本文来自公众号“AI大道理”
YOLO v3 是目前工业界用的非常多的目标检测的算法。
YOLO v3 没有太多的创新,主要是借鉴一些好的方案融合到 YOLO v2 里面。
不过效果还是不错的,在保持速度优势的前提下,提升了预测精度,尤其是加强了对小物体的识别能力。
YOLO v3 主要的改进有:
(1)调整了网络结构;
(2)利用多尺度特征进行对象检测;
(3)对象分类用 Logistic 取代了 softmax。

 YOLO v3的思想
YOLO v3的思想
1)多种尺度网格
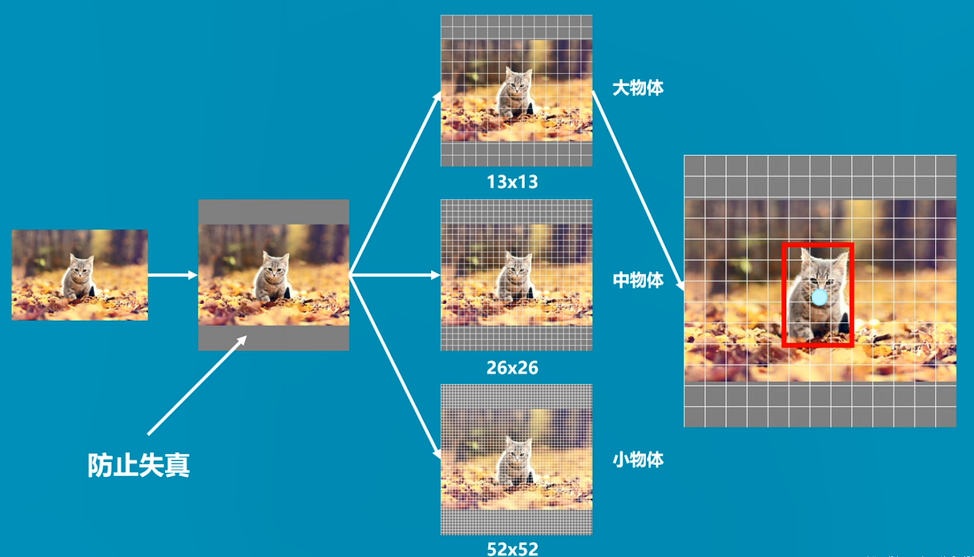
YOLO v3 的核心思想就是用 3 种不同的网格来划分原始图像。
其中 13 * 13 的网格划分的每一块最大,用于预测大物体。
26 * 26 的网格划分的每一块中等大小,用于预测中等物体。
52 * 52 的网格划分的每一块最小,用于预测小物体。
2)Darknet-53
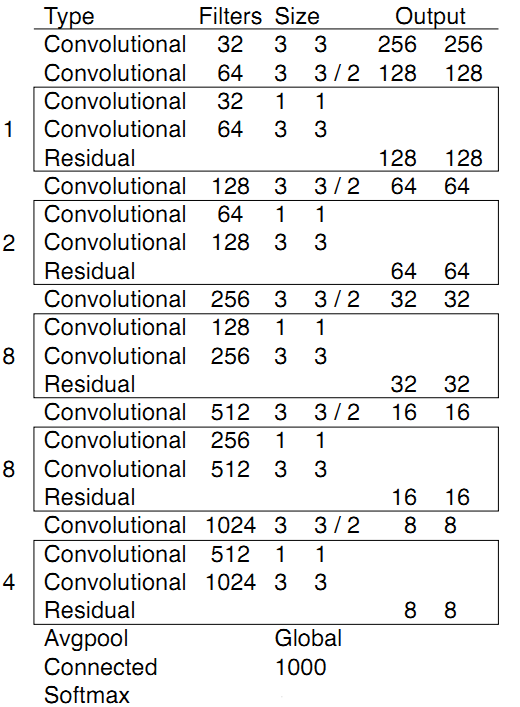
YOLO v3 的 backbone 采用了自己设计的 Darknet-53 的网络结构(含有53个卷积层),它借鉴了残差网络 residual network 的做法,在一些层之间设置了快捷链路(shortcut connections)。
上图的 Darknet-53 网络采用 256 * 256 * 3 作为输入,最左侧那一列的 1、2、8 等数字表示多少个重复的残差组件。每个残差组件有两个卷积层和一个快捷链路。

3)9 种尺度先验框
随着输出的特征图的数量和尺度的变化,先验框的尺寸也需要相应的调整。
YOLO v2 已经开始采用 K-means 聚类得到先验框的尺寸,YOLO v3 延续了这种方法,为每种下采样尺度设定 3 种先验框,总共聚类出 9 种尺寸的先验框。
在 COCO 数据集这 9 个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。
分配上,在最小的 13 * 13 特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。
中等的 26 * 26 特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。
较大的 52 * 52 特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。


