R包ropls的偏最小二乘判别分析(PLS-DA)和正交偏最小二乘判别分析(OPLS-DA)
 R包ropls的PCA、PLS-DA和OPLS-DA
R包ropls的PCA、PLS-DA和OPLS-DA 在代谢组学分析中经常可以见到主成分分析(PCA)、偏最小二乘判别分析(partial least-squares discrimination analysis,PLS-DA)、正交偏最小二乘判别分析(orthogonal partial least-squares discrimination analysis,OPLS-DA)等分析方法,目的为区分样本差异,或在海量数据中挖掘潜在标志物。PCA是最常见的基于特征分解的降维方法,关于它的相关概念可参考PCA概述。PCA是一种无监督的模式,属于探索性分析。与PCA不同的是,PLS-DA和OPLS-DA则是有监督的模式,属于模型的方法。它们使用偏最小二乘回归建立代谢物表达量与样本类别之间的关系模型,对数据降维,这种监督模式通常可以更好地确立样本关系,如下图所示这样,无监督的PCA无法很好地区分组间样本时,而PLS-DA则实现有效分离。除了降维数据外,PLS-DA和OPLS-DA还可实现对样品类别的预测(即用于分类),通过构建分类预测模型,可进一步用于识别更多的样本所属,这是探索性的PCA方法无法做到的。
在代谢组学分析中经常可以见到主成分分析(PCA)、偏最小二乘判别分析(partial least-squares discrimination analysis,PLS-DA)、正交偏最小二乘判别分析(orthogonal partial least-squares discrimination analysis,OPLS-DA)等分析方法,目的为区分样本差异,或在海量数据中挖掘潜在标志物。PCA是最常见的基于特征分解的降维方法,关于它的相关概念可参考PCA概述。PCA是一种无监督的模式,属于探索性分析。