摘要:
像我这样愚蠢的人,经过这么长时间的深入学习,我已经学会了如何划分数据集。我太傻了,我哭了。我的图像集是从一个大家伙那里下载的。总共有五种类型的图像。大家伙的博客在这里https://blog.csdn.net/guyuealian/article/details/81560537可以说它相当强大,但我没有按照他的方式来划分。我在网上找了几个帖子供参考,然后根据自己的情况进行了划分。重要的,重要的
笨蛋如我,学深度学习这么久,居然才学会划分数据集啊,我快被我自己蠢哭了,我的这个图像集是从一个大佬那下载的,一共5类的图像,大佬的博客在这https://blog.csdn.net/guyuealian/article/details/81560537 可以说是相当厉害了,但是我没按照他的那种方式划分,我在网上找了几个帖子做了参考,然后结合我自己的情况划分的。
import os import random import shutil from shutil import copy2 """os.listdir会将文件夹下的文件名集合成一个列表并返回""" def getDir(filepath): pathlist=os.listdir(filepath) return pathlist """制作五类图像总的训练集,验证集和测试集所需要的文件夹,例如训练集的文件夹中装有五个文件夹,这些文件夹分别装有一定比例的五类图像""" def mkTotalDir(data_path): os.makedirs(data_path) dic=['train','validation','test'] for i in range(0,3): current_path=data_path+dic[i]+'/' #这个函数用来判断当前路径是否存在,如果存在则创建失败,如果不存在则可以成功创建 isExists=os.path.exists(current_path) if not isExists: os.makedirs(current_path) print('successful '+dic[i]) else: print('is existed') return """传入的参数是五类图像原本的路径,返回的是这个路径下各类图像的名称列表和图像的类别数""" def getClassesMes(source_path): classes_name_list=getDir(source_path) classes_num=len(classes_name_list) return classes_name_list,classes_num """change_path其实就是制作好的五类图像总的训练集,验证集和测试集的路径,sourcepath和上面一个函数相同 这个函数是用来建训练集,测试集,验证集下五类图像的文件夹,就是建15个文件夹,当然也可以建很多类 """ def mkClassDir(source_path,change_path): classes_name_list,classes_num=getClassesMes(source_path) for i in range(0,classes_num): current_class_path=os.path.join(change_path,classes_name_list[i]) isExists=os.path.exists(current_class_path) if not isExists: os.makedirs(current_class_path) print('successful '+classes_name_list[i]) else: print('is existed') """ source_path:原始多类图像的存放路径 train_path:训练集图像的存放路径 validation_path:验证集图像的存放路径 test_path:测试集图像的存放路径 """ def divideTrainValidationTest(source_path,train_path,validation_path,test_path): """先获取五类图像的名称列表和类别数目""" classes_name_list,classes_num=getClassesMes(source_path) """调用上面的函数,在训练集验证集和测试集文件夹下建立五类图像的文件夹""" mkClassDir(source_path,train_path) mkClassDir(source_path,validation_path) mkClassDir(source_path,test_path) """ 先将一类图像的路径拿出来,将这个路径下所有这类的图片,就是800张图片的文件名做成一个列表,使用os.listdir函数, 然后再将列表里面的所有图像名进行shuffle就是随机打乱,然后从打乱后的图像中抽7成放入训练集,2成放入验证集,1成 放入测试集的图像名称列表 """ for i in range(0,classes_num): source_image_dir=os.listdir(source_path+classes_name_list[i]+'/') random.shuffle(source_image_dir) train_image_list=source_image_dir[0:int(0.7*len(source_image_dir))] validation_image_list=source_image_dir[int(0.7*len(source_image_dir)):int(0.9*len(source_image_dir))] test_image_list=source_image_dir[int(0.9*len(source_image_dir)):] """ 找到每一个集合列表中每一张图像的原始图像位置,然后将这张图像复制到目标的路径下,一共是五类图像 每类图像随机被分成三个去向,使用shutil库中的copy2函数进行复制,当然也可以使用move函数,但是move 相当于移动图像,当操作结束后,原始文件夹中的图像会都跑到目标文件夹中,如果划分不正确你想重新划分 就需要备份,不然的话很麻烦 """ for train_image in train_image_list: origins_train_image_path=source_path+classes_name_list[i]+'/'+train_image new_train_image_path=train_path+classes_name_list[i]+'/' copy2(origins_train_image_path,new_train_image_path) for validation_image in validation_image_list: origins_validation_image_path=source_path+classes_name_list[i]+'/'+validation_image new_validation_image_path=validation_path+classes_name_list[i]+'/' copy2(origins_validation_image_path,new_validation_image_path) for test_image in test_image_list: origins_test_image_path=source_path+classes_name_list[i]+'/'+test_image new_test_image_path=test_path+classes_name_list[i]+'/' copy2(origins_test_image_path,new_test_image_path) if __name__=='__main__': data_path = 'D:/软件/pycharmProject/wenyuPy/Dataset/VGG16/' source_path = 'C:/Users/Administrator/Desktop/dataset/ImageData/' train_path = 'D:/软件/pycharmProject/wenyuPy/Dataset/VGG16/train/' validation_path = 'D:/软件/pycharmProject/wenyuPy/Dataset/VGG16/validation/' test_path = 'D:/软件/pycharmProject/wenyuPy/Dataset/VGG16/test/' mkTotalDir(data_path) divideTrainValidationTest(source_path, train_path, validation_path, test_path)
然后看一下划分结果,先看原始情况:
这就是source_path和下面的五类图像,每一类图像有800张,然后下面是划分后
这里面的这个路径就是train_path,就是装五类图像训练的那一部分的路径,下面是其中一类划分过后的训练集部分
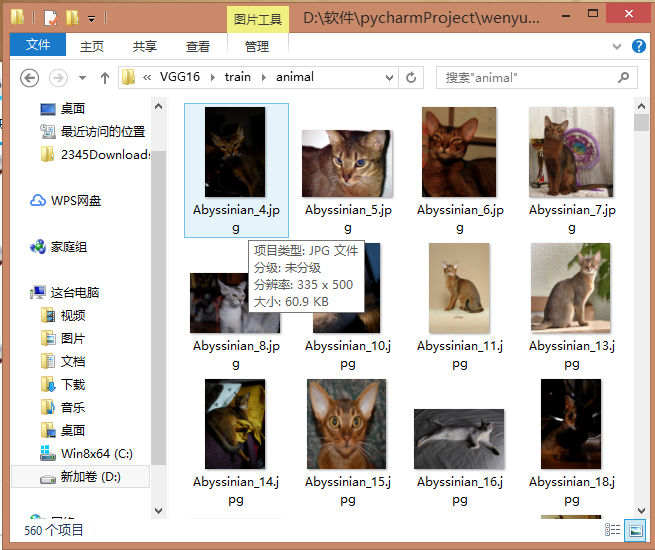
可以看到有560张图片啦
这就是我学习如何划分数据集的一天啦,将他们划分到不同的文件夹下是因为制作tfrecords的时候可能会更方便,我不太懂哈,如果有更好的划分方法希望大佬们赐教。
抱歉,由于我的问题,最后那个560张训练集的图片好像不小心被我删掉了,我换了电脑,图找不到了,但是程序本身是没有问题的哈,就酱