自信息的含义包括两个方面:
1.自信息表示事件发生前,事件发生的不确定性。
2.自信息表示事件发生后,事件所包含的信息量,是提供给信宿的信息量,也是解除这种不确定性所需要的信息量。
互信息:
离散随机事件之间的互信息:
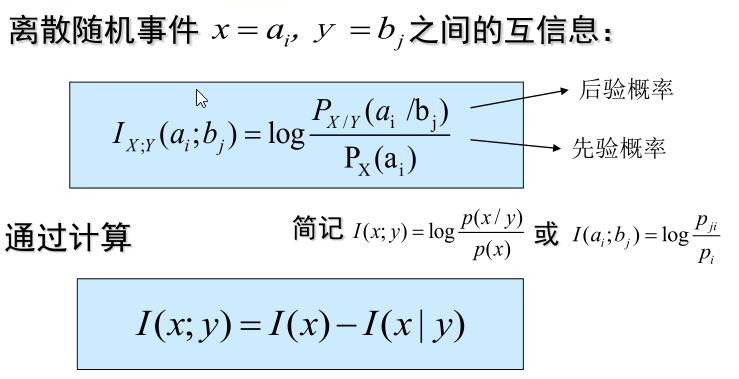
换句话说就是,事件x,y之间的互信息等于“x的自信息”减去 “y条件下x的自信息”。 I(x)表示x的不确定性,I(x|y)表示在y发生条件下x的不确定性,I(x;y)表示当y发生后x不确定性的变化。 两个不确定度之差,是不确定度消除的部分,代表已经确定的东西,实际就是由y发生所得到的关于x的信息量。互信息可正可负(但是自信息一定是正的),所以就有了任何两事件之间的互信息不可能大于其中任一事件的自信息。(毕竟I(x;y)=I(y;x)=I(x)-I(x|y)=I(y)-I(y|x), I(x|y)和I(y|x)皆大于0 )
如果x事件提供了关于另一事件y的负的信息量,说明x的出现不利于y的出现。
另一个角度,如果x和y统计独立,即I(x|y)=I(y|x)=0. 则就会出现I(x;y) = I(x) 这种情况!,这也说明了另一个问题,就是一个事件的自信息是任何其他事件所能提供的关于该事件的最大信息量。
信息熵:
含义:
1.在信源输出后,表示每个信源符号所提供的平均信息量。
2.在信源输出前,表示信源的平均不确定性。
3.表示信源随机性大小,H(x)大的,随机性大
4.当信源输出后,不确定性解除,熵可视为解除信源不确定性所需的信息量。
信息熵的计算:
离散信源的熵等于所对应的有根概率树上的所有节点(包括根节点,不包括叶)的分支熵用该节点概率加权的和,即H(x)=∑q(ui)H(ui) 式中q(ui)为节点ui的概率,H(ui)为节点ui的分支熵。
条件熵:

另外 【 H(1/2) = 2* -1*(1/2)log2(1/2) = 1 H(1/3)=3* -1*(1/3)log2(1/3) = log23 ≈1.585 bit/符号】
联合熵:

另外【 H(1/3,1/3,1/3)=3* -1*(1/3) (1/3) = log23≈1.585 bit/符号 ,H() 的括号中如果只有一个分数1/2,那么就代表是 H(1/2,1/2) 毕竟2*1/2=1,同理H(1/3)代表 H(1/3,1/3,1/3) 】
熵的基本性质:
1.对称性2.非负性 3.拓展性 4.可加性
有以下表述:

5.极值性
离散最大熵定理:对于有限离散随机变量集合,当集合中的事件等概率发生时,熵达到最大值。可由散度不等式证明:

即H(x)≤logn,仅当P(x)等概率分布时等号成立。
6.确定性 :当随机变量集合中任一事件概率为1时,熵就为0. 换个形式来说,从总体来看,信源虽含有许多消息,但只有一个消息几乎必然出现,而其他消息几乎都不出现,那么,这是一个确知信源,从熵的不确定性概念来讲,确知信源的不确定性为0.
7上凸性:H(p)=H(p1,p2,p3,...,pn)是(p1,p2,p3,...,pn)的严格上凸函数。
各类熵之间的关系:
1.条件熵与信息熵之间的关系
H(Y|X) ≤H(Y) 这说明了:在信息处理的过程中,条件越多,熵越小。
2.联合熵和信息熵的关系
H(X1X2...XN)≤∑i=1NH(Xi) 当且仅当Xi相互独立时,等式成立。
熵函数的唯一性:
如果熵函数满足:(1)是概率的连续函数 (2)信源符号等概率时是n(信源符号数)的增函数(H(X)=log2n); (3)可加性 (H(XY) = H(X) + H(Y|X) =H(Y) + H(X|Y) )
那么,熵函数的表示是唯一的,即只与定义公式相差一个常数因子。