摘要:
使用反射+枚举+自由标记自动生成实体类并创建数据表和索引。主要步骤与前一篇博客文章中的步骤类似,即首先反映和读取枚举类,获取所需信息,然后使用freemarker生成实体类。这里还需要Freemarker Jar This Jar包。由于需要创建表和索引,因此应该使用底层数据库的javaAPI,因此我们应该首先在java中普及DatabaseMetaData元数据信息。典型类型有“表格”、“视图”、“系统表”、“全局临时”、“本地临时”、”ALIAS“和”SYNONYM“。
接上一篇博文 反射+枚举+freemarker,自动生成实体类,自动建表建索引(一)之生成实体类,枚举详解,这篇博文介绍自动建表。
用反射+枚举+freemarker,自己实现的自动生成实体类和自动建立数据表建索引。用enum枚举作为数据表的配置文件,1个枚举就是1张表,根据枚举类,自动生成实体类,和自动建表建索引。
主要步骤和 上一篇博文差不多,就是先反射读取枚举类,获取所需信息,然后用freemarker生成实体类。这里也需要用到freemarker.jar这个jar包(点击下载)。由于是要建表,和建索引,需要用到底层数据库的javaAPI,所以也要先普及一下Java中DatabaseMetaData 元数据信息。
1、Java中DatabaseMetaData 元数据信息
// 现获取DatabaseMetaData
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/test";
String user = "root";
String password = "root";
Connection con = DriverManager.getConnection(url, user, password);
DatabaseMetaData dbMetaData = con.getMetaData();
// 表信息
/**
* 每个表描述都有以下列:
* TABLE_CAT String => 表类别(可为 null)
* TABLE_SCHEM String => 表模式(可为 null)
* TABLE_NAME String => 表名称
* TABLE_TYPE String => 表类型。典型的类型是 "TABLE"、"VIEW"、"SYSTEM TABLE"、"GLOBAL TEMPORARY"、"LOCAL TEMPORARY"、"ALIAS" 和 "SYNONYM"。
* REMARKS String => 表的解释性注释
* TYPE_CAT String => 类型的类别(可为 null)
* TYPE_SCHEM String => 类型模式(可为 null)
* TYPE_NAME String => 类型名称(可为 null)
* SELF_REFERENCING_COL_NAME String => 有类型表的指定 "identifier" 列的名称(可为 null)
* REF_GENERATION String => 指定在 SELF_REFERENCING_COL_NAME 中创建值的方式。这些值为 "SYSTEM"、"USER" 和 "DERIVED"。(可能为 null)
*
*/
// table type. Typical types are "TABLE", "VIEW", "SYSTEM TABLE", "GLOBAL TEMPORARY", "LOCAL TEMPORARY", "ALIAS", "SYNONYM".
String[] types = { "TABLE" };
ResultSet rs = dbMetaData.getTables(null, schemaName, "%", types);
while (rs.next()) {
String tableName = rs.getString("TABLE_NAME"); //表名
String tableType = rs.getString("TABLE_TYPE"); //表类型
String remarks = rs.getString("REMARKS"); //表备注
System.out.println(tableName + "-" + tableType + "-" + remarks);
}
//获得表或视图中的所有列信息
/**
* 每个列描述都有以下列:
*
* TABLE_CAT String => 表类别(可为 null)
* TABLE_SCHEM String => 表模式(可为 null)
* TABLE_NAME String => 表名称
* COLUMN_NAME String => 列名称
* DATA_TYPE int => 来自 java.sql.Types 的 SQL 类型
* TYPE_NAME String => 数据源依赖的类型名称,对于 UDT,该类型名称是完全限定的
* COLUMN_SIZE int => 列的大小。
* BUFFER_LENGTH 未被使用。
* DECIMAL_DIGITS int => 小数部分的位数。对于 DECIMAL_DIGITS 不适用的数据类型,则返回 Null。
* NUM_PREC_RADIX int => 基数(通常为 10 或 2)
* NULLABLE int => 是否允许使用 NULL。
* columnNoNulls - 可能不允许使用 NULL 值
* columnNullable - 明确允许使用 NULL 值
* columnNullableUnknown - 不知道是否可使用 null
* REMARKS String => 描述列的注释(可为 null)
* COLUMN_DEF String => 该列的默认值,当值在单引号内时应被解释为一个字符串(可为 null)
* SQL_DATA_TYPE int => 未使用
* SQL_DATETIME_SUB int => 未使用
* CHAR_OCTET_LENGTH int => 对于 char 类型,该长度是列中的最大字节数
