微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
举个例子,在微服务系统中,一个来自用户的请求,请求先达到前端A(如前端界面),然后通过远程调用,达到系统的中间件B、C(如负载均衡、网关等),最后达到后端服务D、E,后端经过一系列的业务逻辑计算最后将数据返回给用户。对于这样一个请求,经历了这么多个服务,怎么样将它的请求过程的数据记录下来呢?这就需要用到服务链路追踪。
Google开源的 Dapper链路追踪组件,并在2010年发表了论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,这篇文章是业内实现链路追踪的标杆和理论基础,具有非常大的参考价值。
常见的业界开源解决方案
1、Dapper(谷歌)
2、Zikpin,与Spring Cloud Sleuth结合的比较好
3、Eagleeye(阿里)
4、pinpoint
5、skywalking
本文主要讲述如何在Spring Cloud Sleuth中集成Zipkin。在Spring Cloud Sleuth中集成Zipkin非常的简单,只需要引入相应的依赖和做相关的配置即可。
Spring Cloud Sleuth简介
Spring Cloud Sleuth为Spring Cloud实现了分布式跟踪解决方案。
术语
Span:基本工作单元。例如,发送RPC是一个新的跨度,就像发送响应到RPC一样。跨度由跨度的唯一64位ID和跨度所属的跟踪的另一个64位ID标识。跨区还具有其他数据,例如描述,带有时间戳的事件,键值注释(标签),引起跨度的跨区ID和进程ID(通常为IP地址)。
跨度可以启动和停止,并且可以跟踪其时序信息。创建跨度后,您必须在将来的某个时间点将其停止。
PUT请求形成。Annotation:用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束 。这些注解包括以下:
- cs:客户端已发送。客户提出了要求。此注释指示跨度的开始。
- sr:接收到服务器:服务器端收到了请求并开始处理它。从此时间戳中减去
cs时间戳可显示网络延迟。 - ss:服务器已发送。在请求处理完成时进行注释(当响应被发送回客户端时)。从此时间戳中减去
sr时间戳将显示服务器端处理请求所需的时间。 - cr:收到客户。表示跨度结束。客户端已成功收到服务器端的响应。从此时间戳中减去
cs时间戳将显示客户端从服务器接收响应所需的整个时间。
图显示了Span和Trace在系统中的外观以及Zipkin批注:

音符的每种颜色都表示一个跨度(从A到G共有七个spans-)。请考虑以下注意事项:
Trace Id = X Span Id = D Client Sent
该说明指出,当前跨距跟踪编号设定为X和Span标识设置为d。同样,发生了Client Sent事件。
