---恢复内容开始---
案例1:对主席的新年致辞进行分词,绘制出词云
掌握jieba分词的用法
1.加载包
library(devtools)
library(tm)
library(jiebaR)
library(jiebaRD)
library(tmcn)
library(NLP)
library(wordcloud2)2.导入数据
news <- readLines('E:\Udacity\Data Analysis High\R\R_Study\高级课程代码\数据集\第一天\2文本挖掘\xitalk2017.txt',encoding='UTF-8') head(news)

3.清洗数据
#去除新闻中的英文 gsub('[0-9,a-z,A-Z]','',news) ->news segword_tmp =worker() segword = segword_tmp <=news #加载停用词表 stopwords = readLines('E:\Udacity\Data Analysis High\R\R_Study\第一天数据\中文停用词表.txt',encoding='UTF-8') head(stopwords,10)
4.移除感叹词
removewords <-function(targetword,stopword){ targetword = targetword[targetword%in%stopword ==F] return(targetword) } segword2 <- sapply(X=segword, FUN =removewords,stopwords) head(segword2) segword2[[1]] length(unlist(segword)) length(unlist(segword2))
5.绘制词云
letterCloud(word_freq, word = 'R',color = 'random-dark',backgroundColor = "snow") wordcloud2(word_freq, size = 1,shape = 'circle')

案例2:通过拉勾网的数据进行分析,找出数据分析师相关的城市,薪水,工作年限等信息
数据集下载:链接:https://pan.baidu.com/s/1Bz7mA_dnvD1MGTVrZKyhPA 密码:layp
目的:掌握文本分析,数据报表结论展示
数据集字段说明:
字段 描述 用途 id 唯一标识 与数据库表主键功能类似,用于处理表关联 title 岗位名称 作为岗位的标识,与雇主和岗位描述组合成唯一标识 company 公司名称 作为雇主的标识 salary 平均月薪(k) 用于平均月薪的分析 city 工作所在城市 用于分析地域 scale 规模 用于区别企业的指标 phase 融资/发展阶段 用于区别企业的指标 experience 职位经验要求 分析工作经验的影响 education 学历要求 分析学历的影响 description 职位描述 用于文本挖掘,做岗位需求技能分析
1.加载数据集
library(readxl)
library(jiebaR)
library(jiebaRD)
library(zoo)
library(VIM)
library(plyr)
library(ggplot2)
library(wordcloud2)2.加载数据集
CN.df <- read_excel('E:\Udacity\Data Analysis High\R\R_Study\CN_lagou_jobdata.xlsx',1) CN.df <- CN.df[,c('title','salary','experience','education','campany','scale','scale2','description','phase','city')] str(CN.df)

3.查看是否有缺失值,以及常用函数的定义
