内存数据刷写(MemStore Flush)
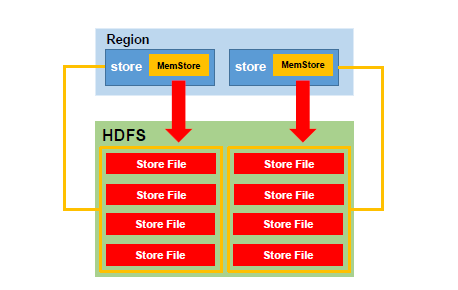
同一个Region上的不同Store代表了不同的列族,最终刷写到HDFS上的时候,会形成不同的文件夹。每一个Store都有一个MemStore,刷写数据正是从将MemStore的数据刷写到磁盘形成存储文件store file的。那么何时开始进行刷写呢?HBase制定了一系列的刷写策略,规定了内存何时开始刷写数据。在HBase的默认的核心配置文件中,有一些比较重要的属性,决定了何时开始刷写数据,这些属性作用域可能不相同。如下:
1、RegionServer级别的刷写时机
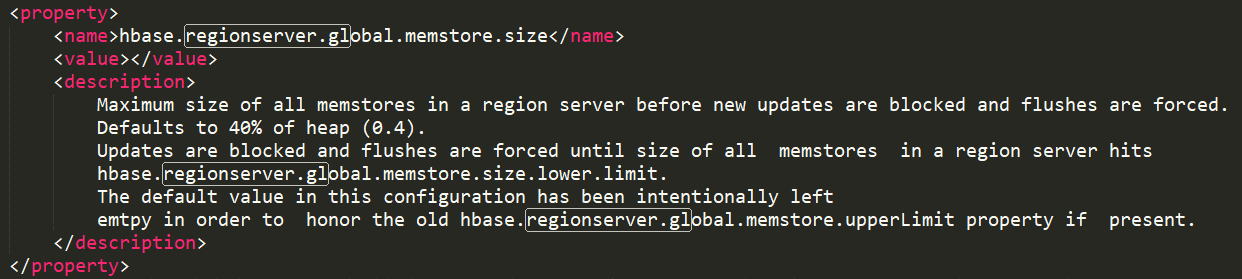
该属性的含义是,当一个RegionServer中的所有的MemStore之和最大达到Java堆内存的40%时,就会阻塞客户端的写操作,RegionServer中所有的memstore都会开始刷写,只有当所有的RegionServer中的所有MemStore大小之和小于另一个属性hbase.regionserver.global.memstore.size.lower.limit时,才会取消对客户端的阻塞。
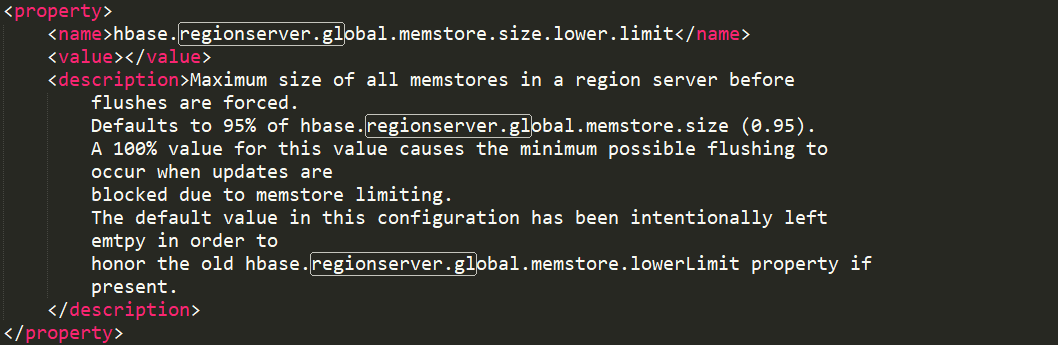
那么属性hbase.regionserver.global.memstore.size.lower.limit又有什么作用呢?这个属性可以理解为一个安全性的设置,有时一个集群的“写负载”非常高,写入的数据量一直大于刷写的数据量,那么就可能会造成内存崩溃,所以为了集群的安全性,就设置这个属性,当RegionServer的所有memstore的数据量超过这个属性的值的时候,所有memstore就开始刷写,然后如果写速度依旧大于刷写速度,那么memstore中的数据量还会增加,那么当所有的memstore的大小超过上面的那个属性值时,就会阻塞客户端写入数据。等到,所有的memstore数据量之后小于hbase.regionserver.global.memstore.size.lower.limit属性值的时候,取消对客户端的阻塞。
hbase.regionserver.global.memstore.size属性的默认值是Java堆内存的40%,即 0.4 * heapsize;
hbase.regionserver.global.memstore.size.lower.limit属性的默认值是,第一个属性的95%,即0.4 * 0.95 * heapsize