与PCA不同的是,PLS-DA和OPLS-DA则是有监督的模式,属于模型的方法。它们使用偏最小二乘回归建立代谢物表达量与样本类别之间的关系模型,对数据降维,这种监督模式通常可以更好地确立样本关系,如下图所示这样,无监督的PCA无法很好地区分组间样本时,而PLS-DA则实现有效分离。除了降维数据外,PLS-DA和OPLS-DA还可实现对样品类别的预测(即用于分类),通过构建分类预测模型,可进一步用于识别更多的样本所属,这是探索性的PCA方法无法做到的。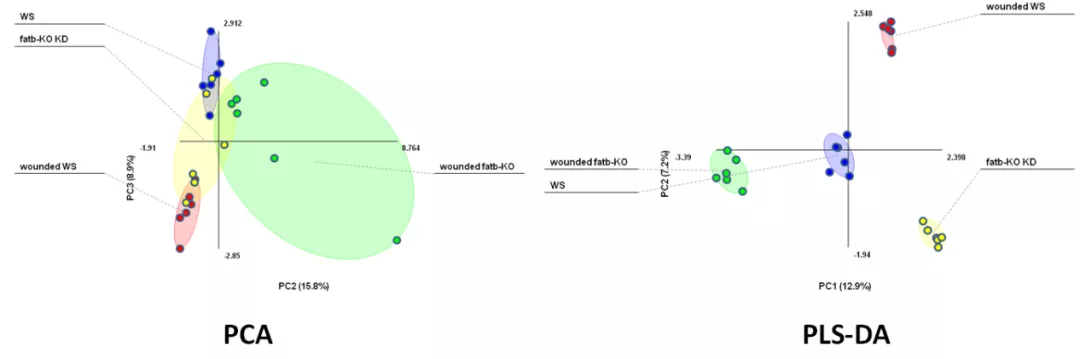
PLS-DA和OPLS-DA中涉及到两个矩阵:X矩阵为样本-变量观测矩阵,Y矩阵为样本类别归属矩阵。通过X和Y矩阵进行建模,即通过样本-变量关系确立样本关系。

两种方法相比,偏最小二乘(PLS)是一种基于预测变量和响应变量之间协方差的潜在变量回归方法,已被证明可以有效地处理具有多共线性预测变量的数据集。正交偏最小二乘(OPLS)则分别对与响应相关且正交的预测变量的变化进行建模。将它们与判别分析结合,即分别为PLS-DA和OPLS-DA。
本篇简介R包ropls的PLS-DA和OPLS-DA方法。
数据集
液相色谱高分辨质谱法(LTQ Orbitrap)分析了来自183位成人的尿液样品,共计109种代谢物能够注释到MSI level 1或2水平。
#Bioconductor安装ropls
BiocManager::install('ropls')
#加载
library(ropls)
#数据集,详情?sacurine
data(sacurine)
head(sacurine$dataMatrix[,1:6])
head(sacurine$sampleMetadata)
head(sacurine$variableMetadata)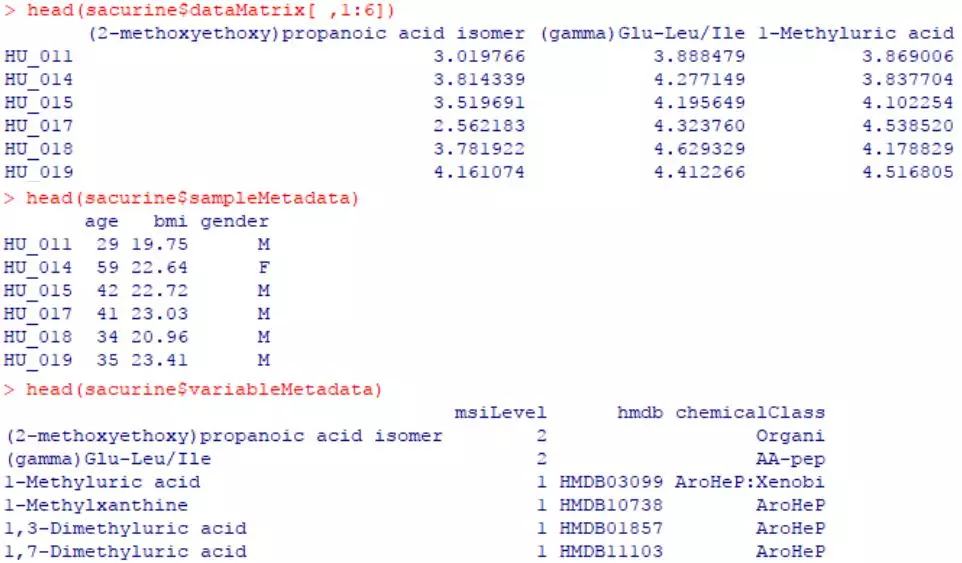
