今天这道题是困难难度的,二狗很努力的尝试,还是失败了。但是感觉虽然没通过全部的测试用例,思考的过程还是有很多地方挺有趣的,记录一下。
97. 交错字符串
给定三个字符串s1, s2, s3, 验证s3是否是由s1和s2 交错组成的。
示例 1:
输入: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbcbcac"
输出: true
示例2:
输入: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbbaccc"
输出: false
先来看看我的想法以及做法吧:
这道题目很值得纪念一下。对官方给出的解答十分佩服,另外虽然自己做的过程 99/101 没有完全通过,但是思考过程也觉得有很多可以留意的地方。
初见这道题,两个字符串混合成第三个字符串。第一反应就是利用双指针,分别与第三个字符串进行比较.进一步思考发现也没有那么简单,比如遇到三个指针指向的字母现在是同一个的时候,比如都是'a'
应该选择哪个呢?顺着这个思路联想到了 回溯算法 没关系,现在两条路看起来都是正确的,那么我就去尝试,如果失败了我就回溯到选择的地方,选择另一条路径继续进行尝试。
除开简单的边界值考虑,上面这种双指针+回溯的算法其实很简单。需要考虑的就只有三种情况。
- s1,s2当前应该计算的字符与s3的应当计算的字符都不相等。 这种可以直接判断是不满足条件的,应当返回false.
- s1, s2与s3中当前对应应比较的字符有一个相等,这种其实只有一条路径,更新下次我们应该计算的索引即可。
- s1,s2与s3中当前对应应比较的字符全部都相等,这种其实就对应我们的回溯,应该选择一条路去尝试,不行就尝试另一条。
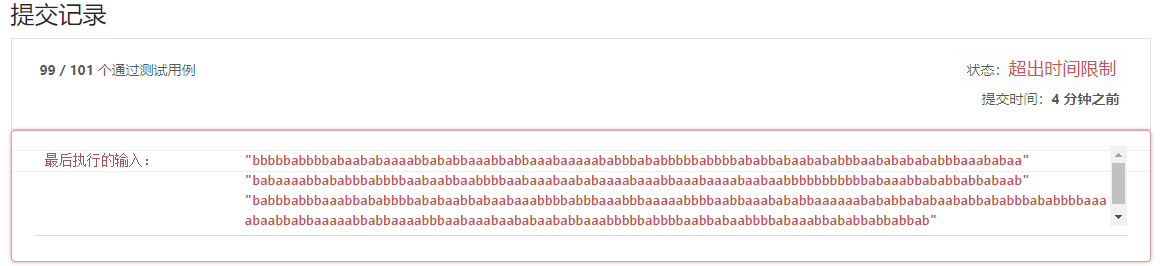
照着这个思路,前面的测试用例都通过了,直到遇到了测试用例99:
s1 "bbbbbabbbbabaababaaaabbababbaaabbabbaaabaaaaababbbababbbbbabbbbababbabaabababbbaabababababbbaaababaa"
s2 "babaaaabbababbbabbbbaabaabbaabbbbaabaaabaababaaaabaaabbaaabaaaabaabaabbbbbbbbbbbabaaabbababbabbabaab"
s3 "babbbabbbaaabbababbbbababaabbabaabaaabbbbabbbaaabbbaaaaabbbbaabbaaabababbaaaaaabababbababaababbababbbababbbbaaaabaabbabbaaaaabbabbaaaabbbaabaaabaababaababbaaabbbbbabbbbaabbabaabbbbabaaabbababbabbabbab"
像是为上面的方法量身定制的天敌一样,这组测试用例足够长,并且内容足够“简单”,只有a,b两个字符,因此按照上面的算法,遇到3的情况就会特别频繁。也就会花费大量的时间计算错误的路径,最后的结果当然是超时了。
但我其实不是很愿意轻易就放弃写好的算法,打算优化一下。首先作为回溯算法来说,合理的剪枝可以减少不必要的计算。但观察题目,我也没有想到特别好的剪枝的办法,因为实在不容易根据已计算的字符判断后续哪条路径是不正确的。
回忆起当初看的算法教程关于字符串匹配KMP算法的内容,其中一个核心思想是每次尽可能多的匹配字符。于是我也尝试这样做。
对于上述的2的这种情况,比如s1的当前索引i1对应的字符与s3当前索引i3对应的字符相等,s2的索引i2对应的字符不相等,下次递归我就会计算 i1+1,i2,i3+1 这三个字符的关系。就从这里下手,这种情况下,我们可以多计算一些偏移量。
具体来说就是如果i1+1,i2,i3+1仍满足这个条件,我们就继续向后偏移,直到不满足这种条件了我们才进行下一次的递归。结合代码如下:
if (ca1[i1] == ca3[i3] && ca2[i2] !=ca3[i3]) { int offset = 0; while (i1 + offset < ca1.Count() && ca1[i1 + offset] == ca3[i3 + offset] && ca2[i2] != ca3[i3 +offset]) { offset++; } if (ca2[i2] != ca3[i3 +offset]) return false; return huisu(ca1, i1 + offset, ca2, i2, ca3, i3+offset); }
这样一番改造后自信满满的去测试,仍旧超时。其实分析一下就明白了,上面的优化主要集中在2的那种情况,而98更多的其实会命中3的那种情况。
综上,完败,虽然有点不甘心,但还是服气的。完整代码在下面:
