一、准备知识
1、LSN
LSN用来标识特定日志在日志文件中位置(详情请见什么是LSN:日志序列号),它由两部分组成:一部分用来标识VLF(虚拟日志文件)的序列号,剩下的用来标识该日志在VLF中的具体的位置。
根据LSN不同,日志一般分为两类:首日志(最新的活动日志序号)和尾日志(保留时间最长的活动日志序号)。随着数据库的操作不断增加(如数据库中的update操作),首日志LSN序号不断变化。尾日志的序号只有在日志备份后才会变化。
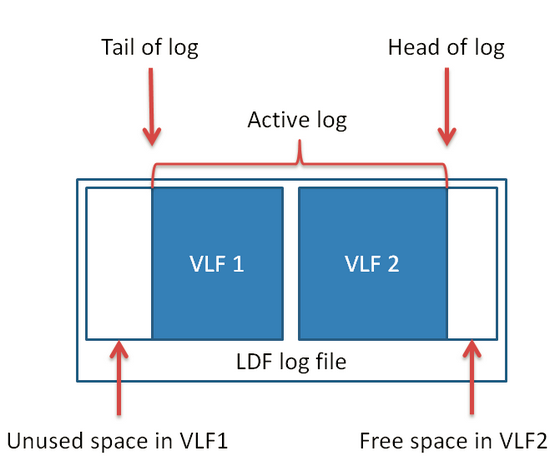
(图一)日志文件结构图
2、VLF
你可以通过DCC LOGINFO去分析数据库LDF中VLF(虚拟日志文件),LDF、VLF、日志的关系是:LDF包括多个VLF,每个VLF中包括多个日志记录。在VLF中,当事物日志增加时,日志的头部(首日志)不断向前移动,日志将占用越来越多的剩余空间,当这个VLF被占满后,新的日志写入到其他未被使用的VLF中,这个时候LDF并不会增大。当LDF中没有可用的VLF时,数据库会创建一个新的VLF。从而使得LDF文件物理增大,占用更多的磁盘空间。
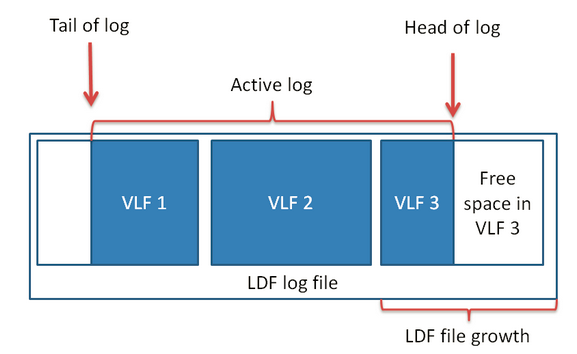
(图二)日志增长
二、解决方法详细阐述
1、日志的截断
上图演示了首日志向前移动的场景,结合图一和图二可以看到,当VLF2的空间被日志填满后,数据库扩充LDF文件(申请更多的磁盘空间),并在扩充后的LDF中新建一个VLF3用来填充新的日志记录。尽管VLF1中存在剩余空间,但因为VLF1中存在活动日志(哪怕只有一条),所以数据库无法利用这个VLF的剩余空间。
这个时候做日志备份就会发生日志截断的现象。一般会将截断理解为"删除"一些日志记录(非活动),实际上它只是意味着尾日志的向前移动:尾日志序号会被刷新成最小的活动日志序号,而从原来尾日志的位置到新位置之间的空间被标记为"可重新利用"。这个过程并不会减少LDF已占用的磁盘空间。如下图,整个VLF1的和部分VLF2上的日志(非活动)被截断了。
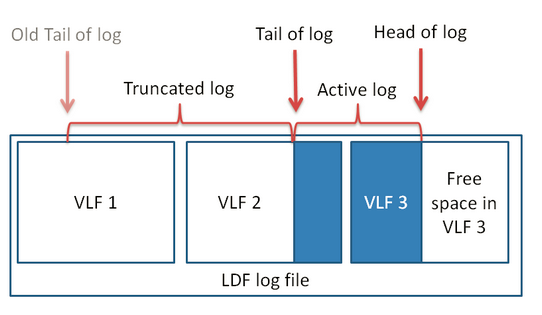
(图三)日志截断示意图
随着事务日志不断增加,VLF3中日志头部所在的位置将不断向前移动,当VLF3的空间被占满后,数据库会重新利用VLF1的空间,这种写入、截断、再写入的方式形成一个写日志的循环。在此期间LDF并不会物理上增大。
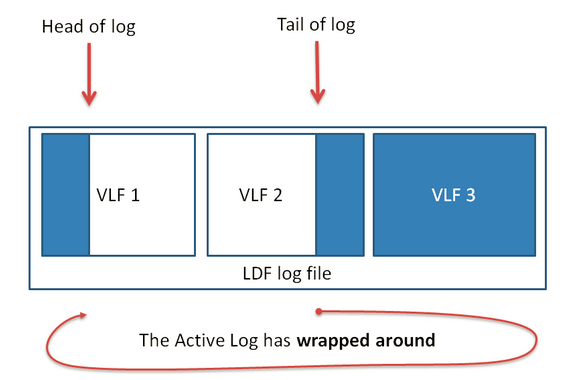
(图四)日志循环使用示意图
2、为什么日志不能收缩
现在我们再来看一个日志无法收缩的场景:
图四中,VLF1中的日志不断增加,直到VLF1的所有空间都被填满(如图五),此时因为没有发生截断,尾日志都在VLF2上,且VLF2和VLF3都被标记为不可重新利用,数据库只能扩充LDF、新建一个VLF4用来记录新的日志,首日志的位置将出现在VLF4中,整个写日志的(从图一到图四)顺序为VLF2——>VLF3——>VLF1——>VLF4。这个过程会导致数据库的日志文件在物理上增大。
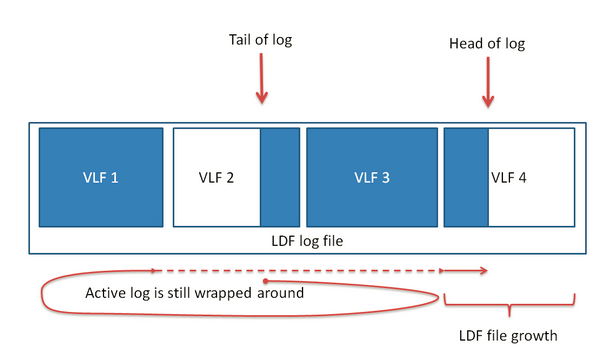
(图五)日志增长示意图
这时我们再来截断事物日志,如上文所说,尾日志的会被更新,最后可能出现尾日志和首日志在同一个VLF上的场景。从日志文件记录的架构上来看,我们可以将这个过程简单地理解为:截断的顺序会按照首日志移动的顺序移动,从VLF2——>VLF3——>VLF1——>VLF4,最终尾日志和首日志出现在同一个VLF上。
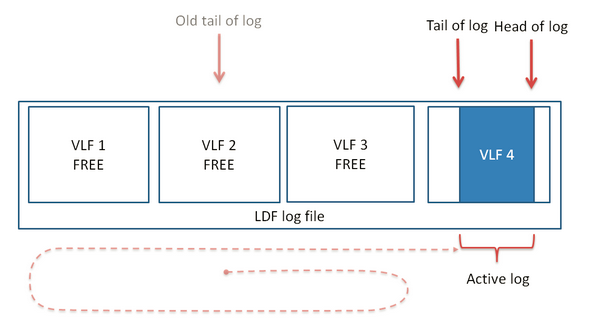
(图六)日志截断示意图二
如上图,这个LDF文件包括3个空的和1个只有小部分活动日志的VLF文件,首日志和尾日志在同一个VLF中,这种情况下,试图通过DBCC SHRINKFILE是不会减小LDF文件的大小的。