dataMatrix为样本-代谢物含量矩阵,记录了各种类型的代谢物在各样本中的含量信息,根据质谱中代谢物的峰值强度等换算得到。共计183个样本(行)以及109种代谢物(变量,列)。
sampleMetadata中记录了183个样本所来源个体的年零、体重、性别等信息。
variableMetadata为109种代谢物的注释详情,MSI level水平。
接下来期望根据各样本中代谢物组成的不同,评估样本间整体的差异,预测样本的来源个体属性(如性别),以及鉴定重要的代谢物等。
ropls包的PCA
首先可执行PCA探索各样本间代谢物组成的差异。
#PCA,详情?opls sacurine.pca<-opls(x=sacurine$dataMatrix) sacurine.pca
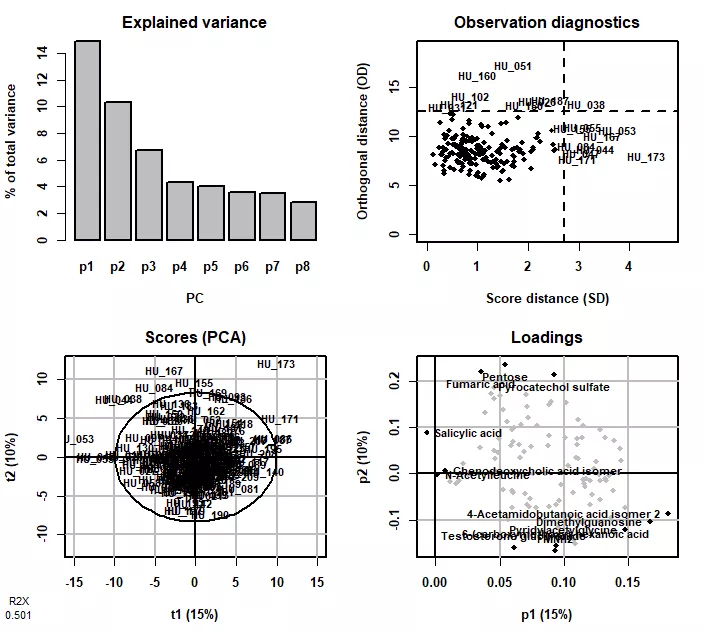
左上图展示了各PCA轴的特征值,显示前2-3轴承载了较多的方差,可通过绘制前2-3轴的排序图观测样本差异。
右上方图展示了各样本在投影平面内以及正交投影面的距离,具有高值的样本标注出名称,表明它们与其它样本间的差异较大。
左下图为PCA前两轴中的样本得分,即各样本在PC1和PC2轴中的排序坐标,可据此评估各样本在代谢物组成上的差异。
右下图为PCA前两轴中的变量得分,即各代谢物变量在PC1和PC2轴中的排序坐标,边缘处的变量表示它们在各样本中的含量差别明显(如在某些样本中具有较大/较小的极端值等),即对排序空间的贡献较大,暗示它们可能为一些重要的代谢物。
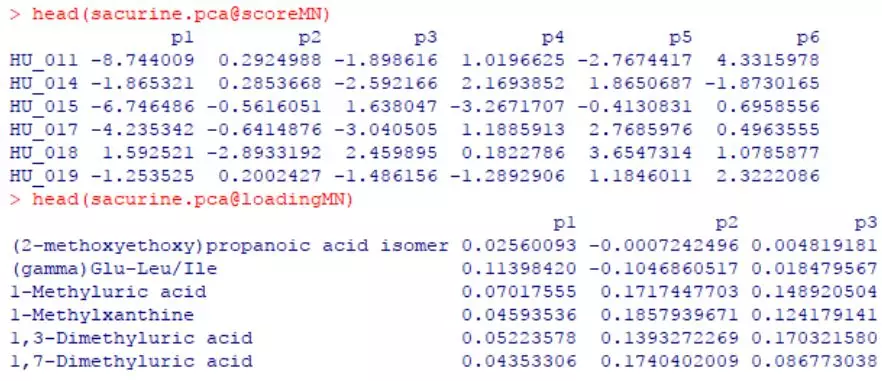
#opls()返回结果是S4对象结构,可通过@在其中提取所需结果 names(attributes(sacurine.pca))#查看包含信息 head(sacurine.pca@scoreMN)#例如,提取对象得分(各样本在PCA轴中的排序坐标) head(sacurine.pca@loadingMN)#例如,提取变量得分(各代谢物在PCA轴中的排序坐标)