* ORDINAL_POSITION int => 表中的列的索引(从 1 开始)
* IS_NULLABLE String => ISO 规则用于确定列是否包括 null。
* YES --- 如果参数可以包括 NULL
* NO --- 如果参数不可以包括 NULL
* 空字符串 --- 如果不知道参数是否可以包括 null
* SCOPE_CATLOG String => 表的类别,它是引用属性的作用域(如果 DATA_TYPE 不是 REF,则为 null)
* SCOPE_SCHEMA String => 表的模式,它是引用属性的作用域(如果 DATA_TYPE 不是 REF,则为 null)
* SCOPE_TABLE String => 表名称,它是引用属性的作用域(如果 DATA_TYPE 不是 REF,则为 null)
* SOURCE_DATA_TYPE short => 不同类型或用户生成 Ref 类型、来自 java.sql.Types 的 SQL 类型的源类型(如果 DATA_TYPE 不是 DISTINCT 或用户生成的 REF,则为 null)
* IS_AUTOINCREMENT String => 指示此列是否自动增加
* YES --- 如果该列自动增加
* NO --- 如果该列不自动增加
* 空字符串 --- 如果不能确定该列是否是自动增加参数
*
*/
ResultSet rs = dbMetaData.getColumns(null, schemaName, tableName, "%");
while (rs.next()){
String tableCat = rs.getString("TABLE_CAT");//表目录(可能为空)
String tableSchemaName = rs.getString("TABLE_SCHEM");//表的架构(可能为空)
String tableName_ = rs.getString("TABLE_NAME");//表名
String columnName = rs.getString("COLUMN_NAME");//列名
}
//索引信息
/**
* 每个索引列描述都有以下列:
*
* TABLE_CAT String => 表类别(可为 null)
* TABLE_SCHEM String => 表模式(可为 null)
* TABLE_NAME String => 表名称
* NON_UNIQUE boolean => 索引值是否可以不唯一。TYPE 为 tableIndexStatistic 时索引值为 false
* INDEX_QUALIFIER String => 索引类别(可为 null);TYPE 为 tableIndexStatistic 时索引类别为 null
* INDEX_NAME String => 索引名称;TYPE 为 tableIndexStatistic 时索引名称为 null
* TYPE short => 索引类型:
* tableIndexStatistic - 此标识与表的索引描述一起返回的表统计信息
* tableIndexClustered - 此为集群索引
* tableIndexHashed - 此为散列索引
* tableIndexOther - 此为某种其他样式的索引
* ORDINAL_POSITION short => 索引中的列序列号;TYPE 为 tableIndexStatistic 时该序列号为零
* COLUMN_NAME String => 列名称;TYPE 为 tableIndexStatistic 时列名称为 null
* ASC_OR_DESC String => 列排序序列,"A" => 升序,"D" => 降序,如果排序序列不受支持,可能为 null;TYPE 为 tableIndexStatistic 时排序序列为 null
* CARDINALITY int => TYPE 为 tableIndexStatistic 时,它是表中的行数;否则,它是索引中唯一值的数量。
* PAGES int => TYPE 为 tableIndexStatisic 时,它是用于表的页数,否则它是用于当前索引的页数。
* FILTER_CONDITION String => 过滤器条件,如果有的话。(可能为 null)
*
*/
ResultSet rs = dbMetaData.getIndexInfo(null, schemaName, tableName, true, true);
while (rs.next()){
boolean nonUnique = rs.getBoolean("NON_UNIQUE");//非唯一索引(Can index values be non-unique. false when TYPE is tableIndexStatistic )
String indexQualifier = rs.getString("INDEX_QUALIFIER");//索引目录(可能为空)
String indexName = rs.getString("INDEX_NAME");//索引的名称
short type = rs.getShort("TYPE");//索引类型
String columnName = rs.getString("COLUMN_NAME");//列名
String ascOrDesc = rs.getString("ASC_OR_DESC");//列排序顺序:升序还是降序
}
// 还有主键信息,外键信息,视图信息等就不一一列举了。。。。2、自动建表建索引操作。
由于上一篇博文中已经介绍了关于枚举类的信息,所以此处不再赘述,直接贴出自动建表建索引的代码,代码中已经注释的很详细了,大体思路如下,先判断待创建的数据表存在与否,不存在则创建,存在则更新,更新时找出数据表中有而枚举类中无的字段,即列,然后更新表结构,然后不论是建表还是更新表,都需要进行判断索引是否存在,是否要建立索引,具体获得索引,获得表信息,获得列信息,上面的DatabaseMetaData 元数据信息已经介绍获取方法。好了,废话不多说,直接上代码:
