摘要:
正常的csv文件读取如下:#coding:utf-8importcsvcsvfilename='demo.csv'printu'################获取某一行'withopen(csvfilename,'rb')ascsvfile:reader=csv.reader(csvfile)rows=[rowforrowinreader]printrows[0],rows[1],rows[2]
正常的csv文件读取如下:
#coding:utf-8 importcsv csvfilename = 'demo.csv' print u'################获取某一行'with open(csvfilename, 'rb') as csvfile: reader =csv.reader(csvfile) rows = [row for row inreader] print rows[0], rows[1], rows[2], rows[3] print u'################获取某一列'with open(csvfilename,'rb') as csvfile: reader =csv.reader(csvfile) column0 = [row[0] for row inreader] with open(csvfilename, 'rb') as csvfile: reader =csv.reader(csvfile) column1 = [row[2] for row inreader] printcolumn0, column1 s = [1,2,3] for i incolumn0: printtype(i) #print u'sum:',sum(column0) new_column0 =column0.pop(0) print u'删除的元素为:', new_column0 print u'删除后的列表:', column0 printtype(column0) for i incolumn0: print type(i)
读取一个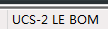 ucs-2 le 格式(notepa++打开csv)的csv就会报错: Python CSV error: line contains NULL byte 参考了这个文章里面的内容
ucs-2 le 格式(notepa++打开csv)的csv就会报错: Python CSV error: line contains NULL byte 参考了这个文章里面的内容
https://stackoverflow.com/questions/4166070/python-csv-error-line-contains-null-byte

代码如下:
#coding:utf-8 from __future__ importdivision importcsv importcodecs importxlwt importpandas as pd #twsfilename = "mem.csv"#134列 twsfilename = "tws.csv"#123列 #读取行 print u'################获取某一行'with codecs.open(twsfilename, 'rb', "utf-16") as csvfile: reader =csv.reader(csvfile) column1 = [row for row inreader] print column1[1][0].split(" ") print type(column1[1][0].split(" ")) print u'################获取某一列'with codecs.open(twsfilename, 'rb', "utf-16") as csvfile: reader = csv.reader(csvfile, delimiter='') reader.next()#向下跳一行 这行可以注释掉 主要为了去掉标题行 column1 = [row[1] for row inreader] printcolumn1 print "max:",max(column1) s =0 for i incolumn1: x =float(i) s +=x print "sum:",s,"count:",len(column1) #round (s / len(column1), 3) print "avg",round (s / len(column1), 3)

最后感谢大神 参考了很多都搞不定 什么.replace('