通过某种特定的条件,将存放在同一个数据库中的数据分散存放到多个数据库上,实现分布存储,通过路由规则路由访问特定的数据库,这样一来每次访问面对的就不是单台服务器了,而是N台服务器,这样就可以降低单台机器的负载压力。提示:sqlserver 2005版本之后,可以友好的支持“表分区”。
垂直(纵向)拆分:是指按功能模块拆分,比如分为订单库、商品库、用户库...这种方式多个数据库之间的表结构不同。
水平(横向)拆分:将同一个表的数据进行分块保存到不同的数据库中,这些数据库中的表结构完全相同。
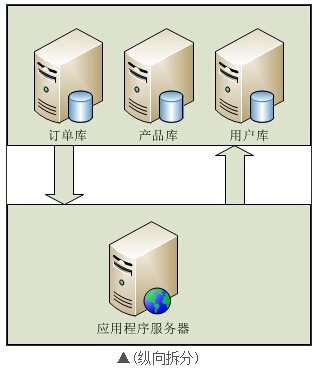
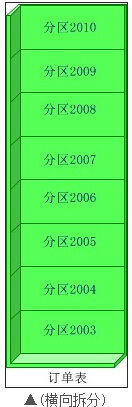
1. 实现原理:使用垂直拆分,主要要看应用类型是否合适这种拆分方式,如系统可以分为,订单系统,商品管理系统,用户管理系统业务系统比较明的,垂直拆分能很好的起到分散数据库压力的作用。业务模块不明晰,耦合(表关联)度比较高的系统不适合使用这种拆分方式。但是垂直拆分方式并不能彻底解决所有压力问题,例如 有一个5000w的订单表,操作起来订单库的压力仍然很大,如我们需要在这个表中增加(insert)一条新的数据,insert完毕后,数据库会针对这张表重新建立索引,5000w行数据建立索引的系统开销还是不容忽视的,反过来,假如我们将这个表分成100个table呢,从table_001一直到table_100,5000w行数据平均下来,每个子表里边就只有50万行数据,这时候我们向一张只有50w行数据的table中insert数据后建立索引的时间就会呈数量级的下降,极大了提高了DB的运行时效率,提高了DB的并发量,这种拆分就是横向拆分
2. 实现方法:垂直拆分,拆分方式实现起来比较简单,根据表名访问不同的数据库就可以了。横向拆分的规则很多,这里总结前人的几点,
(1)顺序拆分:如可以按订单的日前按年份才分,2003年的放在db1中,2004年的db2,以此类推。当然也可以按主键标准拆分。
优点:可部分迁移
缺点:数据分布不均,可能2003年的订单有100W,2008年的有500W。
(2)hash取模分: 对user_id进行hash(或者如果user_id是数值型的话直接使用user_id的值也可),然后用一个特定的数字,比如应用中需要将一个数据库切分成4个数据库的话,我们就用4这个数字对user_id的hash值进行取模运算,也就是user_id%4,这样的话每次运算就有四种可能:结果为1的时候对应DB1;结果为2的时候对应DB2;结果为3的时候对应DB3;结果为0的时候对应DB4,这样一来就非常均匀的将数据分配到4个DB中。
优点:数据分布均匀
缺点:数据迁移的时候麻烦;不能按照机器性能分摊数据 。
(3)在认证库中保存数据库配置
就是建立一个DB,这个DB单独保存user_id到DB的映射关系,每次访问数据库的时候都要先查询一次这个数据库,以得到具体的DB信息,然后才能进行我们需要的查询操作。
优点:灵活性强,一对一关系
缺点:每次查询之前都要多一次查询,会造成一定的性能损失。
原文:http://tech.it168.com/a2012/0110/1300/000001300144_2.shtml