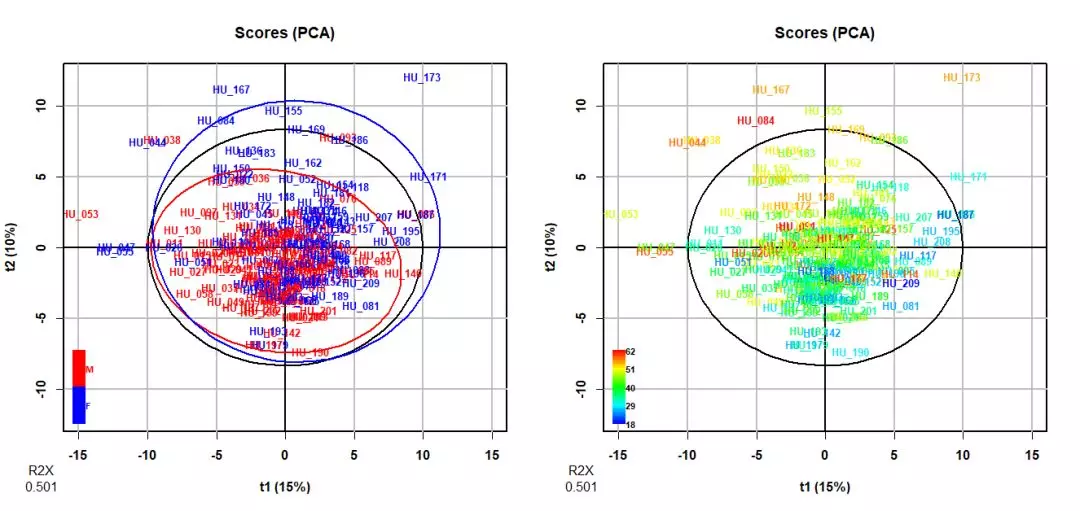
#如在排序图中根据个体属性(性别、年龄等)给样本上色 par(mfrow=c(1,2)) plot(sacurine.pca,typeVc='x-score',parAsColFcVn=sacurine$sampleMetadata[,'gender']) plot(sacurine.pca,typeVc='x-score',parAsColFcVn=sacurine$sampleMetadata[,'age']) #也可根据提取坐标自定义作图展示,如ggplot2 #展示前两轴的样本分布,并按个体性别着色 library(ggplot2) scoreMN<-sacurine.pca@scoreMN scoreMN<-cbind(scoreMN,sacurine$sampleMetadata) scoreMN$samples<-rownames(scoreMN) ggplot(scoreMN,aes(p1,p2,color=gender))+ geom_point()+ stat_ellipse(show.legend=FALSE)
ropls包的PLS-DA
对于本文的示例,尽管通过代谢物含量的PCA能够帮助我们识别一些重要的代谢物,以及探索样本差异,但在评估组间区别则似乎有些欠佳:例如不同性别或年龄人群的代谢物差异在PCA图中比较难以区分。
现在我们更换为带监督的PLS-DA,查看代谢物对个体性别的定性响应。
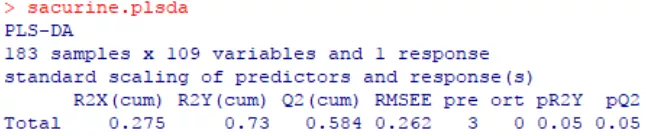
#PLS-DA,详情?opls #监督分组以性别为例,orthoI=0时执行PLS-DA sacurine.plsda<-opls(x=sacurine$dataMatrix,y=sacurine$sampleMetadata[,'gender'],orthoI=0) sacurine.plsda
