1.1 梯度下降法的算法思路
算法目的:找到(损失)函数的最小值以及相应的参数值。从而找到最小的损失函数。
梯度下降法:通过模拟小球滚动的方法来得到函数的最小值点。
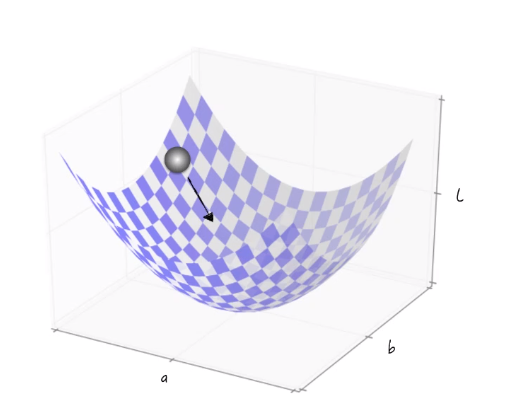
小球会根据函数形状找到一个下降方向不停的滚动,它的高度一直是下降的。随着时间的推移,小球会滚到底,从而找到最小值点。
但是梯度下降法不能保证到达最小值点,也有可能到达 鞍点 (这一点的梯度为0)或者 极小值点。
1.2 梯度下降法的数学细节(泰勒级数)
损失函数等于每一点的损失之和,就如之前所将的 线性回归 和 逻辑回归(交叉熵)。
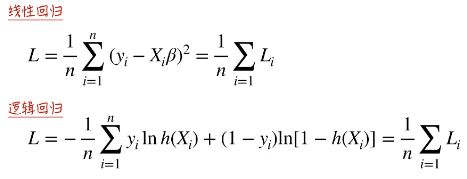
损失函数在模型训练的时候, Yi 和 Xi 都是给定的,所以损失函数是一个以 模型参数β 为变量的函数。我们要找的也是 模型参数β 的估计值。在此基础上,进一步假设损失函数对于模型参数都是可微的。在现实生活中,有的时候有的模型对于模型参数不是可微的。但是我们总可以通过一些数学上的近似方法,使其变成模型参数是可微的。这样才能在数学上比较好处理。
泰勒展开式描述了函数在某一点的值跟它附近的值之间的关系。具体来说,我们想计算函数在 β1 到 βn 的值。那么可以在附近找一点 a1 到 an ,所以 β1 到 βn 这一点的损失函数的值就约等于 a1 到 an 这一点的值再加上损失函数的梯度(一阶偏导)乘以两点之间的距离。
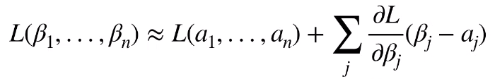
