Python 标准数据库接口为 Python DB-API,Python DB-API为开发人员提供了数据库应用编程接口。它定义了一系列必须的对象和数据库存取方式, 以便为各种各样的底层数据库系统和多种多样的数据库接口程序提供一致的访问接口 。Python 数据库接口支持非常多的数据库,MySQL 、 PostgreSQL、Microsoft SQL Server 2000、 Informix 、Interbase、Oracle 、Sybase。如通过python连接MySQL可以通过以下python库:
MySQLdb
MySQLdb 是用于Python链接Mysql数据库的接口,它实现了 Python 数据库 API 规范 V2.0,基于 MySQL C API 上建立的。MySQLdb又叫MySQL-python ,是 Python 连接 MySQL 最流行的一个驱动,很多框架也是依据其开发的。只支持python2.x。
Mysqlclient
完全兼容MySQLdb的衍生版;同时兼容Python3.x,原生SQL操作数据库。由于MySQLdb年久失修,后来出现了它的 Fork 版本 mysqlclient,完全兼容 MySQLdb
PyMysql
纯Python实现的驱动。速度不如MySQLdb,兼容MySQLdb,推荐使用PyMysql连接mysql
一、SQLite
SQLite是一种嵌入式数据库,SQLite本身是C写的体积很小,它的数据库就是一个文件,所以经常被集成到各种应用程序中,甚至在iOS和Android的App中都可以集成。Python内置了sqlite3。
#coding:utf-8 import sqlite3 conn = sqlite3.connect('test.db') cursor = conn.cursor() # sqlite创建表时,若id为INTEGER类型且为主键,可以自动递增,在插入数据时id填NULL即可 # cursor.execute('create table user(id integer primary key, name varchar(25))') #执行一次 # 插入一条数据 cursor.execute('insert into user(id,name)values(NULL,"yjc")') # 返回影响的行数 print(cursor.rowcount) #提交事务,否则上述SQL不会提交执行 conn.commit() # 执行查询 cursor.execute('select * from user') # 获取查询结果 print(cursor.fetchall()) # 关闭游标和连接 cursor.close() conn.close()
输出:
1
[(1, 'yjc'), (2, 'yjc')]我们发现Python里封装的数据库操作很简单:
1、获取连接conn;
2、获取游标cursor;
3、使用cursor.execute()执行SQL语句;
4、使用cursor.rowcount返回执行insert,update,delete语句受影响的行数;
5、使用cursor.fetchall()获取查询的结果集。结果集是一个list,每个元素都是一个tuple,对应一行记录;
6、关闭游标和连接。
如果SQL语句带有参数,那么需要把参数按照位置传递给cursor.execute()方法,有几个?占位符就必须对应几个参数,示例:
cursor.execute('select * from user where name=? ', ['abc'])
为了能在出错的情况下也关闭掉Connection对象和Cursor对象,建议实际项目里使用try:...except:...finally:...结构。
二、Mysql
1. 安装 PyMysql 库
pip3 install pymysql
2. 连接数据库的几种方法
connect()方法用于连接数据库
第一种:将各类字段写上
db = pymysql.connect(host="localhost", port=3306, user="root", passwd="root", db="Geek_Web", charset="utf8mb4")
第二种:省略字段
db = pymysql.connect(root,root, Geek_Web)
第三种:构建配置文件
config = {
'host':'localhost',
'port':3306,
'user':'root',
'passwd':'root',
'db':'Geek_Web',
'charset':'utf8mb4',
}
db = pymysql.connect(**config)
3. 操作数据库
cursor = db.cursor() # cursor() 方法获取操作游标
sql = "SELECT * FROM main"
cursor.execute(sql) # 执行SQL语句
results = cursor.fetchall() # 获取所有记录列表
results = cursor.fetchone() # 获取一条记录列表
db.commit() # 没有设置默认自动提交,需要主动提交,以保存所执行的语句
# 除了查询其他操作都需要保存执行
cursor.close()
db.close() # 关闭数据库连接
4. PyMysql 返回字典数据
PyMysql 默认返回是元组,有时候需要返回数据库的字段,需要把 Key 也返回及返回字典类型
# 在连接数据库时候加上 cursorclass 就可以数据库内容以字典格式返回
cursorclass=pymysql.cursors.DictCursor
5. 源码实例
#!/usr/bin/env python3 # -*- coding: UTF-8 -*- # 安装PyMySQL # sudo pip install PyMySQL import pymysql config = { 'host':'localhost', 'port':3306, 'user':'root', 'passwd':'root', 'db':'Geek_Web', 'charset':'utf8mb4', # 数据库内容以字典格式输出 #'cursorclass':pymysql.cursors.DictCursor, } # 连接数据库 def Mysql(): # 连接数据库 #db = pymysql.connect(host="localhost", port=3306, user="root", passwd="root", db="Geek_Web", charset="utf8mb4") db = pymysql.connect(**config) #cursor()方法获取操作游标 cursor = db.cursor() try: return (db, cursor) except: print("数据库访问失败") # 增 def Insert(db, cursor): sql = "insert into main(id, Tag, Name, Version, Introduce, Class, Worked_OS, Course_URL, Download_URL, Image_URL, Remarks_1, Remarks_2) values (NULL, '软件编号', '软件名称', '软件版本', '软件简介', '软件类别', '运行环境', '教程地址', '下载地址', '图标地址', '备注1', '备注2')" # 执行SQL语句 cursor.execute(sql) # 没有设置默认自动提交,需要主动提交,以保存所执行的语句 db.commit() # 删 def Delect(db, cursor): sql = "DELETE FROM main WHERE Name = '修改后的名字'" cursor.execute(sql) db.commit() # 查 def Select(db, cursor): sql = "SELECT * FROM main" cursor.execute(sql) # 获取所有记录列表 results = cursor.fetchall() return results # 改 def Update(db, cursor): sql = "UPDATE main SET Name = '修改后的名字' WHERE Remarks_2 = '备注2'" cursor.execute(sql) db.commit() # 关闭数据库连接 def Close(db, cursor): cursor.close() db.close() (db, cursor) = Mysql() print(" -------------数据库初始状态-------------") print(Select(db, cursor)) Insert(db, cursor) print(" -------------数据库插入数据-------------") print(Select(db, cursor)) Update(db, cursor) print(" -------------数据库修改数据-------------") print(Select(db, cursor)) Delect(db, cursor) print(" -------------数据库删除数据-------------") print(Select(db, cursor)) Close(db, cursor)
6. pymysql使用:
三、Mssql
1. 安装 PyMssql 库
pip3 install pymysql
2. 连接数据库的方法
Mssql 用字典配置不可以用,connect() 用来连接数据库
db = pymssql.connect(host="192.0.0.200",user="ymyg",password="ymyg",database="Geek_Web")
3. 操作数据库
和 Mysql 操作方法一模一样,只不过将 PyMysql 改为 PyMssql 即可,参考上面 PyMssql
4. PyMssql 返回字典数据
只需要在连接数据库时候加上一个 as_dict 字段,将值改为 True 即可
db = pymssql.connect(host="192.0.0.200",user="ymyg",password="ymyg",database="Geek_Web",as_dict=True)
5.连接示例
import time import pymssql #import decimal class MSSQL: def __init__(self,host,user,pwd,db): self.host=host self.user=user self.pwd=pwd self.db=db def GetConnect(self): if not self.db: raise(NameError,'没有目标数据库') self.connect=pymssql.connect(host=self.host,user=self.user,password=self.pwd,database=self.db,charset='utf8') cur=self.connect.cursor() if not cur: raise(NameError,'数据库访问失败') else: return cur def ExecSql(self,sql): cur=self.GetConnect() cur.execute(sql) self.connect.commit() self.connect.close() def ExecQuery(self,sql): cur=self.GetConnect() cur.execute(sql) resList = cur.fetchall() self.connect.close() return resList def main(): ms = MSSQL(host="192.168.0.108", user="sa", pwd="sa", db="ComPrject") resList = ms.ExecQuery("select *from TestModel") print(resList) if __name__ == '__main__': main() input("执行完成:")
5. PyMssql 参数
connect() 参数
- dsn 连接字符串 主要用于与之前版本的pymssql兼容
- user 用户名
- password 密码
- trusted 布尔值 指定是否使用windows身份认证登陆
- host 主机名
- database 数据库
- timeout 查询超时
- login_timeout 登陆超时
- charset 数据库的字符集
- as_dict 布尔值 指定返回值是字典还是元组
- max_conn 最大连接数
操作方法
- close() 关闭游标
- execute(operation) 执行操作
- execute(operation params) 执行操作 可以提供参数进行相应操作
- executemany(operation paramsseq) 执行操作 Paramsseq 为元组
- fetchone() 在结果中读取下一行
- fetchmany(size=None) 在结果中读取指定数目的行
- fetchall() 读取所有行
- nextset() 游标跳转到下一个数据集
其他方法
- autocommit(status) 布尔值 指示是否自动提交事务 默认的状态是关闭的 如果打开 你必须调用commit()方法来提交事务
- close() 关闭连接
- cursor() 返回游标对象 用于查询和返回数据
- commit() 提交事务
- rollback() 回滚事务
- pymssqlCursor类 用于从数据库查询和返回数据
- rowcount 返回最后操作影响的行数
- connection 返回创建游标的连接对象
- lastrowid 返回插入的最后一行
- rownumber 返回当前数据集中的游标(通过索引)
6. PyMssql 配置文件
在目录下找到 freetds.conf
四、Oracle
连接Oracle比MySQL麻烦一些,连接Oracle需要安装cx_Oracle和oracle客户端
1. 安装 cx_Oracle 库
pip3 install cx_Oracle
2.