这一步直接将全部数据集输入构建预测模型,即将所有数据均作为训练集使用。如果最终目的不是建模预测更多未知归属的数据,而是只为识别给定数据集的特征,那么这样是完全可以的。
结果中,R2X和R2Y分别表示所建模型对X和Y矩阵的解释率,Q2标示模型的预测能力,它们的值越接近于1表明模型的拟合度越好,训练集的样本越能够被准确划分到其原始归属中。
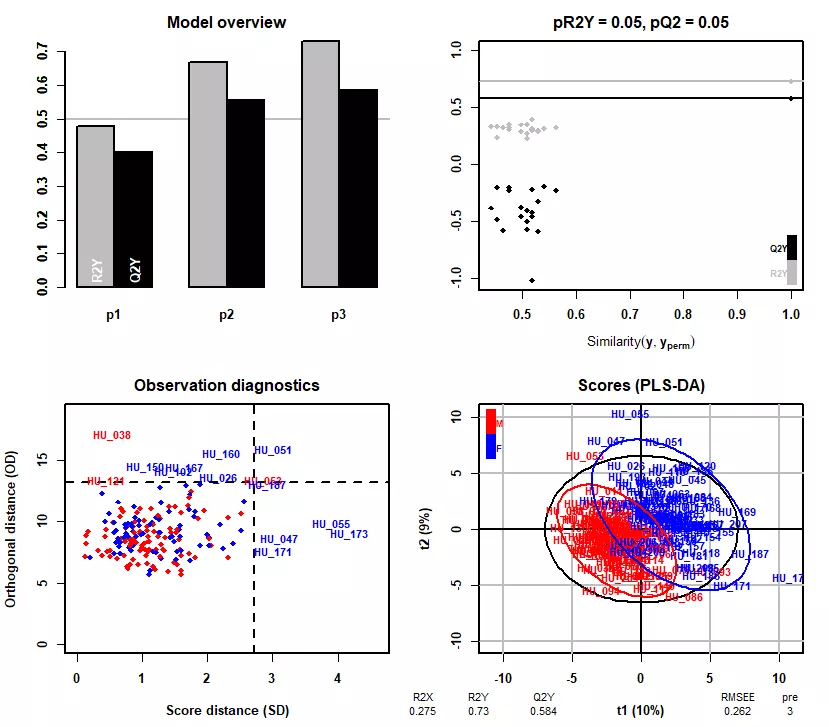
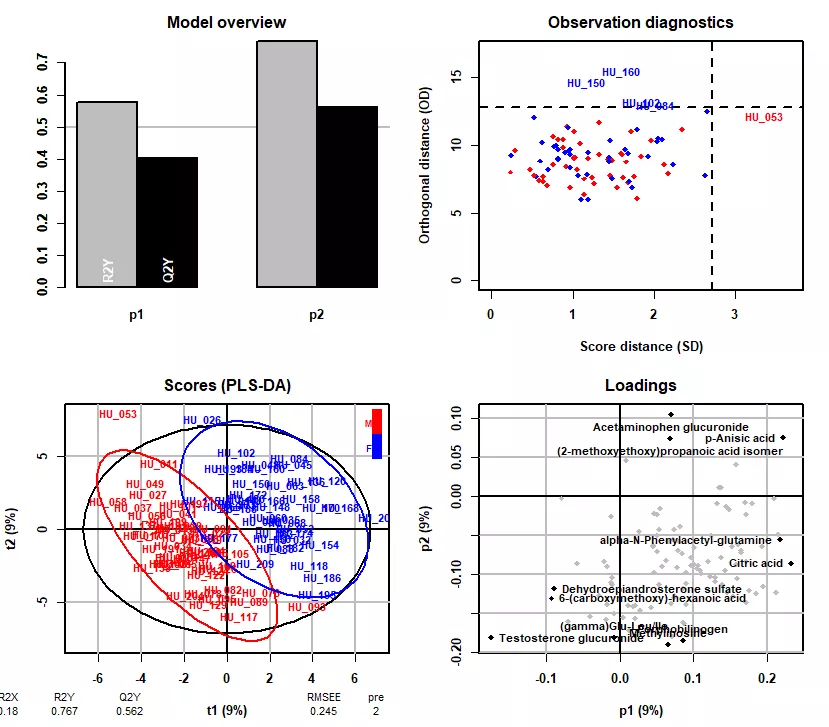
性别监督的PLS-DA模型。
左上图,展示了3个正交轴的R2Y和Q2Y。
由上图,PLS-DA模型的R2Y和Q2Y与随机置换数据后获得的相应值进行比较。
左下图,展示了各样本在投影平面内以及正交投影面的距离,具有高值的样本标注出名称,表明它们与其它样本间的差异较大。颜色代表性别分组。
右下图,各样本在PLS-DA轴中的坐标,颜色代表性别分组。我们可以看到,相对于上文的PCA(仅通过方差特征值分解),PLS-DA在区分组间差异时更有效(带监督的偏最小二乘判别分析)。图的下方还提供了R2X、R2Y等值,用于评估模型优度。
对于需要的结果提取和可视化。
#opls()返回对象的提取方法和上文PCA一致 names(attributes(sacurine.plsda))#查看包含信息 head(sacurine.plsda@scoreMN)#例如,样本在PLS-DA轴上的位置 head(sacurine.plsda@loadingMN)#例如,代谢物在PLS-DA轴上的位置 #默认plot()作图,如查看样本差异以及帮助寻找重要的代谢物 