#查看是否有缺失值 aggr(CN.df,prop=T,numbers=T) #返回分词频数表的排序 top.freq <- function(x,topn=0){ require(plyr) top.df <-count(x) top.df <- top.df[order(top.df$freq,decreasing =TRUE),] if(topn > 0) return(top.df[1:topn,]) else return(top.df) } #排序 reorder_size <- function(x,decreasing=T){ factor(x,levels = names(sort(table(x),decreasing=decreasing))) } #ggplot自定义主题 my.ggplot.theme <- function(...,bg='white'){ require('guid') theme_classic(...)+ theme(rect = element_rect(fill =bg), plot.title = element_text(hjust = 0.5), text = element_text(family = 'STHeiti'), panel.background = element_rect(fill='transparent', color='#333333'), axis.line = element_line(color='#333333',size = 0.25), legend.key = element_rect(fill='transparent',colour = 'transparent'), panel.border = element_rect(fill='transparent',colour = 'transparent'), panel.grid = element_line(colour = 'grey95'), panel.grid.major = element_line(colour = 'grey92',size = 0.25), panel.grid.minor = element_line(colour = 'grey92',size = 0.1)) } #多图展示 mutiplot <- function(...,plotlist=NULL,file,cols=1,layout=NULL){ library(grid) plots <-c(list(...),plotlist) numPlots <-length(plots) if(is.null(layout)){ layout <- matrix(seq(1,cols*ceiling(numPlots/cols)), ncol =cols, nrow = ceiling(numPlots/cols)) } if(numPlots == 1){ print(plot[[1]]) } else{ grid.newpage() pushViewport(viewport(layout =grid.layout(nrow(layout),ncol(layout)))) for(i in 1:numPlots){ matchidx <- as.data.frame(which(layout==i,arr.ind =T)) print(plots[[i]],vp=viewport(layout.pos.row = matchidx$row,layout.pos.col =matchidx$col)) } } }
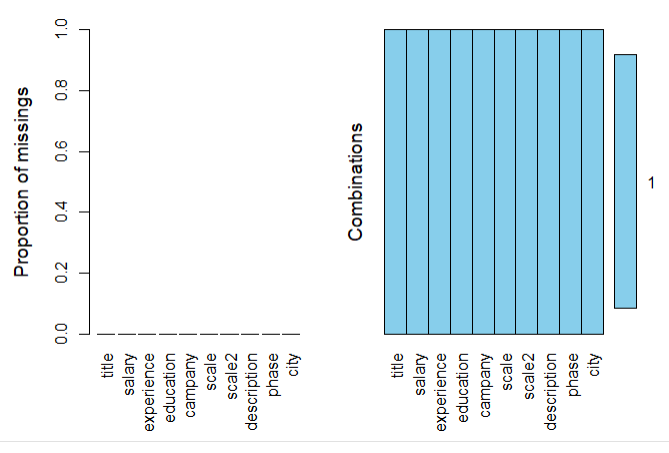
结论:没有缺失值
4.数据清洗整理
cleaning <-function(my.data){ #去掉重复值 my.data <- my.data[!duplicated(my.data[c('title','campany','description')]),] #计算平均月薪 max_sal <- as.numeric(sub('([0-9]*).*','\1',my.data$salary)) min_sal <- as.numeric(sub('.*-([0-9]*).