【Pixel-Fillrate】
“填充率“以每秒钟填充的像素点为单位,“三角形(多边形)生成速度“则表示每秒钟三角形(多边形)生成个数。现在的3D显卡的性能也主要看着两项指标,这两项指标的数值越大,显卡三维图像的处理能力就越强,显卡的档次也就越高。
填充率的故事
谈到3D加速卡,最常用的一个词就是填充率。各大厂商在介绍和推广自己的产品时,填充率总是作为一个重要指标而大肆宣扬。甚至一场宣传战的争夺焦点也是填充率。那么,填充率到底意味着什么?为什么有些公司用texels(纹理填充率)而另一些用pixels(像素填充率)来定义呢?
首先让我们来看看厂商们对填充率相关的声明:
“ATi的下一代Rage 128 GL图形芯片将为高端PC市场提供最好的性能和功能,Rage 128 GL具有超标量渲染引擎和单通道多纹理技术,将是第一个突破1 G texel/s大关的3D芯片。”
-引自ATI的多年前的一次产品宣传
“nVIDIA Geforce 2,历史上第一款填充率破G的图形芯片!(1.0 Gigapixels)”
nVIDIA当年的的新闻声明:
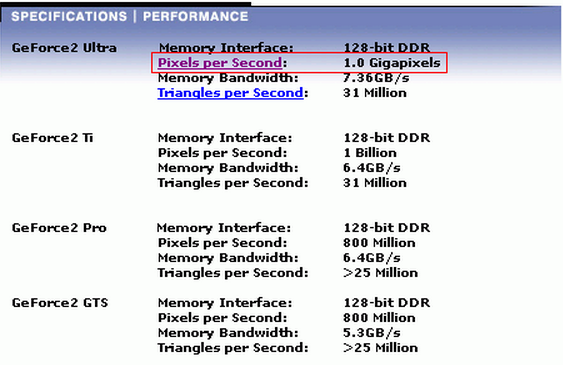
[理论峰值填充率]
大多数公司所谓的填充率实际指的是理论峰值填充率,那么那些填充率的数值是怎么得来的呢?要获得一块显卡的填充率的前提条件是必须知道3D芯片的时钟。将芯片时钟、像素渲染管线的数目相乘,即可得到芯片的填充率数值。下面的几个例子有助于理解:
3dfx Banshee处理器通常在100MHz下运行。它只有一条像素渲染管线,(这样每个周期它只能计算出一个双线性过滤像素并在屏幕上显示出来)。根据填充率的定义,Banshee的理论峰值填充率就是100MHzX1=100M pixels/s。
nVIDIA RIVA TNT有两条像素渲染管线,芯片时钟为90MHz,很容易算出TNT的理论填充率为180M pixels/s。
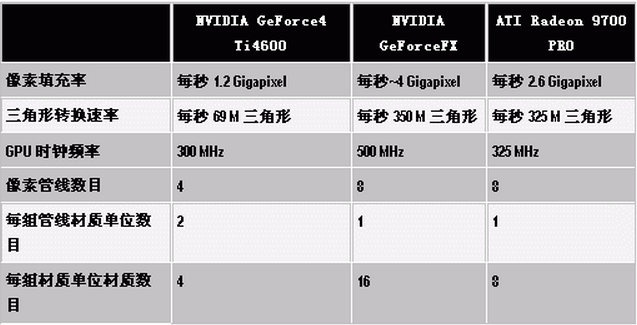
nVIDIA Geforce FX 5800 Ultra处理器通常在500MHz下运行。它有八条像素渲染管线,每条管线一个纹理单元。根据填充率的定义,Geforce FX 5800 Ultra的理论峰值填充率就是
500MHzX8X1=4000M pixels/s。
ATi Radeon 9700 Pro处理器通常在325MHz下运行。它有八条像素渲染管线,每条管线一个纹理单元。根据填充率的定义,Radeon 9700 Pro的理论峰值填充率就是325MHzX8X1=2600M pixels/s。
原来如此,我明白了!先别太得意,事情可不是想的那么简单。上面的填充率都是在极端的条件下得到的。某些图形处理器面临限制,它们的像素渲染管线只能为同一个屏幕像素工作,如果像素为单纹理的话,那么第二个像素渲染管线就只好闲置了,这时填充率实际上很低。这里我要告诉大家的主要问题是:在不同的条件下,填充率可能有所不同。理论峰值填充率是3D芯片时钟与像素渲染管线数目的乘积。但这种填充率是在特定的工作环境下获得的,要求像素渲染管线可以同时工作。
让我们来体验一个复杂些的情况:试着计算一下nVIDIA Geforce Ti 4600的填充率,Ti 4600有四条像素渲染管线,每条管线两个纹理单元,芯片时钟为300MHz, Geforce Ti 4600的理论峰值填充率怎么计算?300MHzX4X2=2400M pixels/s?嗯,算来不错,可实际上呢?300MHzX4=1200M pixels/s,这才是正确的计算!那么300MHzX4X2=2400M是什么呢?答案就是:2400M texels /s。这里,texels /s这个英文就是我们下面要讲的——纹理填充率。
[纹理填充率与像素填充率]
为什么有的厂商广告词中填充率的数字怎么比理论填充率还要高?难道是厂商骗人吗?这里你所看到的填充率很可能就是纹理填充率而不是理论填充率!
纹理填充率是指一秒钟内纹理渲染的数目,计算公式同理论填充率相似:3D芯片时钟x像素渲染管线数目x单个纹理使用的texel数目。
哇,太难受了!不要紧,我们还是举例子:
ATi Rage 128GL原打算设计为125MHz,有两条像素渲染管线。每条管线可以为一个双线性过滤像素上色,而双线性过滤需要4个texles。因此Rage 128GL纹理填充率为:125(时钟)X 2(像素渲染管线条数)x 4(texels)= 1000 Mtexels/s或1G texels/s。
让我们回首上文那段新闻稿:
“ATi Rage 128 GL图形芯片将为PC市场提供最好的性能和功能,Rage 128 GL具有超标量渲染引擎和单通道多纹理技术,将是第一个突破1 G texel/s大关的3D芯片。”
许多人都迷惑不解,因为他们认为上面所说的1G texels是理论峰值填充率,我个人认为不应该使用纹理填充率,那样做的唯一目的就是欺骗和愚弄人们。所以当你看到一个近似天文数字或比同一代其他显卡高的多的填充率,你应当意识到那很可能是纹理填充率而不是理论峰值填充率。
这里,我们要注意的是,纹理填充率从来都是以Mtexels表示,而不用Mpixels!