par(mfrow=c(1,2)) plot(sacurine.plsda,typeVc='x-score',parAsColFcVn=sacurine$sampleMetadata[,'gender']) plot(sacurine.plsda,typeVc='x-loading') #其它可视化方法,提取坐标后自定义作图(如ggplot2等),不再多说
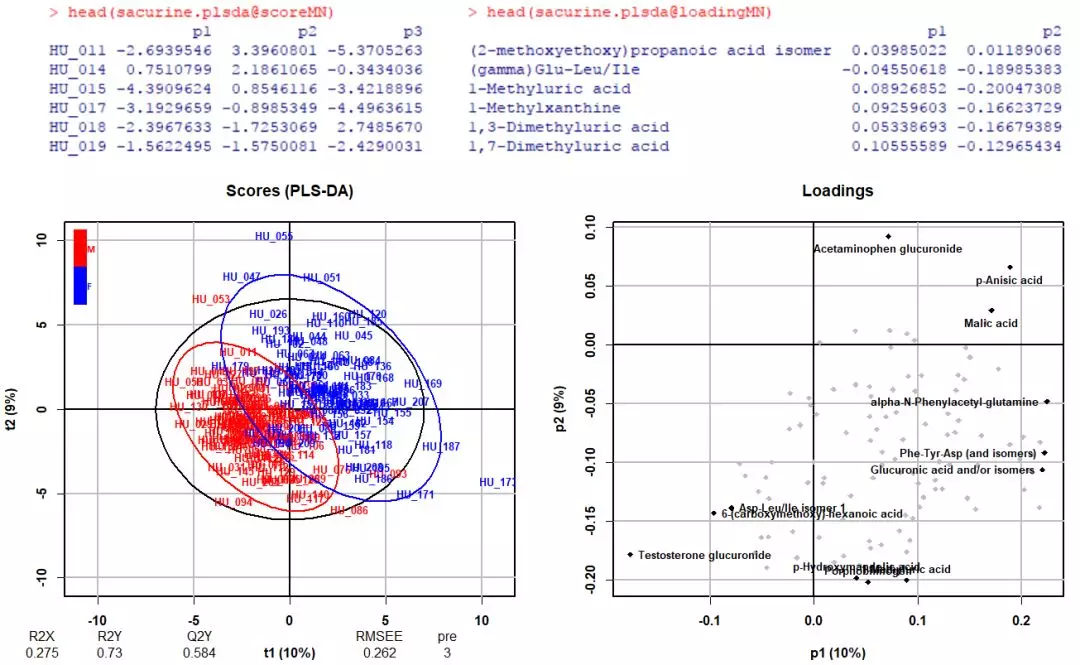
类似上文的PCA,上图右图中指示了一些重要的代谢物变量,根据它们的拟合度贡献推断。
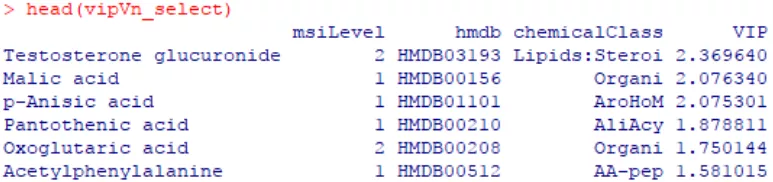
此外,还可通过变量投影重要度(Variable Importance for the Projection,VIP)衡量各代谢物组分含量对样本分类判别的影响强度和解释能力,辅助标志代谢物的筛选。通常以VIP值>1作为筛选标准。
#VIP值帮助寻找重要的代谢物 vipVn<-getVipVn(sacurine.plsda) vipVn_select<-vipVn[vipVn>1]#这里也通过VIP>1筛选下 head(vipVn_select) vipVn_select<-cbind(sacurine$variableMetadata[names(vipVn_select),],vipVn_select) names(vipVn_select)[4]<-'VIP' vipVn_select<-vipVn_select[order(vipVn_select$VIP,decreasing=TRUE),] head(vipVn_select)#带注释的代谢物,VIP>1筛选后,并按VIP降序排序
如上所述,建模的另一目的为预测更多未知归属的数据。
如上过程直接使用所有数据构建了预测模型,目的仅为识别已知数据集的分类特征以及鉴定重要的代谢物,模型自身的拟合优度通过R2X、R2Y、Q等值评估。当然作为扩展,如果存在更多的其它样本,则也可以使用构建好的模型进一步预测它们的分类(这里为根据代谢物组成判断样本来源个体的性别),测试模型性能以及确定更多样本的归属。