下图显示了spans的父子关系:

Zipkin简介
Zipkin是一个分布式跟踪系统。它有助于收集解决服务体系结构中的延迟问题所需的时序数据。功能包括该数据的收集和查找。
链路追踪案例架构图

Zipkin服务端搭建
1、下载Zipkin服务端jar包,可以去网关下载,也可以去地址:https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/
2、使用命令启动Zipkin服务端,命令:java -jar zipkin-server-2.12.9-exec.jar

3、使用浏览器访问地址:http://127.0.0.1:9411,9411是Zipkin的默认端口
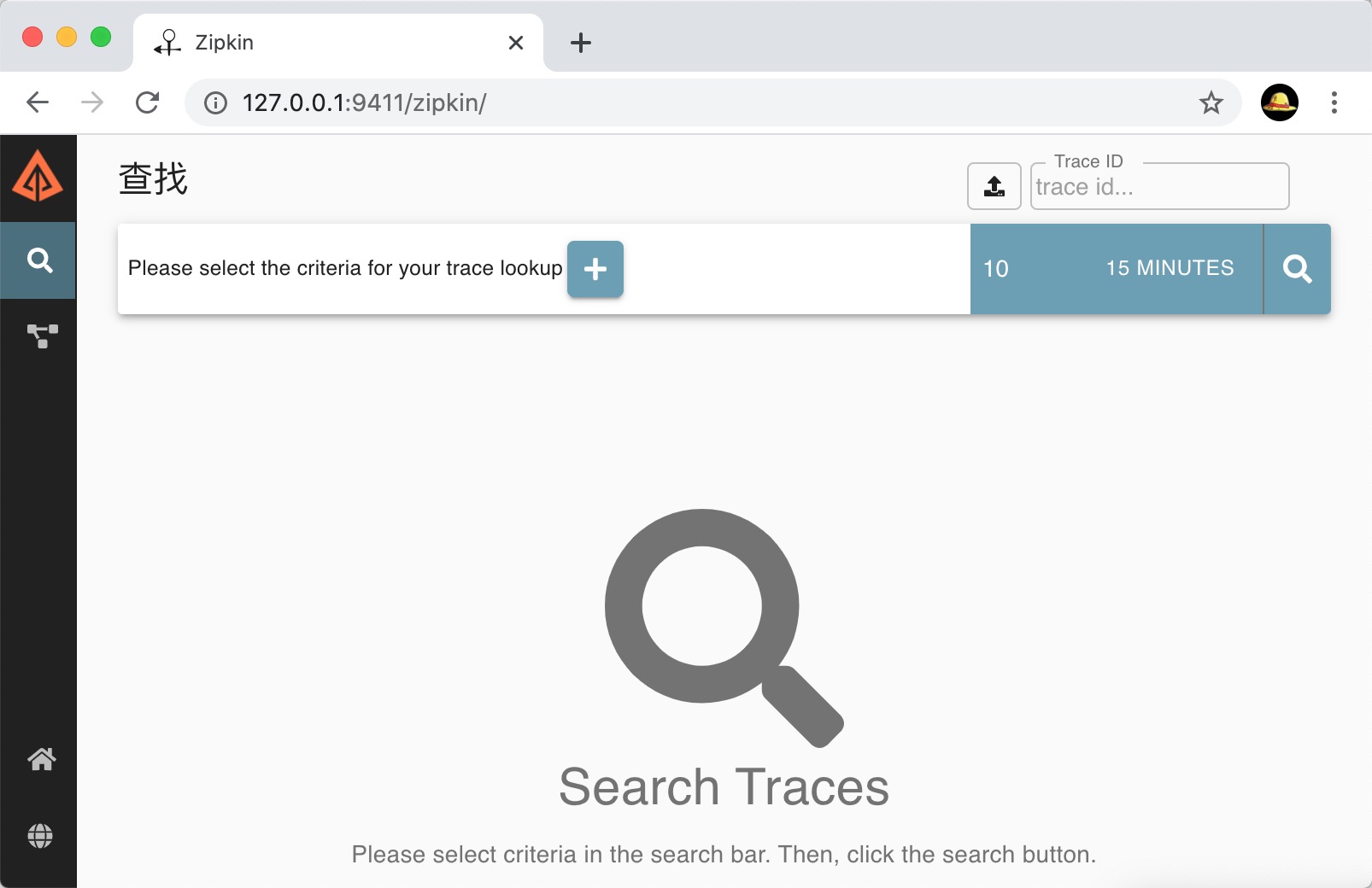
Sleuth服务提供者项目搭建
Eureka注册中心搭建参考:【SpringCloud】快速入门(一)
1、新建一个模块(springcloud-provider-sleuth-payment8010)作为Sleuth服务提供者
2、修改pom文件,引入依赖zipkin + sleuth,以及eureka
1 <!--zipkin + sleuth --> 2 <dependency> 3 <groupId>org.springframework.cloud</groupId> 4 <artifactId>spring-cloud-starter-zipkin</artifactId> 5 </dependency> 6 7 <!--eureka client --> 8 <dependency> 9 <groupId>org.springframework.cloud</groupId> 10 <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> 11 </dependency>
查看spring-cloud-starter-zipkin依赖,可以看到它包含了spring-cloud-starter-sleuth以及spring-cloud-starter-sleuth-zipkin依赖
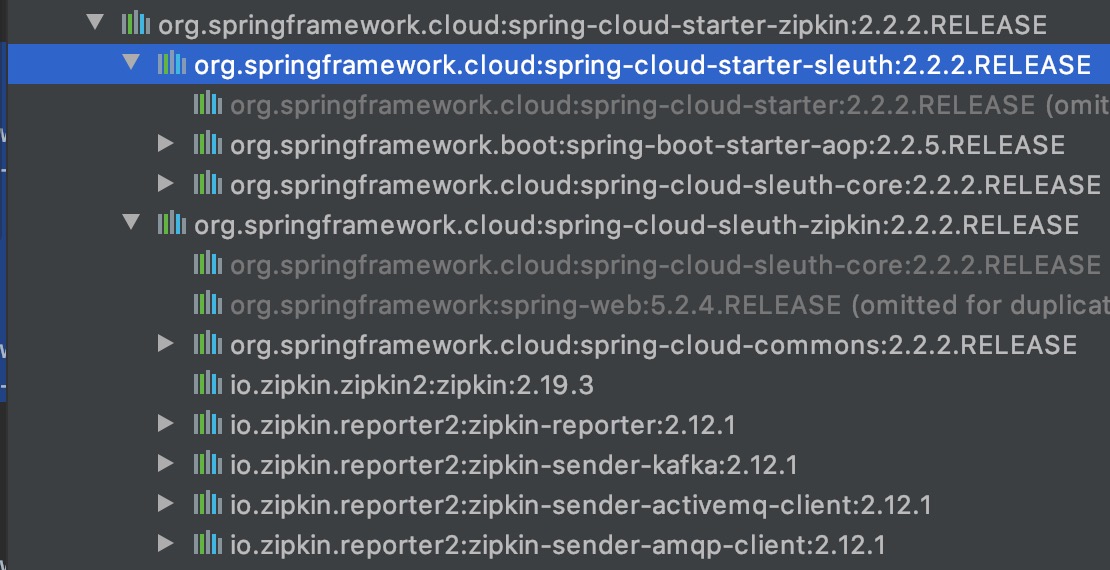
完整pom文件如下:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <project xmlns="http://maven.apache.org/POM/4.0.0" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 5 <parent> 6 <artifactId>test-springcloud</artifactId> 7 <groupId>com.test</groupId> 8 <version>1.0-SNAPSHOT</version> 9 </parent> 10 <modelVersion>4.0.0</modelVersion> 11 12 <artifactId>springcloud-provider-sleuth-payment8010</artifactId> 13 14 <dependencies> 15 16 <!