首先是关于新生代中的内存分布的描述:
新生代中的对象都是“朝生夕死”的对象,所以每次gc存活的对象很少,于是在新生代中采用的垃圾回收算法是“复制算法”。
将新生代的内存分为一块较大的Eden区域和两块较小的Survivor区域。每次使用Eden和其中一块Survivor空间。回收的时候,将Eden和Survivor中还存活着的对象一次性地复制到另一块空间上,最后清理Eden和刚才用过的Survivor空间。
HotPost虚拟机默认Eden和Survivor的大小比例是8:1,也就是每次新生代中可用内存空间为整个新生代容量的90%(80%+10%),只有百分之10%的内存会被浪费。
当Survivor空间不够放的时候,需要依赖其他内存(这里指老年代)进行分配担保。
这是书上(《深入理解Java虚拟机》)对于复制算法的描述。
但在后面更详细地讲内存分配与回收策略的时候:
书上说:在大多数情况下,对象在新生代Eden区中分配。当Eden区没有足够空间进行分配时,虚拟机发起一次Minor GC。
这就有点疑惑了,照这么说超过Eden就执行mimor gc,然后survivor只是用来放存活的对象的,那为什么要两个呢?
这是为了解决内存碎片化的问题。
假设我们现在只有一个Survivor空间。
刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。下一次Eden满了的时候,问题来了,此时进行Minor GC,Eden和Survivor各有一些存活对象,因为只有一个Survivor,所以Eden第二次的gc发现的存活对象也是放在唯一的一个Survivor区域中。但此时把Eden区的存活对象硬放到Survivor区,很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。
看图来理解:
(图片来自:https://blog.csdn.net/antony9118/article/details/51425581)
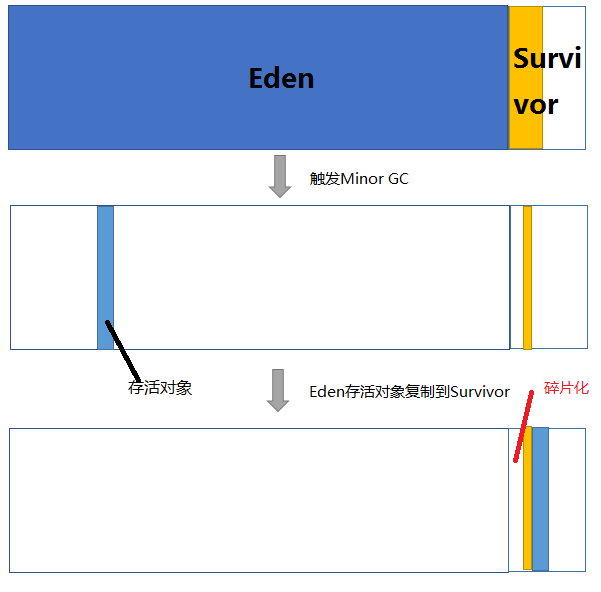
第一个图,是Eden中蓝色的内存装满了,要gc,然后Survivor区中的黄色内存,是上一次gc从Eden过来的存活对象。
第二个图是触发gc后,通过可达性判断,把活着的对象找出来。蓝色的Eden中剩一小丢存活对象,注意Survivor区中的对象也会死掉!所以现在Survivor区的对象也不是从头充满Survivor区域的了。
然后第三个图便是把Eden存活的对象放到Survivor中去,这时就产生了碎片化。
那么要怎么解决这个问题呢?
- 试图将Eden区存活的对象转移到survivor中,努力适应这种不连续的空间。但是不连续的空间会导致再分配大对象的时候,由于没有连续的空间来分配,会导致提前垃圾回收。
- 将survivor中的所有存活对象向下移动来消除碎片,然后将所有的存活对象移入其中。这样做会降低效率。
- 把两个区域中的所有存活对象都转移到完全独立的空间中,也就是第二块Survivor中,这样就可以留出一块完全空着的Eden和Survivor了,下次GC的时候再重复这个流程
显然方案三好点hh,所以我们便要有两个Survivor区。
那么,顺理成章的,应该建立两块Survivor区。
刚刚新建的对象在Eden中,经历一次Minor GC,Eden中的存活对象就会被移动到第一块survivor space S0,Eden被清空;等Eden区再满了,就再触发一次Minor GC,Eden和S0中的存活对象又会被复制送入第二块survivor space S1(这个过程非常重要,因为这种复制算法保证了S1中来自S0和Eden两部分的存活对象占用连续的内存空间,避免了碎片化的发生)。S0和Eden被清空,然后下一轮S0与S1交换角色,如此循环往复。
看图:
(图片来自:https://blog.csdn.net/antony9118/article/details/51425581)
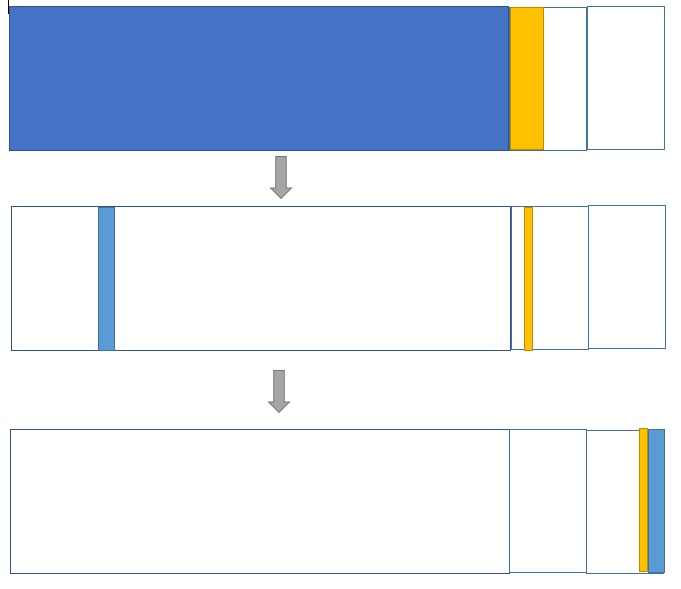
上述机制最大的好处就是,整个过程中,永远有一个survivor space是空的,另一个非空的survivor space无碎片。
参考文章:
https://blog.csdn.net/antony9118/article/details/51425581
https://www.jianshu.com/p/a5fd5bf93d26