1. 概述
logspout收集数据以后,就会把数据发送给logstash进行处理,本文主要讲解logstash的input, filter, output处理
2. input
数据的输入处理
支持tcp,udp等协议
晚上找资料建议在使用 LogStash::Inputs::Syslog 的时候走 TCP 协议来传输数据。
因为具体实现中,UDP 监听器只用了一个线程,而 TCP 监听器会在接收每个连接的时候都启动新的线程来处理后续步骤。
如果你已经在使用 UDP 监听器收集日志,用下行命令检查你的 UDP 接收队列大小:# netstat -plnu | awk 'NR==1 || $4~/:514$/{print $2}'
Recv-Q
228096
228096 是 UDP 接收队列的默认最大大小,这时候 linux 内核开始丢弃数据包了!
2.1. 语法
基本语法如下:
input{ tcp { mode => "server" port => 5000 codec =>json_lines tags => ["data-http"] } }
2.2. multiline
有时候日志是这样多行显示的:
[2019-10-12 15:24:50 ACCOUNT 97364 4658800064 INFO] http_ip=127.0.0.1 http_uri=/account/v1/binding http_method=POST http_time=182ms http_status=401 http_headers=Content-Type:application/x-www-form-urlencoded Content-Length:27 Accept-Encoding:identity Host:localhost:8800 User-Agent:Python-urllib/3.6 Key:424518e4d27b11e8ada274e5f95979ae Version:1.1.0 Time:1570865090.412524 Token:y66AHLNmRoscIIsoWnKzxosojSg= User-Id:0 Connection:close http_kwargs={'sns_type': 'wechat', 'code': 'CG9DEj', 'user_id': 0, 'language': 1} http_response={"code":"usr_sns_code_error","message":"u7b2cu4e09u65b9snsu5e10u53f7codeu65e0u6548"}
默认情况下logstash会把一行日志转换成elasticsearch的一个doc,上面这个日志就会存储成15条日志。这样就不能满足我们的需求,我们只是想要一条日志
我们可以这么配置input:
input{tcp {
port => 5001type =>syslog
tags => ["syslog"]
codec=>multiline{
pattern => "[%{TIMESTAMP_ISO8601:timestamp}"
negate =>true
what => "previous"
}
}
}红色代码的作用是:匹配到以[2019-10-08 16:57:42开头的一行日志作为previous,不是以这个格式开头的将作为子行出现,然后把多行记录合并成一行记录
3. filter
数据的过滤转化处理
3.1. 语法
基本语法如下:
filter {
grok {
match => { "message" => "%{SYSLOGBASE} %{DATA:message}" }
overwrite => [ "message" ]
}
}
3.2. grok范式匹配
grok适合用来解析syslog,apache,mysql等日志
假如你的日志格式是这样的
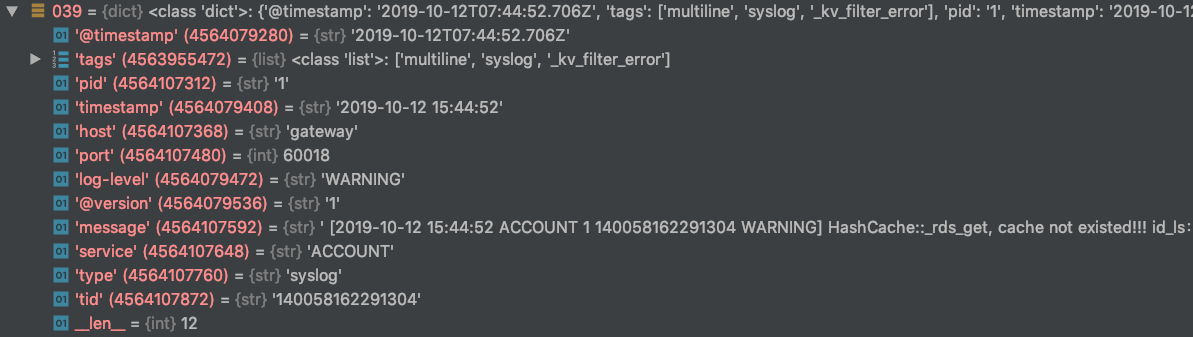
[2019-10-12 15:44:52 ACCOUNT 1 140058162291304 WARNING] HashCache::_rds_get, cache not existed!!! id_ls:[]
日志的格式是这样的:
"[%(asctime)s %(service)s %(process)d %(thread)d %(levelname)s] %(message)s"
那么针对这样有特定格式的日志,我们要怎样提取这里面的字段呢?