*','\1',my.data$salary)) my.data$avg_sal <- (max_sal+min_sal)/2 #清理不需要的字符,将需要分析的字符转换成因子 my.data$city <- factor(gsub('[/]*','',my.data$city)) my.data$experience <- gsub('经验|[/ ]*','',my.data$experience) my.data$experience[my.data$experience %in% c('不限','应届毕业生')] <- '1年以下' my.data$experience<-factor(my.data$experience, levels = c('1年以下','1-3年','3-5年','5-10年','10年以上')) my.data$education <- gsub('学历|及以上|[/ ]*','',my.data$education) my.data$education[my.data$education == '不限'] <- '大专' my.data$education <-factor(my.data$education, levels = c('大专','本科','硕士')) my.data$phase <- factor(gsub('[ ]*','',my.data$phase), levels=c('不需要融资','未融资','天使轮','A轮','B轮','C轮','D轮及以上','上市公司')) my.data$campany <- gsub('[ | ]*','',my.data$campany) my.data$scale <- factor(gsub('.*(少于15人|15-50人|50-150人|150-500人|500-2000人|2000人以上).*', '\1',paste(my.data$scale,my.data$scale2)), levels =c("少于15人","15-50人","50-150人","150-500人","500-2000人","2000人以上")) my.data$id <-index(my.data) my.data <- droplevels(subset(my.data,select=-scale2)) return(my.data) } CN.clean <-cleaning(CN.df) str(CN.clean)

结论:转化成结构化数据
5.开始进行分词统计
#采用默认的jieba分词器 engine <- worker(user = 'E://Udacity//R//R-3.4.3//library//jiebaRD//dict//user.dict.utf8',encoding = 'UTF-8') #去除无关的词 word.lis <-lapply(CN.clean$description, function(x){ v <- gsub('[u4e00-u9fa5|0-9|\.|\-]','',segment(x,engine)) v <- v[v!=''] return(v) }) #所有的词语转化成大写,避免出现大小写的错误 segWord <-toupper(unlist(word.lis)) #加载stop词语列表 stopWords <- toupper(readLines('E://Udacity//R//R-3.4.3//library//jiebaRD//dict//stop_words.utf8',encoding = 'UTF-8')) #过滤分词 #此处确保我要得到的前15个关键技能是正确的数据分析技能 removewords <-function(targetword,stopword){ targetword = targetword[targetword%in%stopword ==F] return(targetword) } segword<- sapply(X=segWord, FUN =removewords,stopWords) word_freq <- top.freq(unlist(segword),15) #成有id和keyword构建的数据框 id <-NULL keyword <-NULL for(i inindex(word.lis)){ id <-c(id,rep(i,length(word.lis[[i]]))) keyword <-c(keyword,word.lis[[i]]) } keyword.df <- data.frame("id"=id,"keyword"=toupper(keyword)) keyword.df <- droplevels(keyword.df[keyword.df$keyword %in%word_freq$x,]) merge.df <- merge(CN.clean,keyword.df,by = 'id') summary(merge.df)

