ElasticSearch的聚合(Aggregations)引入了两个概念:
- 桶(Buckets): 满足特定条件的文档的集合
- 指标(Metrics): 对桶内的文档进行统计计算
每个聚合都是多个桶和指标的组合。和sql的聚合语法对比:
SELECT COUNT(color) FROM table_xxx GROUP BY color
桶在概念上类似于 SQL 的分组(GROUP BY),而指标则类似于 COUNT() 、 SUM() 、 MAX() 等统计方法。
典型示例:
一个ES聚合的请求示例如下:
{
"size": 0,
"aggs": {
"最大费用": {
"max": { "field": "费用" }
}
}
}
关键字"aggs"标志了它是一个聚合请求,里面的请求参数为:
"最大费用": { "max": { "field": "费用" } }
主要包含标题,聚合类型(关键字),聚合参数三个部分。
返回值为:
{
"aggregations": {
"最大费用": {
"value": 2260.0
}
}
}
返回值随着不同的请求值会呈现不同的格式,具体规则可以看下面介绍。
指标(Metrics):
指标用来对查询结果进行统计运算,除了计数外,大部分针对数字类型属性进行统计。
"aggs": {
"最大费用": { "max": { "field": "费用" } }
}
典型的统计算法有:
- 计数
- 最大值
- 最小值
- 平均值
- 和
ES也支持一些高级统计指标,例如加权平均值,范围百分比等,具体可参看其官方文档。
一个聚合请求下可以下发多个指标:
{
"size": 0,
"aggs": {
"最大费用": { "max": { "field": "费用" } },
"费用合计": { "sum": { "field": "费用" } }
}
}
桶(Buckets):
桶用于对数据进行分组,类似于sqlserver的group,传统的分组请求在es中对应的语法为:
"aggs": {
"性别": {
"terms": { "field": "性别" }
}
}
和传统的关系型数据库分组相比,ES具有如下优势:
- 提供不少高级分组方式,如直方图,范围,过滤等
- 支持多级聚合,非常容易构建类似透视图的数据。
- 支持多种管道聚合
聚合和bucket的层级关系:
- 聚合可以放多个bucket,
- bucket下也可以挂聚合
这样,当使用两个指标分组的时候,有两种组合方式,
- 一个聚合,两个指标
- 两个指标组合成一个多级聚合
这两个的行为是不一样的,当聚合下放多个bucket的时候,是从两个维度分别统计,并union展示:后面的则是在第一个指标每个分组中就行二次分组。
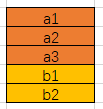
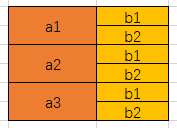
简单的讲,一个是a+b, 一个是a*b
返回结果格式:
规则1: 当只返回一个结果的时候,会作为属性返回,metrics的返回值基本上遵循此规则。
查询
"aggs": {
"最大费用": { "max": { "field": "费用" } },
"费用合计": { "sum": { "field": "费用" } }
}
返回结果:
"aggregations": {
"最大费用": { "value": 2260.0 },
"费用合计": { "value": 158704.37085723877 }
}
有的bucket也只返回一个结果,例如filter bucket。
规则2: 结果分组名称不可预知的时候,会作为名为buckets的数组返回,大部分的bucket返回结果满足此属性。
请求:
"aggs": {
"性别": { "terms": { "field": "性别" }
}
}
返回结果:
"aggregations": {
"性别": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{ "key": "女", "doc_count": 289 },
{ "key": "男", "doc_count": 208 }
]
}
}
规则3: 结果分组是可预知的多值是,会作为名为buckets的对象返回,部分bucket返回值,如range,filters遵循此规则。
请求:
"aggs": {
"费用级别": {
"range": {
"field": "费用",
"keyed": true,
"ranges": [
{ "key": "便宜", "to": 100 },
{ "key": "一般", "from": 100, "to": 300 },
{ "key": "贵", "from": 300 }
]
}
}
}
返回结果:
"aggregations": {
"费用级别": {
"buckets": {
"便宜": { "to": 100.0, "doc_count": 20 },
"一般": { "from": 100.0, "to": 300.0, "doc_count": 385 },
"贵": { "from": 300.0, "doc_count": 92}
}
}
}