Oracle instant client 下载安装
1、下载
下载地址(官网下载需要登录Oracle账户,注册过程比较简单):http://www.oracle.com/technetwork/database/features/instant-client/index-097480.html
2、解压安装
解压下载的压缩包,并将对应的解压位置加入系统变量Path中(计算机->属性->高级系统设置->环境变量->系统变量->编辑系统变量->将解压后的路径加在后面)
关于系统变量的配置详细可参考:http://jingyan.baidu.com/article/3ea51489e1c2b752e61bbad0.html
将Oracle instant client目录下的oraocci12.dll、oraociei12.dll、oci.dll复制到python安装目
3. 连接数据库的几种方法
第一种:Oracle 连接方法
db = cx_Oracle.connect('root/root@localhost: 1523/orcl')
第二种:省略字段连接方法
db = cx_Oracle.connect('root', 'root', 'localhost: 1523/orcl')
第三种:dsn 方法
makedsn(IP/HOST, PORT, TNSNAME)
dsn = cx_Oracle.makedsn('localhost','1523','orcl')
db = cx_Oracle.connect('root','root',dsn)
4. 操作数据库
和 Mysql 操作方法一模一样,只不过将 PyMysql 改为 cx_Oracle 即可
5. PyMssql 返回字典数据
Oracle 返回字典类型比较麻烦,因为 cx_Oracle 没有集成,所以需要我们自己写返回字典的方法
cx_Oracle 的 Cursor 对象有一个属性 rowfactory 是是用来自定义查询结果的预处理方法的,定义一个闭包
def makedict(cursor):
cols = [d[0] for d in cursor.description]
def createrow(*args):
return dict(zip(cols, args))
return createrow
并将其注册给游标对象的rowfactory属性 cursor.rowfactory = makedict(cursor) 得到的结果自动由元组转为字典了,但要注意,注册的动作需要在每次执行 cursor.execute 之后都重复一次。最终的方法是定义了一个类来继承 Cursor 对象,这样就不需要重复注册了
6.连接示例
import cx_Oracle #连接数据库,下面括号里内容根据自己实际情况填写 conn = cx_Oracle.connect('用户名/密码@IP:端口号/SERVICE_NAME') # 使用cursor()方法获取操作游标 cursor = conn.cursor() #使用execute方法执行SQL语句 result=cursor.execute('Select member_id from member') #使用fetchone()方法获取一条数据 #data=cursor.fetchone() #获取所有数据 all_data=cursor.fetchall() #获取部分数据,8条 #many_data=cursor.fetchmany(8) print (all_data) db.close()
# -*- coding: UTF-8 -*- import cx_Oracle as oracle import sys import os import io sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8') os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8' class ExportOracle: def __init__(self,odbc,user): self.odbc = odbc self.user = user def start(self): db = oracle.connect(self.odbc) cursor = db.cursor() cursor.execute("SELECT NAME,AGE FROM USERS ") datas = cursor.fetchall() print(datas) if __name__ == '__main__': orcleDb_config = { 'odbc':'TEST_XIAOYI/TEST_XIAOYI@192.168.1.1:1521/orcl', 'user': 'TEST_XIAOYI', } mtables = ExportOracle(orcleDb_config['odbc'],orcleDb_config['user']); mtables.start();
五、ORM
ORM将数据库中的表与面向对象语言中的类建立了一种映射关系,ORM可以说是参照映射来处理数据的模型,比如说:需要创建一个表,可以定义一个类,而这个类存在与表相映射的属性,那么可以通过操作这个类来创建一个表,写原生 SQL 的过程非常繁琐,代码重复,有了 ORM 你不再需要写 SQL 语句。ORM兼容多种数据库系统,如sqlite, mysql、postgresql。
Peewee
Peewee是一个简单小巧的Python ORM
SQLAlchemy
既支持原生 SQL,又支持 ORM 的工具;如果想找一种既支持原生 SQL,又支持 ORM 的工具,那么 SQLAlchemy 是最好的选择。推荐使用SQLAlchemy。
六、Peewee
Peewee中Model类、fields和model实例与数据库的映射关系如下:
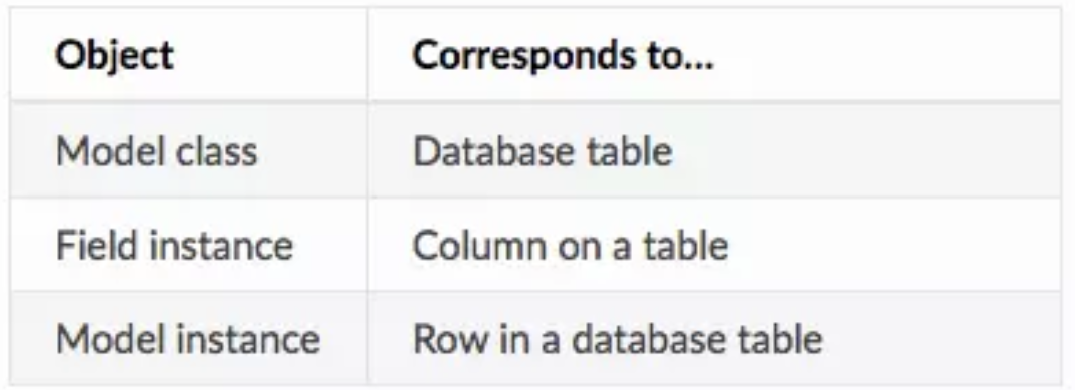
