在我们日常开发过程中,一般不会直接使用命令行来操作 MYSQL 数据库,而会选择一些图形化界面去帮助我们来进行此类操作,常用的有:SQLyog(Logo也是小海豚),Navicat,或者直接使用编辑器自带的图形化界面工具。我这边开发使用的是 Navicat,在日常使用的时候出现过一下的问题:
Too Many Connections - 1040
在 Navicat 的界面中,这是一个很讨人厌的提示框,多人协作开发的时候经常出现。原因有二:
一是 Mysql 数据库的默认最大连接数是:151,
二是 对于多人开发的单体项目来说,虽然我们同时在用的连接不会超过10个,理论上100 绰绰有余,但是除了我们正在使用的连接以外,还有很大一部分 Sleep 的连接,这个才是真正的罪魁祸首。
分析到了问题的根源,我们就需要对症下药,依次解决:
修改 Mysql 最大连接数量
首先查看当前 Mysql 最大连接数量是多少:
show variables like '%max_connections%';
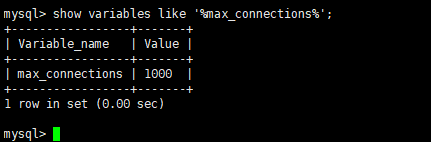
这里我已经修改过了,所以是 1000,没有改过的童鞋应该还是 100,
然后查看从这次 mysql 服务启动到现在,同一时刻并行连接数的最大值:
show status like 'Max_used_connections';
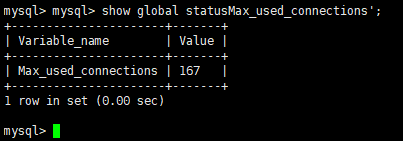
对于 Mysql 的最大连接数设置,在首次配置的时候设置一个较大的数值,以后在使用的过程中,周期的查询 Max_used_connections 然后根据他的值和服务器的性能确定一个最适合当前项目的最大连接数
最大连接数的修改有两种方式
- 使用 sql 语句(立即生效,但服务器重启后失效):
set global max_connections = 1000;

- 修改 /etc/my.cnf.添加 max_connections = 1000 永久有效。重启后生效
但更改最大连接数只能从表面上解决问题,随着我们开发人员的增多,Sleep 连接也会更多,到时候万一又达到了 1000 的上限,难道我们又得改成 10000 吗?这显然是非常不可取的。所以我们不仅要治标,还要治本。杀掉多余的 Sleep 连接就是治本
杀掉Sleep连接
我们可以通过 show_processlist 命令来查看当前的所有连接状态
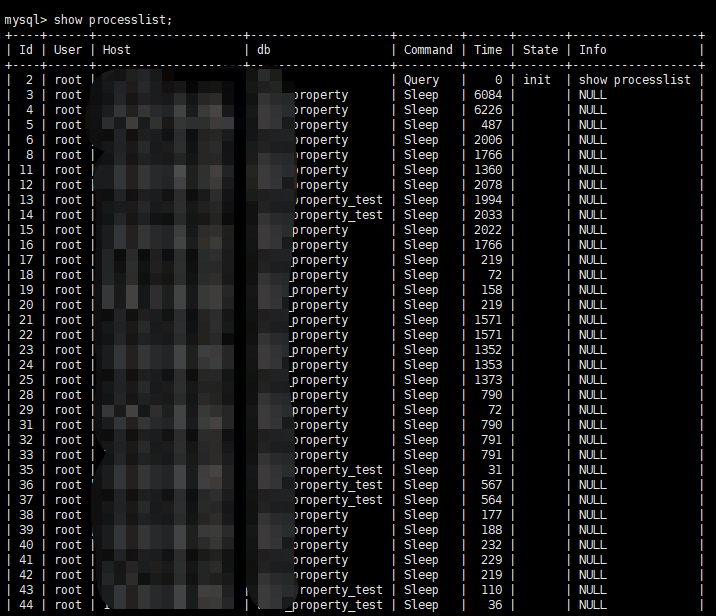
可以发现, Sleep 的连接占了绝大多数。
Mysql 数据库有一个属性 wait_timeout 就是 sleep 连接最大存活时间,默认是 28800 s,换算成小时就是 8 小时,我的天呐!这也太长了!严重影响性能。相当于今天上班以来所有建立过而未关闭的连接都不会被清理。
执行命令:
show global variables like '%wait_timeout';
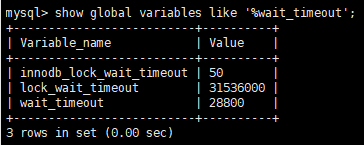
我们将他修改成一个合适的值,这里我改成了 250s。当然也可以在配置文件中修改,添加 wait_timeout = 250。这个值可以根据项目的需要进行修改,以 s 为单位。我在这里结合 navicat 的超时请求机制配置了 240s。
执行命令:
set global wait_timeout=250;
这样,就能从根本上解决 Too Many Connections 的问题了
正在准备...
我们在使用 Navicat 的时候,有时候查询完一次数据之后,就去编写代码,等下次回来的打开表的时候就会出现:正在准备... 等字样,这次查询可能会消耗 20s 以上的时间,这是不能容忍的。
这个时候我们就需要想办法解决他了,首先我想到的是 mysql 的 connection 连接被清理了,通过复现 正在准备... 并同时在 linux 通过 show processlist 命令查看连接状态发现,并不是。这个请求在正在准备的前10几秒并没有和 mysql 建立connection 连接。
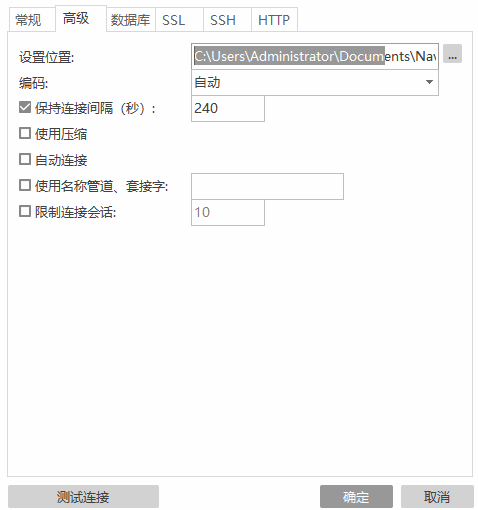
那么我分析可能是 navicat 和数据库服务器之间的通信连接断掉了导致了,而根据 navicat 文档说明,在连接高级设置这里有一个保持连接间隔(官方文档-通过 ping 来保持连接。你可以在编辑框中设置 ping 与 ping 之间的间隔)的时长配置:将其设置成 240s。这样每过240s,软件就会像服务器发送心跳请求,以保证连接不被断开。这样我们就不会出现正在准备。。。等字样了