package com.test.common;
import static com.test.common.EntityConfigData.DEFAULTS;
import static com.test.common.EntityConfigData.INDEX;
import static com.test.common.EntityConfigData.LENGTH;
import static com.test.common.EntityConfigData.NULLABLE;
import static com.test.common.EntityConfigData.TYPE;
import static com.test.common.EntityConfigData.TYPE_DEFUALT_INT;
import static com.test.common.EntityConfigData.TYPE_DEFUALT_LONG;
import static com.test.common.EntityConfigData.TYPE_DEFUALT_STRING;
import java.sql.Connection;
import java.sql.DatabaseMetaData;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
import com.test.PackageClass;
/**
* 自动建表建索引类
* @author Lufeng
*
*/
public class GenDB {
private String sourceDir; // 配置源文件夹
public GenDB(String source) {
this.sourceDir = source;
}
/**
* 获取不同类型默认长度
* @param clazz
* @param obj
* @param type
* @return
* @throws Exception
*/
public int getDefaultLength(String type) throws Exception {
int length = 0;
if(type == null) {
throw new RuntimeException("不能识别的类型:" + type);
}
// 根据不同类型返回不同默认长度
if("int".equals(type)) {
length = TYPE_DEFUALT_INT;;
} else if("long".equals(type)) {
length = TYPE_DEFUALT_LONG;
} else if("String".equals(type)) {
length = TYPE_DEFUALT_STRING;
}
return length;
}
public String getSqlType(String type) {
String result = "";
if("int".equals(type)) {
result = "integer";
} else if("long".equals(type)) {
result = "bigint";
} else if("String".equals(type)) {
result = "varchar";
}
return result;
}
/**
* 获取配置类中的所有字段名
* @param clazz
* @return
*/
public List<String> getColumns(Class<?> clazz) {
List<String> result = new ArrayList<String>();
// 获得所有枚举字段成员(id, account, name, profession...),并遍历获取字段名
Object[] enums = clazz.getEnumConstants();
result.add("id"); // id是默认添加的
for (Object e : enums) {
result.add(e.toString());
}
return result;
}
/**
* 获取所有约束信息
* @param clazz
* @param obj
* @return
* @throws Exception
*/
public Map<String, Object> getFieldInfo(Class<?> clazz, Object obj) throws Exception {
Map<String, Object> result = new HashMap<String, Object>();
// 获取所有约束信息
String name = obj.toString();
String typeName = ((Class<?>) GenUtils.getFieldValue(clazz, obj, TYPE)).getSimpleName();
String type = getSqlType(typeName);
int length = (Integer) GenUtils.getFieldValue(clazz, obj, LENGTH);
boolean index = (Boolean) GenUtils.getFieldValue(clazz, obj, INDEX);
String nullable = (Boolean) GenUtils.getFieldValue(clazz, obj, NULLABLE) == true ? "NULL" : "NOT NULL";
//默认值
Object def = GenUtils.getFieldValue(clazz, obj, DEFAULTS);
String defaults = def == null ? "" : " DEFAULT '" + def.toString() + "'";