也就是说,一个Model类代表一个数据库的表,一个Field字段代表数据库中的一个字段,而一个model类实例化对象则代表数据库中的一行。
定义Model,建立数据库
在使用的时候,根据需求先定义好Model,然后可以通过create_tables()创建表,若是已经创建好数据库表了,可以通过python -m pwiz脚本工具直接创建Model。
第一种方式:
先定义Model,然后通过db.create_tables()创建或Model.create_table()创建表。
例如,我们需要建一个Person表,里面有name、birthday和is_relative三个字段,我们定义的Model如下:
from peewee import *
# 连接数据库
database = MySQLDatabase('test', user='root', host='localhost', port=3306)
# 定义Person
class Person(Model):
name = CharField()
birthday = DateField()
is_relative = BooleanField()
class Meta:
database = database
然后,我们就可以创建表了
# 创建表
Person.create_table()
# 创建表也可以这样, 可以创建多个
# database.create_tables([Person])
其中,CharField、DateField、BooleanField等这些类型与数据库中的数据类型一一对应,我们直接使用它就行,至于CharField => varchar(255)这种转换Peewee已经为我们做好了 。
第二种方式:
已经存在过数据库,则直接通过python -m pwiz批量创建Model。
例如,上面我已经创建好了test库,并且创建了Person表,表中拥有id、name、birthday和is_relative字段。那么,我可以使用下面命令:
# 指定mysql,用户为root,host为localhost,数据库为test
python -m pwiz -e mysql -u root -H localhost --password test > testModel.py
然后,输入密码,pwiz脚本会自动创建Model,内容如下:
from peewee import *
database = MySQLDatabase('test', **{'charset': 'utf8', 'use_unicode': True, 'host': 'localhost', 'user': 'root', 'password': ''})
class UnknownField(object):
def __init__(self, *_, **__): pass
class BaseModel(Model):
class Meta:
database = database
class Person(BaseModel):
birthday = DateField()
is_relative = IntegerField()
name = CharField()
class Meta:
table_name = 'person'
操作数据库
操作数据库,就是增、删、改和查。
1、增
直接创建示例,然后使用save()就添加了一条新数据
# 添加一条数据
p = Person(name='liuchungui', birthday=date(1990, 12, 20), is_relative=True)
p.save()
2、删
使用delete().where().execute()进行删除,where()是条件,execute()负责执行语句。若是已经查询出来的实例,则直接使用delete_instance()删除。
# 删除姓名为perter的数据
Person.delete().where(Person.name == 'perter').execute()
# 已经实例化的数据, 使用delete_instance
p = Person(name='liuchungui', birthday=date(1990, 12, 20), is_relative=False)
p.id = 1
p.save()
p.delete_instance()
3、改
若是,已经添加过数据的的实例或查询到的数据实例,且表拥有primary key时,此时使用save()就是修改数据;若是未拥有实例,则使用update().where()进行更新数据。
# 已经实例化的数据,指定了id这个primary key,则此时保存就是更新数据
p = Person(name='liuchungui', birthday=date(1990, 12, 20), is_relative=False)
p.id = 1
p.save()
# 更新birthday数据
q = Person.update({Person.birthday: date(1983, 12, 21)}).where(Person.name == 'liuchungui')
q.execute()
4、查
单条数据使用Person.get()就行了,也可以使用Person.select().where().get()。
若是查询多条数据,则使用Person.select().where(),去掉get()就行了。语法很直观,select()就是查询,where是条件,get是获取第一条数据。
# 查询单条数据
p = Person.get(Person.name == 'liuchungui')
print(p.name, p.birthday, p.is_relative)
# 使用where().get()查询
p = Person.select().where(Person.name == 'liuchungui').get()