--zipkin + sleuth --> 17 <dependency> 18 <groupId>org.springframework.cloud</groupId> 19 <artifactId>spring-cloud-starter-zipkin</artifactId> 20 </dependency> 21 22 <!--eureka client --> 23 <dependency> 24 <groupId>org.springframework.cloud</groupId> 25 <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> 26 </dependency> 27 28 <!--spring boot --> 29 <dependency> 30 <groupId>org.springframework.boot</groupId> 31 <artifactId>spring-boot-starter-web</artifactId> 32 </dependency> 33 <dependency> 34 <groupId>org.springframework.boot</groupId> 35 <artifactId>spring-boot-starter-actuator</artifactId> 36 </dependency> 37 38 <dependency> 39 <groupId>org.springframework.boot</groupId> 40 <artifactId>spring-boot-devtools</artifactId> 41 <scope>runtime</scope> 42 <optional>true</optional> 43 </dependency> 44 45 <dependency> 46 <groupId>org.projectlombok</groupId> 47 <artifactId>lombok</artifactId> 48 <optional>true</optional> 49 </dependency> 50 <dependency> 51 <groupId>org.springframework.boot</groupId> 52 <artifactId>spring-boot-starter-test</artifactId> 53 <scope>test</scope> 54 </dependency> 55 </dependencies> 56 57 </project>