由于没有更多样本了,因此接下来为了演示这种预测功能,将原数据集分为两部分,一部分数据运行PLS-DA构建模型,并通过另一部分数据测试拟合模型。
#带模型预测性能评估的执行命令 #如下示例,奇数行的数据用于构建PLS-DA,偶数行的数据测试PLS-DA #此外还可以自定义截取数据子集构建训练集或测试集等 sacurine.plsda<-opls(x=sacurine$dataMatrix,y=sacurine$sampleMetadata[,'gender'],orthoI=0,subset='odd') sacurine.plsda
#检查关于训练子集的预测 trainVi<-getSubsetVi(sacurine.plsda) table(sacurine$sampleMetadata[,'gender'][trainVi],fitted(sacurine.plsda)) #计算测试子集的性能 table(sacurine$sampleMetadata[,'gender'][-trainVi],predict(sacurine.plsda,sacurine$dataMatrix[-trainVi,]))
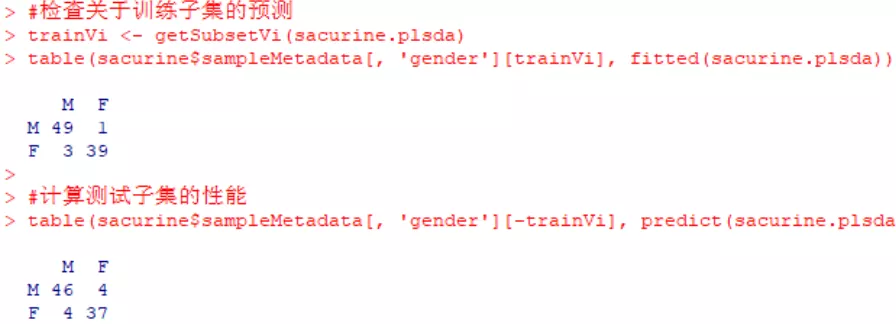
在这个示例中,使用了一半的数据用于构建PLS-DA,作为预测模型区分样本分组;另一半数据使用构建好的PLS-DA作测试。结果显示,构建好的预测模型能够很好地通过训练集样本的代谢物含量信息,对样本归类;使用该预测模型拟合测试集,也能实现较好的分类。
ropls包的OPLS-DA
但是PLS-DA容易出现过拟合(overfitting)问题。所谓过拟合,即通过训练集建立了一个预测模型,它在训练集上表现出色,但通过测试集测试时却表现不佳。过拟合是机器学习中的一个常见问题,主要出现在具有比样本数量更多的变量数量的数据集的分析中。