公式中的损失函数的梯度(一阶偏导)可以展开为 每一点的一阶偏导的和再乘 1/n 。
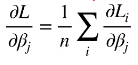
从这里可以看出计算量是很大的,至少要做 n 次加法才能得到这个值。所以后面才会引入 随机梯度下降法 来简化计算。
举一个具体的例子来推导梯度下降法。
假设一个线性回归模型,它的损失函数为

首先随机选取损失函数上的点作为起点(a0, b0),希望看(a0, b0)的附近,我们如何能找到一个点,这个点相对于(a0, b0)来说是它的函数值下降的。假设我们找到的点是(a1, b1),这两个函数值相减就是 ΔL 。如果我们希望(a1, b1)相对于(a0, b0)来说是它的函数值下降的。那么 ΔL 小于 0。
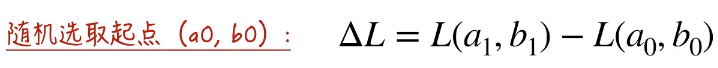
借助泰勒展开式,将右面移到左面可以得到 ΔL。
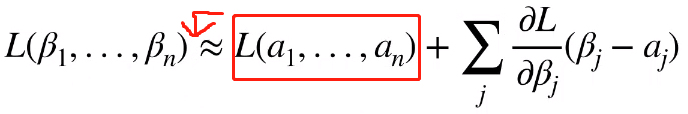
所以 ΔL 等于:
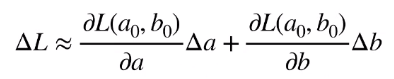
如果令:
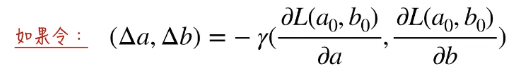
那么将 Δa 和 Δb 带回 ΔL:

所以,就可以定义 a , b 的迭代公式。
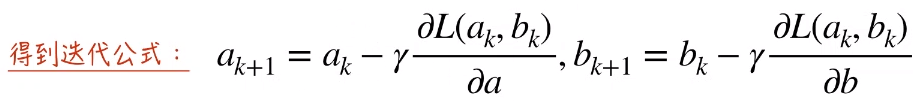
通过继续分析迭代公式,我们可以知道 γ 是学习速率,决定每次迭代参数值移动的步伐大小。它必定是大于0的值。否则就不满足 ΔL 小于 0。