// 如果长度为0,即没设长度,则提取默认值
if(length == 0) {
length = getDefaultLength(typeName);
}
result.put("name", name);
result.put(TYPE, type);
result.put(LENGTH, length);
result.put(INDEX, index);
result.put(NULLABLE, nullable);
result.put(DEFAULTS, defaults);
return result;
}
/**
* 获取表中所有字段信息
* @param clazz
* @return
* @throws Exception
*/
public List<Map<String, Object>> getTableInfo(Class<?> clazz) throws Exception {
List<Map<String, Object>> tableInfo = new ArrayList<Map<String, Object>>();
// 获得所有枚举字段成员(id, account, name, profession...),并遍历获取信息
Object[] enums = clazz.getEnumConstants();
for (Object e : enums) {
// 获取字段约束信息
Map<String, Object> field = getFieldInfo(clazz, e);
tableInfo.add(field);
}
return tableInfo;
}
/**
* 获取某个字段的约束信息
* @param clazz
* @param name
* @return
* @throws Exception
*/
public Map<String, Object> getOneFieldInfo(Class<?> clazz, String name) throws Exception {
Map<String, Object> fieldInfo = new HashMap<String, Object>();
//返回所有枚举类型
Enum<?>[] enums = (Enum[]) clazz.getEnumConstants();
for (Enum<?> e : enums) {
// 如果不是想要的字段信息, 则跳过
if(!e.toString().equals(name)) {
continue;
}
// 获取字段约束信息
fieldInfo = getFieldInfo(clazz, e);
}
return fieldInfo;
}
/**
* 获取配置表中需要创建索引的字段
* @param clazz
* @return
* @throws Exception
*/
public List<String> getIndexField(Class<?> clazz) throws Exception {
List<String> result = new ArrayList<String>();
result.add("id"); // 默认id是索引
// 找出class中所有需要创建索引的字段
Object[] fields = clazz.getEnumConstants();
for(Object f : fields){
boolean index = (Boolean) GenUtils.getFieldValue(clazz, f, INDEX);
if(index) result.add(f.toString());
}
return result;
}
/**
* 在表上创建索引
* @param conn
* @param tableName
* @param clazz
* @param columns
* @throws SQLException
*/
public void checkCreateIndex(Connection conn, String tableName, Class<?> clazz) throws Exception {
// 反射获取配置中待创建索引的列
List<String> indexConfs = getIndexField(clazz);
// 表中加索引的列信息
List<String> indexTables = new ArrayList<String>();
DatabaseMetaData dbMeta = conn.getMetaData();
String schema = null;
// 获取表中索引信息
ResultSet indexs = dbMeta.getIndexInfo(null, schema, tableName, false, true);
while(indexs.next()) {
indexTables.add(indexs.getString("COLUMN_NAME"));
}
indexs.close();
// 若数据表索引包含配置类中全部索引,则不用建索引,直接返回
if(indexTables.containsAll(indexConfs)) {
return ;
}
// 找出配置中有,数据表中没有的索引
List<String> indexDifs = new ArrayList<String>();
for(String i : indexConfs) {
if(!indexTables.contains(i)) {
indexDifs.add(i);
}
}
// 创建索引
Statement st = conn.createStatement();
for(String column : indexDifs) {
String indexSql = "CREATE INDEX " + tableName + "_" + column + " ON " + tableName +"(" + column + ")";