print(p.name, p.birthday, p.is_relative)
# 查询多条数据
persons = Person.select().where(Person.is_relative == True)
for p in persons:
print(p.name, p.birthday, p.is_relative)七、SQLAlchemy
使用 sqlalchemy 有3种方式:
方式1, 使用raw sql;
方式2, 使用SqlAlchemy的sql expression;
方式3, 使用ORM.
前两种方式可以统称为 core 方式. 对于绝大多数应用, 推荐使用raw sql
通过 engine = create_engine("dialect+driver://username:password@host:port/database")初始化连接
参数说明:
- dialect,是数据库类型包括:sqlite, mysql, postgresql, oracle, mssql等
- driver,指定连接数据库的API,如:`psycopg2``, ``pyodbc``, ``cx_oracle``等,为可选关键字。
- username,用户名
- password,密码
- host,网络地址,可以用ip,域名,计算机名,当然是你能访问到的。
- port,数据库端口。
- database,数据库名称。
例如
建立mysql的连接方式为:engine = create_engine("mysql://scott:tiger@hostname/dbname",encoding='utf-8', echo=True)
(echo=True,会显示在加载数据库所执行的SQL语句,可不选此参数,默认为False)
建立oracle的连接方式为:engine = create_engine("oracle://scott:tiger@hostname/dbname",encoding='utf-8', echo=True)
常用的数据库连接字符串
#sqlite
sqlite_db = create_engine('sqlite:////absolute/path/database.db3')
sqlite_db = create_engine('sqlite://') # in-memory database
sqlite_db = create_engine('sqlite:///:memory:') # in-memory database
# postgresql
pg_db = create_engine('postgres://scott:tiger@localhost/mydatabase')
# mysql
mysql_db = create_engine('mysql://scott:tiger@localhost/mydatabase')
# oracle
oracle_db = create_engine('oracle://scott:tiger@127.0.0.1:1521/sidname')
一些非主流数据库缺少DB API接口,比如teradata, 没有专门的DB API实现, 但 odbc driver肯定会提供的. pypyodbc + ODBC driver 应该是一个选项.
sqlalchemy访问数据库的示例
from sqlalchemy import Column, String, create_engine from sqlalchemy.orm import sessionmaker from sqlalchemy.ext.declarative import declarative_base Base = declarative_base() class User(Base): # 表的名字 __tablename__ = 'user' # 表的结构 id = Column(String(20), primary_key=True) name = Column(String(20)) # 初始化数据库连接 engine = create_engine('mysql+mysqlconnector://root:111111@localhost:3306/test') # 创建DBSession类型 DBSession = sessionmaker(bind=engine) # create_engine用来初始化数据库连接. # SQLAlchemy用一个字符串表示连接信息'数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名' # # 创建session对象: # session = DBSession() # # 创建新User对象 # new_user = User(id='5', name='Bob') # # 添加到session # session.add(new_user) # # 提交保存到数据库 # session.commit() # # 关闭session # session.close() # 可见将关键是获取session, 然后把对象添加到session, 最后提交并关闭.(DBSession对象, 可以看做是当前数据库的连接) # 查询 session = DBSession() # 创建Query查询, filter是where条件, 最后调用one()返回唯一行, 如果调用all()则返回所有行. user = session.query(User).filter(User.id=='5').one() print('type:', type(user)) print('name:', user.name) session.close() # ORM就是把数据库表的行与相应的对象简历关联, 互相转换. # 由于关系数据库的多个表还可以用外键实现一对多, 多对多的关联, 相应地, ORM框架也可以提供两个对象之间的一对多, 多对多功能.
