Content1 引言
2 维数灾难与过拟和
3 怎样避免维数灾难
4 总结
1 引言
本文章讨论的话题是“curse of dimension”,即维数灾难,并解释在分类它的重要性,在下面的章节我会对这个概念做一个直观的解释,并清晰的描述一个由维数灾难引起的过度拟合的问题。
下面不如正题,考虑我们有一堆猫和狗的图片,现在要做一个分类器,它可以把猫和狗自动并且正确分类。所以对这个两个类别,首先需要一组描述符,使这两个类别可以被表示为数字,分类器可以使用数字来决定类别(如Logistic Regression 映射到sigmod后,与阈值比较大小来确定类别),本例中可以用颜色来进行分类,我们用红绿蓝三原色来表示,即平均的红色,平均的绿色,平均的蓝色这三个数值,结合三个给定的权重, 来最终构成一个线性分类器,决定最终的分类标签:
比如 if (0.5*red + 0.3*green + 0.2*blue >0.6)return cat;
elsereturn dog;
我们称这些代表颜色的数字为特征,这些特征不足以生成一个很好的分类器,一般来说,颜色无法区分猫和狗,所以需要添加更多的特征,来描述图片的结构,比如在X与Y方向的平均边缘或梯度强度来计算,结合起来便有5个特征,足矣分类猫和狗。
为了获得更精准的分类,可以添加更多基于颜色或者纹理直方图。统计矩的特征,也许特征达到一定维度,我们会得到一个堪称完美的分类器?其实不然,因为当特征达到一定维度后,再去增加维度会导致分类器的性能下降,这便是经常提到的“curse of dimension”如下图所示:
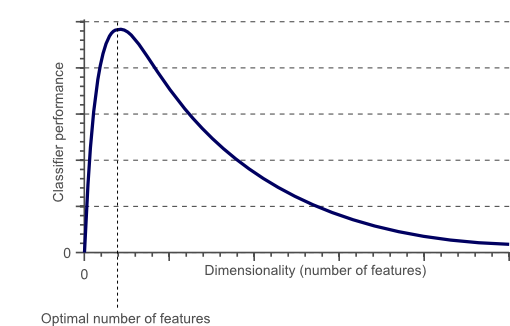
图1
2 维数灾难与过拟和假定有无穷多的猫和狗,任取10个猫或狗,我们的目标是使用10个训练样例,来对无穷多的测试样例进行分类,下面开始模型的构建,首先,随意输入一个特征,如三原色中的红色

图2,单一特征无法对训练集分类
由图2可见,单一特征几乎无法对数据进行分类,为了优化我们的模型,继续添加特征,这次添加绿色

图3,添加了第二个特征,仍然没有一条直线,可以进行线性分类
图3仍然无法完美分类,所以继续添加第三维的特征,如下图:

图4,三维空间中,能够找到一个超平面,来把猫和狗完美分类
由图4似乎可以看出,我们使用的特征组合越多,便能得到更精准的分类器。来对10个训练数据进行分类。
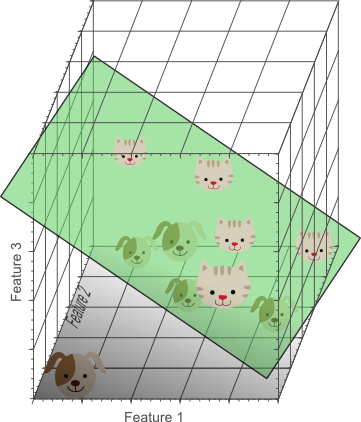
图5,特征数目越多,分类器就有越高的可能性来分类数据
通过上面的分析,我们得到的结论是,在得到一个性能优良的分类器前,增加特征便会有更好的分类效果,单事实却不是这样,正如图1的曲线所示。其实在增加特征时,样本的密度会呈指数形式下降。假设1维中长度为5个单位,2维中会有25个单位 3维则会达到125个单位,样本数目是固定的,本例中为10,可见维度的增高,样本密度会呈指数级下降,通过添加特征导致的稀疏,使我们易于找到一个超平面来把样本分离,因为特征数目趋于无穷大时,样本被分类错误的概率会变得无穷小,然而当把样本由高维投影到低维时,便会有一个严重的问题:

图6:3维投影到2维后的图示
图6可见,使用太多的特征,分类器也会拟合训练数据中的噪声误差,并且不能很好的泛化到新来的测试数据,即分类器不能把对样本数据的分类能力很好的泛化到训练数据。图6也能看出在3维空间中线性可分的数据,投影到2维空间后变为非线性可分,事实上,通过添加增加特征把数据映射到高维空间来获得一个优良的分类器,仅仅相当于在低维空间中使用一个复杂的非线性分类器(kernel method)。在高维空间中,我们的分类器只拟合了稀疏的训练数据,数据可能带有误差,这样便会使分类器不能应用到一个更广阔的数据集,即缺乏泛化性。这个概念便是由维数引起的over-fitting,下图展示了2维空间下线性分类的结果:

图7,虽然对训练数据分类不是很精确,但这个分类器会得到比图5更好的结果
直观来看,图7在训练数据上的分类效果不如图5,但这种简单的分类效果会更好的泛化到训练集以外的数据,因为它并没有拟合只出现在训练数据中的例外状况。换句话说,使用较少的特征,维数灾难是可以避免的,不会过度拟合训练数据。
图8用不一样的方式来描述了上述现象,比如现在我们用一个值在(0-1)之间的特征来分类训练数据,假定这个特征对猫与狗来说是可以区分的,如果我们想要覆盖特征空间的20%,我们便需要猫和狗总数的20%,如果添加一个特征,在2维空间中,要覆盖特征空间的20%,我们便需要在每个维度上取猫和狗的总数的45%,(0.45^2=2),同理,3维空间中需要在每个维度上取58%。
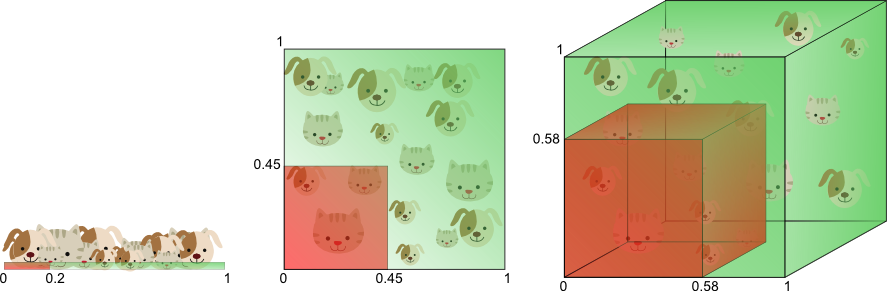
图8,随着维度增长,要覆盖20%的特征空间需要的训练数据会呈指数级增长
换句话说,如果可用训练数据的数量固定,增加维度会导致过度拟合。但是当训练数据随着维度以指数级增加时,分类器才会保持相同的覆盖率来避免过拟和。
上面的实例中,谈到了维数引起的训练数据的稀疏性,当训练数据固定时,特征越多,数据越稀疏,精确的估计分类器参数也就越困难(决策边界)。
维度灾难的另一个现象是稀疏数据并不是均匀分布在特征空间中,位于特征空间中心(超立方体中心)的数据要远比在特征空间角落的数据稀疏,可以这样理解:
二维空间中在一个单位正方形内画一个单位圆,如果数据不落在单位圆内,则表明其落在特征空间的角落,这些样本很难进行分类,因为其特征值有很大差别,如果大部分样本落在单位圆内,其分类则相对容易,如下图:

图9
现在有一个问题就是随着维度的增加,单位圆所占的空间与特征空间的比例是什么样的呢单位特征超空间的容量为1^d=1,d代表维度,单位圆的半径为0.5,公式如下
图10展示了随着维度的增加,单位圆容量的变化:
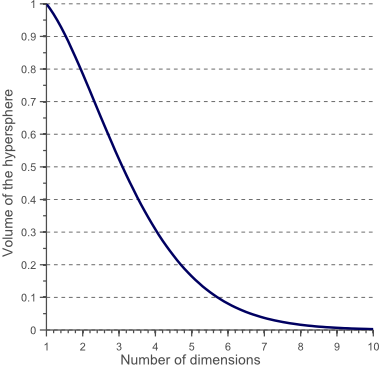
图10
这就表明,当维数变大时,特征超空间的容量不变,但单位圆的容量会趋于0,这种令人惊讶的反观察部分解释了分类中维数灾难相关的问题,在高维空间中,大多数训练数据驻留在特征超空间的角落。散落在角落的数据要比处于中心的数据难于分类,上面的讨论如下图所示,第三幅图为8维空间,有2^8=256个角
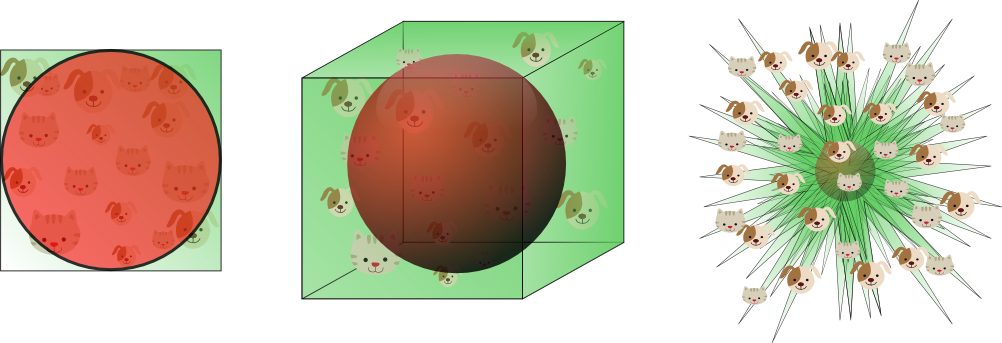
图11,随着维度的增加,很大比例的数据散落在特征空间的角落
8维空间有98%的数据散落在256个角落中,当维度趋于无穷时,样本点到特征空间中心最大与最小欧氏距离差异的比例以及最小的欧氏距离都会趋于0.
因此,距离度量在高维空间效果会很差,由于分类器需要依靠距离度量,如欧式,马氏,曼哈顿等,所以分类才低维空间进行会比较容易,对于Gussian分布,在高维空间会变的非常平坦,极大与极小似然的差与极小似然本身会趋于0.
出处:http://www.visiondummy.com/2014/04/curse-dimensionality-affect-classification/