System.out.println("建索引: " + indexSql);
st.executeUpdate(indexSql);
}
st.close();
}
/**
* 建表操作
* @param conn
* @param tableName
* @param clazz
* @throws Exception
*/
public void createTable(Connection conn, String tableName, Class<?> clazz) throws Exception {
// 拼成SQL语句
StringBuilder sql = new StringBuilder();
sql.append("CREATE TABLE `").append(tableName).append("`"); // 建表
sql.append("(");
sql.append("`id` bigint(20) NOT NULL,"); // 创建默认主键
// 获取并遍历配置表字段
List<Map<String, Object>> tableInfo = getTableInfo(clazz);
for(Map<String, Object> t : tableInfo) {
sql.append("`").append(t.get("name")).append("` "); // 字段名
sql.append(t.get(TYPE)); // 类型
sql.append("(").append(t.get(LENGTH)).append(") "); // 长度
sql.append(t.get(NULLABLE)); // 是否为空
sql.append(t.get(DEFAULTS)); // 默认值
sql.append(",");
}
sql.append("PRIMARY KEY (`id`)"); // 设置主键
sql.append(")");
System.out.println("\n建表: " + sql);
// 执行建表操作
Statement st = conn.createStatement();
st.executeUpdate(sql.toString());
st.close();
// 建索引
checkCreateIndex(conn, tableName, clazz);
}
/**
* 更新表操作
* @param con
* @param tableName
* @param clazz
* @throws Exception
*/
public void updateTable(Connection con, String tableName, Class<?> clazz) throws Exception {
//获取表中列信息
DatabaseMetaData dBMetaData = con.getMetaData();
ResultSet colSet = dBMetaData .getColumns(null, "%", tableName, "%");
//表中已有的列名
List<String> colTables = new ArrayList<String>();
while(colSet.next()) {
colTables.add(colSet.getString("COLUMN_NAME"));
}
colSet.close();
//配置中的列名
List<String> colConfs = getColumns(clazz);
// 如果数据表中列名包含配置表中全部列名, 则检查创建索引,不用更新表,直接返回
if(colTables.containsAll(colConfs)){
checkCreateIndex(con, tableName, clazz);
return;
}
// 找出两表列名不同
List<String> colDifs = new ArrayList<String>();
for(String col : colConfs) {
if(!colTables.contains(col)) {
colDifs.add(col);
}
}
// 取得配置中的表字段信息, 拼成SQL语句
StringBuffer sql = new StringBuffer();
sql.append("ALTER TABLE `").append(tableName).append("` "); // 更新表
for(int i = 0; i < colDifs.size(); i++) {
String col = colDifs.get(i);
Map<String, Object> field = getOneFieldInfo(clazz, col);
if(i > 0) sql.append(", ");
sql.append("ADD `").append(col).append("` "); // 增加列名
sql.append(field.get(TYPE)); // 类型
sql.append("(").append(field.get(LENGTH)).append(") "); // 长度
sql.append(field.get(NULLABLE)); // 是否为空
sql.append(field.get(DEFAULTS)); // 默认值
}
System.out.println("\n更新表: " + sql.toString());
// 更新表操作
Statement st = con.createStatement();
st.executeUpdate(sql.toString());
st.close();
// 建索引
checkCreateIndex(con, tableName, clazz);
}
// TODO 数据库连接方面需要改进
private static Connection getDBConnection(String driver, String urlDB, String user, String pwd) throws Exception {