Flush顺序是按照Memstore由大到小的顺序执行,先刷写最大的Region,再执行次大的,直至总体Memstore内存使用量低于阈值(hbase.regionserver.global.memstore.lowerLimit * hbase_heapsize,默认 38%的JVM堆内存使用量)。
2、Region级别的刷写时机
第一种刷写时机,考虑的整体的RegionServer的情况,一旦触发整个RegionServer的memstore就都开始刷写,尽管有的memstore可能并没有多少数据。所以为了更加有针对性,对于单个的Region来说,也有相应的属性,规定单个Region下所有memstore的刷写时机。即:
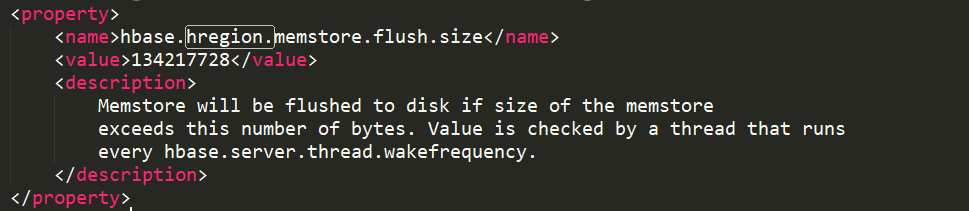
这个属性决定了单个Region何时开始刷写,当单个Region中的memstore超过了默认值128M,那么整个Region就开始进行一次刷写,我们每次调用 put、delete 等操作都会检查的这个条件的。同时还有一个属性,即
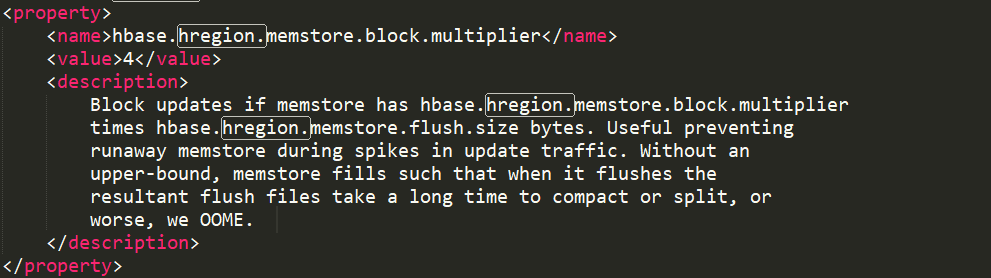
这个属性是决定Region何时阻塞客户端写入的,当上面Region的所有memstore数据量超过上面两个属性值相乘,那么就会开始阻塞客户端的写操作。
注意的是,memstore flush都是以region为单位进行刷写的,并不是以memstore为单位。
3、按照时间决定刷写时机
刷写的时机不仅由数据量决定,也可以由时间来触发,因为有的时候数据量并不大,可能很长时间都达不到刷写的量的要求,那么就需要时间来触发刷写的时机。
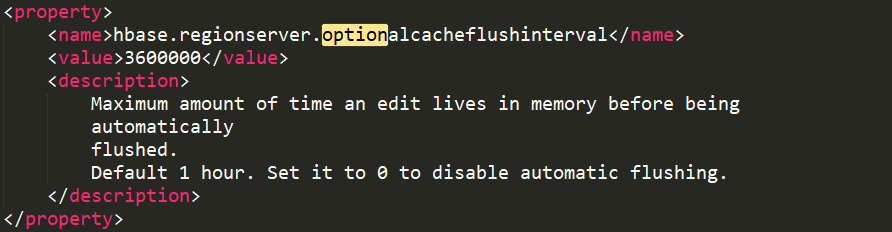
内存中的编辑文件在自动刷新之前能够存活的最长时间,默认是1h。计时是从最后一次编辑时开始的。
4、依据WAL文件数量刷写
WAL(Write-ahead log,预写日志)用来解决宕机之后的操作恢复问题的。数据到达 Region 的时候是先写入WAL,然后再被写到Memstore的。如果WAL的数量越来越大,这就意味着 MemStore 中未持久化到磁盘的数据越来越多。当RegionServer挂掉的时候,恢复时间将会变长,所以有必要在 WAL到达一定的数量时进行一次刷写操作。最开始,wal的数量的阈值是由hbase.regionserver.max.logs这个属性决定的,但是现在这个是属性被废弃了,已经无需手动设置了,最大值默认是32,wal文件数量超过这个值就会进行刷写操作。