SVM有如下主要几个特点:
(1)非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射;
(2)对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思想是SVM方法的核心;
(3)支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量。
(4)SVM 是一种有坚实理论基础的新颖的小样本学习方法。它基本上不涉及概率测度及大数定律等,因此不同于现有的统计方法。从本质上看,它避开了从归纳到演绎的传统过程,实现了高效的从训练样本到预报样本的“转导推理”,大大简化了通常的分类和回归等问题。
(5)SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
(6)少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性。这种“鲁棒”性主要体现在:
①增、删非支持向量样本对模型没有影响;
②支持向量样本集具有一定的鲁棒性;
③有些成功的应用中,SVM 方法对核的选取不敏感
两个不足:
(1) SVM算法对大规模训练样本难以实施
由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。针对以上问题的主要改进有有J.Platt的SMO算法、T.Joachims的SVM、C.J.C.Burges等的PCGC、张学工的CSVM以及O.L.Mangasarian等的SOR算法
(2) 用SVM解决多分类问题存在困难
经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类的分类问题。可以通过多个二类支持向量机的组合来解决。主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决。主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的分类精度。如:与粗集理论结合,形成一种优势互补的多类问题的组合分类器。
应聘数据挖掘工程师或机器学习工程师,面试官经常会考量面试者对SVM的理解。
SVM的原理是什么?
SVM是一种二类分类模型。它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器。(间隔最大是它有别于感知机)
(1)当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机;
(2)当训练数据近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性支持向量机;
(3)当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
注:以上各SVM的数学推导应该熟悉:硬间隔最大化(几何间隔)---学习的对偶问题---软间隔最大化(引入松弛变量)---非线性支持向量机(核技巧)。
SVM为什么采用间隔最大化?
当训练数据线性可分时,存在无穷个分离超平面可以将两类数据正确分开。
感知机利用误分类最小策略,求得分离超平面,不过此时的解有无穷多个。
线性可分支持向量机利用间隔最大化求得最优分离超平面,这时,解是唯一的。另一方面,此时的分隔超平面所产生的分类结果是最鲁棒的,对未知实例的泛化能力最强。
然后应该借此阐述,几何间隔,函数间隔,及从函数间隔—>求解最小化1/2 ||w||^2 时的w和b。即线性可分支持向量机学习算法—最大间隔法的由来。
为什么要将求解SVM的原始问题转换为其对偶问题?
一、是对偶问题往往更易求解(当我们寻找约束存在时的最优点的时候,约束的存在虽然减小了需要搜寻的范围,但是却使问题变得更加复杂。为了使问题变得易于处理,我们的方法是把目标函数和约束全部融入一个新的函数,即拉格朗日函数,再通过这个函数来寻找最优点。)
二、自然引入核函数,进而推广到非线性分类问题。
为什么SVM要引入核函数?
当样本在原始空间线性不可分时,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
引入映射后的对偶问题:
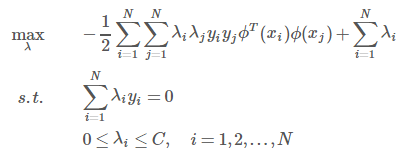
在学习预测中,只定义核函数K(x,y),而不是显式的定义映射函数ϕ。因为特征空间维数可能很高,甚至可能是无穷维,因此直接计算ϕ(x)·ϕ(y)是比较困难的。相反,直接计算K(x,y)比较容易(即直接在原来的低维空间中进行计算,而不需要显式地写出映射后的结果)。
核函数的定义:K(x,y)=<ϕ(x),ϕ(y)>,即在特征空间的内积等于它们在原始样本空间中通过核函数K计算的结果。
除了 SVM 之外,任何将计算表示为数据点的内积的方法,都可以使用核方法进行非线性扩展。
svm RBF核函数的具体公式?
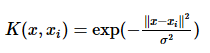
Gauss径向基函数则是局部性强的核函数,其外推能力随着参数σ的增大而减弱。
这个核会将原始空间映射为无穷维空间。不过,如果σ选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果σ选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数σ,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。
为什么SVM对缺失数据敏感?
这里说的缺失数据是指缺失某些特征数据,向量数据不完整。SVM没有处理缺失值的策略(决策树有)。而SVM希望样本在特征空间中线性可分,所以特征空间的好坏对SVM的性能很重要。缺失特征数据将影响训练结果的好坏。
SVM是用的是哪个库?Sklearn/libsvm中的SVM都有什么参数可以调节?