// 连接MYSQL数据库
Class.forName(driver);
Connection conn = DriverManager.getConnection(urlDB, user, pwd);
return conn;
}
/**
* 根据配置源文件夹检查建数据表
*/
public void genDB(Connection conn) {
try {
// 获取源文件夹下的所有类
Set<Class<?>> sources = PackageClass.find(sourceDir);
// 遍历所有类,取出有注解的生成实体类
for(Class<?> clazz : sources) {
// 过滤没有EntityConfig注解的类, 并建表
if(clazz.isAnnotationPresent(EntityConfig.class)) {
checkAndCreat(clazz, conn);
}
}
// 关闭连接
conn.close();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 检查并建表或更新表结构
* @param clazz
* @throws Exception
*/
public void checkAndCreat(Class<?> clazz, Connection conn) throws Exception {
// 获取表的信息
String catalog = null;
String schema = "%";
String tableName = GenUtils.getTableName(clazz);
String[] types = new String[] { "TABLE" };
DatabaseMetaData dBMetaData = conn.getMetaData();
// 从databaseMetaData获取表信息
ResultSet tableSet = dBMetaData.getTables(catalog, schema, tableName, types);
// 如果表不存在, 则建表
if (!tableSet.next()) {
createTable(conn, tableName, clazz);
} else { //表存在, 则更新表
updateTable(conn, tableName, clazz);
}
// 关闭数据库连接
tableSet.close();
}
public static void main(String[] args) throws Exception {
args = new String[] {"com.test.testentity"};
String sourceDir = args[0];
String driver = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql://localhost:3306/game";
String user = "root";
String pwd = "";
Connection conn = getDBConnection(driver, url, user, pwd);
GenDB db = new GenDB(sourceDir);
db.genDB(conn);
}
}
3、补充介绍注解(上一篇博文用到确没有介绍的)。
可以用@interface来声明一个注解,其中的每一个方法实际上是声明了一个配置参数( 注解只有一个配置参数,该参数的名称默认为value,并且可以省略。)。方法的名称就是参数的名称, 返回值类型就是参数的类型。可以通过default来声明参数的默认值。
@Retention用来声明注解的保留策略,有CLASS、RUNTIME和SOURCE这三种,分别表示注解保存在类文件、JVM运行时 刻和源代码中。只有当声明为RUNTIME的时候,才能够在运行时刻通过反射API来获取到注解的信息。@Target用来声明注解可以被添加在哪些类型 的元素上,如类型、方法和域等。具体元注解如下: /* * 元注解@Target,@Retention,@Documented,@Inherited * * @Target 表示该注解用于什么地方,可能的 ElemenetType 参数包括: * ElemenetType.CONSTRUCTOR 构造器声明 * ElemenetType.FIELD 域声明(包括 enum 实例) * ElemenetType.LOCAL_VARIABLE 局部变量声明 * ElemenetType.METHOD 方法声明 * ElemenetType.PACKAGE 包声明 * ElemenetType.PARAMETER 参数声明 * ElemenetType.TYPE 类,接口(包括注解类型)或enum声明 * * @Retention 表示在什么级别保存该注解信息。可选的 RetentionPolicy 参数包括: * RetentionPolicy.SOURCE 注解将被编译器丢弃 * RetentionPolicy.CLASS 注解在class文件中可用,但会被VM丢弃 * RetentionPolicy.RUNTIME VM将在运行期也保留注释,因此可以通过反射机制读取注解的信息。 * * @Documented 将此注解包含在 javadoc 中 * * @Inherited 允许子类继承父类中的注解 * */
4、最后结果截图如下:

配置枚举类为: 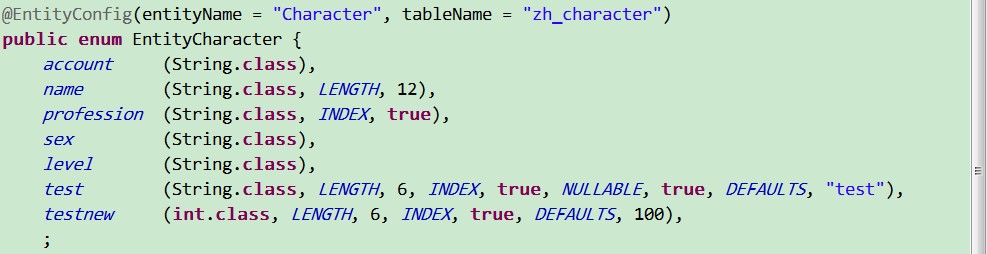
生成的数据表为:
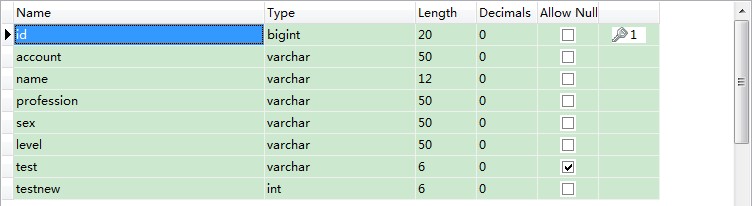
注:这个是本人原创的,如需转载,请尊重劳动果实,务必保持原链接(http://blog.csdn.net/lufeng20/article/details/8731314)。