今年年初这场突如其来的疫情,让我们早晨醒来打开手机的第一件事情,从刷朋友圈变成了刷每日最新的疫情数据。看看国内外新增确诊人数/现存确诊人数,看看国内外疫情分布的地图。各大新闻平台也因为快速上线疫情实时动态板块,成为了大家了解疫情发展的阵地。
其实,在这背后是有着一个海量数据分析的架构平台做支撑。
对于很多企业的管理人员而言,这就是个很熟悉的T+1计算T日的报表场景。管理人员通过报表查看前一天企业的经营情况、库存情况、用户新增/流失情况等,用数据提高决策的准确率,减少误判。
支撑这个典型报表场景的背后,是一整套海量数据计算的大数据架构。根据笔者这几年几十家各行各业企业的交流经验来看,大致都经历了如下几个阶段:
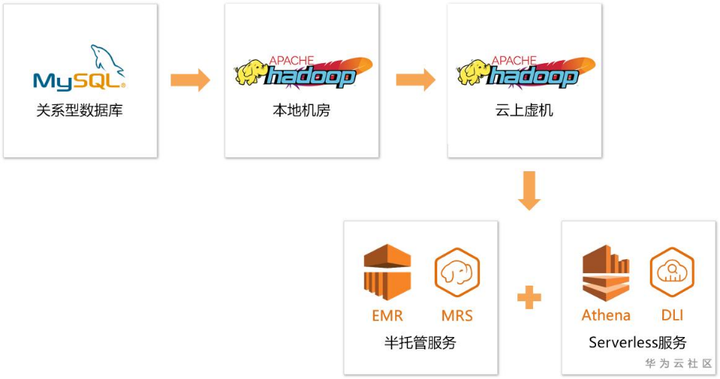
关系型数据库
最初,企业的技术人员通常都是在业务数据库相对空闲的时候(比如:晚上或者凌晨),直接在业务数据库备库进行一些数据分析查询。随着数据量的增多,一份逻辑上相同的数据,通常需要通过分库分表的方式分布在多个业务数据库中。快速分析全量数据且不影响在线业务变成了一件极其复杂的事情。
线下自建Hadoop集群
2004年,Google发布MapReduce论文。2006年,Apache Hadoop项目发布。一些技术走在比较前沿的互联网公司,开始使用Hadoop的分布式处理能力解决数据分析中常见的数据量激增、查询出不了结果等问题。
随后几年,越来越多的公司开始在线下机房搭建开源Hadoop集群,Hadoop生态相关的Kafka、Hive、Spark、Flink等都开始百花齐放,懂这些开源组件的技术人员在职场上也变得越来越吃香。
Hadoop架构最本质的优势就是高扩展性,理论上,解决好节点间的通信、引入多管理节点,就能根据数据量无限扩展集群规模。集群规模跟需要参与计算的数据量(如:最近30天的数据)强相关,尤其像互联网APP,可能一把就火了,但火上半个月用户热情冷却,又下降到最初的业务量。线下机房采购服务器走流程,周期基本都是以月为单位,根本无法满足快速变化的业务场景。
云上自建Hadoop集群
当时,国外的亚马逊已经诞生了几年,国内的阿里也开始大刀阔斧进军公有云。技术团队开始考虑公有云上购买虚拟机部署Hadoop集群,云上虚拟机按需使用的特点很好地解决了Hadoop集群对于节点伸缩能力的诉求。
云上半托管大数据服务 & 云上Serverless大数据服务
云厂商也纷纷看到了企业对大数据分析的诉求,推出了云上半托管大数据服务(如:AWS、华为云的MRS等)。从单纯虚拟机的性能竞争演变成了大数据管理软件的易用性、大数据组件的性能等竞争。
云上半托管大数据服务对于用户来说,最核心的优势就是使得安装、升级、运维变得简单化、可视化。同时,因为组件都是开源 + 自研优化,所以在接口上和开源保持一致,减少了业务的改造成本。
但云上半托管大数据服务对于用户还是有一定的使用门槛(懂大数据运维和调优),而且需要长期持有一部分固定节点资源,存在一定的资源浪费。
注意到这些问题,AWS在2016年推出了基于Serverless架构的Athena服务。最初是主打使用标准SQL分析Amazon S3 中的数据。Athena没有服务器,无需管理任何基础设施,且只需为运行的查询付费。
华为云也在2017年推出了基于Serverless架构的数据湖探索DLI服务,完全兼容Apache Spark和Apache Flink生态,使用SQL就可轻松完成多个数据源的联合分析。
2019年2月,加州大学伯克利分校发表了这篇名为《Cloud Programming Simplified: A Berkerley View on Serverless Computing》的论文,论文中认为Serverless模式主要有三个特点:
- 弱化了储存和计算之间的联系。服务的储存和计算被分开部署和收费,服务的储存不再是它本身的一部分,而是演变成了独立的云服务,这使得计算变得无状态化,更容易调度和缩扩容,同时也降低了数据丢失的风险。
- 代码的执行不再需要手动分配资源。我们再也不需要为服务的运行指定需要的资源(比如使用几台机器、多大的带宽、多大的磁盘...),只需要提供一份代码,剩下的交由Serverless平台去处理就行了