3、编辑application.yml配置文件
1 #端口 2 server: 3 port: 8010 4 5 spring: 6 application: 7 name: cloud-sleuth-provider 8 zipkin: 9 #zipkin url地址 10 base-url: http://localhost:9411 11 sleuth: 12 sampler: 13 #采样率值介于 0 到 1 之间, 1 则表示全部采集 14 #默认值:0.1,即10% 15 probability: 1 16 17 eureka: 18 client: 19 service-url: 20 defaultZone: http://localhost:8761/eureka
4、编写启动类
1 @SpringBootApplication 2 public classPaymentMain8010 { 3 public static voidmain(String[] args) { 4 SpringApplication.run(PaymentMain8010.class, args); 5 } 6 }
5、编写Controller
1 @RestController 2 public classPaymentController { 3 4 @GetMapping("/payment/zipkin") 5 publicString paymentZipkin(){ 6 return "Hi, this is payment zipkin server"; 7 } 8 }
6、测试
1)启动Eureka注册中心,启动Sleuth服务提供者
2)访问地址:http://127.0.0.1:8010/payment/zipkin,正常获取内容

Sleuth服务消费者项目搭建
1、新建一个模块(springcloud-consumer-sleuth-order7995)作为Sleuth服务消费者
2、修改pom文件,引入依赖zipkin + sleuth,以及eureka,内容同上
3、编辑application.yml配置文件
1 #端口 2 server: 3 port: 7995 4 5 spring: 6 application: 7 name: cloud-order 8 zipkin: 9 base-url: http://localhost:9411 10 sleuth: 11 sampler: 12 #采样率值介于 0 到 1 之间, 1 则表示全部采集 13 probability: 1 14 15 eureka: 16 client: 17 service-url: 18 defaultZone: http://localhost:8761/eureka