用的是sklearn实现的。采用sklearn.svm.SVC设置的参数。本身这个函数也是基于libsvm实现的(PS: libsvm中的二次规划问题的解决算法是SMO)。
SVC函数的训练时间是随训练样本平方级增长,所以不适合超过10000的样本。
对于多分类问题,SVC采用的是one-vs-one投票机制,需要两两类别建立分类器,训练时间可能比较长。
sklearn.svm.SVC(C=1.0,kernel='rbf',degree=3,gamma='auto',coef0=0.0,shrinking=True,probability=False,tol=0.001,cache_size=200,class_weight=None,verbose=False,max_iter=-1,decision_function_shape=None,random_state=None)
参数:
l C:C-SVC的惩罚参数C?默认值是1.0
C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
lkernel:核函数,默认是rbf,可以是‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
0 – 线性:u'v
1 – 多项式:(gamma*u'*v + coef0)^degree
2 – RBF函数:exp(-gamma|u-v|^2)
3 –sigmoid:tanh(gamma*u'*v + coef0)
ldegree:多项式poly函数的维度,默认是3,选择其他核函数时会被忽略。
lgamma:‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’,则会选择1/n_features
lcoef0:核函数的常数项。对于‘poly’和 ‘sigmoid’有用。
lprobability:是否采用概率估计?.默认为False
lshrinking:是否采用shrinking heuristic方法,默认为true
ltol:停止训练的误差值大小,默认为1e-3
lcache_size:核函数cache缓存大小,默认为200
lclass_weight:类别的权重,字典形式传递。设置第几类的参数C为weight*C(C-SVC中的C)
lverbose:允许冗余输出?
lmax_iter:最大迭代次数。-1为无限制。
ldecision_function_shape:‘ovo’, ‘ovr’ or None, default=None3
lrandom_state:数据洗牌时的种子值,int值
主要调节的参数有:C、kernel、degree、gamma、coef0。
SVM如何处理多分类问题?
一般有两种做法:一种是直接法,直接在目标函数上修改,将多个分类面的参数求解合并到一个最优化问题里面。看似简单但是计算量却非常的大。
另外一种做法是间接法:对训练器进行组合。其中比较典型的有一对一,和一对多。
一对多,就是对每个类都训练出一个分类器,由svm是二分类,所以将此而分类器的两类设定为目标类为一类,其余类为另外一类。这样针对k个类可以训练出k个分类器,当有一个新的样本来的时候,用这k个分类器来测试,那个分类器的概率高,那么这个样本就属于哪一类。这种方法效果不太好,bias比较高。
svm一对一法(one-vs-one),针对任意两个类训练出一个分类器,如果有k类,一共训练出C(2,k) 个分类器,这样当有一个新的样本要来的时候,用这C(2,k)个分类器来测试,每当被判定属于某一类的时候,该类就加一,最后票数最多的类别被认定为该样本的类。
机器学习关于支持向量机的面试题总结
2018年03月16日 21:07:08
阅读数:386
1.SVM的原理是什么?
SVM是一种二类分类模型。它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器。(间隔最大是它有别于感知机)
(1)当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机;
(2)当训练数据近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性支持向量机;
(3)当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
注:以上各SVM的数学推导应该熟悉:硬间隔最大化(几何间隔)---学习的对偶问题---软间隔最大化(引入松弛变量)---非线性支持向量机(核技巧)。
2.SVM为什么采用间隔最大化?
当训练数据线性可分时,存在无穷个分离超平面可以将两类数据正确分开。利用间隔最大化求得最优分离超平面,这时,解是唯一的。另一方面,此时的分隔超平面所产生的分类结果对未知实例的泛化能力最强。
3.为什么要将求解SVM的原始问题转换为其对偶问题?
一、是对偶问题往往更易求解,(当我们寻找约束存在时的最优点的时候,约束的存在虽然减小了需要搜寻的范围,但是却使问题变得更加复杂。为了使问题变得易于处理,我们的方法是把目标函数和约束全部融入一个新的函数,即拉格朗日函数,再通过这个函数来寻找最优点。)
(a)目前处理的模型严重依赖于数据集的维度d,如果维度d太高就会严重提升运算时间;
(b)对偶问题把SVM从依赖d个维度转变到依赖N个数据点,最后计算时只有支持向量有意义,所以计算量比N小很多。
二、自然引入核函数,进而推广到非线性分类问题。
4.为什么SVM要引入核函数?