- 按使用量计费。Serverless按照服务的使用量(调用次数、时长等)进行计费,而不是像传统的Serverless服务那样,按照使用的资源(ECS实例、VM的规格等)计费。
在很长一段时间内,云上半托管大数据服务和Serverless大数据服务一定是长期并存的状态。
有大数据技术团队的大企业通常会选择半托管服务,一是因为使用习惯和自由度更像是开源Hadoop集群,二是因为技术团队自身也希望在大数据技术上有积累以便不时之需。
大数据技能较弱,且对成本敏感的中小型企业会考虑Serverless服务,吸引他们的是Serverless大数据服务即开即用免运维 + 标准SQL能力,用JDBC连上Serverless服务,体验十分接近传统关系型数据库。
Serverless大数据服务的未来
Serverless大数据服务要真正被大众接受,对外需要做好宣传,对内需要练好内功。Serverless概念从2018年才开始真正火起来,很多用户一提到大数据,直观还是想到自建Hadoop集群或者云上半托管大数据服务。随着K8S容器和微服务被更多的用户接受和使用,Serverless大数据服务也在逐渐出现在技术人员选型的清单中。
内功修炼上,Serverless大数据服务必须要解决好“安全”、“弹性”、“智能”、“易用”四个核心问题
安全
大数据领域,无论是SQL中的UDF还是用户自己开发的应用程序,都存在会攻击其它租户的风险。当前想要解决这类安全问题的方法,不外乎沙箱隔离、安全容器隔离、物理隔离等这几个方法。每一个方法对架构和资源利用率的挑战都非常大。
弹性
Serverless大数据服务最初诞生的初衷就是让用户提交应用时,无需感知和指定具体的运行资源数。弹性分为两个方面:一是弹性的速度,二是弹性的预测。
弹性的速度取决于底层物理资源池的大小和扩容算法、资源预热的程度以及不同租户间的资源抢占机制。
弹性的预测可以从易到难分为几类:最简单的就是根据用户定时规则进行弹性,优点是及时弹性,缺点也显而易见用户需要对业务比较了解;其次就是如果是周期性任务,服务可以通过收集历史作业执行规律(作业数、资源利用率等),在下一次执行时根据历史规律进行弹性;更进一步,通常大数据的任务都是拆分成多个逻辑相同的Task,根据资源量进行多轮调度。第一轮运行的时候,可以收集到单个Task的运行时长、CPU利用率等,第二轮就可以根据单个Task的信息,跟弹性的速度做个平衡,获取最佳弹性策略。
智能
使用大数据组件,其实搭建、升级等都不算特别复杂的事情,真正复杂的是上百个参数的调优。Serverless大数据服务如果想要真正地吸引之前使用自建Hadoop集群的用户,核心就是解决用户最头疼的调优问题。Serverless大数据服务根据用户的业务及历史执行情况,智能对服务参数及数据组织进行调优。最典型的几个问题,比如:如何避免输出过多小文件、如何切分合适的Reduce个数、如何根据查询条件自动调整数据组织形式等。
易用
除了解决基本的部署、升级等运维相关的问题,真正做到免运维。在使用习惯上,相比云上半托管大数据服务,Serverless大数据服务一定会有一个适应过程,我们要做的就是让这个适应过程变得潜移默化。
- 基础功能页面的使用:如果跟微信一样,做好界面易用性设计和功能的取舍,这个学习过程会在潜移默化中完成。
- 运维相关页面的使用:一定要尽可能保持和开源一样或者类似的页面逻辑,比如:Spark UI。
- 作业操作脚本:包括作业的提交、作业的终止、状态的查询等,如果Serverless大数据服务是想搞定某个开源大数据框架的迁移场景,这一部分一定要全兼容开源习惯。
Serverless大数据服务有些是基于开源大数据框架深度优化,有些是纯自研大数据框架。在应用开发的接口定义上,不管是哪种方式,对于从开源组件入门大数据的用户来说,开源接口就是标准,保持和兼容开源接口是Serverless大数据服务的基础。
总结
Serverless大数据服务是一种面向未来的形态。随着逐个攻破当前存在的问题,它在大数据分析所占的比重一定会逐年增加。真正把大数据分析变成跟水和电一样随取随用,每个企业都能用得起的工具。
