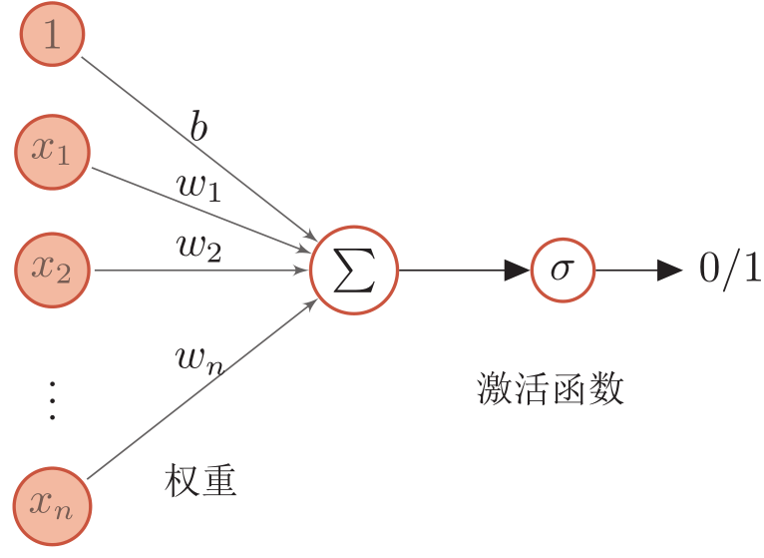
2.工作原理
如上图中所示,只有一层一个神经元,多个输入,我们可以通过y=wx+b求和得到一个数值,然后通过激活函数(图上是sigmoid函数;激活函数作用是把数值压缩在一定范围内,同时权重或者偏移的细小改变能够轻微影响到网络输出,这样可以更好的训练权重跟偏移)把该数值转为0-1之前的一个数,我们可以定义大于0.5为兴奋,小于0.5为抑制,这样就模拟了一个神经单元的工作过程。
当然,神经网络是由多个神经单元、多层神经结构构成的(下图是一个简单的前馈 神经网络),根据神经网络定义的不同可以分为卷积神经网络、循环神经网络以及各种变体等等,但是思想是不变的。

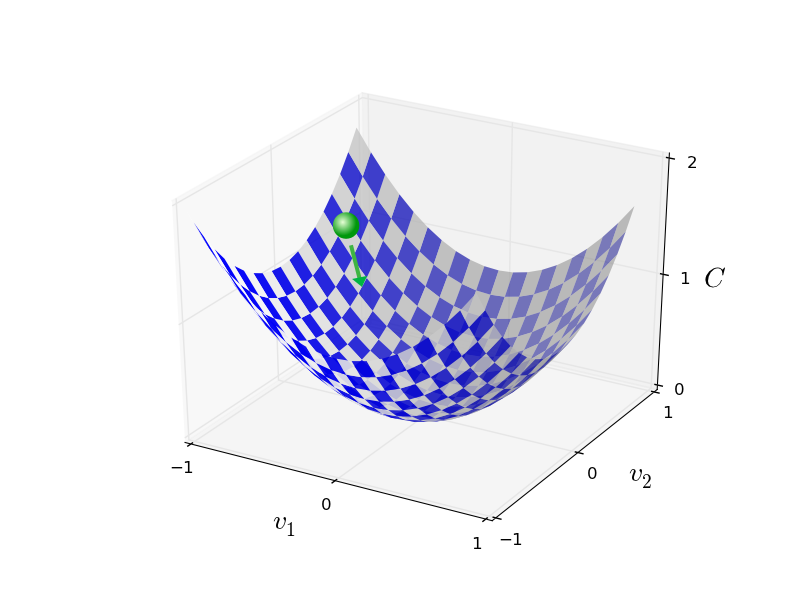
3.算法核心
深度学习一个强大之处是不用人工调整大量的参数,因为很多参数是模型自己根据大量的数据主动学习的!
主动学习的法宝就是误差逆传播(BackPropagation,简称BP),通过损失函数(Loss Function,用于描述模型输出值与真实值的差异)数值最小的原则,对各层输入向量求偏导,不断更新权重跟偏移的数值,最终求得参数的最优解——即模型输出很接近与真实输出。当然,如何更有效的学习,如何防止过拟合与欠拟合以及局部最优情况的出现也是一个很重要的问题,下次再详细讨论。