日志文件能被收缩的原因是该文件尾部的数据被清除了,使得该部分空间被释放,而不是逃过尾部去删除文件首部或者中间部分的内容。这点与MDF文件不同,MDF文件中的数据是不能被删除的,只能将文件尾部的数据迁移到其他区域的剩余空间上,然后释放尾部占用的空间。
在LDF中 ,日志是不能被迁移的,而且也没有迁移的必要,因为当事物被提交后,日志变为不活动状态,通过事物日志备份即可将其截断(特殊情况下日志备份不一定能截断,如发布订阅的环境)。
综上所述,日志文件能被收缩的前提是:日志文件的最后一个VLF必须是free状态,从后向前推,只要是free状态的VLF都会被收缩,据此可以估算一个日志文件可以释放的空间大小。
如下我们看一个实际的例子:
USE DBname
DBCC loginfo
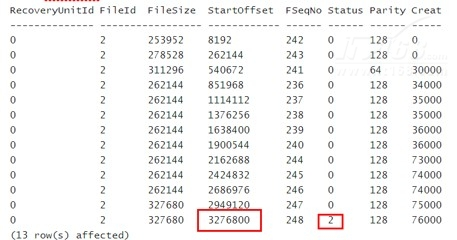
(图七)VLF状态示意图
从上图可以看到,这个数据库的日志文件共有13个VLF,其中有前12个处于free状态,最后1个处于活动状态,因此,我们可以推断首日志和尾日志的位置都在这个VLF上。这个时候执行文件收缩将看不到文件减小的效果。
3、如何解决这个问题
那么碰到这种情况,该怎么去收缩日志呢:尽可能多的执行一些能够产生大量日志的操作,这些日志将导致数据库重新利用startoffset靠前的非活动状态的VLF,将首日志的位置定位到这个startoffset,然后做一次事务日志备份,将尾日志也迁移到startoffset靠前的非活动状态的VLF中,如下图,最后再执行DBCC SHRINKFILE即可收缩日志文件。
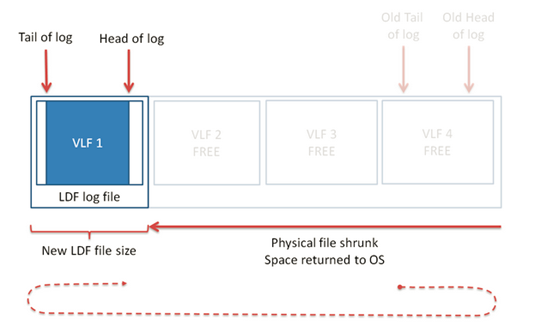
(图八)日志截断示意图三
三、重要说明
前文中一直在说通过日志备份即可解决日志截断的问题,其实这只是最简单的场景。在实际环境中可能有很多因素会影响日志的截断,如:
活动的事物日志
日志备份只能截断非活动的日志,如果一个事物长时间运行,此时备份事物日志将不会引起截断发生。
事物日志分发
事物日志分发中,只有当日志读取器代理已经读取完待分发的日志后,日志才能变得非活动状态。
数据库镜像和AlwaysOn
这两种数据库技术都需要将日志传递到接受端,在传递还没有完成时,日志会一直保留,即使是备份日志也无法截断。
四、Always on 环境下实践
先对数据库进行完整备份:
EXEC sp_configure 'show advanced options', 1;
RECONFIGURE;
EXEC sp_configure 'xp_cmdshell', 1;
RECONFIGURE;
DECLARE @DbName NVARCHAR(1000);
DECLARE myCursor CURSOR LOCAL STATIC
FOR
SELECT [name]
FROM sysdatabases
WHERE [name] NOT IN ( 'master', 'model', 'msdb', 'tempdb' )
AND name NOT LIKE '%test%'
AND name NOT LIKE '%bak%'
AND name NOT LIKE '%demo%'
AND version IS NOT NULL
AND version <> 0
ORDER BY [name];
OPEN myCursor;
FETCH NEXT FROM myCursor INTO @DbName;
WHILE ( @@FETCH_STATUS = 0 )
BEGIN
DECLARE @strDate AS NVARCHAR(20),
@strDateBeforeSeven AS NVARCHAR(20),
@strFileName AS NVARCHAR(255),
@strFileNameBeforeSeven AS NVARCHAR(255),
@strCommand AS NVARCHAR(255)
SET @strDate = CONVERT(NVARCHAR(20),GETDATE(),112);