为什么说它决定了移动的方向呢,如 1 点,它在一个递减函数上,所以按照迭代公式,γ 后面的一堆是小于 0 的。又由于 γ 大于0,所以 ak 减去负数,相当于加一个正数,所以 1点 下一步要向右移动。2 点同理。
而且在数学上可以证明,沿着梯度下降,是函数值下降最快的方向。
1.3 梯度下降法的注意事项
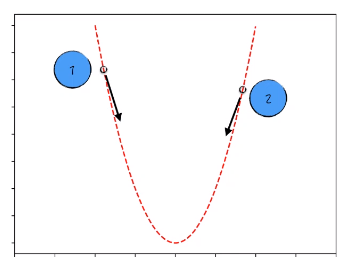
1.3.1 学习速率不能过大
依然如点1为例,如果学习速率过大(步长过大),那么它就会跨过最小值点到达2点。2点也会跨过最小值到3点。3点也会跨过最小值到4点。这样会遇到参数值左右摇摆,但就是不下降的情况。
从数学上来说,梯度下降法依赖的是 泰勒展开式,泰勒展开式 中的约等于是在函数的局部成立的。如果局部被扩的比较大,那么偏差也就比较大。所以学习速率不能过大,这样泰勒展开式的精度更高,梯度下降法效果更好。
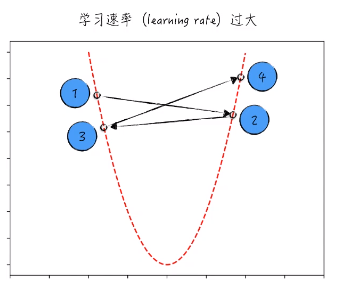
1.3.2 局部最优和全局最优
以 1点 为例,梯度下降法只能经过 点2 然后到达 点3。点3 的梯度是为0的。所以就停止了迭代。这样只能找到局部最优。
为了解决这个问题,我们可以选择 点4 为起点进行梯度下降法。
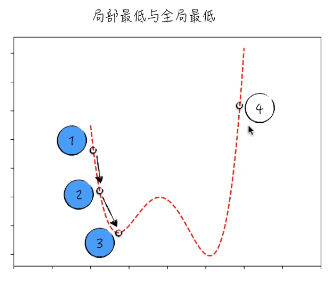
在实际运用中,如果我们使用梯度下降法,通常会随机选取若干起点,同时运用梯度下降法进行下降,每一个起点都会得到一个它认为的全局最低点。然后再比较这些 “全局最低点”,从中选出最低的点,那么这个点就作为最终的结果。