当样本在原始空间线性不可分时,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。引入映射后的对偶问题:
在学习预测中,只定义核函数K(x,y),而不是显式的定义映射函数ϕ。因为特征空间维数可能很高,甚至可能是无穷维,因此直接计算ϕ(x)·ϕ(y)是比较困难的。相反,直接计算K(x,y)比较容易(即直接在原来的低维空间中进行计算,而不需要显式地写出映射后的结果)。
核函数的定义:K(x,y)=<ϕ(x),ϕ(y)>,即在特征空间的内积等于它们在原始样本空间中通过核函数K计算的结果。
除了 SVM 之外,任何将计算表示为数据点的内积的方法,都可以使用核方法进行非线性扩展。
5.svm RBF核函数的具体公式?
Gauss径向基函数则是局部性强的核函数,其外推能力随着参数σ的增大而减弱。
这个核会将原始空间映射为无穷维空间。不过,如果 σ 选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上相当于一个低维的子空间;反过来,如果 σ 选得很小,则可以将任意的数据映射为线性可分——当然这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数σ ,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。
6.为什么SVM对缺失数据敏感?
这里说的缺失数据是指缺失某些特征数据,向量数据不完整。SVM没有处理缺失值的策略(决策树有)。而SVM希望样本在特征空间中线性可分,所以特征空间的好坏对SVM的性能很重要。缺失特征数据将影响训练结果的好坏。
7.SVM是用的是哪个库?Sklearn/libsvm中的SVM都有什么参数可以调节?
用的是sklearn实现的。采用sklearn.svm.SVC设置的参数。本身这个函数也是基于libsvm实现的(PS: libsvm中的二次规划问题的解决算法是SMO)。
SVC函数的训练时间是随训练样本平方级增长,所以不适合超过10000的样本。
对于多分类问题,SVC采用的是one-vs-one投票机制,需要两两类别建立分类器,训练时间可能比较长。
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None,random_state=None)
参数:
C:C-SVC的惩罚参数C,默认值是1.0。C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
kernel :核函数,默认是rbf,可以是‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
0 – 线性:u'v
1 – 多项式:(gamma*u'*v + coef0)^degree
2 – RBF函数:exp(-gamma|u-v|^2)
3 –sigmoid:tanh(gamma*u'*v + coef0)
degree :多项式poly函数的维度,默认是3,选择其他核函数时会被忽略。
gamma : ‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’,则会选择1/n_features
coef0 :核函数的常数项。对于‘poly’和 ‘sigmoid’有用。
max_iter :最大迭代次数。-1为无限制。
decision_function_shape :‘ovo’, ‘ovr’ or None, default=None3
主要调节的参数有:C、kernel、degree、gamma、coef0。
8.SVM如何处理多分类问题?
一般有两种做法:
一种是直接法,直接在目标函数上修改,将多个分类面的参数求解合并到一个最优化问题里面。看似简单但是计算量却非常的大。
另外一种做法是间接法:对训练器进行组合。其中比较典型的有一对一,和一对多。
一对多,就是对每个类都训练出一个分类器,由svm是二分类,所以将此二分类器的两类设定为目标类为一类,其余类为另外一类。这样针对k个类可以训练出k个分类器,当有一个新的样本来的时候,用这k个分类器来测试,那个分类器的概率高,那么这个样本就属于哪一类。这种方法效果不太好,bias比较高。
一对一法(one-vs-one),针对任意两个类训练出一个分类器,如果有k类,一共训练出C(2,k) 个分类器,这样当有一个新的样本要来的时候,用这C(2,k) 个分类器来测试,每当被判定属于某一类的时候,该类就加一,最后票数最多的类别被认定为该样本的类。
10、 类和和少数类采用不同的惩罚因子,对正例和负例赋予不同的C值,例如正例远少于负例,则正例的C值取得较大,这种方法的缺点是可能会偏离原始数据的概率分布;
2)、对训练集的数据进行预处理即对数量少的样本以某种策略进行采样,增加其数量或者减少数量多的样本,典型的方法如:随机插入法,缺点是可能出现 overfitting,较好的是:Synthetic Minority Over-sampling TEchnique(SMOTE),其缺点是只能应用在具体的特征空间中,不适合处理那些无法用特征向量表示的问题,当然增加样本也意味着训练时间可能增加;
3)、基于核函数的不平衡数据处理。
11、样本失衡时,如何评价分类器的性能好坏?
答:使用ROC曲线
12、数据维度大于数据量的对SVM的影响?