蓝色框为聚类得到的先验框,黄色框是 ground truth,红框是对象中心点所在的网格。
4)输入与输出
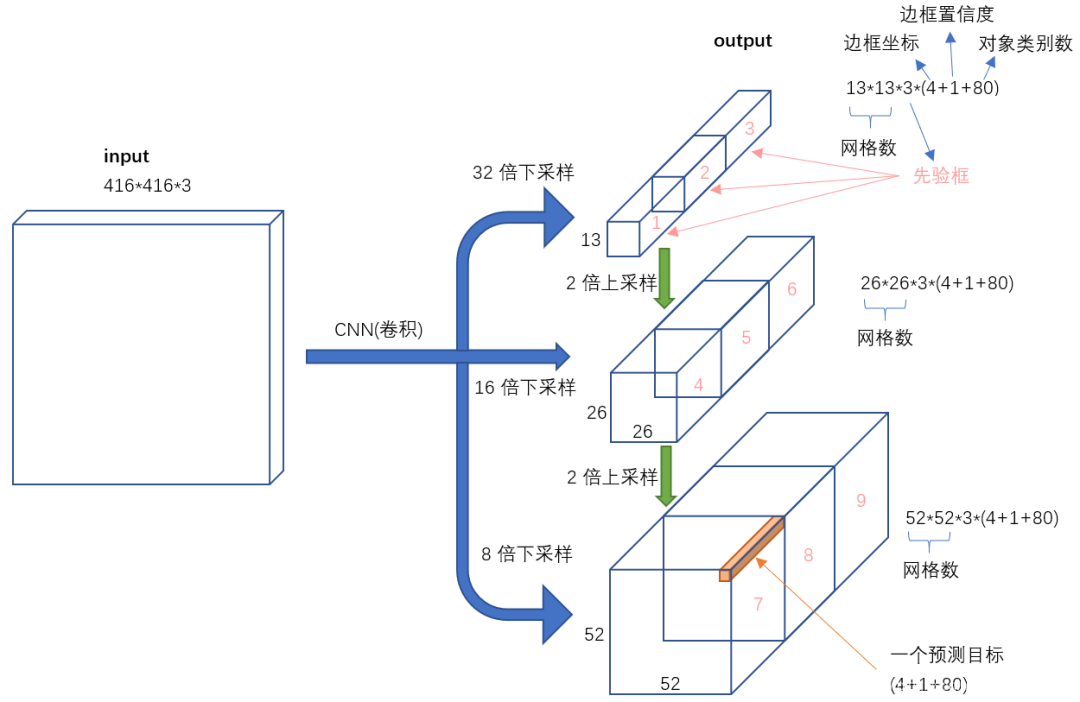
不考虑神经网络结构细节的话,总的来说,对于一个输入图像,YOLO v3 将其映射到 3 个尺度的输出张量,代表图像各个位置存在各种对象的概率。
对于一个 416 * 416 的输入图像,在每个尺度的特征图的每个网格设置 3 个先验框,总共有 13 * 13 * 3 + 26 * 26 * 3 + 52 * 52 * 3 = 10647 个预测。
每一个预测是一个 (4 + 1 + 80) = 85 维向量,这个 85 维向量包含边框坐标(4 个数值),边框置信度(1 个数值),对象类别的概率(对于 COCO 数据集,有 80 种对象)。
对比一下,YOLO v2 采用 13 * 13 * 5 = 845 个预测,YOLO v3 的尝试预测边框数量增加了 10 多倍,而且是在不同分辨率上进行,所以 mAP 以及对小物体的检测效果有一定的提升。
5)bounding box的坐标预测方式
bounding box的坐标预测方式还是延续了YOLO v2的做法。
简单讲就是下面这个截图的公式,tx、ty、tw、th就是模型的预测输出。
cx和cy表示grid cell的坐标,比如某层的feature map大小是13*13,那么grid cell就有13*13个,第0行第1列的grid cell的坐标cx就是0,cy就是1。
pw和ph表示预测前bounding box的size。
bx、by。bw和bh就是预测得到的bounding box的中心的坐标和size。
坐标的损失采用的是平方误差损失。
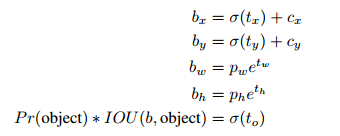
6)类别预测
类别预测方面主要是将原来的单标签分类改进为多标签分类。
因此网络结构上就将原来用于单标签多分类的softmax层换成用于多标签多分类的逻辑回归层。
为什么要做这样的修改?
原来分类网络中的softmax层都是假设一张图像或一个object只属于一个类别,但是在一些复杂场景下,一个object可能属于多个类。
比如你的类别中有woman和person这两个类,那么如果一张图像中有一个woman,那么你检测的结果中类别标签就要同时有woman和person两个类。
这就是多标签分类,需要用逻辑回归层来对每个类别做二分类。