相较于PLS-DA,OPLS-DA可以更好地避免过拟合现象,但与PLS-DA相比通常没有预测性能优势的提升。如果PLS-DA模型尚可,仍推荐PLS-DA。
尽管本文的示例数据没有出现过拟合现象,但不影响继续展示OPLS-DA方法。我们再通过OPLS-DA查看代谢物对个体性别的定性响应,仍然直接使用所有数据作为输入。
#OPLS-DA,详情?opls #监督分组以性别为例,orthoI=NA时执行OPLS-DA sacurine.oplsda<-opls(x=sacurine$dataMatrix,y=sacurine$sampleMetadata[,'gender'],predI=1,orthoI=NA) sacurine.oplsda
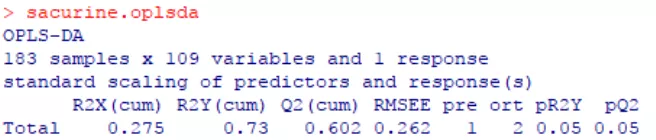
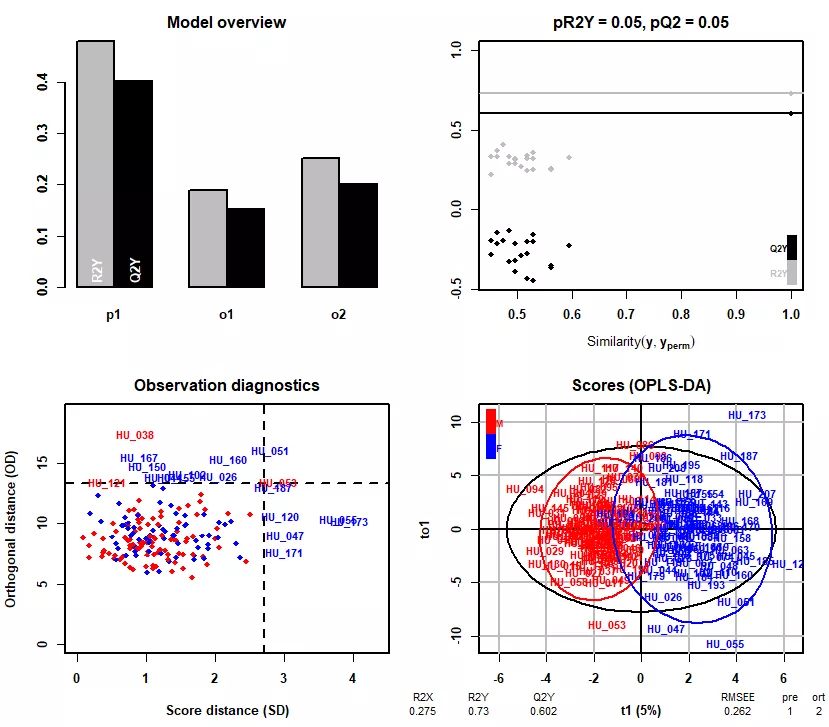
性别监督的OPLS-DA模型。
左上、右上、左下图的含义参考上文PLS-DA。
右下图,横坐标为预测组分,纵坐标为正交组分。并在下方展示了用于评估模型优度的统计量。
其它内容,如数据提取、可视化、重要变量评估、模型性能测试等,参考上文PLS-DA。
参考资料
https://www.bioconductor.org/packages/devel/bioc/vignettes/ropls/inst/doc/ropls-vignette.html#partial-least-squares-pls-and-pls-da
https://cn.bing.com/search?q=PLSDA%20OPLSDA&qs=n&form=QBRE&sp=-1&pq=plsda%20oplsda&sc=2-12&sk=&cvid=7BEA53B98EE647C7A3E8CEBE30A6CAB8