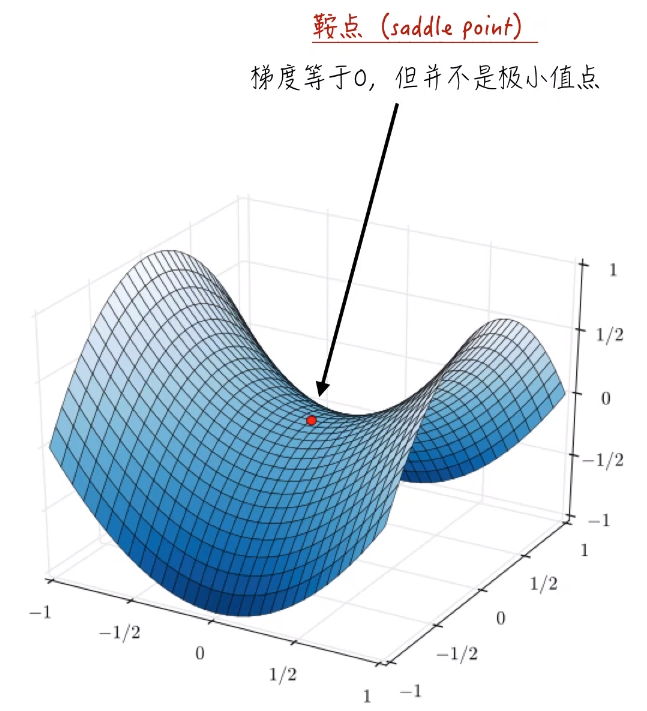
1.3.3 鞍点和山谷
鞍点和山谷是梯度下降法很怕遇到的。
鞍点:在这点的梯度等于0,但并不是极小值点。所以梯度下降法将会停止迭代。不会得到极小值点。
山谷:在一个狭长的区域内,梯度几乎等于0,但两边的梯度绝对值很大。下图深蓝色的一环就是这种情况。
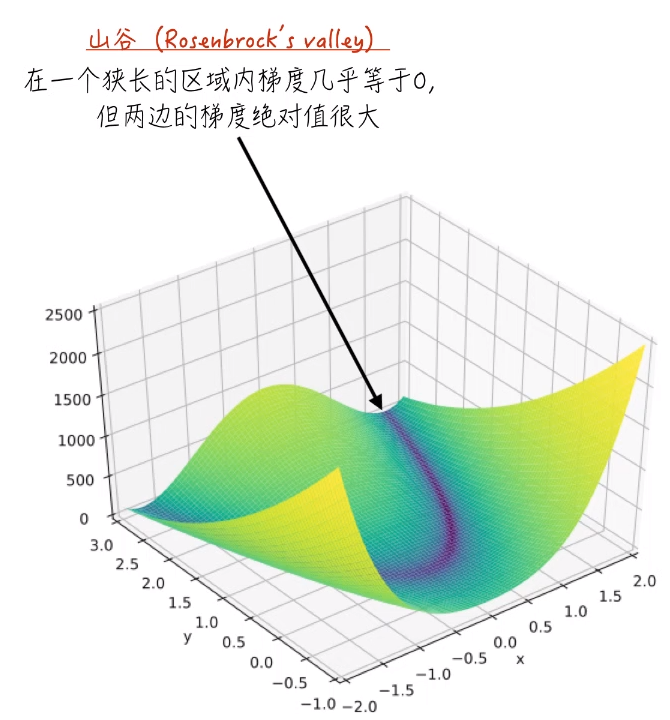
这两点到目前为止没有特别好的解决方法,但是后面会讲针对这种情况的优化改良算法。
2. 随机梯度下降法2.1 随机梯度下降法
正如 1.2 部分所说,梯度下降法面对大量的数据,速度会变得很慢。下面是梯度下降法的回顾。
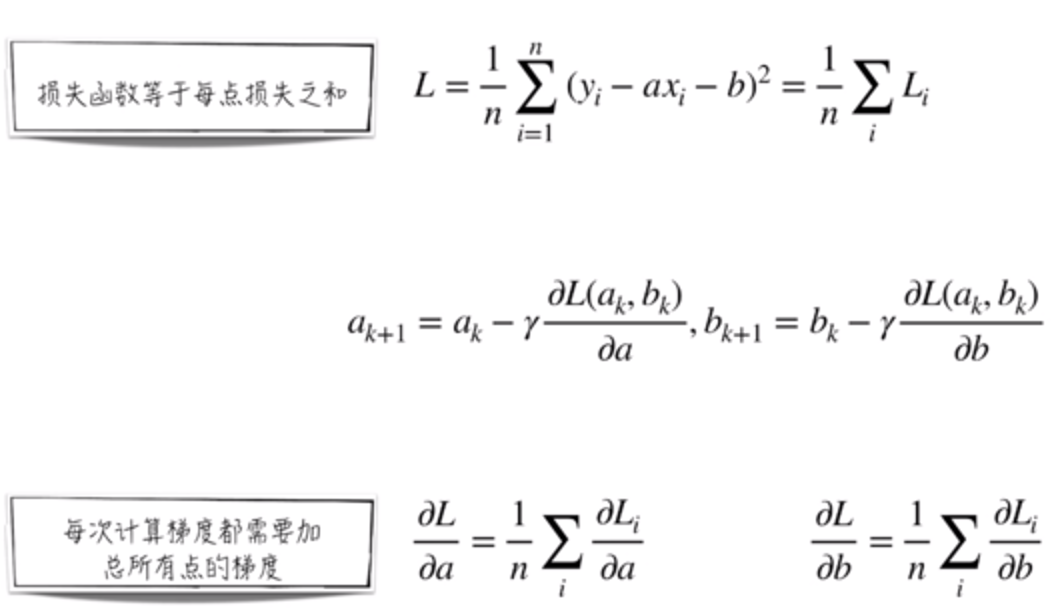
总结一下,由于损失函数的梯度等于各点梯度的平均值,这导致了:
1. 计算开销大。2. 面对大量的训练数据时,几乎不可用梯度下降法。
所以,现实生活中,一般都使用随机梯度下降法。为了提高效率,在随机梯度下降法中,使用小批量的数据的梯度平均值代替损失函数的梯度。
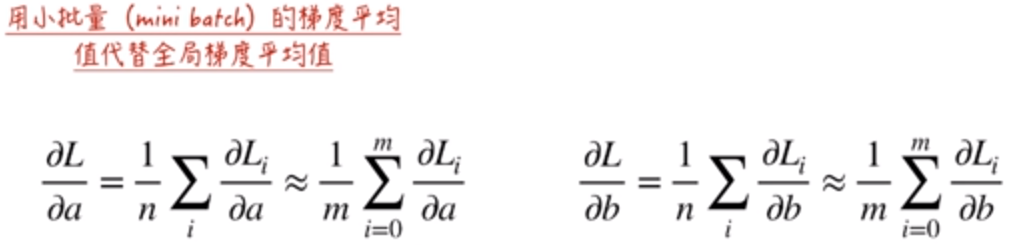
在这里和统计学的应用类似,比如说我们要统计所有中国人的平均年龄。由于中国人太多了,所以随机抽样100万人,然后求这100万人的平均年龄。这样近似代替中国人的平均年龄。虽然是有误差的,但是这个误差也是很小的,效率的提升是极大的。
