什么是Prometheus?
Prometheus是由SoundCloud开源的监控系统,是Google BorgMon监控系统的开源版本。伴随着容器及Kubernetes技术的兴起,Prometheus越来越受到大家的关注。
无论是传统数据中心还是云数据中心,无论是物理机,虚拟机还是容器,整个数据中心的建设都绕不开监控这个话题。优秀的监控系统不仅需要兼容各种设备和环境,还需要具备高性能,高可靠及易运维等特性,Prometheus正是其中之一。伴随着容器相关技术的兴起,Prometheus正逐步成为容器监控的标准,并且对于传统应用和设备也有良好的兼容性。
Prometheus有GO语言编写而成,采用Pull方式获取监控信息,并提供了多维度的数据模型和灵活的查询接口。Prometheus不仅可以通过静态文件配置监控对象,还支持自动发现机制,能够通过Kubernetes,Consul,DNS等多种方式动态获取监控对象。在数据采集方面,借助Go语言的高并发特性,单机Prometheus可以采集数百个节点的监控数据;在数据存储方面,随着本地时序数据库的不断优化,单机Prometheus每秒可以采集一千万个指标,如果需要存储大量的历史监控数据,则还支持远端存储。
Prometheus生态系统组件架构:
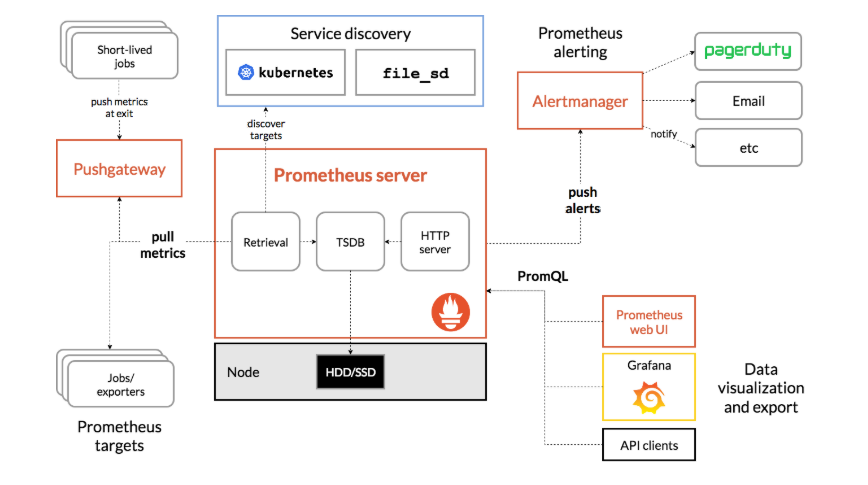
Prometheus Server负责定时在目标上抓取Metrics数据,每个抓取目标都需要暴露一个HTTP服务接口用于Prometheus定时抓取。这种调用被监控对象获取监控数据的方式被称为Pull。Pull方式体现了Prometheus独特的设计哲学与大多数采用了Push方式的监控系统不同。
但某些现有系统是通过push方式实现的,为了接入这个系统,Prometheus提供对PushGateway的支持,这些系统主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
AlertManager是独立于Prometheus的一个组件,在触发了预先设置在Prometheus中的高级规则后,Prometheus便会推送告警信息到AlertManager。
Prometheus支持两种存储方式:
- 一种是本地存储。通过Prometheus自带的时序数据库将数据保存到本地磁盘,为了性能考虑,建议使用SSD。但本地存储的容量毕竟有限,建议不要保存超过一个月的数据。
- 另一种是远程存储,适用于存储大量监控数据。通过中间层的适配器的转化,目前Prometheus支持OpenTSDB、InfluxDB、Elasticsearch等后端存储,通过适配器实现Prometheus存储的remote write和remote read接口,便可以接入Prometheus作为远端存储使用。
Prometheus的优势:
- 由监控名称和键/值对标签标识的时间序列数据组成的多维数据模型
- 强大的查询语言PromQL
- 不依赖分布式存储;单个服务节点具有自治能力
- 时间序列数据是服务端通过HTTP协议主动拉取获得的
- 也可以通过中间网关来推送时间序列数据
- 可以通过静态配置文件或服务发现来获取监控目标
- 支持多种类型的图表和仪表盘
Prometheus监控目标:
- 长期趋势分析:通过对监控样本数据的持续收集和统计,对监控指标进行长期趋势分析。例如,通过对磁盘空间增长率的判断,我们可以提前预测在未来什么时间节点上需要对资源进行扩容。
- 对照分析:两个版本的系统运行资源使用情况的差异如何?在不同容量情况下系统的并发和负载变化如何?通过监控能够方便的对系统进行跟踪和比较。
- 告警:当系统出现或者即将出现故障时,监控系统需要迅速反应并通知管理员,从而能够对问题进行快速的处理或者提前预防问题的发生,避免出现对业务的影响。
- 故障分析与定位:当问题发生后,需要对问题进行调查和处理。通过对不同监控以及历史数据的分析,能够找到并解决根源问题。
- 数据可视化:通过可视化仪表盘能够直接获取系统的运行状态、资源使用情况、以及服务运行状态等直观的信息。
指标摘要:
通常来说,单个指标对我们价值很小,往往需要联合并可视化多个指标,这其中需要应用一些数学转换。
- 计数(count):计算特定时间间隔的观察点数。
- 求和(sum):将特定时间间隔内所有观察点的值累计相加
- 平均值(avg):提供特定时间间隔内所有值的平均值
- 中间数:数值的几何中点,正好50%的数值位于他前面,而另外50%则位于它后面
- 百分位数:度量占总数特定百分比的观察点的值
- 标准差(stddev):显示指标分布中与平均值的标准差,这可以策略出数据集的差异程度。标准差为0表示数据都等于平均值,较高的标准差意味着数据分布的范围很广。