6.生成词云的常用词
#提取非技能型关键词
keys <- worker(type = "keywords", user = "E://Udacity//R//R-3.4.3//library//jiebaRD//dict//user.dict.utf8", topn = 20, encoding = 'UTF-8', stop_word = "E://Udacity//R//R-3.4.3//library//jiebaRD//dict//stop_words.utf8") keyword.lis <-lapply(CN.clean$description, function(x){ v <- gsub("[a-zA-Z|0-9|\.|\-]","",keywords(x,keys)) v <- v[v!=""] return(v) }) keyword.lis <-unlist(keyword.lis) #形成词频表 not.tool.keyword <-top.freq(keyword.lis) str(not.tool.keyword)

7.查看数据集
attach(CN.clean)
#观测数据清洗后的统计信息summary(CN.clean[c("city","phase","scale","education","experience","avg_sal")])

8.通过数据集回答问题
8.1不同地区的数据分析师岗位的薪资和需求的分布
#创建ggplot绘图对象 p.cn <- ggplot(CN.clean) +my.ggplot.theme() city.table <-data.frame(prop.table(table(reorder_size(city,T)))) names(city.table)[1] <- 'city' p1 <- ggplot(city.table,aes(x=city,y=Freq))+ my.ggplot.theme()+ geom_bar(fill='turquoise3',stat = 'identity')+ labs(x='城市',y='不同城市需求占总量的比率')+ scale_y_continuous(labels =scales::percent) group_diff <- diff(range(avg_sal))/20 p2 <- p.cn+geom_histogram(aes(x=avg_sal,y=..density..), binwidth = group_diff,fill='turquoise3',color='white')+ stat_density(geom = 'line',position = 'identity',aes(x=avg_sal),color='brown1')+ labs(x='月薪(K/月)') mutiplot(p1,p2,cols = 1)
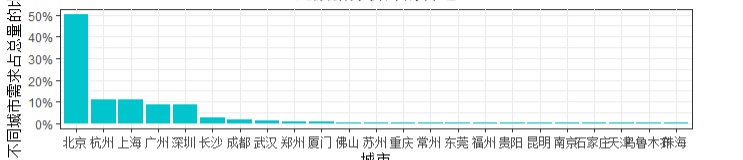
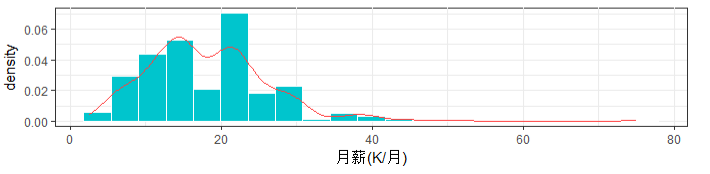
结论:1.北京,上海,杭州,深圳,广州”占据了近90%的需求量,是数据分析师的首选
2.数据分析师平均月薪为18.22k,月薪的分布主要集中在10k~25k之间,拿到10k以上薪资的机会比较大
CN.clean$type<-NA CN.clean$type[CN.clean$city %in% top.freq(city,5)$x] <- 'top5' CN.clean$type[is.na(CN.clean$type)] <- 'other' CN.clean$type <- factor(CN.clean$type,levels = c('top5','other')) p.cn+geom_boxplot(aes(x=city,y=avg_sal,fill=CN.clean$type))+ labs(x='城市',y='月薪(K/月)',fill='需求量排名')+ theme(axis.text.x=element_text(angle = 30,hjust = 1) )