所以根据这个思路,我们得到了随机梯度下降法的迭代公式:
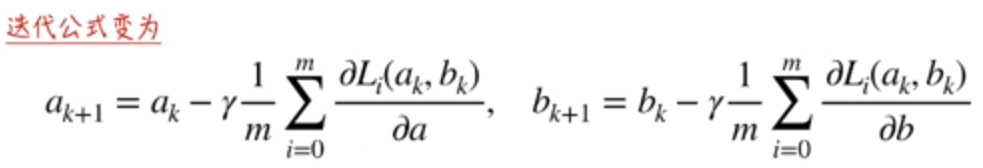
在实现随机梯度下降法时,会引入两个超参数。batch_size(公式中的 m ),epoch(所有数据循环的上限)。同时,需要注意的是,在极限的情况下,可以使用一个数据点的梯度代替损失函数的梯度,也就是说m可以是等于1的。当 m = 1 的时候,称为 Mini-Batch Gradient Descent。
2.2 随机梯度下降法的缺陷和改进
2.2.1 随机梯度下降法的缺陷
随机梯度下降法面对的主要困难在于,它的梯度估计并不稳定,下降路径时常“弯弯曲曲”。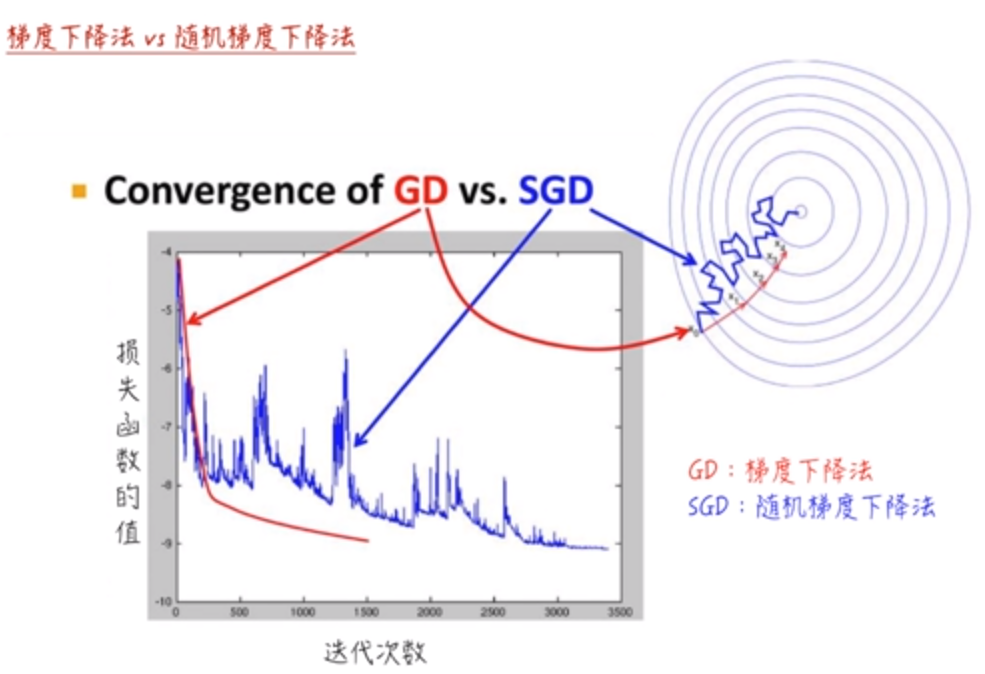
随机梯度下降法的梯度是近似值,与真实值是有误差的,虽然我们认为这个误差是比较小的,但是在特定条件下可能会引起整个算法的下降效率变差。
梯度下降法(GD)可以准确地计算每一点的梯度,所以它的下降是比较直接的(红色)。但是对于随机梯度下降法(SGD),因为它的梯度估计有误差,所以真实的下降路线是弯弯曲曲的。它需要的迭代次数也会比梯度下降法更高,虽然它每一次迭代比梯度下降法需要的时间更短。
总结一下,随机梯度下降法中,函数梯度的估计值并不稳定,遇到 鞍点 和 山谷 时,随机梯度下降法的效果很差。
2.2.2 随机梯度下降法的改进(动量方法)
在随机梯度下降法中,根据递推公式,它每次的迭代都只与这次迭代的起点的梯度相关,跟上次是无关的。这并不是很合理。
动量方法模拟了物理中的惯性作用:
1. 上一次迭代的改变量视为速度。2. 这次迭代的梯度视为加速度。
它的公式及参数说明如下:
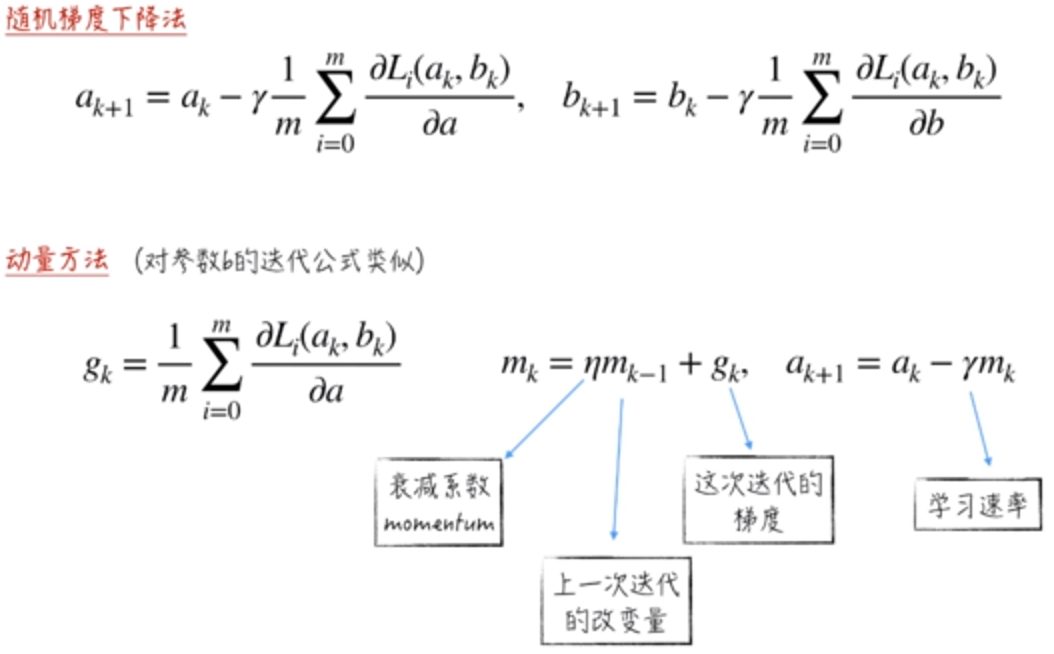
使用这样的方法去迭代,从实践上证明,它通常会比梯度下降法和随机梯度下降法的下降效率高很多。
2.2.3 随机梯度下降法的改进(Adam方法)
它不仅仅保留了 2.2.2章节中动量方法的“惯性作用”,并在此基础上,增加了如下作用:
对于历史梯度较小的模型参数,放大当前的更新步伐(步长);反之,则变小。

我们可以认为 mk 代表了速度。vk 与 mk 的差别在于 gk 的平方,这里的平方在于,我们想衡量历史上梯度的绝对值的大小。当 vk 特别大的时候,就需要减少 mk 的值。否则,将放大 mk 的值。结合这两点就得到了模型参数的估计公式 ak+1 。这里的 ε 就是工程上的处理,主要为了处理 vk = 0的情况,这种情况下会变得无法计算。
另外,递推公式里用的 mk帽子 和 vk帽子 是 mk 和 vk 处理之后得到的。
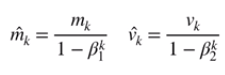
做这种处理的目的在于,我们希望 mk帽子 的期望是等于 gk 的期望,vk帽子 的期望是等于 gk平方 的期望。如果我们将 mk 和 vk 展开之后可以得到
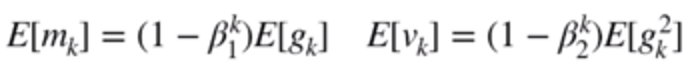
因此,我们做了上面的帽子修正。就使得期望成立。从数学上来说公式更加完美,从实践上来说梯度的下降效率和下降精度都会有所提高。