可以这么配置你的filter:
filter{
if [type] == "syslog" {
grok {
match => { "message" => "[%{TIMESTAMP_ISO8601:timestamp} %{DATA:service} %{DATA:pid} %{DATA:tid} %{LOGLEVEL:log-level}] %{GREEDYDATA:msg_body}" }
}
}
}
使用grok的match正则表达式匹配可以方便的从message中提取字段
从elasticsearch可以发现增加了timestamp、server、pid、tid和log-level等字段。
附上官网文档:
# grok调试器
https://grokdebug.herokuapp.com=>debugger
# 官方文档
https://www.elastic.co/guide/en/kibana/7.3/xpack-grokdebugger.html
3.3. gsub字符串替换
经过logspout处理以后,会增加一些metadata(container name, container id, etc)
红色部分是logspout添加的:
<14>1 2019-10-08T18:00:15Z zfswalk0 mage-device-11283 16901 - - [2019-10-09 09:49:08 WARNING SACCOUNT C P1 T140004171454120 P1 P2 P3] start listen on HTTP:0.0.0.0:17698, start listen on HTTP:0.0.0.0:17698
如何去除这部分多余的数据呢?
logstash需要使用gsub进行字符串替换:
filter{
if [type] == "syslog" {
mutate {
gsub => [ "message", "<d+>.*?- -", "" ]
}
}
}
这个正则表达式的意义是选择从“<14>”开始到“- -”结束的子字符串,然后替换成空字符串,实现metadata的删除
3.4. remove_filed删除字段
ELK是采用json字典的方式来存储数据的
如果你有哪些字段是不需要的,可以通过remove_field来删除
假如你不想要grop解析出来的msg_body字段和test字段,可以这么操作,那么最后存储到elasticsearch那边将不会出现这2字段
filter{
if [type] == "syslog" {
mutate {
remove_field => [ "msg_body", "test" ]
}
}
}
3.5. kv过滤器解析kv数据
官方文档kv filter:https://www.elastic.co/guide/en/logstash/current/plugins-filters-kv.html
动态的解析kv可以很方便的支持日志扩展,不需要后期去修改
它会把这个字符串:ip=1.2.3.4 error=REFUSED解析成kv字典形式:{"ip":"1.2.3.4", "error": "REFUSED"}
filter{
if [type] == "syslog" {
kv {
source => "msg_body"
field_split => " "
}
}
}
这边的配置意思是:从msg_body这个字段去解析kv字段,字段的分隔符是" "
当然这也要求日志写入的时候需要采用" "来区分多个字段,类似这样:
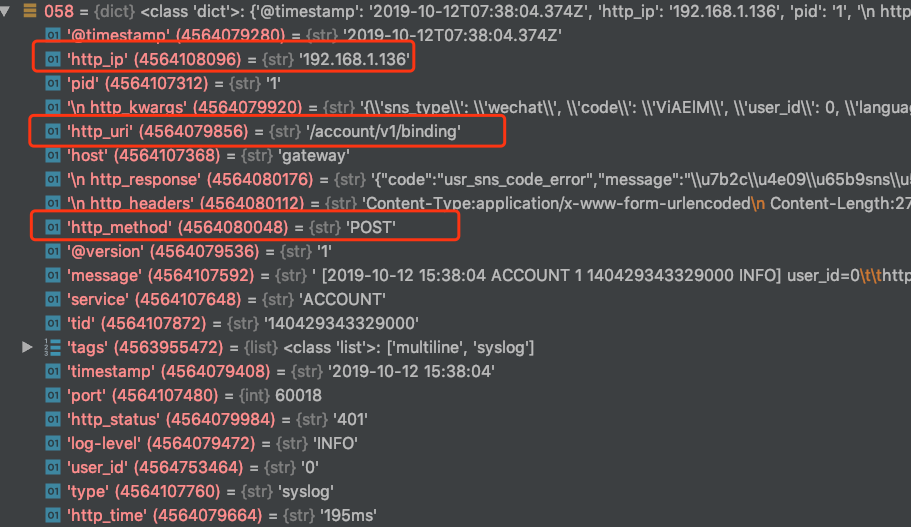
[2019-10-12 15:24:50 ACCOUNT 97364 4658800064 INFO] http_ip=192.168.1.136 http_uri=/account/v1/binding http_method=POST
http_ip=127.0.0.1、http_uri=/account/v1/binding与http_method=POST这三个字段是采用' '分割的
这样kv filter就会解析成功,并往doc里面设置http_ip, http_uri,http_method这三个值:
4. output
过滤转化后的数据的输出处理
这里是把数据存储到elasticsearch的9200端口,index是"syslog-%{+YYYY.MM.dd}"
output{
if "syslog" in [tags]{
elasticsearch{
hosts=>["elasticsearch:9200"]
index => "syslog-%{+YYYY.MM.dd}"
}
stdout{codec => rubydebug}
}
}
然后elasticsearch就能得到数据了