分水岭分割利用图像形态学进行图像区域分割。它将图像灰度值看作一幅地形图,在地形图的局部极小值处与地形最低点是连通的,从最低点开始注水,水流会逐渐淹没地形较低点构成的区域,直到整个图像被淹没。在这个过程中,通过相关形态学处理,可以实现一幅图像的分水岭分割。
以下GIF图像给出了形象说明:

图像来自 https://www.cnblogs.com/mikewolf2002/p/3304118.html
分水岭分割具体算法思想如下:
1 设 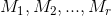 为地形图上完成分割后的 r 个蓄水池,
为地形图上完成分割后的 r 个蓄水池,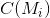 为完成分割后蓄水池
为完成分割后蓄水池 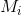 内的像数集合,
内的像数集合,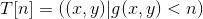 为地形图上灰度值小于 n 的像数集合;
为地形图上灰度值小于 n 的像数集合;
2 当水面上涨到 n 时,当前蓄水池 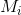 被淹没的像数集合可表示为:
被淹没的像数集合可表示为: 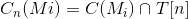 ,
,
当前所有蓄水池被淹没的像数集合表示为: ;
;
3 假设第 n 步时,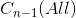 已知, 令 Q 表示
已知, 令 Q 表示 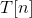 集合构成的连通区域,通过考察 Q 上各个连通区域 q 与
集合构成的连通区域,通过考察 Q 上各个连通区域 q 与  连通区域关系,分别进行如下处理:
连通区域关系,分别进行如下处理:
1)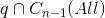 为空时,发现一个新的蓄水池 q,将 q 加入
为空时,发现一个新的蓄水池 q,将 q 加入 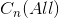 ;
;
2)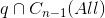 不为空,但仅包含
不为空,但仅包含 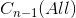 的一个连通分量,将 q 合并到
的一个连通分量,将 q 合并到  中构成
中构成 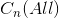 ,蓄水池面积扩大,但数量保持不变;
,蓄水池面积扩大,但数量保持不变;
3)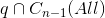 不为空,但包含
不为空,但包含  的两个及两个以上连通分量,此时需要构造堤坝防止
的两个及两个以上连通分量,此时需要构造堤坝防止 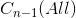 中蓄水池融合;
中蓄水池融合;
4 重复步骤3,直到 n = nmax + 1 时, 表示整个图像像数,分割完成,
表示整个图像像数,分割完成,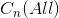 各个连通区域即为分割的蓄水池区域,留下的堤坝则为分割边界。
各个连通区域即为分割的蓄水池区域,留下的堤坝则为分割边界。
以上为分水岭分割基本思想,图像的每个极小值点构成一个蓄水池的中心点。由于图像中存在较多极小值点,故一般图像分水岭分割可能得到很多小的区域。可以通过手动设定蓄水池位置来避免过多极小值影响,算法仅认为设定点为蓄水池中心点,从而忽略掉任意其他极小值点。
同时,可以首先对图像进行一阶微分处理,在图像平滑区域图像梯度值较小,在图像边缘区域梯度值较大。然后使用梯度图像作为地形图,可以分割出平滑图像块。
在 opencv 中,函数 cv::watershed() 实现了分水岭分割,该函数将图像边缘转换为地形图上的山脊,图像平滑区域转换为地形图上的山谷,同时使用 markers 参数标记蓄水池,实现分水岭分割,具体如下:
void cv::watershed(cv::InputArray image, cv::InputOutputArray markers);
image: 8位3通道图像,函数对图像进行一阶微分处理,视梯度图为地形图上的山脊与山谷;
markers: 32位有符号整数图像,使用 1,2,3... 等序号标记不同的蓄水池。当完成分割后,该图像形成最终蓄水池区域标记图像,其中,值 -1 表示区域边界。
以下给出 cv::watershed() 分析截图:


参数资料 医学图像处理与分析 罗述谦 周果宏
https://www.cnblogs.com/mikewolf2002/p/3304118.html