结论:需求量最多的5个城市的平均薪资均处于全国较高的水平,苏州是一个特例,需求量少,薪资高
8.2 不同经验,数据分析岗位的需求分布以及对应的薪资分布
exp.table <-prop.table(table(experience)) exp.table <-as.data.frame(exp.table) p3 <- ggplot(exp.table,aes(x=experience,y=Freq))+ my.ggplot.theme()+ geom_bar(fill='turquoise3',stat = 'identity')+ labs(x='工作经验',y='不同工作经验需求占总量的比率')+ scale_y_continuous(labels =scales::percent) p4 <- p.cn + geom_boxplot(aes(x=experience,y=avg_sal),fill='turquoise3')+ labs(x='工作经验',y='平均月薪(K/月)') mutiplot(p3,p4,cols = 2)
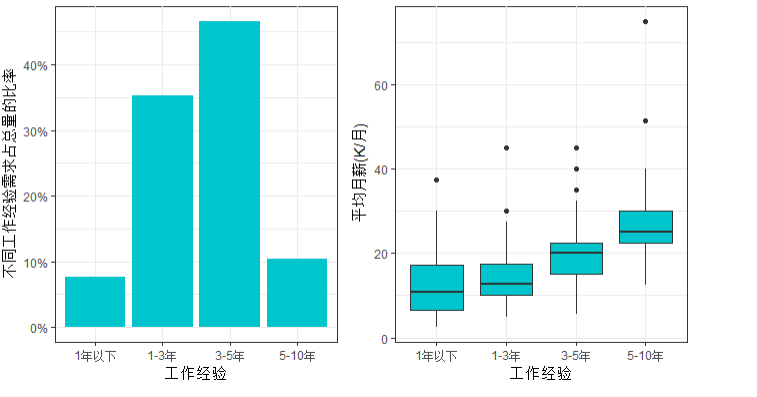
结论:1.企业需要更有经验的分析师,主要需求集中在1-3年和3-5年经验
2.随着工作经验的增加,数据分析师的月薪有非常可观的增长
8.3 不同学历,数据分析岗位的需求分布以及对应的薪资分布
edu.table <-prop.table(table(education)) edu.table <-as.data.frame(edu.table) p5 <- ggplot(edu.table,aes(x=education,y=Freq))+ my.ggplot.theme()+ geom_bar(fill='turquoise3',stat = 'identity')+ labs(x='学历',y='不同学历占总量的比率')+ scale_y_continuous(labels =scales::percent) p6 <- p.cn + geom_boxplot(aes(x=education,y=avg_sal),fill='turquoise3')+ labs(x='学历',y='平均月薪(K/月)') mutiplot(p5,p6,cols = 2)

结论:1.超过90%的岗位需要本科及以上的学历
2.学历随着工作经验的增长不是太明显
8.4 不同企业规模,数据分析岗位的各项需求分布及薪资分布
scale.table <-data.frame(prop.table(table(scale))) p7 <- ggplot(scale.table,aes(x=scale,y=Freq))+ my.ggplot.theme()+ geom_bar(fill='turquoise3',stat = 'identity')+ labs(x='企业规模',y='不同企业规模需求占总量的比率')+ theme(axis.text.x = element_text(angle = 30,hjust = 1))+ scale_y_continuous(labels =scales::percent) p8 <- p.cn + geom_boxplot(aes(x=scale,y=avg_sal),fill='turquoise3')+ labs(x='企业规模',y='平均月薪(K/月)')+ theme(axis.text.x = element_text(angle = 30,hjust = 1)) mutiplot(p7,p8,cols = 2)
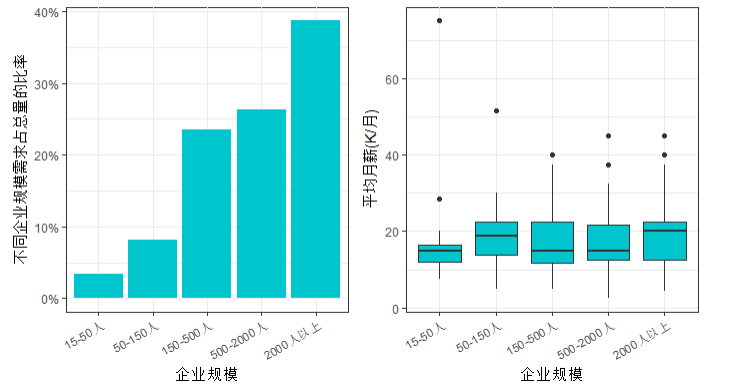
结论:1.企业规模越大越需要数据分析师的岗位
2.企业的规模越大,薪水越高
8.5企业规模与工作经验要求分析