public bool IsInterleave(string s1, string s2, strings3) { if (s1.Length + s2.Length !=s3.Length) { return false; } if (string.IsNullOrEmpty(s1) || string.IsNullOrEmpty(s2)) { return s1 + s2 ==s3; } return huisu(s1.ToCharArray(), 0, s2.ToCharArray(), 0, s3.ToCharArray(), 0); } public bool huisu(char[] ca1, int i1, char[] ca2, int i2, char[] ca3, inti3) { if (i1 == ca1.Count() && i2 == ca2.Count() && i3 ==ca3.Count()) { return true; } if (i1 ==ca1.Count()) { for (int i = 0; i < ca3.Count() - i3 - 1; i++) { if (ca2[i2 + i] != ca3[i3 +i]) { return false; } } return true; } if (i2 ==ca2.Count()) { for (int i = 0; i < ca3.Count() - i3 - 1; i++) { if (ca1[i1 + i] != ca3[i3 +i]) { return false; } } return true; } if (ca1[i1] == ca3[i3] && ca2[i2] !=ca3[i3]) { int offset = 0; while (i1 + offset < ca1.Count() && ca1[i1 + offset] == ca3[i3 + offset] && ca2[i2] != ca3[i3 +offset]) { offset++; } if (ca2[i2] != ca3[i3 +offset]) return false; return huisu(ca1, i1 + offset, ca2, i2, ca3, i3 +offset); } else if (ca1[i1] != ca3[i3] && ca2[i2] ==ca3[i3]) { int offset = 0; while (i2 + offset < ca2.Count() && ca1[i1] != ca3[i3 + offset] && ca2[i2 + offset] == ca3[i3 +offset]) { offset++; } if (ca1[i1] != ca3[i3 +offset]) return false; return huisu(ca1, i1, ca2, i2 + offset, ca3, i3 +offset); } else if (ca1[i1] != ca3[i3] && ca2[i2] !=ca3[i3]) { return false; } else{ return huisu(ca1, i1 + 1, ca2, i2, ca3, i3 + 1) || huisu(ca1, i1, ca2, i2 + 1, ca3, i3 + 1); } }
下面是官方给出的动态规划的解法,让人眼前一亮。
解题过程中也有想过是否可以使用动态规划的思路去做,但没想到一个合适的状态转移方程,就没有继续思考下去。
来看看官方给出的状态转移的思路吧:传送门.
简单来说:关键是要找到当前的状态和上一个状态的关系,在这道题目中是 如果当前s1或s2的字符与s3相等,如果满足条件,那么上一个字符比如按也是满足的.C#版代码如下:
public bool IsInterleave(string s1, string s2, strings3) { if (s1.Length + s2.Length !=s3.Length) { return false; } bool[,] dp = new bool[s1.Length + 1, s2.Length + 1]; dp[0, 0] = true; for (int i = 0; i <= s1.Length; i++) { for (int j = 0; j <= s2.Length; j++) { int p = i + j - 1; if (i > 0) { dp[i, j] = dp[i, j] || (dp[i - 1, j] && s1[i - 1] ==s3[p]); } if (j > 0) { dp[i, j] = dp[i, j] || (dp[i, j-1] && s2[j - 1] ==s3[p]); } } } returndp[s1.Length, s2.Length]; }
虽然自己写的很爽,但是估计没有人会看的吧,如果你看到这里了,二狗子在这儿先谢谢您哈,哈哈。