SET @strDateBeforeSeven = CONVERT(NVARCHAR(20),GETDATE()-3,112);
SET @strFileName = 'E:daybak['+@DbName+']_bakup_'+@strDate;
SET @strFileNameBeforeSeven = 'E:daybak['+@DbName+']_bakup_'+@strDateBeforeSeven;
EXEC ('BACKUP DATABASE ['+@DbName+'] TO DISK = ''' + @strFileName + '.bak''')
SET @strCommand = 'DEL ' + @strFileNameBeforeSeven + '.bak'
EXEC master.dbo.xp_cmdshell @strCommand
FETCH NEXT FROM myCursor INTO @DbName;
END;
CLOSE myCursor;
DEALLOCATE myCursor;
然后对数据库进行事务日志备份并收缩:
EXEC sp_configure 'show advanced options', 1;
RECONFIGURE;
EXEC sp_configure 'xp_cmdshell', 1;
RECONFIGURE;
DECLARE @DbName NVARCHAR(1000);
DECLARE myCursor CURSOR LOCAL STATIC
FOR
SELECT [name]
FROM sysdatabases
WHERE [name] NOT IN ( 'master', 'model', 'msdb', 'tempdb' )
AND name NOT LIKE '%test%'
AND name NOT LIKE '%bak%'
AND name NOT LIKE '%demo%'
AND version IS NOT NULL
AND version <> 0
ORDER BY [name];
OPEN myCursor;
FETCH NEXT FROM myCursor INTO @DbName;
WHILE ( @@FETCH_STATUS = 0 )
BEGIN
DECLARE @strDate AS NVARCHAR(20),
@strDateBeforeSeven AS NVARCHAR(20),
@strFileName AS NVARCHAR(255),
@strFileNameBeforeSeven AS NVARCHAR(255),
@strCommand AS NVARCHAR(255)
SET @strDate = CONVERT(NVARCHAR(20),GETDATE(),112);
SET @strDateBeforeSeven = CONVERT(NVARCHAR(20),GETDATE()-3,112);
SET @strFileName = 'E:Log_daybak['+@DbName+']_bakup_'+@strDate;
SET @strFileNameBeforeSeven = 'E:Log_daybak['+@DbName+']_bakup_'+@strDateBeforeSeven;
EXEC ('BACKUP LOG ['+@DbName+'] TO DISK = ''' + @strFileName + '.log'';USE ['+@DbName+'];DBCC SHRINKFILE(2,100);')
SET @strCommand = 'DEL ' + @strFileNameBeforeSeven + '.log'
EXEC master.dbo.xp_cmdshell @strCommand
FETCH NEXT FROM myCursor INTO @DbName;
END;
CLOSE myCursor;
DEALLOCATE myCursor;