逻辑回归层主要用到sigmoid函数,该函数可以将输入约束在0到1的范围内,因此当一张图像经过特征提取后的某一类输出经过sigmoid函数约束后如果大于0.5,就表示属于该类。
YOLO v3的网络结构
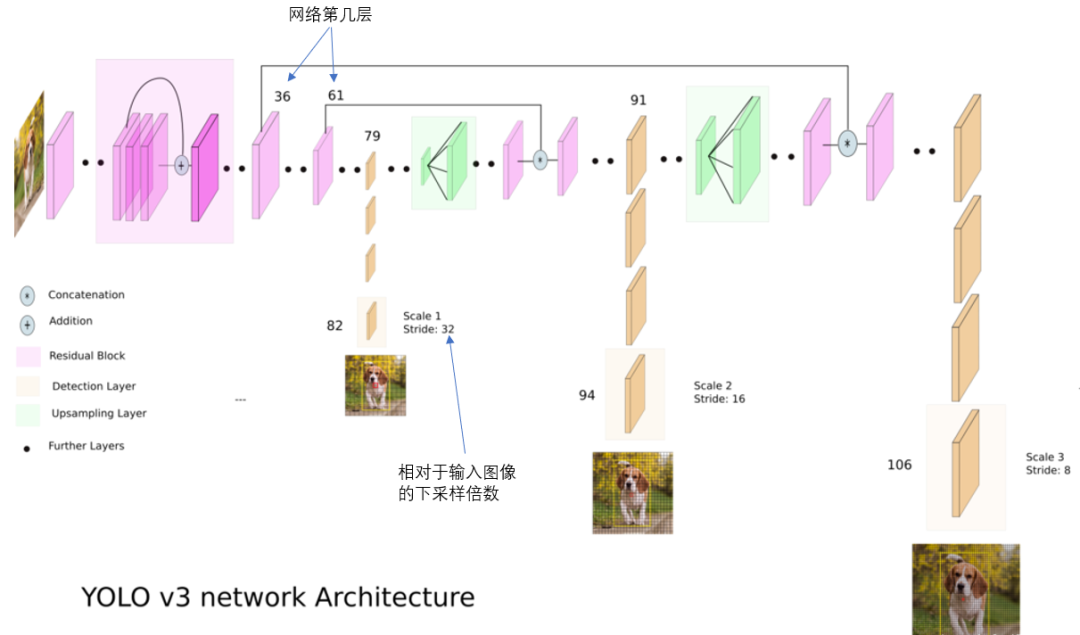
YOLO v2 曾采用 passthrough 结构来检测细粒度特征,在 YOLO v3 更进一步采用了 3 个不同尺度的特征图来进行对象检测。
结合上图看,卷积网络在 79 层后,经过下方几个黄色的卷积层得到一种尺度的检测结果。
相比输入图像,这里用于检测的特征图有 32 倍的下采样。
比如输入是 416 * 416 的话,这里的特征图就是 13 * 13 了。
由于下采样倍数高,这里特征图的感受野比较大,因此适合检测图像中尺寸比较大的对象。
为了实现细粒度的检测,第 79 层的特征图又开始作上采样(从 79 层往右开始上采样卷积),然后与第 61 层特征图融合(Concatenation),这样得到第 91 层较细粒度的特征图,同样经过几个卷积层后得到相对输入图像 16 倍下采样的特征图。
它具有中等尺度的感受野,适合检测中等尺度的对象。
最后,第 91 层特征图再次上采样,并与第 36 层特征图融合(Concatenation),最后得到相对输入图像 8 倍下采样的特征图。
它的感受野最小,适合检测小尺寸的对象。
YOLO v3 的损失函数
在YOLO v1中使用了一种叫sum-square error的损失计算方法,就是简单的差方相加而已。
但在v3的论文里没有明确提所用的损失函数。
其实也是跟YOLO v1类似,只是做了一些小调整。即损失还是四个特性((x,y)、(w,h)、分类和confidence)的损失累加起来,也就是一个loss_function搞定端到端的训练。
总结
YOLO3借鉴了残差网络结构,形成更深的网络层次,以及多尺度检测,提升了mAP及小物体检测效果。
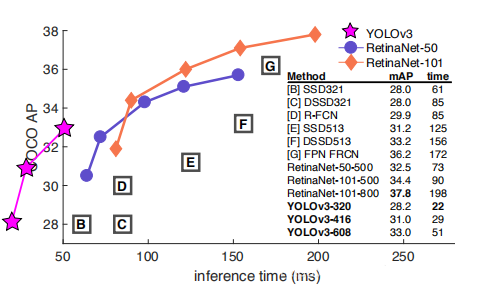
如果采用COCO mAP50做评估指标(不是太介意预测框的准确性的话),YOLO3的表现相当惊人,如下图所示,在精确度相当的情况下,YOLOv3的速度是其它模型的3、4倍。

——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————


—————————————————————