sc.exp <- data.frame(prop.table(table(scale,experience),1)) ggplot(data=sc.exp,aes(x=scale,y=Freq,fill=experience))+ my.ggplot.theme()+ geom_bar(stat = 'identity')+ labs(x='企业规模',y='需求比例',fill='工作经验')+ geom_text(aes(label=paste(round(sc.exp$Freq,3)*100,'%',sep = '')), colour='white',position = position_stack(.5),vjust=00)+ scale_y_continuous(labels = scales::percent)
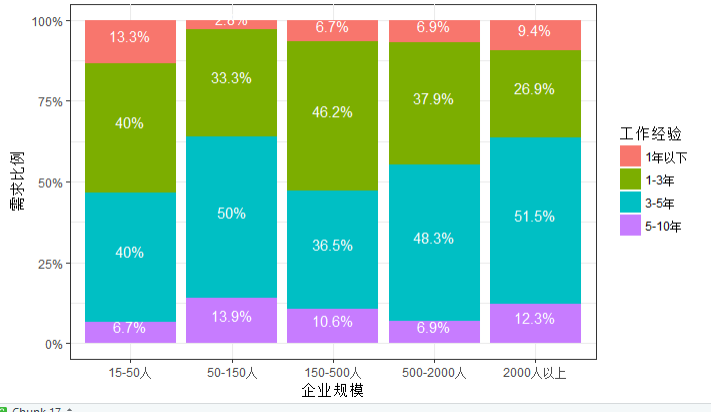
结论:综合来看50-150人的企业和2000人以上的企业对工作经验比较看重
8.6 数据分析岗位对工具型技能的需求
key.df <-data.frame(table(reorder_size(merge.df$keyword,TRUE))) key.df$Freq <- key.df$Freq/length(CN.clean$id) ggplot(key.df)+my.ggplot.theme() + geom_bar(aes(x=Var1,y=Freq),fill = "turquoise3",stat = "identity") + labs(x="工具型技能",y="不同技能需求占总岗位需求量的比率") + theme(axis.text.x = element_text(angle = 30,hjust = 1))+ geom_text(aes(x=Var1,y=Freq,label=paste(round(key.df$Freq,3)*100,'%',sep = '')),vjust=-0.2)+ scale_y_continuous(labels = scales::percent)
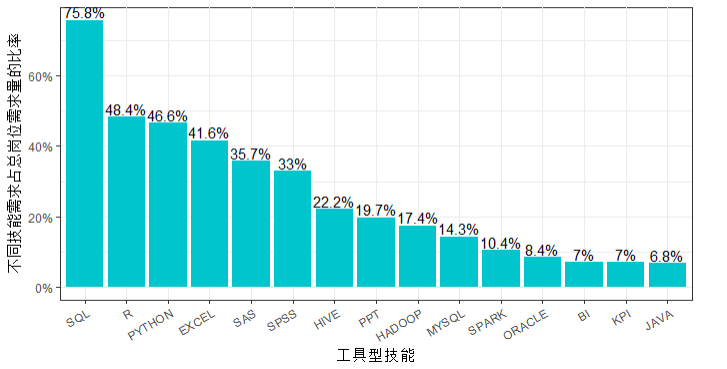
结论:SQL,R,Python,Excel是数据分析师的必备技能,超过78%的岗位都要求掌握SQL,SQL是数据分析师的必备技能,R语言的需求量居于第二
8.7 工具型技能与薪资的分析
merge.df$type <-NA merge.df$type[merge.df$keyword %in% top.freq(merge.df$keyword,5)$x] <- 'top5' merge.df$type[is.na(merge.df$type)] <- 'other' merge.df$type <- factor(merge.df$type,levels = c('top5','other')) ggplot(merge.df)+my.ggplot.theme()+ geom_boxplot(aes(x=keyword,y=avg_sal,fill=merge.df$type))+ labs(x ='工具型技能',y='平均月薪(K/月)',fill='需求量排名')+ theme(axis.text.x = element_text(angle = 30,hjust = 1))
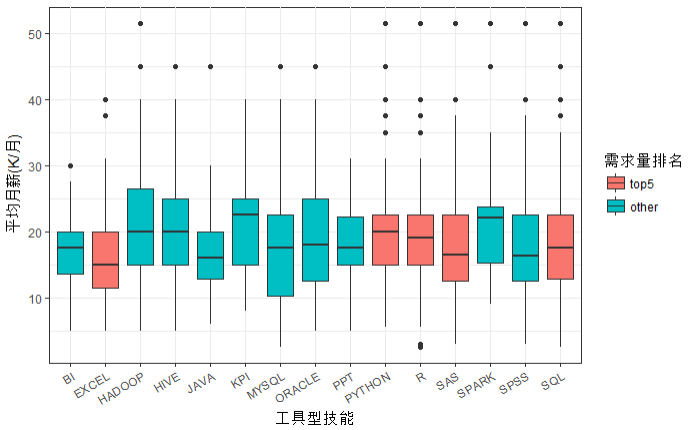
结论:收入最高的数据分析技能是HADOOP,HIVE,SPARK,R,PYTHON
8.8 绘制词云
wordcloud2(not.tool.keyword,size = 0.9,fontFamily = '微软雅黑')

结论:1.从地域上看北京,上海,深圳,广州,杭州市数据分析师的首选城市,苏州也是一个可选城市,但是需求量较低
2.从企业方来看,企业更需要具备工作经验,解决实际问题的人才,随着工作年限的增加,对应的薪资也有可观的增长
3.从大环境看,由于很多自动化分析软件的普及,使得现有的业务人员也可以快速的转行进行数据分析,所以对新手来说并不是很友好
4.50-150人的企业比较适合新人去锻炼增加经验值,此外越大的公司对数据分析人才的需求量越大
5.从分析师的角度来说则更需要注重项目的积累和新技术的掌握,相对于业务方向,数据挖掘会有更加可观的薪资
6.数据分析师需要掌握SQL,R,PYTHON,EXCEL四种必备工具,如果想转行大数据开发,则需要掌握HADOOP,HIVE,SPARK
7.数据分析师还需要注重逻辑思维、表达沟通、分析报告、报告书写等关键能力
数据集:https://github.com/Mounment/R-Project