答:这种情况下一般采用线性核(即无核),因为此时特征够用了(很大可能是线性问题),没必要映射到更高维的特征空间。
13、怎么用SVM解决多分类问题?参考1;参考2
答:1)一对一法:任意两类样本之间设计一个SVM,最终有k(k-1)/2个分类器,投票决定,libsvm是这么做的。虽然分类器多,但是训练总时间要比一对多的速度快,因为训练复杂度是跟样本量有关的。
2)一对多法:最终k个分类器,最终如果只有一个+1,则分为该类;如果有多个+1(分类重叠),则取wx+b的值最大的那个;如果没有+1(不可分),则分为其余类,会造成数据集倾斜问题。PS:当样本可以属于多个类别时,采取这种方式。
3)DAG法:用一对一的方法建立k(k-1)/2个分类器,然后将这些分类器建立成有向无环图(有点像二叉树);预测的时候,都只需要调用k-1个分类器;缺点是存在错误累积,一旦开始分类错的话,接下来就不可能分对了。所以第一个分类器一定要选好
14、数据不规范化对SVM的影响?参考
答:大值特征会掩盖小值特征(内积计算)。高斯核会计算向量间的距离,也会产生同样的问题;多项式核会引起数值问题。影响求解的速度。数据规范化后,会丢失一些信息。预测的时候,也要进行规范化,测试数据规划时,使用的最大值和最小值都是训练集的而不是测试集的。
15、如何处理离散型变量?参考
答:{red, green, blue} 可以表示为 (0,0,1), (0,1,0), and (1,0,0);这样向量的内积或距离才有真正意义。
16、如何选择核函数?参考1;参考2;参考3;参考4
答:线性核是高斯核的特例,对于特征非常多的情况下,应使用线性核。因为此时特征够用了(很大可能是线性问题),没必要映射到更高维的特征空间,线性核的训练速度快,而且一般情况下效果还不错,尤其是维度高的情况下。
sigmoid核在给定的参数下和高斯核相似
多项式核的参数太多;对于高斯核0<Kij<1,而多项式核则可能会出现无穷大或无穷小;
其他核需要调参(使用交叉验证),所以速度慢。
高斯核必然映射到无穷维,因为核函数的泰勒展开有无穷多项。
17、为什么SVM训练的时候耗内存,而预测的时候占内存少?
答:因为SVM训练过程中需要存储核矩阵。而预测的时候只需要存储支持向量和相关参数。
详细回答:算法最耗时的地方是优化乘子的选择和更新一阶导数信息,这两个地方都需要去计算核函数值,而核函数值的计算最终都需要去做内积运算,这就意味着原始空间的维度很高会增加内积运算的时间;对于dense matrix我就直接用numpy的dot了,而sparse matrix采用的是CSR表示法,求它的内积我实验过的方法有三种,第一种不需要额外空间,但时间复杂度为O(nlgn),第二种需要一个hash表(用dictionary代替了),时间复杂度为线性,第三种需要一个bitmap(使用BitVector),时间复杂度也为线性,实际使用中第一种速度最快,我就暂时用它了,应该还有更快的方法,希望高人们能指点一下;另外由于使用dictionary缓存核矩阵,遇到训练数据很大的数据集很容易挂掉,所以在程序中,当dictionary的内存占用达到配置文件的阈值时会将其中相对次要的元素删掉,保留对角线上的内积值。
18、在SMO中,什么叫违反KKT条件最严重的?
答:每一个α对应一个样本,而KKT条件是样本和对应的α应该满足的关系。所谓违反最严重是指α对应的样本错得最离谱
19、SVM适合处理什么样的数据?
答:高维稀疏,样本少。【参数只与支持向量有关,数量少,所以需要的样本少,由于参数跟维度没有关系,所以可以处理高维问题】高维问题还可以另外一个角度来思考,假设给定一个训练数据集,其特征是少量的,那么很可能需要映射到高维空间才能求解,那么这个问题就是一个高维问题
20、线性核VS多项式核VS径向基核?
答:1)训练速度:线性核只需要调节惩罚因子一个参数,所以速度快;多项式核参数多,难调;径向基核函数还需要调节γ,需要计算e的幂,所以训练速度变慢。【调参一般使用交叉验证,所以速度会慢】
2)训练结果:线性核的得到的权重w可以反映出特征的重要性,从而进行特征选择;多项式核的结果更加直观,解释性强;径向基核得到权重是无法解释的。
3)适应的数据:线性核:样本数量远小于特征数量(n<<m)【此时不需要映射到高维】,或者样本数量与特征数量都很大【此时主要考虑训练速度】;径向基核:样本数量远大于特征数量(n>>m)
21、径向基核函数中参数的物理意义
答:如果σ选得很大的话,高次特征上的权重实际上衰减得非常快,使用泰勒展开就可以发现,当很大的时候,泰勒展开的高次项的系数会变小得很快,所以实际上相当于一个低维的子空间;
如果σ选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题,因为此时泰勒展开式中有效的项将变得非常多,甚至无穷多,那么就相当于映射到了一个无穷维的空间,任意数据都将变得线性可分