4、编写启动类
1 @SpringBootApplication 2 public classOrderMain7995 { 3 public static voidmain(String[] args) { 4 SpringApplication.run(OrderMain7995.class, args); 5 } 6 }
5、编写配置类
1 @Configuration 2 public classAppConfig { 3 4 /** 5 * 注入restTemplate,请用请求rest接口 6 * @return 7 */ 8 @Bean 9 //标注此注解后,RestTemplate就具有了客户端负载均衡能力 10 //负载均衡技术依赖于的是Ribbon组件~ 11 //RestTemplate都塞入一个loadBalancerInterceptor 让其具备有负载均衡的能力 12 @LoadBalanced 13 publicRestTemplate restTemplate(){ 14 return newRestTemplate(); 15 } 16 }
6、编写controller,调用服务
1 @RestController 2 public classOrderController { 3 4 @Autowired 5 privateRestTemplate restTemplate; 6 7 @GetMapping("/consumer/payment/zipkin") 8 publicString paymentZipkin(){ 9 String result = restTemplate.getForObject("http://CLOUD-SLEUTH-PROVIDER" + "/payment/zipkin", String.class); 10 returnresult; 11 } 12 13 }
7、测试
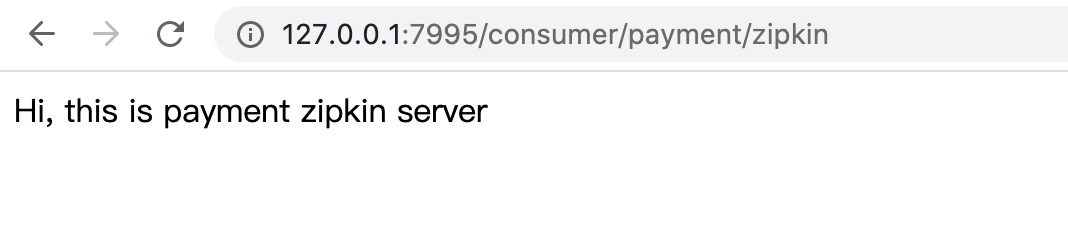
1)启动Eureka注册中心,启动Sleuth服务提供者、消费者,Zipkin服务端
2)访问地址:http://127.0.0.1:7995/consumer/payment/zipkin,正常获取内容
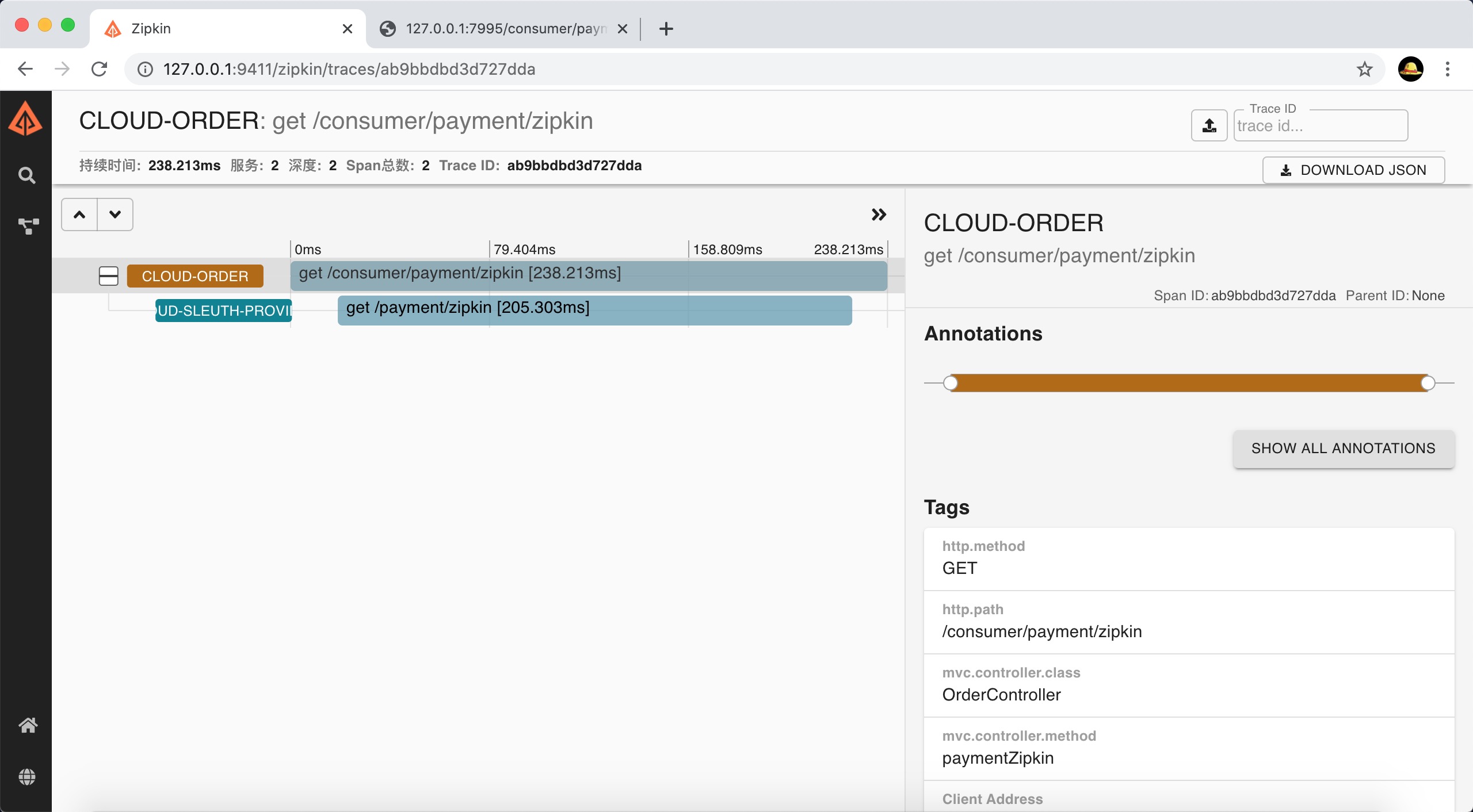
3)查看Zipkin的Web界面,地址:http://127.0.0.1:9411/zipkin,点击查询按钮
显示如下,可以看到里面的请求记录,包括:ROOT(微服务名,请求方式,请求路径)、TRACE ID、开始时间、持续时间

4)查看最近一次请求CLOUD-ORDER的详情数据
5)打开依赖页面,进行搜索,可以看打时间段内,服务之间的依赖关系