1、连接数据库 在sqlalchemy中,session用于创建程序与数据库之间的会话。所有对象的载入和保存都需要通过session对象。 from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker # 链接数据库采用pymysq模块做映射,后面参数是最大连接数5 ENGINE=create_engine("mysql+pymysql://root@127.0.0.1:3306/digchouti?charset=utf8", max_overflow=5) Session = sessionmaker(bind=engine) session = Session() 2、创建映射(创建表) 一个映射对应着一个Python类,用来表示一个表的结构。下面创建一个person表,包括id和name两个字段。也就是说创建表就是用python的的类来实现 import sqlalchemy from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String from sqlalchemy.orm import sessionmaker ENGINE=create_engine("mysql+pymysql://root@127.0.0.1:3306/digchouti?charset=utf8", max_overflow=5) #生成一个SQLORM基类,创建表必须继承他,别问我啥意思就是这么规定的 Base = declarative_base() class Person(Base): __tablename__ = 'userinfo' id = Column(Integer, primary_key=True) name = Column(String(32)) def __repr__(self): return "<Person(name='%s')>" % self.name 此代码是创建了一个名字叫userinfo的表,表里有两列,一列是id,一列是name。 3、添加数据 当然我们创建了表,肯定也要添加数据,代码如下: #创建一个person对象 person = Person(name='张三') #添加person对象,但是仍然没有提交到数据库 session.add(person) #提交数据库 session.commit() 当然还能添加多条数据: session.add_all([ Person(name='张三'), Person(name='aylin') ]) session.commit()
4、查找数据 在sqlalchemy模块中,查找数据给提供了query()的方法 下面我就把能用到的给列举一下: #获取所有数据 session.query(Person).all() #获取name=‘张岩林’的那行数据 session.query(Person).filter(Person.name=='张三').one() #获取返回数据的第一行 session.query(Person).first() #查找id大于1的所有数据 session.query(Person.name).filter(Person.id>1).all() #limit索引取出第一二行数据 session.query(Person).all()[1:3] #order by,按照id从大到小排列 session.query(Person).ordre_by(Person.id) #equal/like/in query = session.query(Person) query.filter(Person.id==1).all() query.filter(Person.id!=1).all() query.filter(Person.name.like('%ay%')).all() query.filter(Person.id.in_([1,2,3])).all() query.filter(~Person.id.in_([1,2,3])).all() query.filter(Person.name==None).all() #and or from sqlalchemy import and_ from sqlalchemy import or_ query.filter(and_(Person.id==1, Person.name=='张三')).all() query.filter(Person.id==1, Person.name=='张三').all() query.filter(Person.id==1).filter(Person.name=='张三').all() query.filter(or_(Person.id==1, Person.id==2)).all() # count计算个数 session.query(Person).count() # 修改update session.query(Person).filter(id > 2).update({'name' : '张三'}) # 通配符 ret = session.query(Users).filter(Users.name.like('e%')).all() ret = session.query(Users).filter(~Users.name.like('e%')).all() # 限制 ret = session.query(Users)[1:2] # 排序 ret = session.query(Users).order_by(Users.name.desc()).all() ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() # 分组 from sqlalchemy.sql import func ret = session.query(Users).group_by(Users.extra).all() ret = session.query( func.max(Users.id), func.sum(Users.id), func.min(Users.id)).group_by(Users.name).all() ret = session.query( func.max(Users.id), func.sum(Users.id), func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all() # 连表 ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all() ret = session.query(Person).join(Favor).all() ret = session.query(Person).join(Favor, isouter=True).all() # 组合 q1 = session.query(Users.name).filter(Users.id > 2) q2 = session.query(Favor.caption).filter(Favor.nid < 2) ret = q1.union(q2).all() q1 = session.query(Users.name).filter(Users.id > 2) q2 = session.query(Favor.caption).filter(Favor.nid < 2) ret = q1.union_all(q2).all()